http://xilinx.eetrend.com/content/2020/100059756.html
judy 在 周一, 12/14/2020 - 15:51 提交
本文转载自:网络交换FPGA微信公众号
近年来,随着集成电路工艺的不断进步,大数据与人工智能的兴起,数据中心的网络负载愈来愈高,然而由于摩尔定律和Dennard缩放定律的失效,通用处理器依靠加深流水线深度和增加多核并行都受到功耗墙和存储器墙的限制。星球级算力需求的增加促使定制化硬件逐渐兴起(见公众号文章:未来已来:ASIC云和行星级应用程序的数据中心),从RDMA到RoCE V2到TOE设备,数据中心网络从10Gbps发展到40Gbps,目前100Gbps和400Gbps的接口正在成为主流。本文设计的100Gbps网卡基于一款开源100Gbps NIC刚玉(见公众号文章:业界第一个真正意义上开源100 Gbps NIC Corundum介绍),在理解消化代码的基础上,基于其架构将部分核心代码进行修改,使其更适合于硬件实现,并为后续扩展功能进行了前期预研和准备。
公众号文章《业界第一个真正意义上开源100 Gbps NIC Corundum介绍》发出后,得到了很多粉丝的关注,大家纷纷留言讨论。因此,本文也是对众多问题的简单回应。另外,特别感谢Xilinx提供免费试用的Alveo U50网卡,我们把原本搭载在VCU118板卡上的刚玉工程移植到了Alveo U50板卡上,与VCU118板卡一起实现了两台普通电脑的100Gbps光纤连接,并进行了非优化加速情况下普通应用的测试。
随着云计算的兴起,越来越多的计算被部署到云端来执行,数据中心的运营模式逐渐云化,从接入模式来看,当前部署的云计算主要分为公有云、私有云和混合云。私有云主要是单位或者个人使用的云计算资源,不对外提供,因此可以不兼容传统以太网,在诸如高性能的分布式计算应用场景下有较好的应用前景。公有云通过Internet为用户提供服务,因此需要兼容以太网。再加上需要定制加速的应用越来越多,可编程的Smart NIC逐渐的走上了舞台中央。
高性能数据中心的网络演进趋势
软硬件协同优化方法
在1Gbps时代,由操作系统网络、协议栈和进程调度引起的开销是可以接受的,但是随着定制化硬件的性能越来越高,网络协议栈和进程上下文切换引起的开销变得不可接受。针对协议栈的开销,人们提出了分段卸载功能,将数据面卸载到可编程网卡设备而在处理器上仅对控制面进行处理;在用户侧,应用程序通过BSD
Socket接口和协议栈通信,然而协议栈进程和网卡驱动程序位于内核态,频繁发生的用户态和内核态上下文切换和数据缓冲区的拷贝带来了极大的CPU开销。为了解决这个问题,提出了诸如英特尔的DPDK的用户态协议栈,这些协议栈大多涉及或支持无锁的Ring操作,更换了用户Socket
API,采用内存重映射等技术实现DMA零拷贝技术。可见,采用软硬件协同设计方法是优化网络中心的最佳方案。
RDMA技术
RDMA(RemoteDirect Memory Access)技术全称远程直接内存访问,就是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA有以下三个特性:
Remote:无CPU参与,数据通过网络与远程机器间进行数据传输。
Direct:没有内核态的切换,有关发送传输的所有内容都卸载到网卡上。
Memory:在用户空间虚拟内存与RNIC网卡直接进行数据传输不涉及到系统内核,没有额外的数据移动和复制。
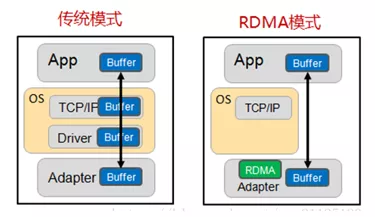
值得注意的是,RDMA没有使用标准的TCP/IP协议,而是提出了自己的一套传输协议,因此不支持广域网的传输,为了支持公有云的设计,RDMA在承载网络上设计了三套标准。
1)实现在InfiniBand网络。InfiniBand是专为RDMA设计的一套网络,在硬件级别保证数据可靠传输。需要专用的IB交换机和IB网卡,不支持Internet连接,主要适用于私有云和分布式计算。
2)RoCE(RDMAover Converged
Ethernet),分为V1版本和V2版本。RoCEV1将RDMA协议运行在以太网协议上,而RoCEV2将RDMA协议运行在UDP协议上。构建RoCE网络需要专用网卡,但是交换机可以兼容标准以太网交换机,因此可以用于构建公有云和数据中心。
3)iWarp(internetWide Area RDMA Protocol),iWarp将RDMA协议运行在TCP协议上,与RoCE具有类似特性。
目前,RoCE由于支持Internet并且较iWarp协议更加简单,拥有较大的市场和更好的前景。
另外,针对Smart NIC的研究现在也被推上高潮,由于采用了嵌入式的CPU,智能网卡可以进一步降低对Host主机的依赖,因此正在被数据中心广泛采用。
开源100Gbps NIC(Corundum)架构简介
高性能NIC采用基于队列和描述符的机制完成数据发送和接收的调制解调。描述符即指向内存中数据物理地址的一组地址描述逻辑,队列被实现为内存中连续的、可以存放多个描述符的环形缓冲区。网卡的驱动程序发出内存屏障,生成数据和对应的描述符后通过门铃操作告知板卡,板卡获取描述符后解析,并产生对数据的处理操作。
从系统结构上来看,NIC的顶层包含PCIe IP和DMA接口、100Gbps MAC
IP和PHY及相应的以太网接口,顶层还需要包含一个或者多个Interface接口,一个Interface接口被实现为Host下的一个NIC,即操作系统级别的网络接口。网络接口内部主要用于户逻辑的实现,包括用于维护NIC队列的队列管理逻辑,描述符获取和操作完成报文写逻辑、发送和接收引擎以及发送调度程序,用于中间暂存数据的分段存储器。
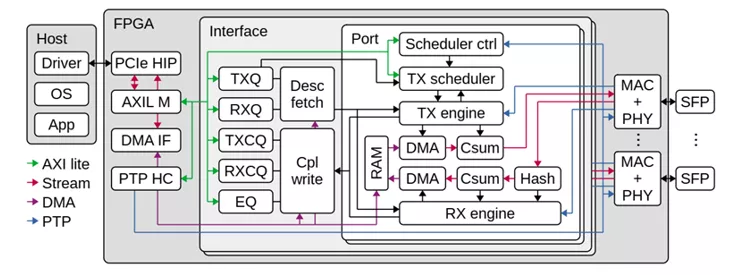
在发送方向上,由驱动更新生产者指针并通过PCIe的下行链路通知到板卡寄存器,发送队列管理逻辑通过Doorbell操作告知发送调度程序。发送调度采用RR调度算法从已启用的队列进行调度,而后发送调度向发送引擎发起req请求。发送引擎收到传输请求后,向对应队列发送描述符获取请求,最终,描述符获取请求由描述符获取模块路由到发送队列管理模块,发送队列管理模块将对应的状态响应到描述符获取模块,描述符获取模块使用DMA接口上的控制接口将描述符从队列取出后放到中间段RAM,而后将描述符获取状态返回到发送引擎。发送引擎根据描述符获取状态到中间段RAM取得描述符,而后使用DMA的数据接口将数据从Host搬移到分段存储器RAM,然后又DMA客户端将数据从分段存储器发送到MAC控制器。上述数据操作流程相当复杂,如果采用状态机控制,将会浪费部分数据通路的带宽,这样数据很难达到高性能。高性能NIC往往采用流水线设计,而刚玉NIC中基于操作表和操作指针的设计非常适合网络流水线的处理,因此我们沿用了这个设计思路并将其扩展到部分数据控制通路上去,后续小节将会详细介绍采用操作表和操作指针的流水线设计思路。
在接收方向上,传入的数据包通过流哈希模块确定目标接收队列,并为接收引擎生成命令,该命令协调对接收数据路径的操作。由于同一接口模块中的所有端口共享同一组接收队列,因此不同端口上的传入流将合并到同一组队列中。接收方向的数据的流程不在赘述。
基于流水线的队列管理
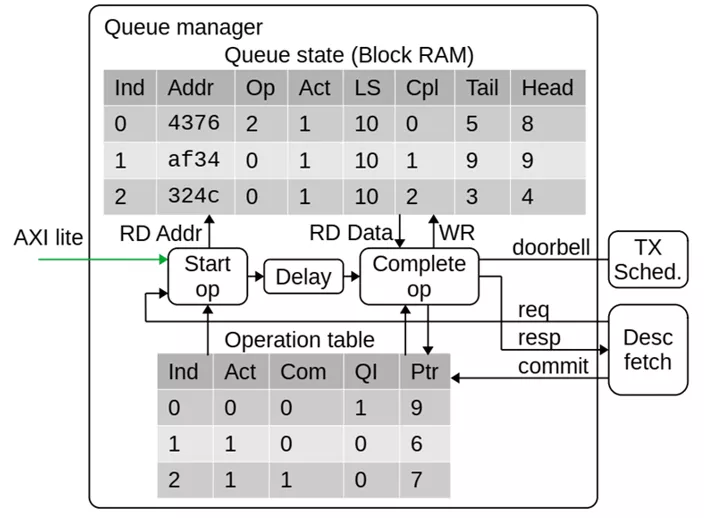
实际上,NIC中为了提高数据带宽利用率,几乎所有的模块都采用了流水线处理方式来促进高并发。本节以队列管理模块来介绍基于操作表和操作指针的流水线设计思路。
Corundum NIC的队列管理逻辑必须能够有效地存储和管理数千个队列的状态。为了支持高吞吐量,NIC必须能够并行处理多个描述符。因此,队列管理逻辑必须跟踪多个正在进行的操作,并在操作完成时向驱动程序报告更新的队列指针。NIC的操作表项包含激活和提交标志、所属队列号、和影子指针,操作指针包括操作表开始指针和操作表提交指针,通过不同的指针对操作表不同字段的索引就可以跟踪当前进行中的不同操作项目进展到哪一个步骤,从而可以触发流水操作。更详细的来说,当队列管理接收到出队请求时将命令放置到Pipeline同时触发队列消息,当命令到达处理周期时,对应队列的信息已经被索引到,此时可以进行处理,如果出队被允许,必要的信息会被记录到操作表,处理逻辑只需要不断写入操作表并更新操作指针,可以认为出队逻辑在处理操作表的表头,操作被提交时会触发提交逻辑,提交逻辑处理操作表末并合理的释放操作表。需要注意的是,操作表只跟踪正在进行中的处理进程,因此不需要设置太大。它和队列管理的信息RAM构成了一个双向链表,即队列信息中需要存入为该队列服务的最新的操作表项索引,用于维护正确的影子指针。
分段存储器
为了实现高性能,Corundum在内部使用了自定义分段存储器接口,该思想与CPU中的剩余缓存技术设计思路类似但又不完全一致。该接口被分成最大128位的段,并且整体宽度是PCIe硬IP内核的AXI流接口的两倍。例如,将PCIe Gen 3 x16与PCIe硬核中的512位AXI流接口一起使用的设计将使用1024位分段接口,该接口分成8个段,每个128位。与使用单个AXI接口相比,该接口提供了改进的“阻抗匹配”,通过消除背压和对准问题来提高PCIe链路利用率。通过设置基地址和偏移量,分段存储器可以在每次访问时保证100%的数据带宽。
基于Xilinx Alevo U50和VCU118 板卡的测试
Xilinx Alevo U50卡采用赛灵思 UltraScale+™ 架构,率先使用半高半长的外形尺寸和 低于75 瓦的低包络功耗。该卡支持高带宽存储器 (HBM2),每秒 100G 网络连接,面向任意类型的服务器部署。而VCU118则包含了两个100Gbps光模块,支持PCIe Gen3 X16,最大128Gbps带宽,两块板卡均可以满足我们的测试需求。

我们在测试过程中选用了两台主流性能机器,它们采用分别Intel 8700K和4770K,配置单如下:

两台机器使用光纤连接,U50直接插在主机的PCIe插槽上,VCU118通过扩展的PCIe延长线插到主机的PCIe插槽上,实物图如下:

Alveo U50由于采用半高设计,可以直接插入到服务器或者普通主机机箱内,VCU118则需要PCIe电缆进行连接。

板卡安装就绪后,烧写Bit文件,并重新启动系统,装载Linux驱动,此时可以使用Linux系统的网络工具进行查看,在本次测试中,设置U50板卡的IP地址为192.168.0.128,VCU118板卡的IP为192.168.0.129。而后进行网络测试,发现可以正常Ping通,网络延时在2ms左右。(视频请点击公众号查看)
为了测试TCP连接,我们安装了FTP传输工具用于在两台机器之间传输文件。受限于FTP软件是双线程,并且我们使用的机器采用机械硬盘,传输的速率并不理想,但是可以证明TCP链接是没有问题的。(视频请点击公众号查看)
为了测试到高性能NIC的极限性能,我们使用C语言创建UDPSocket链接,并不断发送1400字节帧长数据。
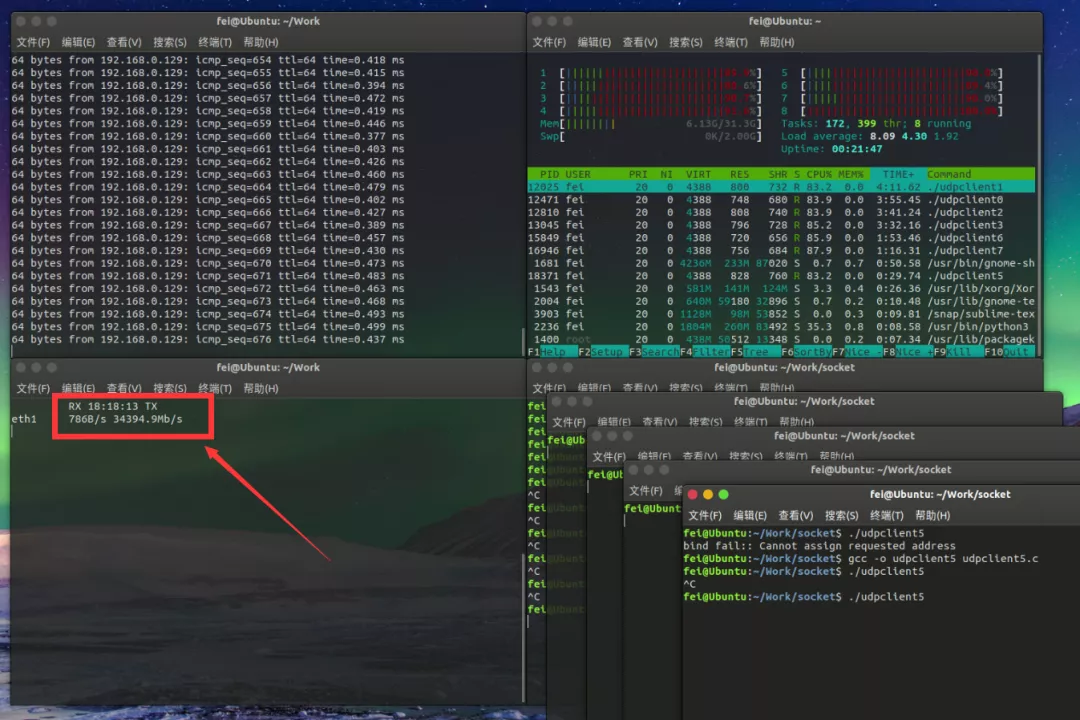
UDP Socket极限发包速率
在单线程下,使用BSD
Socket可以达到将近10Gbps的速率,在多线程使用时受限于CPU瓶颈,我们的最高测试速率达到了35Gbps,此时可以发现CPU性能已经接近满负载,即使增加更多的线程,网络处理速率也不会增大,非常遗憾的是更高的性能需要在服务器级别的主机上才能进一步测试。(视频请点击公众号查看)
也有网友在服务器上实现并分享了自己的测试结果:

用户态协议栈和用户套接字简介
用户态协议栈旨在替换Linux内核自带的协议栈,并提供零拷贝DMA技术。网络协议栈一般作为操作系统的组件,运行在内核态中,用户调用套接字来调用协议栈进程,此时会涉及用户态和内核态的上下文切换。Linux协议栈为了通用性考虑,本身性能并不高。
从概念上讲:Linux协议栈分为三层,VFS层为应用程序提供套接字API;传统的TCP/IP层提供I/O复用、拥塞控制、丢包恢复、路由和服务质量保证;网卡层与网卡硬件完成数据收发。VFS层贡献了网络协议中极大一部分开销。内核穿越和套接字描述符锁为每次操作带来了开销,传输协议在TCP/IP处理上消耗CPU,其他诸如中断、进程切换、I/O复用也在消耗CPU;此外,BSD Socket中的send和recv语义会导致协议栈和应用之前的数据复制。
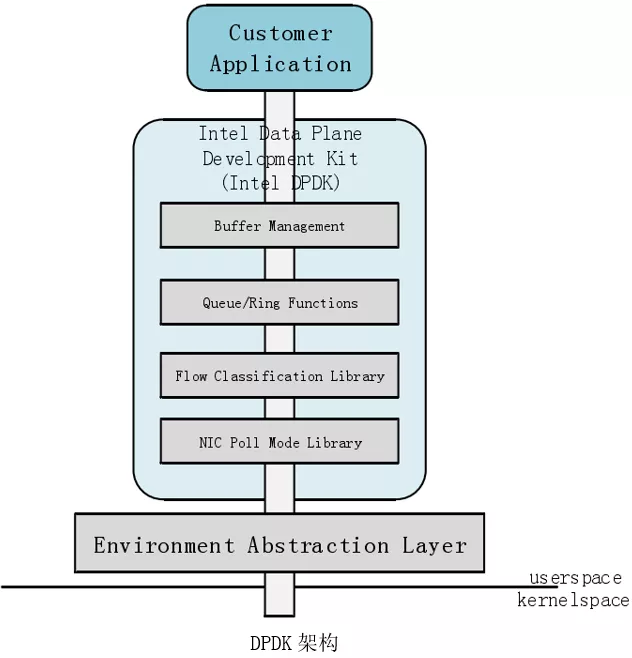
为了解决上述问题,目前有多款开源的用户态协议栈被提出。其中包括Intel针对高速大并发网络提出的数据平面开发套件DPDK。Intel-DPDK提供了一套可从linux用户态空间使用的API来替代传统的LINUX系统调用,数据将不再跨越Linux内核,而是直接通过Intel-DPDK路径。注意到,DPDK本身并不具备协议栈功能,而是为用户提供一套开发套件。目前,已经存在诸如MTCP等基于DPDK的开源用户协议栈。
DPDK存在以下优势:
1)轮询:在包处理时避免中断上下文切换的开销,对于高速大突发数据量的网络中心,随时都有数据到达。
2)用户态驱动:通过UIO技术将报文拷贝到应用空间处理,规避不必要的内存拷贝和系统调用,便于快速迭代优化。
3)亲和性与独占:传统内核运行时,调度器采用负载均衡机制,一个进程会在多个CPU核心上切换,造成额外开销,而DPDK特定任务可以被指定只在某个核上工作,避免线程在不同核间频繁切换,保证更多的cache命中。
4)降低访存开销:Linux默认采用4KB分页管理机制,然而在大量使用内存时,将严重制约程序的运行性能。Linux2.6后开始支持HUGEPAGE,利用内存大页HUGEPAGE可以降低TLB miss,利用内存多通道交错访问提高内存访问有效带宽。
5)软件调优:cache行对齐,预取数据,多元数据批量操作。
6)无锁队列:DPDK 提供了一种低开销的无锁队列机制 Ring,Ring 既支持单生产者单消费者,也支持多生产者多消费者。内部实现没有使用锁,大大节省了使用开销。
7)使用rte_mbuf结构体来代替传统的sk_buff结构体,可以节省一次内存开销。
后续的工作和发展方向
通过测试表明,高性能NIC依然存在一些问题,如在接收方向上没有进行描述符预读取机制,这将会大大提高接收延迟;没有加入对虚拟化的支持,由于网络中心主要面向多用户服务,因此大多云都需要加入对SRIO-V等虚拟化功能的支持;没有采用大容量DDR或者更高性能的HBM缓存,这将导致其防抖动性能较差;没有软件协议栈与其配合工作,软硬件协同设计优化趋势是大势所趋,在网络中心上也是如此,高性能NIC需要采用用户态协议栈来进行优化才能更好的发挥其性能;另外,硬件协议栈分段卸载也是未来发展的方向,未来的高性能NIC势必也要具备这个功能。
后记
业界和学术界也在为提高Smart NIC性能在不懈的努力。如最近斯坦福大学著名的Nick教授团队提出的NanoPU(文章题目:The
nanoPU: Redesigning the CPU-Network Interface to Minimize RPC Tail
Latency,2020年),100G光口经过协议无关Match-Aciton多级流表等内部处理逻辑再到内部嵌入式RISC-V处理器的回环时延仅有65ns。

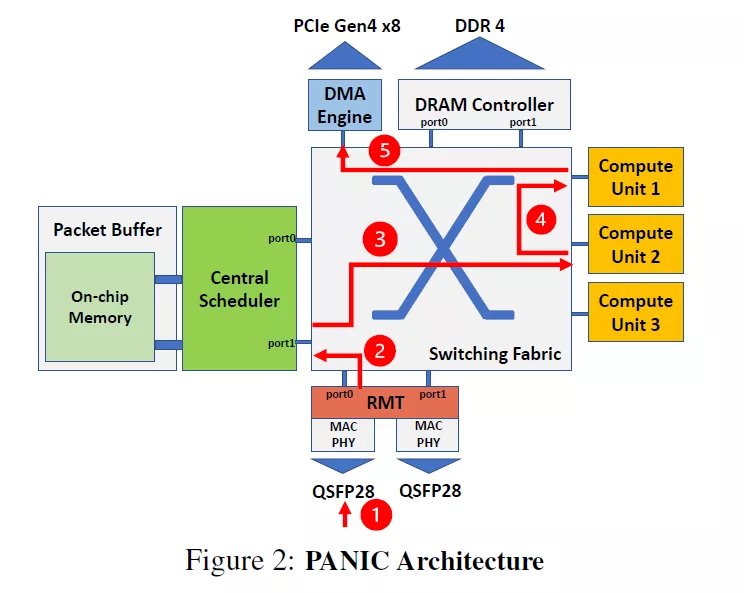
另外,在100G开源 Corundum 可编程NIC的基础上的对该开源IP核进行改进的文章也已经出来了,而且,最可贵的是这篇改进的文章PANIC也是开源的(OSDI 2020:https://www.usenix.org/conference/osdi20/presentation/lin)。文章针对目前所有的SmartNIC都不擅长同时运行多个租户的卸载问题进行了研究并提出了切实可行的解决方案。相关研究工作后续本公众号会持续跟进。