 点击我前往Github查看源代码 别忘记star
点击我前往Github查看源代码 别忘记star
本项目github地址:https://github.com/wangqifan/ZhiHu
一.如何获取到用户的信息
前往用户主页,以轮子哥为例

从中可以看到用户的详细信息,教育经历主页,主修。所在行业,公司,关注量,回答数,居住地等等。打开开发者工具栏查看网络,即可找到,一般是html或者json这个数据在Html页面里。
URL为https://www.zhihu.com/people/excited-vczh/answers,excited-vczh是轮子哥的id,我们只要拿到某个人的Id就可以获取详细信息了。
二.信息藏在哪

对这个json数据进行解析,即可找到用户信息
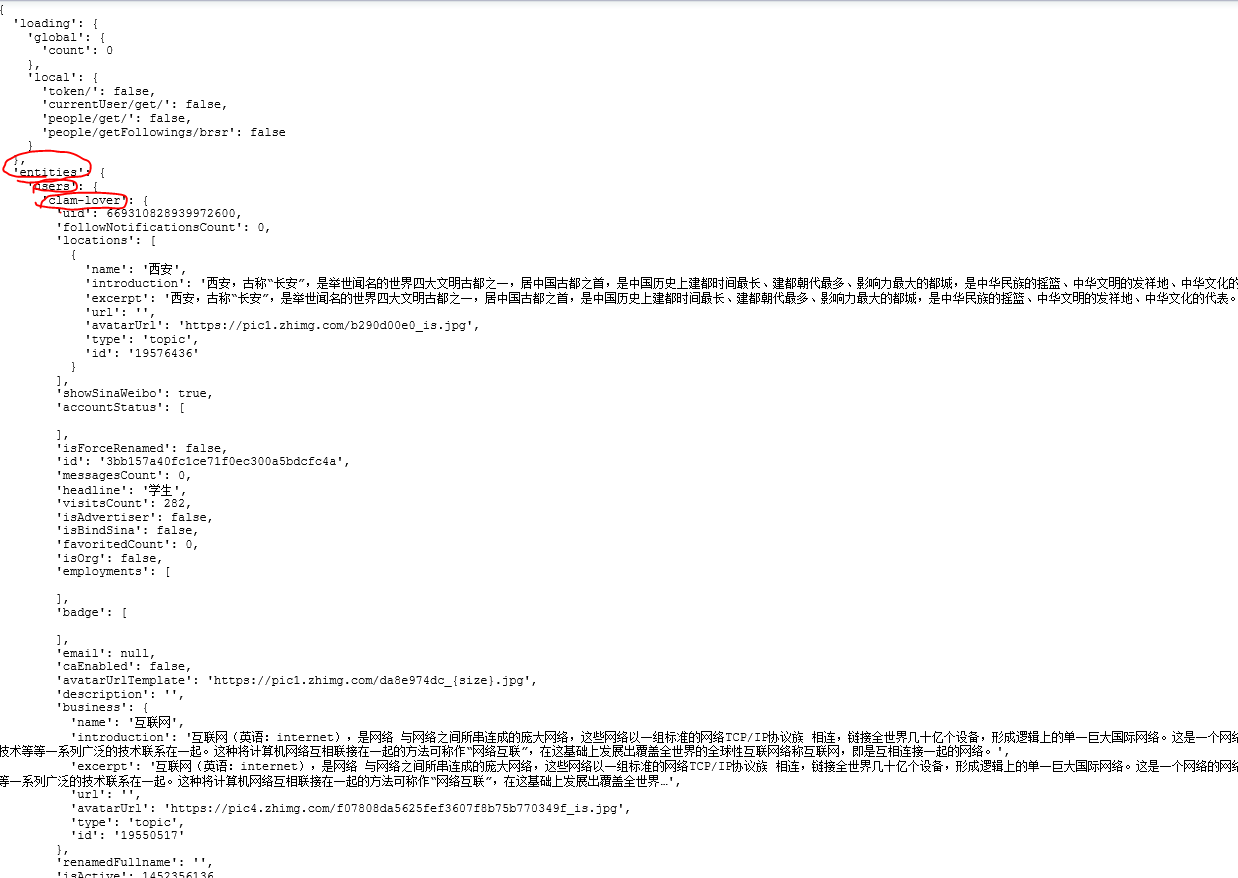
根据URL下载Html页面,解析json就可以获取用户信息了
三.如何获取更多的用户Id

每个人都有自己的关注列表,关注的人和被关注的人,抓取这些人再到这些人主页去抓关注列表,这样就不抽找不到用户了

这里还有nexturl,这个链接可以保存下来。如果isend为true的化就是列表翻到头了,url就不必保存下来
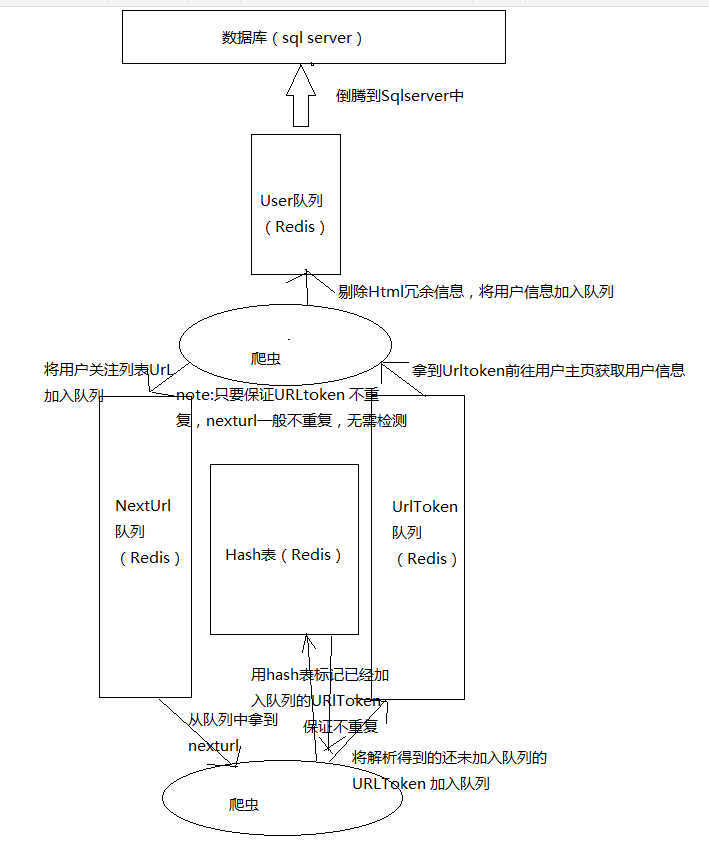
二.爬虫工作流程
有两个爬虫模块,一个爬虫负责重nexturl队列中得到url,下载json并解析,得到的nexturl插入哈希表,如果插入成功,加入队列
另外一个负责中urltoken队列获取urltoken,下载解析页面,将用户信息存入数据库,将nexturl存入nexturl队列
三.常见问题解决思路
重复爬取问题
解析得到的Urltoken肯定有大量的重复,高高兴兴获取很多数据,却发现都是重复的,那可不行。解决办法是对于已经加入队列的urltoken,都放到一张hash表进行标记
断点续爬
爬取百万用户是个比较大的工作量,不能保证一次性爬取完毕,对于中间数据还是要进行持久化,这里选用的是Redis数据库,对于爬取任务加入队列,如果程序中途停止,再次开启只需要重新在队列中获取任务继续爬起
反爬虫问题
抓取过于频繁,服务器返回429.这个时候需要切换代理IP了,我有过自建代理IP池(https://github.com/wangqifan/ProxyPool),也有买过服务商提供的代理服务
例如阿布云:https://www.abuyun.com/
多台机器共同爬取
任务比较大,借助实验室的电脑,一共有10台电脑,5台电脑装了Redis,3台做hash表,2台作队列,具有良好的伸缩性