1.聚合(aggregate)
聚合的主要语法:
from django.db.models import Avg , Max , Min , Count
models.类名 .objects.all().aggregate(聚合函数(字段名))
也可以给聚合函数手动加一个名字 : aggregate(c=count(字段名))
上面这句话的意思是,从类名这个对象中得到你想要聚合(avg,max,min,count)的字段
目前常用的聚合函数有: avg(平均值) , max(最大值) , min(最小值) ,count(计数,有多少个个数)
如果你需要不止一个聚合,可以向aggregate()字句中添加另一个参数,比如:
book.objects.aggregate( Avg(price) , Min(price), Max(price) )
2.分组(annotate)
sql语句 : select * from 表名 group by 以什么进行分组 ;
在orm中,
models.book.objects.values('依据什么字段进行分组').annotate(聚合函数)
例子: 从emp表中找到最高的工资
models.emp.objects.values(dep).annotate(c=Max(salary)) #注意 annotate里面必须写个聚合函数,不然没有意义,并且必须有个别名,别名随便写,但是必须有,用哪个字段分组,values里面就写哪个字段,annotate其实就是对分组结果的统计,统计你需要什么
单表查询:
查询每一个部门(dep)的名称以及对应员工(emp)的平均薪水
models.emp.objects.values('dep_id__name').annotate(av=Avg('salary'))
查询每个部门的Id以及对应的员工的最大的年龄
models.emp.objects.values(dep_id).annotate(max=Max(age))
连表:
models.emp.objects.values(dep__name).annotate(a=Count(id),b=Max(age))
3.F查询: (某数大于,小于某数的查询方式) 如果要查询小于等于可以用 ''~'' 符 ,表示非,小于
语法:
查询a数大于b数的内容
models.book.objects.filter(a__gt=F(b))
查询a数小于b数两倍的内容
models.book.objects.filter(a__lt=F(b)*2)
修改操作也可以使用F函数,比如将每一本书的价格提高10元:
new_price=models.book.objects.update(price=F(price)+10)
4.Q查询:(常与 ''|'' 连用)
语法:
查询姓张的作者或者年龄为28岁的人
models.author.objects.filter(Q(name='张')|Q(age=28))
语法:
查询姓张的作者并且年龄为28岁的人
models.author.objects.filter(Q(name="张"),Q(age=28))
5.orm原生sql语句
Django提供两种方法使用原始SQL进行查询,
一种是raw()方法,进行原始SQL查询并返回模型实例,另一种是完全避开模型层,直接执行自定义的SQL语句.
另一种是extra方法,
6. Python脚本中使用Django环境
import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "BMS.settings")
import django
django.setup()
from app01 import models #引入也要写在上面三句之后
books = models.Book.objects.all()
print(books)
7.自定义标签和过滤器
自定义过滤器:
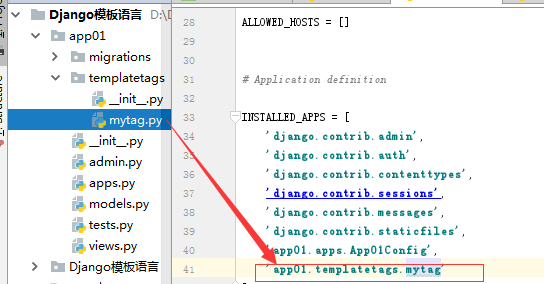
1.在settings中的INSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag
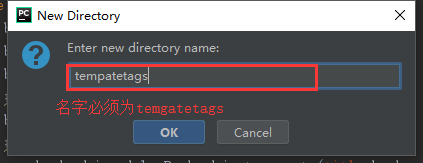
2.在app中创建tempatetags模块(模块名只能是templatetags)
3.创建任意.py文件,如: my_tags.py
from django import template from django.urls.safestring import mark_safe register=template.Library() #register的名字是固定的,不可改变
步骤1: 创建一个文件夹,名必须为tempatetags
步骤2: tempatetags中创建.py文件, 导入
from django import template
from django.urls.safestring import mark_safe
步骤3: 在settings中注册
步骤4:写你自己要写的过滤器,比如: 你要将所有的'o'替换成'x'
@register.filter #固定死的
def myreplace(a,b): #最多接收连个参数,而且这个过滤器可以放到if判断和for循环等语句里面
来使用 return a.replace(o,b)
步骤5:在HTML文件中写
在开头引入你创建的py文件
{% load 创建的py文件 %}
然后在你想要过滤的地方写你自定义的过滤器
{{ name|myreplace:'内容' }} 此时就把你的name内容中的'o'全部替换成了'x'
自定义标签:(不能用在if ,for循环里面)
前三步的步骤是相同的
步骤4:
也是写一个函数
@register.simple_tag #也是固定不变的
def func(v1,v2,v3): 过滤内容
步骤5:
在HTML文件中,写你自定义的标签
{% func 属性1 属性2 属性3 ...%}