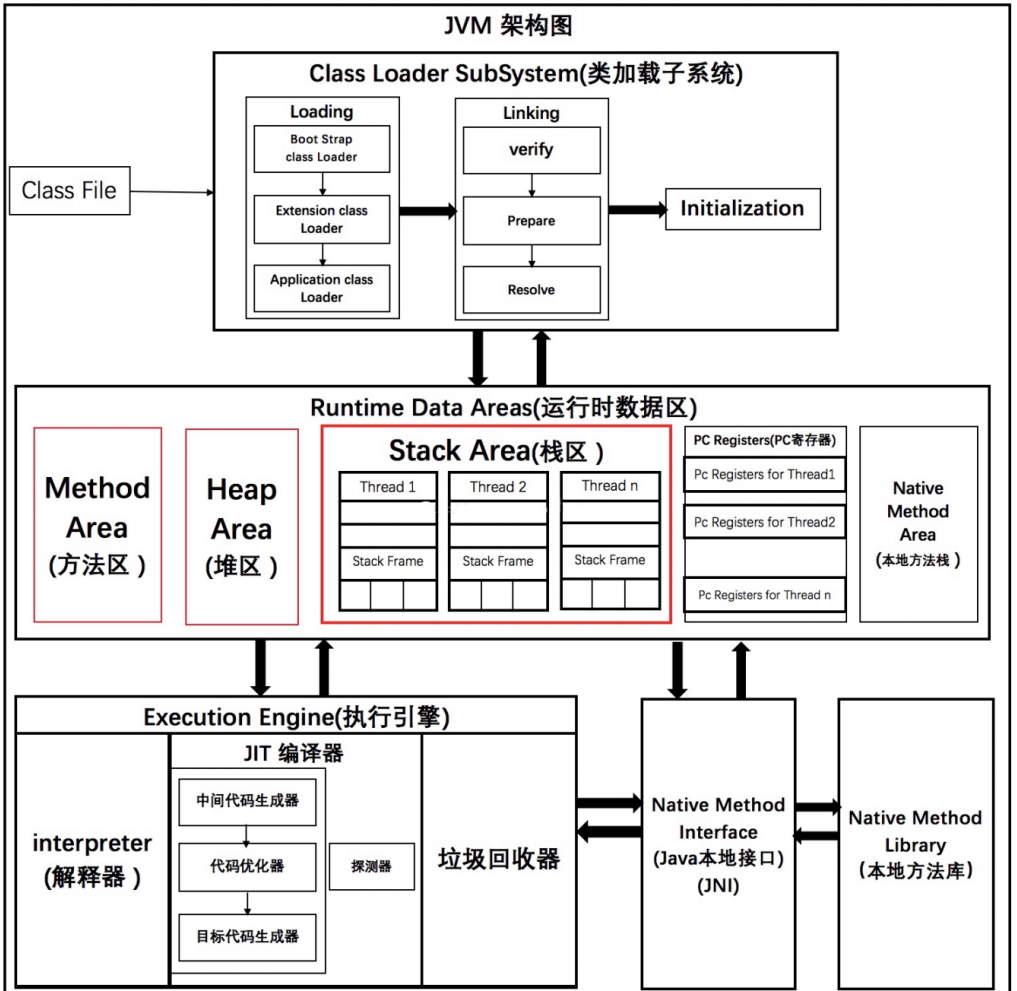
JVM架构图
今天带大家了解下JIT编译器,,首先来看看JVM的整体架构图,JIT编译器存在于执行引擎中.
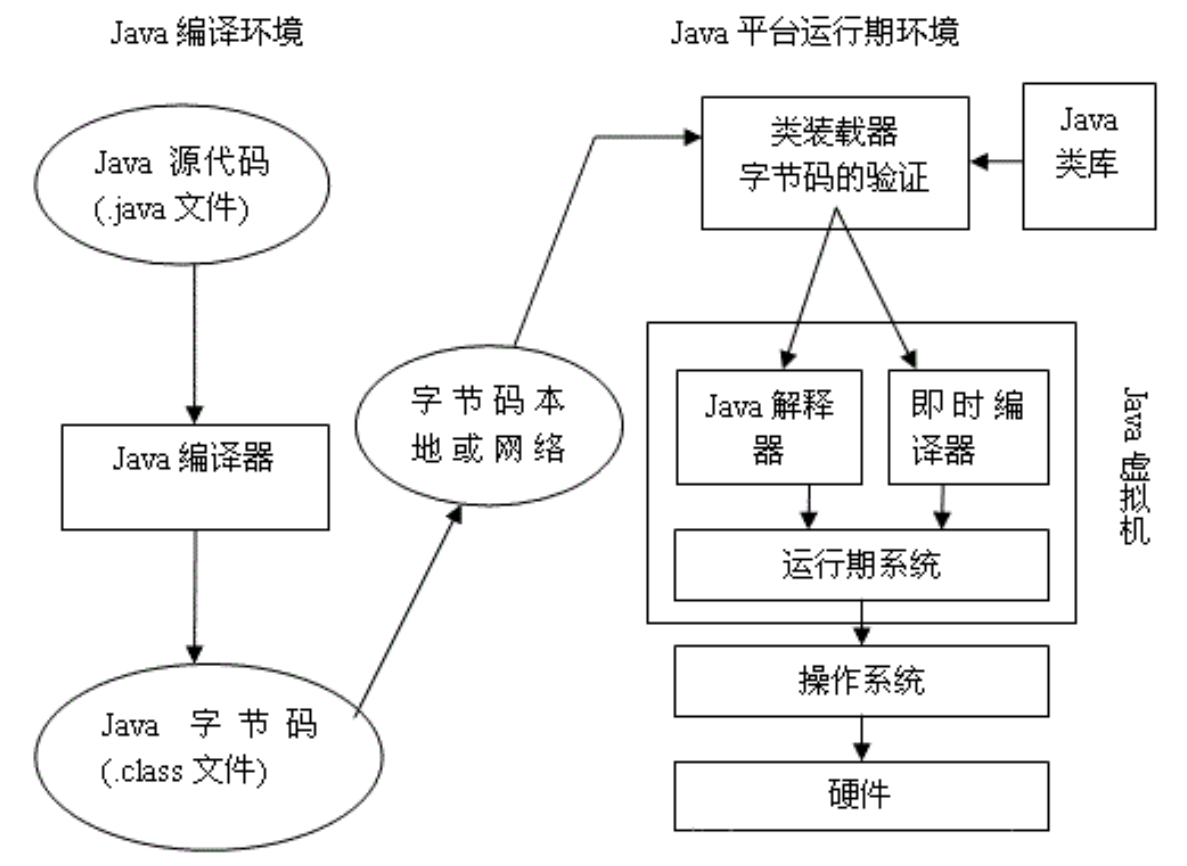
java程序执行流程图
一个类的执行流程需要从.java源文件需要编译成.class文件,然后通过类加载器加载到内存中,但是此时操作系统还不能识别.class文件,它只能认识机器码.所以要通过JVM将.class文件解释成机器码,才能够被操作系统执行.流程图如下
JIT即时编译器
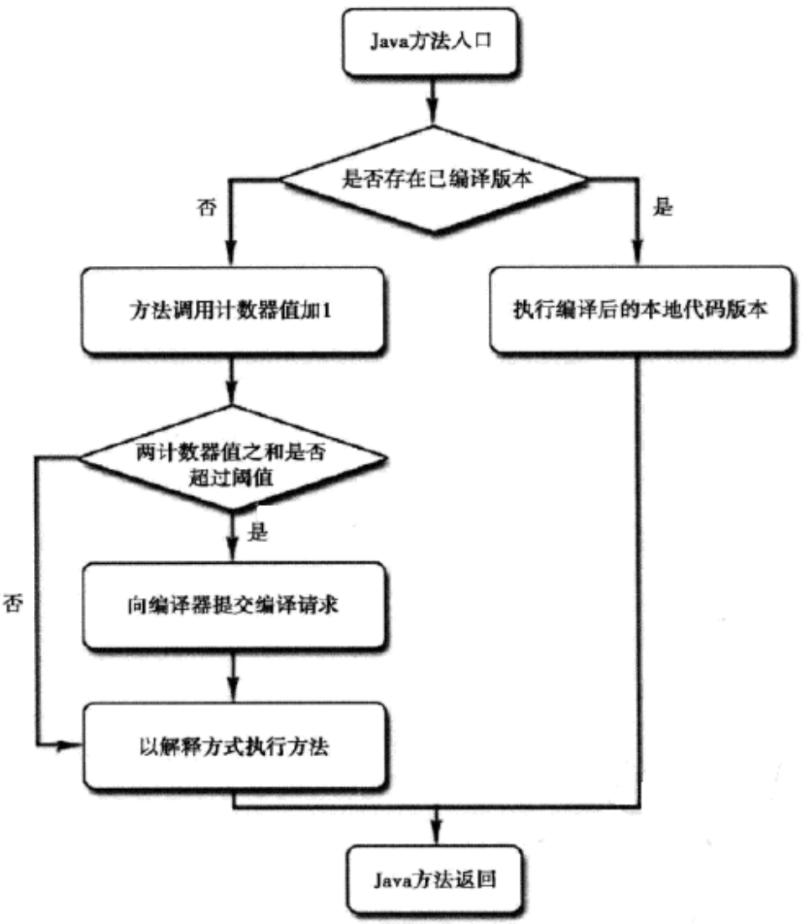
可以看到JAVA解释器和JIT即时编译器是平行的.那么有了解释器就可以将.class转换为机器码为什么还需要即时编译器呢?当操作系统执行.class文件时,解释器需要逐行将.class代码解释成机器语言,这个过程会很快,但若相同的代码被多次执行,例如一个方法被多线程调用,或者代码存在于for循环中,此时在逐行解释就会重复性的执行相同工作.所以出现了即时编译.通过将热点代码一次编译成机器码.大概流程如下图

热点代码
那么什么样的代码算是热点代码呢?运行过程中会被即时编译器编译的热点代码有两类.
1被多次调用的方法
2被多次执行的循环体.
两种情况,编译器都会以整个方法作为编译对象.这种编译方法因为编译发生在方法执行过程中,因此形象的称之为栈上替换,即方法帧栈还在栈上,方法就被替换了.
什么样的代码是热点代码
热点检查的方式一般有两种.
HotSpot虚拟机采用的热点探测
方法调用计数器
回边计数器
JIT编译优化
JIT不仅能做到一次编译重复使用,它还对即时编译的代码做了优化,优化部分为以下六种
1公共子表达式的消除
2方法内联
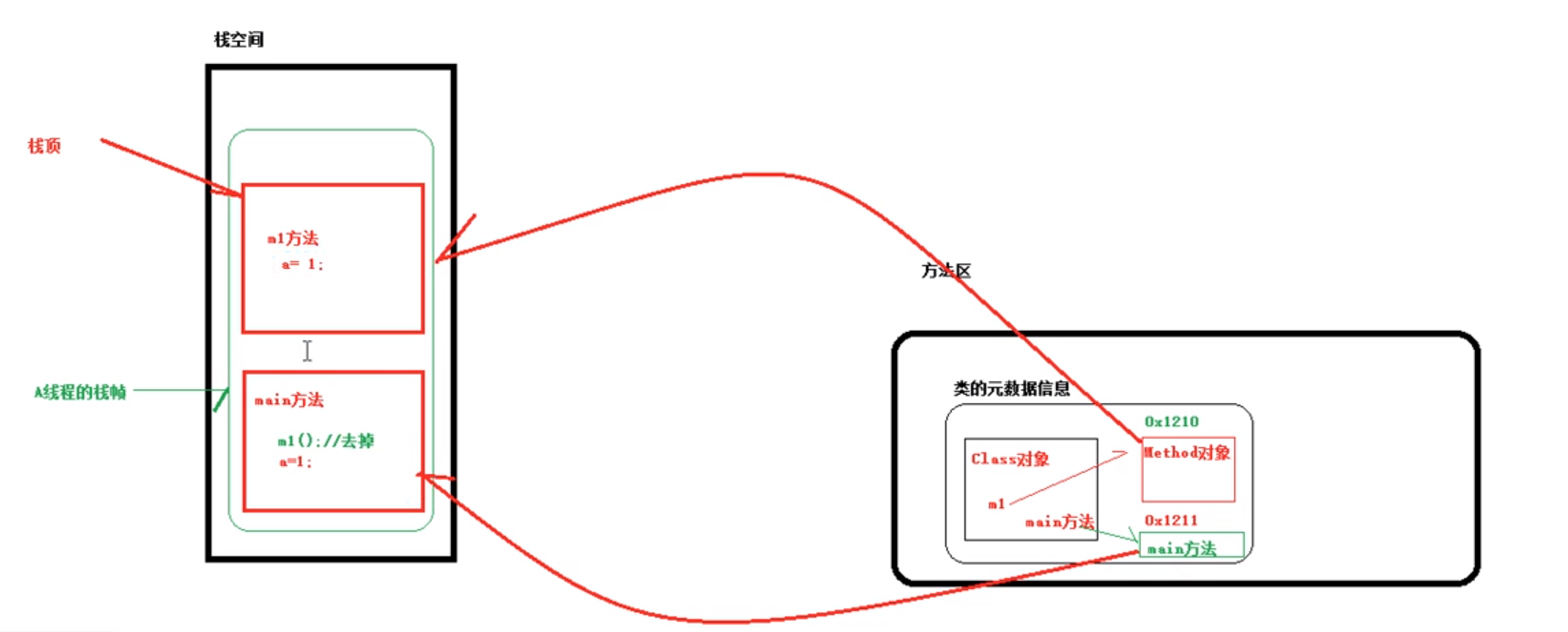
如果方法的调用层次很深,而方法本身并不复杂则会出现频繁的压栈弹栈,是没必要的.在使用JIT进行即时编译时,将方法调用直接使用方法体中的代码进行替换,这就是方法内联,减少了方法调用过程中压栈与入栈的开销。同时为之后的一些优化手段提供条件。如果JVM监测到一些小方法被频繁的执行,它会把方法的调用替换成方法体本身。
逃逸分析
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术。这是一种可以有效减少Java程序中同步负载和内存堆分配压力的跨函数全局数据流分析算法。通过逃逸分析,Java Hotspot编译

public class EscapeAnalysis { //全局变量 public static Object object; public void globalVariableEscape(){//全局变量赋值逃逸 object = new Object(); } public Object methodEscape(){ //方法返回值逃逸 return new Object(); } public void instancePassEscape(){ //实例引用发生逃逸 this.speak(this); } public void speak(EscapeAnalysis escapeAnalysis){ System.out.println("Escape Hello"); } }
1 对象的栈内存分配
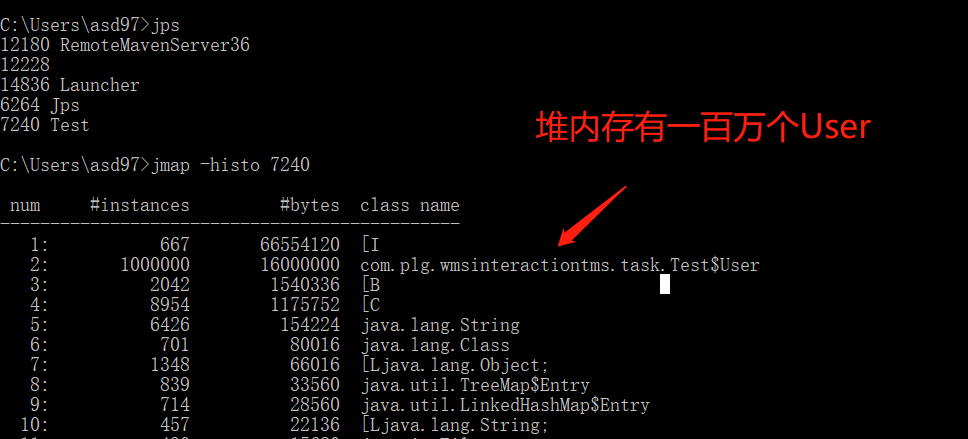
public class Test { public static void main(String[] args) { for (int i = 0; i < 1000000; i++) { alloc(); } // 为了方便查看堆内存中对象个数,线程sleep try { Thread.sleep(1000000); } catch (InterruptedException e1) { e1.printStackTrace(); } } private static void alloc() { User user = new User(); } static class User { } }

从jdk 1.7开始已经默认开始逃逸分析.代码中我们循环了100W次User对象,而在堆内存中只有10W个,可以看出逃逸分析生效了.
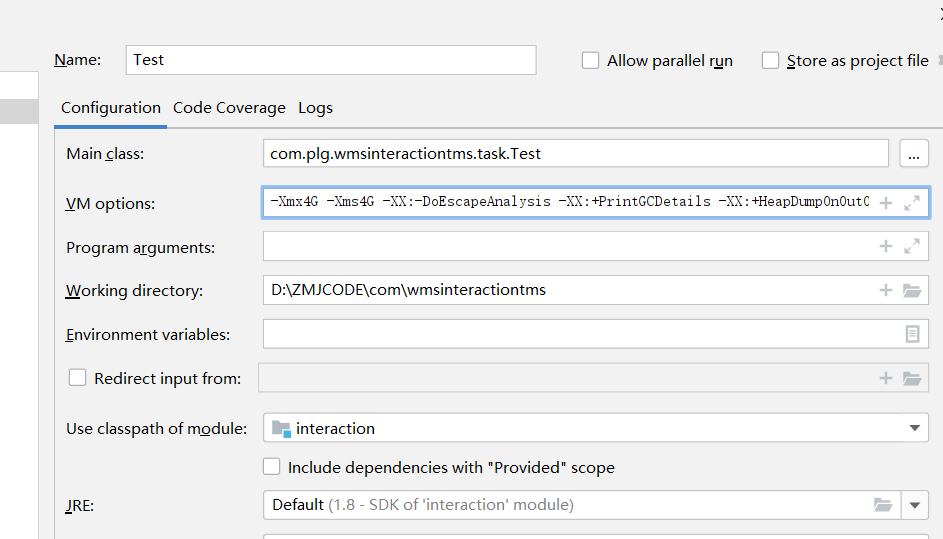
下面把逃逸分析关闭掉.idea启动加入参数,从结果可以看出,没有了逃逸分析,循环100W次,确实是创建了100W个对象在堆内存中.
-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
2 标量替换
标量即不可被进一步分解的量,而JAVA的基本数据类型就是标量(如:int,long等基本数据类型以及reference类型等),标量的对立就是可以被进一步分解的量,而这种量称之为聚合量。而在JAVA中对象就是可以被进一步分解的聚合量.标量替换就是.在JIT阶段,如果经过逃逸分析,发现一个对象不会被外界访问的话,那么经过JIT优化,就会把这个对象拆解成若干个其中包含的若干个成员变量来代替。

3 同步锁消除
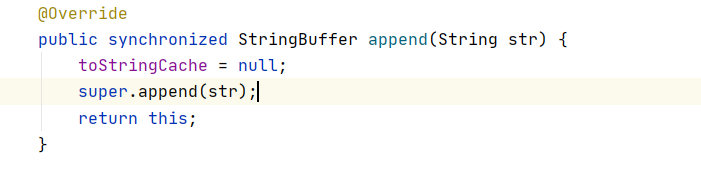
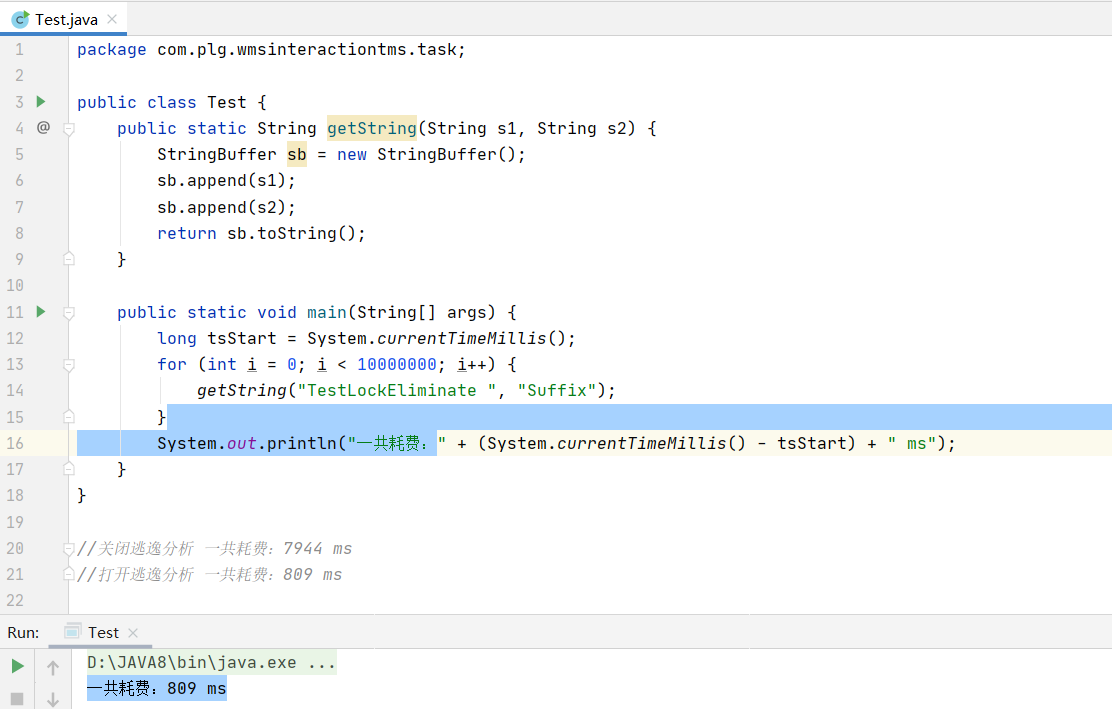
看以下代码示例,在使用StringBuffer时,我们都知道它是线程安全的,也就是它的方法都加了同步锁.加入同步锁肯定会影响执行效率.JIT在开启逃逸分析后,发现StringBuffer对象并没有逃出方法内,所以会使用同步锁消除,也就是以下代码并不会有同步锁加入.
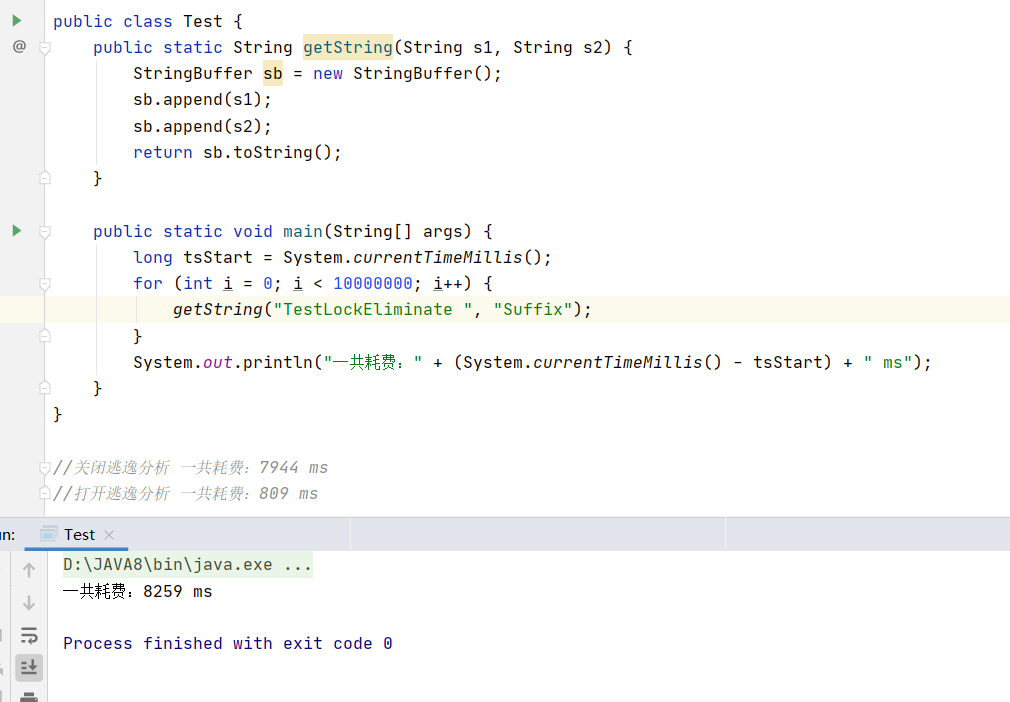
public class Test { public static String getString(String s1, String s2) { StringBuffer sb = new StringBuffer(); sb.append(s1); sb.append(s2); return sb.toString(); } public static void main(String[] args) { long tsStart = System.currentTimeMillis(); for (int i = 0; i < 10000000; i++) { getString("TestLockEliminate ", "Suffix"); } System.out.println("一共耗费:" + (System.currentTimeMillis() - tsStart) + " ms"); } }
以下执行结果是默认开启了逃逸分析的执行时间
以下执行结果关闭了逃逸分析,执行时间远远超过上边的开启逃逸分析