Catalog:Click to jump to the corresponding position
目录:
=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=.=
Pandas模块
Numpy能够帮助我们处理的是数值型的数据,当然在数据分析中除了数值型的数据还有好多其他类型的数据(字符串,时间序列)
那么pandas就可以帮我们很好的处理除了数值型的其他数据
pandas中有两个常用的类:Series、DataFrame
Series
Series是一维的,且元素必须是同一类型由下面两个部分组成:
values:一组数据(ndarray类型)
index:相关的数据索引标签
由列表或numpy数组创建
由字典创建
-使用列表创建
from pandas import Series #注意Series的首字母大写
s_case = Series(data=[2,4,6,8,10])
s_case
输出结果:

-使用数组创建
import numpy as np
from pandas import Series #注意Series的首字母大写
arr_case = np.random.randint(1,10,size=(5,)) #Series只能是一维,所以size=(5,)
s_case = Series(data=arr_case)
s_case
输出结果:

-使用字典创建
字典的键作为Series的行索引,字典的值作为Series的值
import numpy as np
from pandas import Series #注意Series的首字母大写
dict_case = {'name':'zrh','age':20,'height':175,'wife':'yoona'}
s_case = Series(data=dict_case)
s_case
输出结果:

指定行索引
用index来指定显示索引(Series是一个一维的对象,所以只有行索引,没有列索引)
import numpy as np
from pandas import Series #注意Series的首字母大写
data_case = ['yuri','yoona','zrh']
s_case = Series(data=data_case,index=['a','b','c'])
s_case
输出结果:

import numpy as np
from pandas import Series #注意Series的首字母大写
dict_case = {'name':'zrh','age':20,'height':175,'wife':'yoona'}
s_case = Series(data=dict_case)
s_case
输出结果:

s_case[0] #取第一行的值
输出结果:'zrh'
s_case.wife #取索引为 wife 对应的值
输出结果:'yoona'
s_case[0:3] #取Series的第1行到第3行
输出结果:

s_case[[0,2]] #取Series的第一行和第三行
输出结果:

s_case[::-1] #将Series倒序显示
输出结果:

s_case[2::-1] #将Series倒序显示之后取前三行数据(在[::-1]这种模式下:倒序之后索引是不变的)
输出结果:

shape、size、index、values、dtype
import numpy as np
from pandas import Series #注意Series的首字母大写
dict_case = {'name':'zrh','age':20,'height':175,'wife':'yoona'}
s_case = Series(data=dict_case)
s_case
输出结果:

s_case.shape #形状
输出结果:(4,)
s_case.ndim #维度
输出结果:1(Series只能是一维的)
s_case.size #元素个数
输出结果:4
s_case.values #Series的值 也可以使用s_case.values.tolist()将其转化为列表
输出结果:array(['zrh', 20, 175, 'yoona'], dtype=object)
s_case.index #返回Series的索引
输出结果:Index(['name', 'age', 'height', 'wife'], dtype='object')
s_case.dtype #返回Series的类型
输出结果:dtype('O') O表示object、字符串的意思
head()、tail()、unique()、isnull()、notnull()
add() 加、sub()减、 mul()乘、 div()除
import numpy as np
from pandas import Series
s_case = Series(data=np.random.randint(1,10,size=(8,)))
s_case
输出结果:
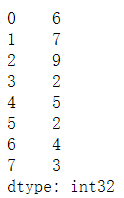
s_case.head(3) #显式前3行,参数不填的话默认显示前5行
输出结果:

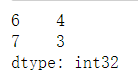
s_case.tail(2) #显式后3行,参数不填的话默认显示后5行
输出结果:
s_case.unique() #去重
输出结果:array([6, 7, 9, 2, 5, 4, 3], dtype=int64)
s_case.isnull() #用于判断每一个元素是否为空,为空返回True,否则返回False
输出结果:

s_case.notnull() #用于判断每一个元素是否不为空,不为空返回True,否则返回False
输出结果:

s_case.add(10) #返回新的Series,不改变原Series的值
输出结果:
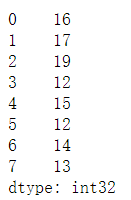
s_case[0] = 10 #将s_case的第一个数据改为10(原理是将值取出来重新赋值)
s_case[0]
输出结果:10
法则:索引一致的元素进行算数运算,否则补空
from pandas import Series
s1 = Series(data=[1,2,3],index=['a','b','c'])
s2 = Series(data=[4,5,6],index=['a','e','c'])
s = s1 + s2
s

-drop:删除元素
import numpy as np
from pandas import Series #注意Series的首字母大写
dict_case = {'name':'zrh','age':20,'height':175,'wife':'yoona'}
s_case = Series(data=dict_case)
s_case
输出结果:

s_case.drop(['name','height'],inplace=True)
s_case
输出结果:

inplace=True 表示应用到原数据上,即会改变原Series的数值
-append:添加元素
import numpy as np
from pandas import Series
dict_case = {'name':'zrh','age':20,'height':175,'wife':'yoona'}
s_case = Series(data=dict_case)
s_case
输出结果:

dict_case2={'money':520}
s_case2 = Series(data=dict_case2)
s_case2
输出结果:

s_case.append(s_case2) #返回新视图,原来的s_case数据没有改变
输出结果:

DataFrame
DataFrame是一个【表格型】的数据结构,DataFrame由按一定顺序排列的多列数据组成。
设计初衷是将Series的使用场景从一维拓展到多维,所以Series的各种常用方法在DF中也同样适用
DataFrame既有行索引,也有列索引
行索引:index
列索引:columns
值:values
列表创建、ndarray创建、字典创建
-列表创建
import numpy as np
import pandas as pd
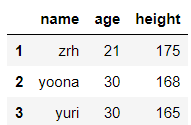
list_case = [['zrh',21,175],['yoona',30,168],['yuri',30,165]]
df = pd.DataFrame(data=list_case,columns=['name','age','height'],index=[1,2,3]) #注意DataFrame的两个大写字母
df
输出结果:
columns=表示指定列名
index=表示指定行索引名
-ndarray创建
import numpy as np
import pandas as pd
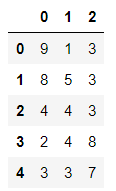
df = pd.DataFrame(data=np.random.randint(1,10,size=(5,3)))
df
输出结果:
-字典创建
再用字典创建DataFrame时,字典的键作为DF的列索引,字典的键对应的值成为该列索引下的值
import numpy as np
import pandas as pd
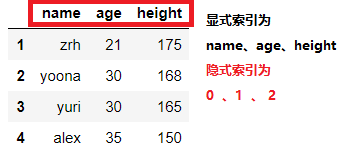
dict_case = {'name':['zrh','yoona','yuri','alex'],'age':[21,30,30,35],'height':[175,168,165,150]}
df = pd.DataFrame(data=dict_case,index=range(1,len(dict_case['name'])+1))
df
输出结果:

values、columns、index、shape
import numpy as np
import pandas as pd
dict_case = {'name':['zrh','yoona','yuri','alex'],'age':[21,30,30,35],'height':[175,168,165,150]}
df = pd.DataFrame(data=dict_case,index=range(1,len(dict_case['name'])+1))
df
输出结果:
df.shape #DF的形状
输出结果:(4, 3)
df.values #返回DF的值
输出结果:

df.index #返回DF的行索引
输出结果:RangeIndex(start=1, stop=5, step=1)
df.columns #返回DF的列索引
输出结果:Index(['name', 'age', 'height'], dtype='object')
import numpy as np
import pandas as pd
dict_case = {'name':['zrh','yoona','yuri','alex'],'age':[21,30,30,35],'height':[175,168,165,150]}
df = pd.DataFrame(data=dict_case,index=range(1,len(dict_case['name'])+1))
df
输出结果:
通过索引取值的两种方式:
iloc: 通过隐式索引取值
loc: 通过显示索引取值
输出结果:
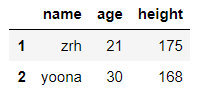
-取单列的简单方式
df取单列可以写成df['x'],表示取x列;但如果想要取某行某列或者多行多列,必须使用df.loc或者df.iloc
df.age #取DF的 age 这一列
输出结果:

df['name'] #取DF的 name 这一列
输出结果:

-索引详解
df.iloc[0] #通过隐式索引取第一行
输出结果:

df.loc[1] #通过显示索引取第一行
输出结果:

df.iloc[[0,2]] #通过隐式索引取第一行和第三行
输出结果:

df.loc[[1,2]] #通过显式索引取行索引为1和行索引为2的数据
输出结果:
df.iloc[1,0] #通过隐式索引取第二行第一列的数据
输出结果:'yoona'
df.loc[2,'name'] #通过显式索引取行索引为2,name列的数据
输出结果:'yoona'
DF的索引其实和Series的一模一样,只不过有两种模式,一种是iloc、一种是loc
在iloc模式下,使用的是每个元素对应的隐式索引的值进行取值
在loc模式下,使用的是每个元素对应的显式索引的值进行取值
DataFrame的切片操作
df.iloc[0:2] #通过隐式索引切前两行
输出结果:
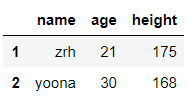
df.loc[1:2] #通过显示索引切前两行
输出结果:
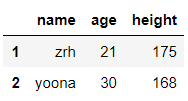
df.iloc[:,0:2] #通过隐式索引切前两列
输出结果:
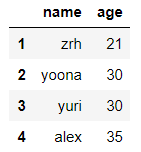
df.loc[:,'name':'age'] #通过显式索引切name列和age列
输出结果:
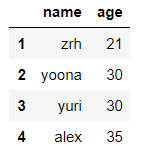
df.iloc[[0,2,3],[0,2]] #通过隐式索引取第一行、第三行、第四行的第一列和第三列的数据
输出结果:
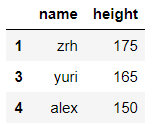
df.loc[[1,3,4],['name','height']] #通过显式索引取行索引值为1、3、4 列索引为name、height的数据
输出结果:
-层次化索引
层次化索引主要用于行索引有多列的情况下的取值
源数据展示:
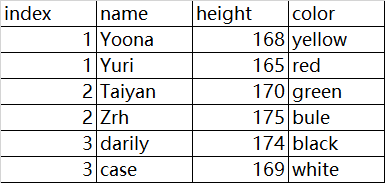
import numpy as np
import pandas as pd
df = pd.read_excel(r'F:datacase.xlsx',encoding='utf-8',sheet_name=0,index_col=[0,1])
df
index_col=[0,1] 表示以第一列和第二列共同作为行索引
sheet_name=0 表示读取第一张工作表的内容
输出结果:
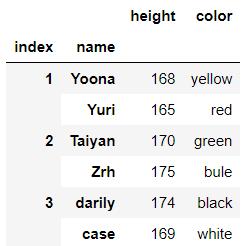
-层次化索引方式1:(使用元组方式)
df.loc[(1,'Yuri'),'height'] #取Yuri的height数据
返回结果:165
df.loc[(1,'Yuri'),:] #取Yuri的所有数据
输出结果:

df.loc[(1,['Yuri']),:] #给Yuri加上[]后,返回的是一个DF结构的数据,更方便读取
输出结果:

df.loc[(1,['Yoona','Yuri']),'color'] #取Yoona、Yuri对应的color列的值
输出结果:

df.loc[(1,['Yoona','Yuri']),['color']] #给color加上[]后,返回的是DF结构的结果
输出结果:

-层次化索引方式2:(使用连续取值的方式)
df.loc[1].loc['Yoona'] #第一步:先取行索引为1的所有值 第二步:再在取出来的基础上取'Yoona'对应的值
输出结果:

在第一步结束的时候,其结果已经是一个DF结构的数据,所以在其基础上取数据需要再.loc[]
使用df.rename函数,函数参数需要使用字典格式
df.rename函数可以选择“inplace=”参数,否则所有操作都是返回一个新的视图,不会对原数据有任何影响
import numpy as np
import pandas as pd
dict_case = {'name':['zrh','yoona','yuri','alex'],'age':[21,30,30,35],'height':[175,168,165,150]}
df = pd.DataFrame(data=dict_case,index=range(1,len(dict_case['name'])+1))
df
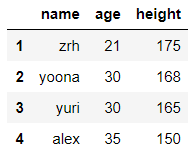
df.rename(index={1:'one',2:'two',3:'three',4:'four'},columns={'name':'名字','age':'年龄','height':'身高'})
add() 加、sub()减、 mul()乘、 div()除……
N个DF在计算时,是对应位置的元素进行计算
import numpy as np
import pandas as pd
df_1 = pd.DataFrame(data=np.random.randint(1,10,size=(3,2)),index=[1,2,3],columns=[1,2])
df_1
输出结果:
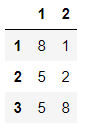
df_2 = pd.DataFrame(data=np.random.randint(1,10,size=(3,2)),index=[1,2,3],columns=[1,2])
df_2
输出结果:
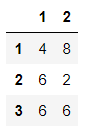
df_2+df_1 #也可以使用np.add(df_1,df_2)
输出结果:
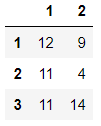
在索引不同时,返回NAN(与Series性质相同)
一次性产生多个汇总统计集合
数据部分展示:
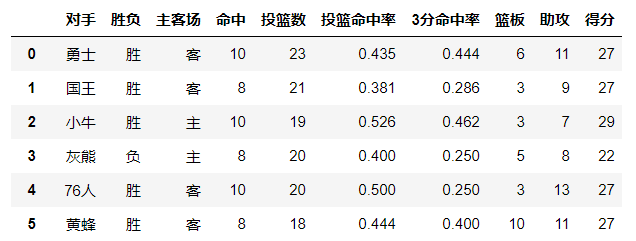
import numpy as np
import pandas as pd
data = pd.read_csv(r'F:dataasketball.csv',encoding='utf-8')
data.describe()
对于数值型数据:
count次数、mean平均值、std标准差、min最小值、25%四分之一位数、50%中位数、75%四分之三位数、max最大值
输出结果:
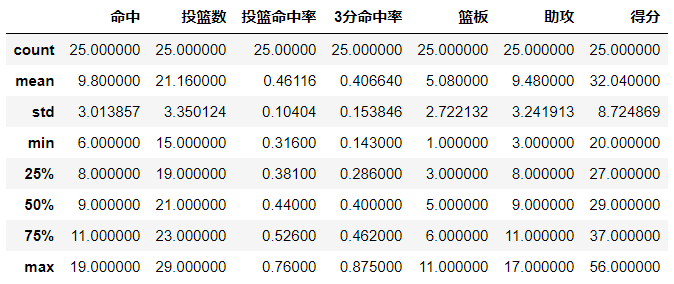
import numpy as np
import pandas as pd
data = pd.read_csv(r'F:datausa_election.txt',encoding='utf-8',dtype=str)
data.describe()
对于字符型数据:
输出结果:
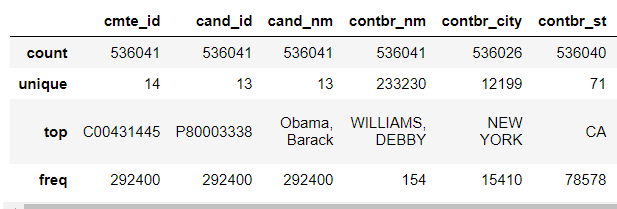
count次数、unique不重复值、top使用次数最多的字符串、frep对应top内容使用的次数
在对既有数值型数据还有字符串型数据的文件来说,在进行describe汇总统计集合时,可以选择参数:
df.describe(include='all') #将数值型、字符串型数据都进行统计
df.describe(include='object') #只对字符串型数据进行统计
df.describe() #默认值对数值型数据进行统计
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,20,size=(10,)))
df
输出结果:

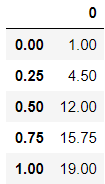
df.quantile([0,0.25,0.5,0.75,1]) #计算df的最小值、1/4位数、中位数、3/4位数、最大值
输出结果:
-时间类型转换:
使用:pd.to_datetime(col)
import numpy as np
import pandas as pd
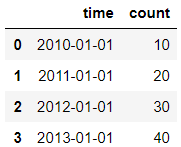
dict={'time':['2010-01-01','2011-01-01','2012-01-01','2013-01-01'],'count':[10,20,30,40]}
df = pd.DataFrame(data=dict)
df
输出结果:
df.time.dtype
输出结果:dtype('O')
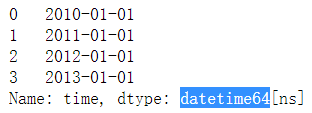
df['time']=pd.to_datetime(df['time'])
df['time']
输出结果:
-关于日期时间的其他N多操作:
import numpy as np
import pandas as pd
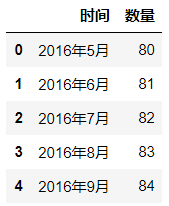
df = pd.read_csv(r'F:data ime.csv',encoding='gbk')
df.head()
输出结果:
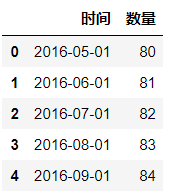
df['时间'] = pd.to_datetime(df['时间'],format='%Y-%m-%d',errors='coerce')
df.head()
format='%Y-%m-%d'表示修改时间格式
errors='coerce'表示错误值等于空
输出结果:
pd.datetime.today() #返回此时此刻的时间
输出结果:datetime.datetime(2020, 9, 19, 20, 0, 33, 399814)
df['相差天数']=pd.datetime.today()-df['时间']
df.head()
输出结果:
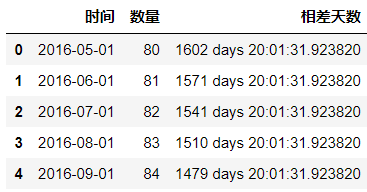
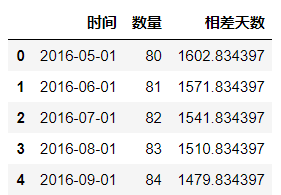
#修改相差天数的格式
df['相差天数']=df['相差天数']/np.timedelta64(1,'D')
#这里的1改为30就表示对于天数除以30,相当于计算多少个月 ; 除以365,相当于计算多少年
df.head()
输出结果:
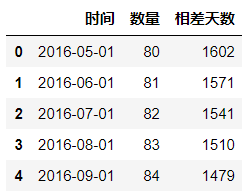
df['相差天数']=df['相差天数'].astype(int)
df.head()
输出结果:
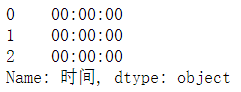
#取时间
df['时间'].dt.time.head(3)
输出结果:
#取日期
df['时间'].dt.date.head(3)
输出结果:

#取日期中的年
df['时间'].dt.year.head(3)
#取月将year改为month
输出结果:

使用df.set_index()
import numpy as np
import pandas as pd
dict={'time':['2010-01-01','2011-01-01','2012-01-01','2013-01-01'],'count':[10,20,30,40]}
df = pd.DataFrame(data=dict)
df
输出结果:
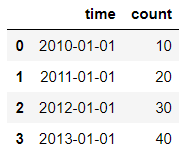
df.set_index('time',inplace=True) #z这里的time直接写,不加df['time']
df
输出结果:
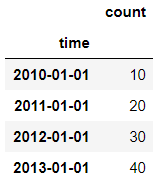
作用:apply()将一个函数作用于DataFrame中的每个行或者列
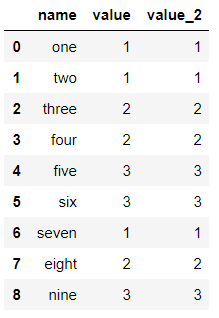
import pandas as pd import numpy as np list_case = [1,1,2,2,3,3,1,2,3] list_case2 = [1,1,2,2,3,3,1,2,3] name = ['one','two','three','four','five','six','seven','eight','nine'] df = pd.DataFrame(data={'name':name,'value':list_case,'value_2':list_case2}) df
输出结果:
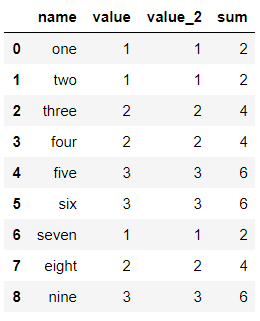
df['sum'] = df[['value','value_2']].apply(lambda x:np.sum(x),axis=1) df
输出结果:
apply函数替换字符串的操作
import numpy as np
import pandas as pd
dict_case={'name':['zrh','yoona','yuri'],'tel':[1501234567,1234567895,1541263548]}
df = pd.DataFrame(data=dict_case)
df['tel'] = df['tel'].astype(str)
df
输出结果:
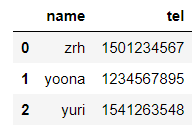
df['tel_case'] = df['tel'].apply(lambda x: x.replace(x[3:7],'****'))
df
输出结果:
用于随机抽样的函数
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,20,size=(9,5)))
df
输出结果:
df.sample(n=5,replace=False) #随机抽样,replace=False表示不放回抽样
输出结果:

n=5 表示随机抽取5行数据
对给定的参数进行连乘操作
import numpy as np
import pandas as pd
dict_case = {'name':['zrh','yoona','yuri'],'count':[5,9,6],'money':[10,50,15]}
df = pd.DataFrame(data=dict_case)
df
输出结果:
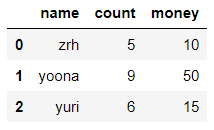
df[['count','money']].apply(np.prod,axis=1) #对给定的参数进行连乘操作
输出结果:
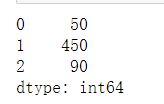
N日聚合函数,聚合方式可以自由选择,最常见的是求N日移动平均
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,10,size=(6,)))
df
输出结果:

df.rolling(3).mean() #计算3日移动平均
输出结果:
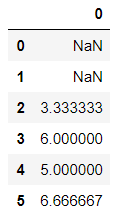
将对象向下平移N个单位,参数可正可负,经过移动空缺的数值使用NaN填充
数为正时向下移动、参数为负时参数向上移动
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,10,size=(6,)))
df
输出结果:

df.shift(1)
输出结果:

pct_change(x)函数,表示与同列上x个数字的变化率的结果,x默认为1
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,10,size=(6,)))
df
输出结果:
df.pct_change()
输出结果:
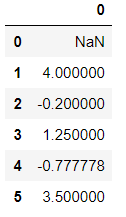
例如索引为1 的计算过程为 (5-1)/1=4
diff(n) 进行n阶差分操作
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,10,size=(6,)))
df
输出结果:

df['diff'] = df.diff(1)
df
输出结果:
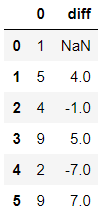
df.diff(n) 的实质就是 df-df.shift(n)
unique()是以数组形式(numpy.ndarray)返回列的所有唯一值(特征的所有唯一值)
nunique() Return number of unique elements in the object 即返回的是唯一值的个数
nunique的本质就是len(df['count'].unique())
unique表示去重、nunique表示查看去重后的个数
import numpy as np import pandas as pd df=pd.DataFrame(data={'count':list(np.random.randint(1,500,size=(20,)))}) df.head()
输出结果:

df['count'].unique() #返回列的所有唯一值
输出结果:

df['count'].nunique() #返回列的所有唯一值的个数
输出结果:19
len(df['count'].unique())
输出结果:19
对应的操作为:增加列数、删除列、调整列的顺序,修改元素的值
import numpy as np
import pandas as pd
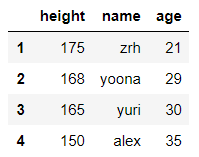
dict_case = {'name':['zrh','yoona','yuri','alex'],'age':[21,30,30,35],'height':[175,168,165,150]}
df = pd.DataFrame(data=dict_case,index=range(1,len(dict_case['name'])+1))
df
输出结果:
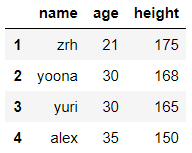
#增加列
df['增加列数']=1
df
输出结果:
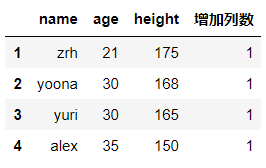
#删除列
df.drop(labels='增加列数',axis=1,inplace=True)
df
输出结果:
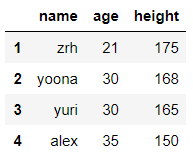
#调整列的顺序
data=df['height']
df.drop(labels='height',axis=1,inplace=True)
df.insert(0,'height',data) #0表示在第一列插入,第二个参数表示字段名,第三个参数表示数据源
df
输出结果:
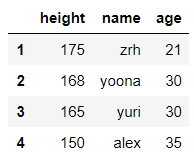
#修改元素的数值,改值的原理就是将值取出来重新赋值
df.loc[2,'age']=29
df
输出结果:
-排序操作
DataFrame的排序用到的函数:
-df.sort_index(axis=,inplace=)表示根据索引排序
axis=1,表示对列名进行排序
axis=0,表示对行索引进行排序
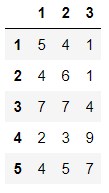
import pandas as pd import numpy as np df = pd.DataFrame(data=np.random.randint(1,10,size=(5,3)),columns=[2,1,3],index=[5,2,1,4,3]) df
输出结果:

df.sort_index(axis=1,inplace=True) #对列名进行排序,并应用到原数据上 df
输出结果:

df.sort_index(axis=0,inplace=True) #对行索引进行排序,并应用到原数据上 df
输出结果:
-df.sort_values(data,ascending=,na_position=,inplace=) 表示根据值排序
data表示排序的列
ascending=True 表示升序排列(Fasle表降序)
na_position= 表示缺失值显式的位置(first、last)
-df.reset_index(drop=,inplace=) 表示重置行索引
drop=True 表示删除原来的索引列
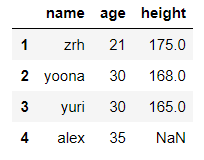
import numpy as np
import pandas as pd
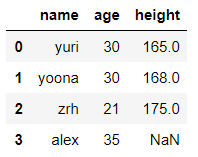
dict_case = {'name':['zrh','yoona','yuri','alex'],'age':[21,30,30,35],'height':[175,168,165,None]}
df = pd.DataFrame(data=dict_case,index=range(1,len(dict_case['name'])+1))
df
输出结果:
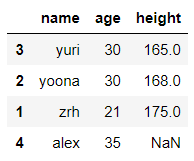
df.sort_values('height',ascending=True,na_position='last',inplace=True)
df
输出结果:
df.reset_index(drop=True,inplace=True)
df
输出结果:
-替换操作
替换操作可以同步作用于Series和DataFrame中,替换操作是批量的给元素重新复制的原理
单值替换:
普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
按列指定单值替换: to_replace={列标签:替换值} value='value'
-普通替换
import numpy as np
import pandas as pd
dict_case = {'name':['zrh','yoona','yuri','alex','yoona'],'age':[21,30,30,35,30],'height':[175,168,165,None,168]}
df = pd.DataFrame(data=dict_case,index=range(1,len(dict_case['name'])+1))
df
输出结果:
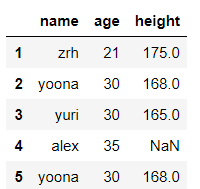
df.replace(to_replace=30,value='三十',inplace=False) #将 df 里的 30 替换成 三十
输出结果:
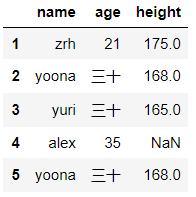
df.replace(to_replace={'yoona':'林允儿'},inplace=False) #将df里的yoona替换成林允儿
输出结果:
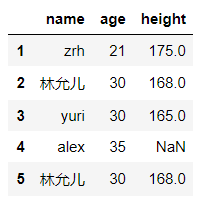
#将指定列的元素进行替换to_replace={列索引:被替换的值},value='替换值'
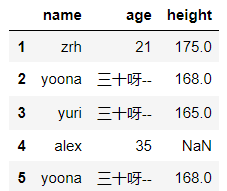
df.replace(to_replace={'age':30},value='三十呀--',inplace=False) #将 age 列的 30 全部替换成 三十呀--
输出结果:
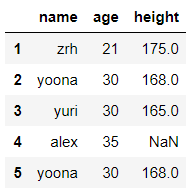
-多值替换
列表替换: to_replace=[] value=[]
字典替换(推荐) to_replace={to_replace:value,to_replace:value}
import numpy as np
import pandas as pd
dict_case = {'name':['zrh','yoona','yuri','alex','yoona'],'age':[21,30,30,35,30],'height':[175,168,165,None,168]}
df = pd.DataFrame(data=dict_case,index=range(1,len(dict_case['name'])+1))
df
输出结果:
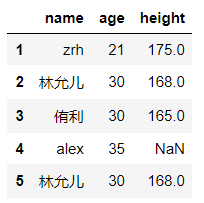
df.replace(to_replace=['yoona','yuri'],value=['林允儿','侑利'],inplace=False)
输出结果:
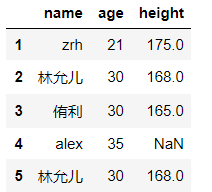
df.replace(to_replace={'yoona':'林允儿','yuri':'侑利'},inplace=False)
输出结果:
DateFrame的筛选与条件查询使用 query() 函数
DateFrame的筛选与条件查询的实质可以理解为利用布尔值为索引条件来取值
import numpy as np
import pandas as pd
dict_case={'area':['华南','华北','华东','东北','西北','西南'],'count':[3241,1660,1545,500,984,662],'product':['乒乓球','篮球','足球','橄榄球','台球','冰球']}
df = pd.DataFrame(data=dict_case)
df
输出结果:
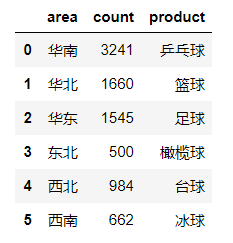
df[(df['count']>1000) & (df['area']=='华东')] #筛选 count>1000 并且 area是华东的数据
输出结果:

df.query('count>1000 & area=="华东"') #query函数里需要用单引号包裹,如果条件等于的结果是字符串则需要使用双引号
输出结果:

-between的用法
df['count'].between(500,1660,inclusive=True) #nclusive表示是否包括边界(即500、1660)
输出结果:

df[df['count'].between(500,1660,inclusive=True)] #将布尔值作为索引条件进行取值
输出结果:

有两种类型的丢失数据:None、np.nan(NaN)
import numpy as np
import pandas as pd
type(None)
输出结果:NoneType
type(np.NaN) #可以使用numpy模块创建NaN空值
输出结果:float
由此可见:
None类型的空值是一个对象型数据、NaN类型的空值是一个float型数据
NAN可以参与运算的、None是不可以参与运算
数据分析中会常常使用某些形式的运算来处理原始数据,如果原数数据中的空值为NAN的形式,则不会干扰或者中断运算
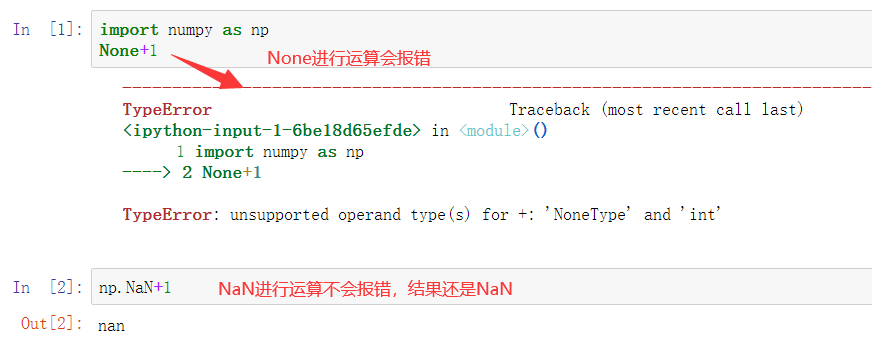
在pandas中如果遇到了None形式的空值则pandas会将其强转成NAN的形式
pandas在处理空值操作时用到的函数:isnull、notnull、any、all、dropna、fillna
-方式1:
对空值进行过滤(删除空所在的行数据)
使用到的函数:isnull,notnull,any,all
-使用 isnull ---> any 实现的空值过滤
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,20,size=(5,3)),index=[1,2,3,4,5],columns=[1,2,3])
df.loc[1,1]=np.NaN
df.loc[3,2]=None
df.loc[4,1]=np.NaN
df
输出结果:
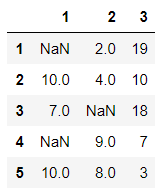
df.isnull():判断对象是否为空,为空则返回True
any(axis=1):any作用到的df中的该行中有一个True,则返回True
any作用到的df中该行全部为False,才返回False
df.isnull().any(axis=1) #判断df的每一行是否存在空值
输出结果:

df[~(df.isnull().any(axis=1))]
#将布尔值取反之后作为索引条件,可以返回不为空的数据,实现了控制的过滤,不过返回的是一个新的视图,对原df的数据没有影响
输出结果:
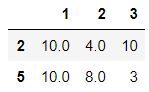
-使用 notnull--> all 实现的空值过滤
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,20,size=(5,3)),index=[1,2,3,4,5],columns=[1,2,3])
df.loc[1,1]=np.NaN
df.loc[3,2]=None
df.loc[4,1]=np.NaN
df
输出结果:
df.notnull():判断对象是否不为空,不为空则返回True
all(axis=1):all作用到的df中的该行中有一个元素为空值,则返回False
any作用到的df中的该行中所有元素都不为空时,才返回True
df.notnull().all(axis=1) #判断df的每一行的元素是否不为空,没有空值返回True,存在空值返回False
输出结果:

df[df.notnull().all(axis=1)]
#将布尔值取反之后作为索引条件,可以返回不为空的数据,实现了空值的过滤,不过返回的是一个新的视图,对原df的数据没有影响
输出结果:
-方式2:
dropna:可以直接将含有缺失值的行或列进行删除
dropna(subset=,how=,axis=,inplace=)
subset= 表示根据指定的字段名进行删除,指定的字段名下的数值为NaN,才删除该行
how= 表示删除的模式(any、all)
-how='any' 表示每行如果有一个空值,就删除该行
-how='all' 表示一行里面所有的元素都是空值,才删除该行
axis= 在drop语句下 axis=1 表示列,axis=0 表示行
inplace= 表示是否应用到原数据上
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,20,size=(7,5)),index=[1,2,3,4,5,6,7],columns=['one','two','three','four','five'])
df.loc[1,'one']=np.NaN
df.loc[2,'two']=None
df.loc[4,'four']=np.NaN
df.loc[5,['three','four']]=np.nan
df.loc[7,:]=None
df
输出结果:
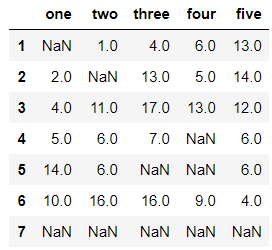
df.dropna(axis=0) #每一行存在空值就删除该行
输出结果:
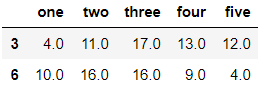
df.dropna(how='all',axis=0) #每一行的元素都为空值时才删除该行
输出结果:

df.dropna(subset=['three','four'],how='all',axis=0) #df中的three、four列都为空值时,才删除该行
输出结果:
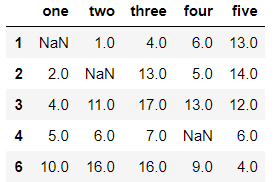
-方式3.
fillna:对缺失值进行覆盖
在所有的fillna语句下可以选择“inplace=”参数,否则所有操作都是返回一个新的视图,不会对原数据有任何影响
df.fillna(value=x) #使用指定的值填充空值
#使用空值的近邻值填充空值
df.fillna(method='ffill',axis=0)
#ffill向前填充、bfill向后填充、axis=0表示列,1表示行
在df.fillna(value=x)的模式下,x可以为某一列的众数、中位数等,也可以是一个字典
如果是一个字典,就表示对每列进行不同的填值方式
import numpy as np
import pandas as pd
df = pd.DataFrame(data=np.random.randint(1,20,size=(7,5)),index=[1,2,3,4,5,6,7],columns=['one','two','three','four','five'])
df.loc[1,'one']=np.NaN
df.loc[2,'two']=None
df.loc[4,'four']=np.NaN
df.loc[5,['three','four']]=np.nan
df.loc[7,:]=None
df
输出结果:
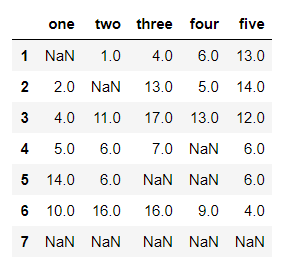
df.fillna(value='填充空值')
输出结果:
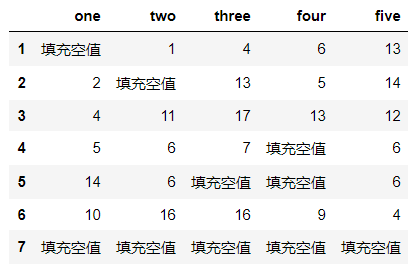
df.four.fillna(value=df['four'].mode()[0]) #对four列中的空值使用four例的众数进行填充
#因为众数有时候可能不是一个,所以需要在mode()后面加[O]
输出结果:

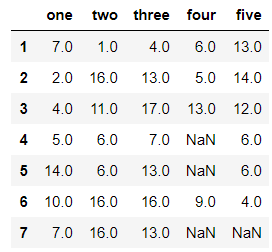
df.fillna(value={'one':df['one'].mean(),'two':df['two'].max(),'three':df['three'].median()},inplace=True)
df #对one列使用one列的平均值填充空值、对two列使用two列的最大值填充空值、对于three列使用three列的中位数填充空值,其他列不填充
输出结果:
-df.drop_duplicates
df.drop_duplicates(subset=,keep=,inplace=)
subset= 表示根据指定的列进行重复值的查询
keep='first'表示保留重复值的第一行 keep='last'表示保留重复值的最后一行、keep=False表示删除所有重复值
在df.drop_duplicates的函数中可以选择“inplace=”参数,否则所有操作都是返回一个新的视图,不会对原数据有任何影响
import numpy as np
import pandas as pd
#创建含有重复数据的df
df = pd.DataFrame(data=np.random.randint(0,100,size=(7,4)))
df.iloc[1] = [6,6,6,6]
df.iloc[4] = [6,6,6,6]
df.iloc[6] = [6,6,6,6]
df
输出结果:
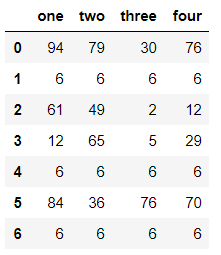
df.drop_duplicates(keep='first')
#keep='first'表示保留重复值的第一行 keep='last'表示保留重复值的最后一行、keep=False表示删除所有重复值
输出结果:
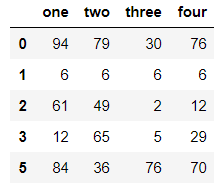
df.drop_duplicates(subset=['one','three'],keep='first') #根据one列、three列删除重复的值,并保留第一行重复值
输出结果:

-df.duplicated(subset=)
duplicated只是根据指定的列查看是否有重复值,返回的是布尔值,只是查看,并不会删除
subset= 表示根据指定的列进行重复值的查询
df.duplicated() #对所有列进行查重,结果代表索引为4、6的那一行有重复值
输出结果:

np.sum(df.duplicated()) #可以使用sum查看重复值的个数
输出结果:2
对异常值进行清洗必须要有一个判定异常值的条件,根据条件去做判断,将满足条件所对应的行数据删除即可
一般常见的判断条件为 数据大于其自身的两倍标准差、使用箱线图的方法处理异常数据
import numpy as np
import pandas as pd
#自定义一个1000行3列(A,B,C)取值范围为0-1的数据源,然后将C列中的值大于其两倍标准差的异常值进行清洗
df = pd.DataFrame(data=np.random.random(size=(1000,3)),columns=['A','B','C'])
df.head()
输出结果:
#判定异常值的条件:C列中的数据大于C列的两倍标准差,则该数据为异常数据
std_twice = df['C'].std() * 2
df['C'] > std_twice #返回的是布尔值
df.loc[~(df['C'] > std_twice)] #将布尔值作为索引条件
输出结果:
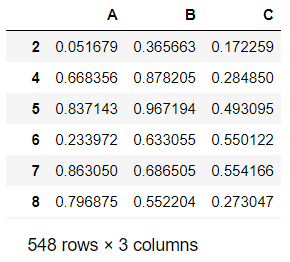
可以看到数据已经从1000行的量级变成了548行的量级,这就实现了异常值的清理
数据的分段:
pd.cut(x,bins=,right=,labels=)
cut的x参数:数据
cut的bins函数:相当于分组的依据
cut的right函数:bool型参数,默认为True,表示是否包含区间右部。比如如果bins=[1,2,3],right=True,则区间为(1,2],(2,3];right=False,则区间为(1,2),(2,3)
cut的labels参数:为分组依据打上标签
import numpy as np import pandas as pd df=pd.DataFrame(data={'count':list(np.random.randint(1,500,size=(200,)))}) df.head()
输出结果:

bins=[0,100,200,300,400,500] pd.cut(df['count'],bins=bins,right=True).head() #这样就会将count列根据我们设置的bins分段 (0, 100] 、(100, 200] 、 (200, 300] 、 (300, 400] 、 (400, 500]
输出结果:
#我们还可以为分段后的内容打上标签,比如(0,100]表示第一部分,(100,200]表示第二部分…… bins=[0,100,200,300,400,500] df['cut'] = pd.cut(df['count'],bins=bins,right=True,labels=['第一部分','第二部分','第三部分','第四部分','第五部分']) df.head()
输出结果:
-等宽分段
将数据分成N段,每段的长度相同
import numpy as np
import pandas as pd
df=pd.DataFrame(data={'year':range(1800,2020,1),'count':list(np.random.randint(10,500,size=(220,)))})
df.head()
输出结果:
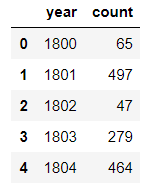
pd.cut(df['count'],5).value_counts() #将count等宽分成5段
输出结果:

等宽分段的含义:

pd.cut(df['count'],5,labels=[1,2,3,4,5]).value_counts() #labels可以为行索引起分段名称
输出结果:

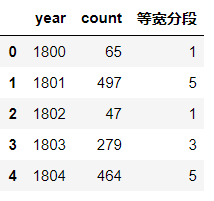
df['等宽分段'] = pd.cut(df['count'],5,labels=[1,2,3,4,5])
df.head()
输出结果:
-等频分段
等频分段相当于将数据分成百分比的分段方式
import numpy as np
import pandas as pd
df=pd.DataFrame(data={'year':range(1800,2020,1),'count':list(np.random.randint(10,500,size=(220,)))})
df.head()
输出结果:

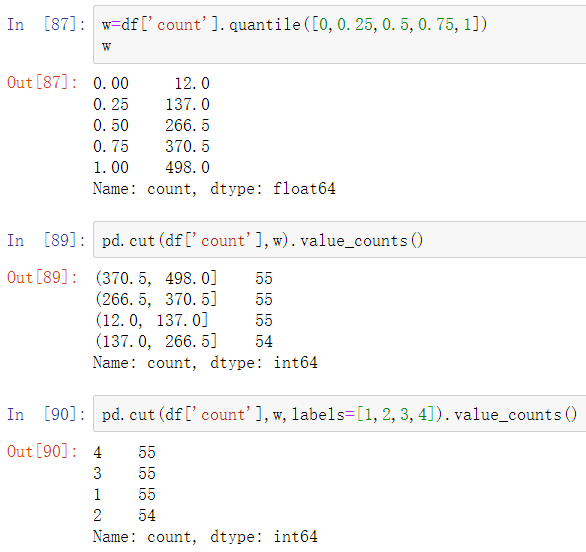
w=[0,0.25,0.5,0.75,1]
pd.qcut(df['count'],w).value_counts()
#w表示分成四段0-25%、25%-50%、50%-75%、75%-1
输出结果:

等频分段的意义:

w=[0,0.25,0.5,0.75,1]
pd.qcut(df['count'],w,labels=[1,2,3,4]).value_counts()
输出结果:

-使用cut也可以进行等频分段
import numpy as np
import pandas as pd
df=pd.DataFrame(data={'year':range(1800,2020,1),'count':list(np.random.randint(10,500,size=(220,)))})
df.head()
输出结果:
原理就是利用quantile函数计算出将要分段的各个位置对应的数值,然后将这数值作为cut分段的依据
pd.concat、pd.append
pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
axis=0
join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联
-匹配级联
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
df1 = DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','B','C'])
df2 = DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','D','C'])
pd.concat((df1,df2),axis=1)
输出结果:

-不匹配级联
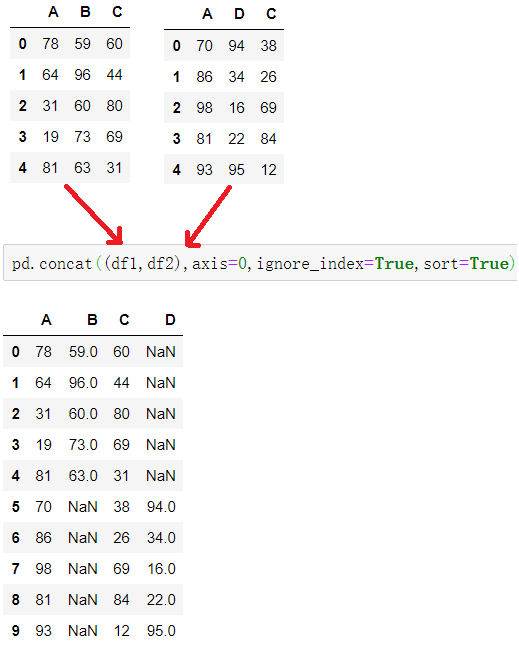
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
pd.concat((df1,df2),axis=,ignore_index=,sort=)
ignore_index=True 为重置索引
sort=True 为忽略索引不匹配产生的警告
不匹配级联有2种连接方式:
外连接 join=outer:补NaN(默认模式)
内连接 join=inner:只连接匹配的项
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
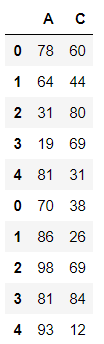
df1 = DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','B','C'])
df2 = DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','D','C'])
pd.concat((df1,df2),axis=0,ignore_index=True,sort=True) #索引不一致的对于列的级联操作,默认join='outer',ort=True表示忽略列数不匹配弹出的警告
输出结果:
pd.concat((df1,df2),axis=0,join='inner')
输出结果:
合并操作需要使用pd.merge()函数
merge与concat的区别在于,merge需要依据某一共同列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
注意每一列元素的顺序不要求一致,pandas合并操作默认的模式为 how=inner

一对一合并
import pandas as pd
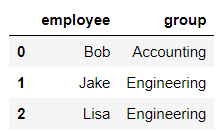
df1 = pd.DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
})
df1
输出结果:
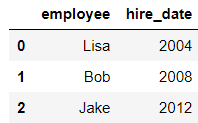
df2 = pd.DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
})
df2
输出结果:
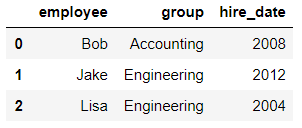
pd.merge(df1,df2,on='employee')
输出结果:
一对多合并
import pandas as pd
df3 = pd.DataFrame({
'employee':['Lisa','Jake'],
'group':['Accounting','Engineering'],
'hire_date':[2004,2016]})
df3
输出结果:

df4 = pd.DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
df4
输出结果:
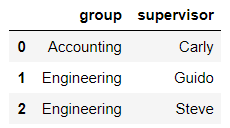
pd.merge(df3,df4) #on不写,默认的合并条件就是两张表中公有的列索引
输出结果:
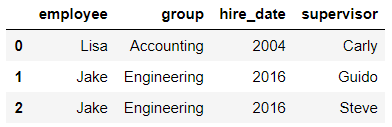
多对多合并
import pandas as pd
df1 = pd.DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df1
输出结果:
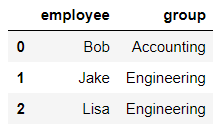
df5 = pd.DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
df5
输出结果:

pd.merge(df1,df5,how='outer')
输出结果:
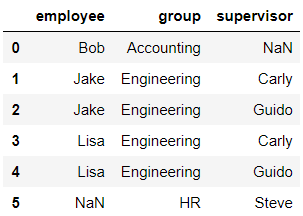
pd.merge(df1,df5,how='left')
输出结果:
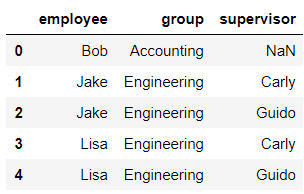
pd.merge(df1,df5,how='right')
输出结果:
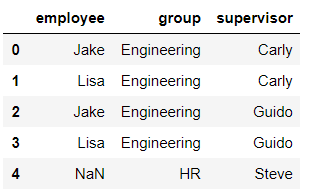
-key的规范化
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key
import pandas as pd
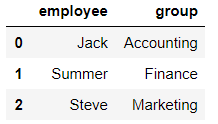
df1 = pd.DataFrame({'employee':['Jack',"Summer","Steve"],
'group':['Accounting','Finance','Marketing']})
df1
输出结果:
df2 = pd.DataFrame({'employee':['Jack','Bob',"Jake"],
'hire_date':[2003,2009,2012],
'group':['Accounting','sell','ceo']})
df2
输出结果:
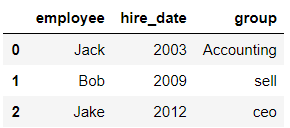
pd.merge(df1,df2,on='group')
输出结果:

当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列:
import pandas as pd
df1 = pd.DataFrame({'employee':['Bobs','Linda','Bill'],
'group':['Accounting','Product','Marketing'],
'hire_date':[1998,2017,2018]})
df1
输出结果:
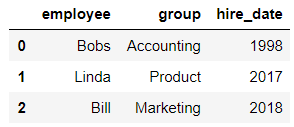
df5 = pd.DataFrame({'name':['Lisa','Bobs','Bill'],
'hire_dates':[1998,2016,2007]})
df5
输出结果:
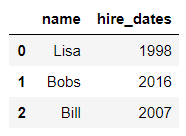
pd.merge(df1,df5,left_on='employee',right_on='name') #将df1的employee列和df5的name列合并
输出结果:
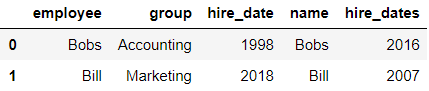
-映射操作
实质就是给一个元素值提供不同的表现形式
概念:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定
创建映射关系表时需要用到 map函数 和 字典
import numpy as np
import pandas as pd
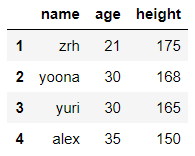
dict_case = {'name':['zrh','yoona','yuri','alex'],'age':[21,30,30,35],'height':[175,168,165,150]}
df = pd.DataFrame(data=dict_case,index=range(1,len(dict_case['name'])+1))
df
输出结果:
#利用字段创建映射关系表
dict_case={
'zrh':'CEO',
'yoona':'CFO',
'yuri':'员工',
'alex':'保安'
}
df['映射']=df['name'].map(dict_case) #在数组中创添加“映射”列,map只能被series调用,这里的df['name']返回的就是一个series
df
输出结果:
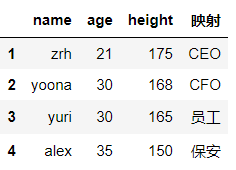
map可以当作运算工具来使用
lise_case = [1,2,3,4]
result = map(lambda x:x**2,lise_case)
print(list(result)) #结果:[1, 4, 9, 16]
-排序实现的随机抽样
df.take(参数,axis=):此方法的作用是根据所给参数将原数据进行打乱,take中的axis参数用法和drop函数一样,axis=1表示列,axis=0表示行
np.random.permutation(X):此方法的作用是生成0到X-1个乱序的随机序列
import numpy as np
import pandas as pd
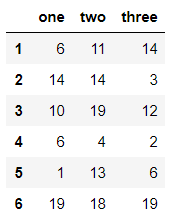
df = pd.DataFrame(data=np.random.randint(1,20,size=(6,3)),index=[1,2,3,4,5,6],columns=['one','two','three'])
df
输出结果:
np.random.permutation(5) #生成0-4的乱序数
输出结果:array([2, 4, 0, 1, 3])
#根据乱序数取值,达到随机抽样的效果
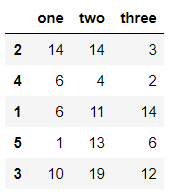
df.take(np.random.permutation(5),axis=0) #take的第一个参数建议传隐式索引,因为隐式索引可以通过乱序序列生成
输出结果:
随机抽样还可以使用sample函数,详情请点击这里
数据的分类处理相当于MySQL中的分组操作
数据分类用到的函数:groupby()函数
-数据分类
import numpy as np
import pandas as pd
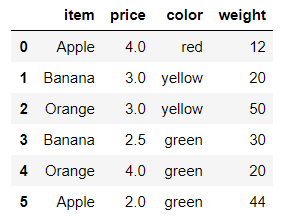
df = pd.DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})
df
-分组聚合
import numpy as np
import pandas as pd
df = pd.DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})
df
输出结果:
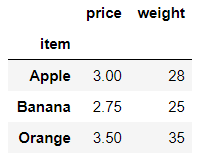
df.groupby(by='item').mean() #不添加指定列的话,会默认会将所有数值型的字段进行平均计算
输出结果:
df.groupby(by='item')['price'].mean() #计算每一种水果的平均价格
输出结果:

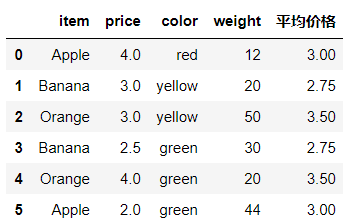
dict_case=df.groupby(by='item')['price'].mean().to_dict() #转化为字典
dict_case
输出结果:{'Apple': 3.0, 'Banana': 2.75, 'Orange': 3.5}
df['平均价格']=df['item'].map(dict_case) #使用映射将平均价格加入到df中
df
输出结果:
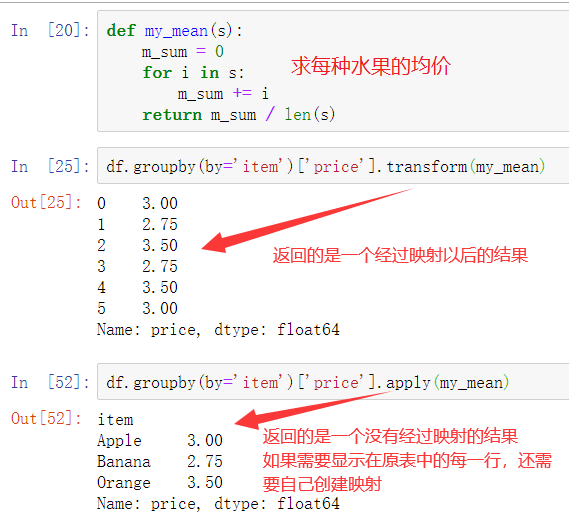
-高级数据聚合
agg:agg方法灵活,能够对分组对象进行相同的聚合,还可以选择不同的聚合方法
apply: apply可以进行聚合计算,还可以按行计算
transform:返回与数据同样长度的行,无法进行聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
transform和apply都会进行运算,在transform或者apply中传入函数即可,transform和apply也可以传入一个lambda表达式
建议:建议今后在更多使用apply或者agg
import numpy as np
import pandas as pd
df = pd.read_csv(r'F:dataasketball.csv')
df.head()
输出结果:

df[['主客场','命中','投篮数','得分']].groupby(by='主客场').agg({'命中':np.mean,'投篮数':np.sum,'得分':np.median})
#对“命中”进行mean聚合,对“投篮数”进行sum聚合,对“得分”进行median聚合
输出结果:

df[['主客场','命中']].groupby(by='主客场').agg({'命中':[np.mean,np.sum]})
#对命中即进行mean聚合,又进行sum聚合
输出结果:

如果分组之后要进行聚合的操作,并且其聚合的操作比较特殊,是在pandas中没有封装的函数
那么只能自己封装聚合操作,自己封装的聚合操作一定要作用在transform或者apply中
输出结果:
数据加载的参数:
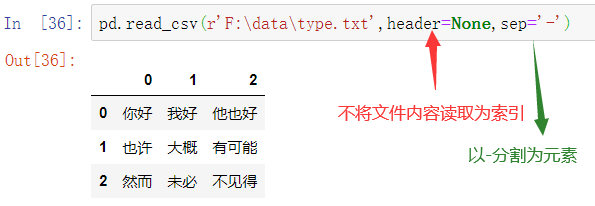
pd.read_csv(r'F:data ype.txt',header=.sep=,nrows=,na_values=)
header=None 表示不将文件内容读取为索引
sep=’-‘ 表示以 - 分割元素
nrows=3 表示只读取前3行
na_values=170 表示将170读取为NaN空值
type.txt文件原内容如下:

import numpy as np
import pandas as pd
df = pd.read_csv(r'F:data ype.txt')
df
输出结果:

df.shape #输出DF的形状,结果为(2,1)
发现其将文件的第一行内容作为了列索引,其形状显示为两行一列
我们希望将文件中每一个词(以-分割)作为元素存放在DataFrame中
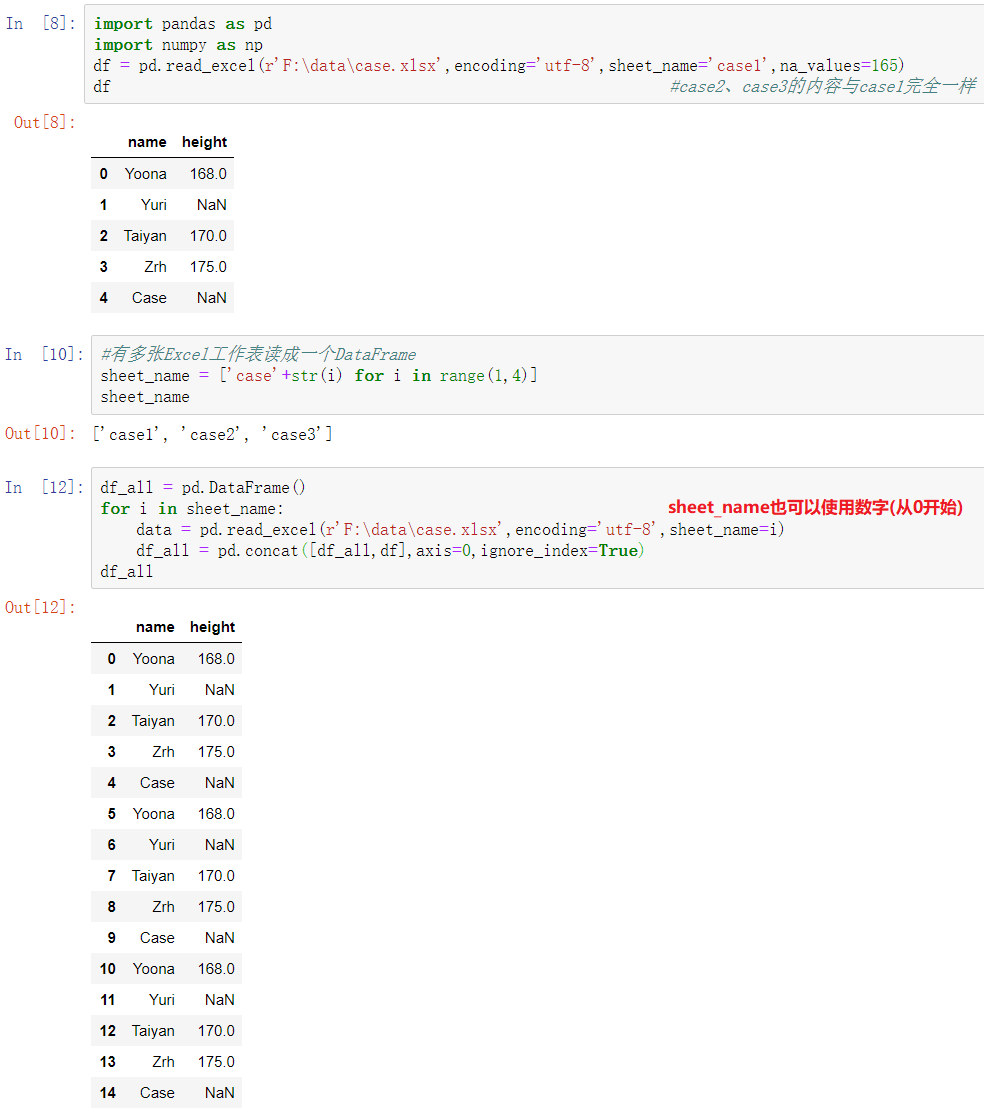
-合并excel文件的多个工作表为一个DataFrame
此方法前提是多张excel文件的列索引等完全相同
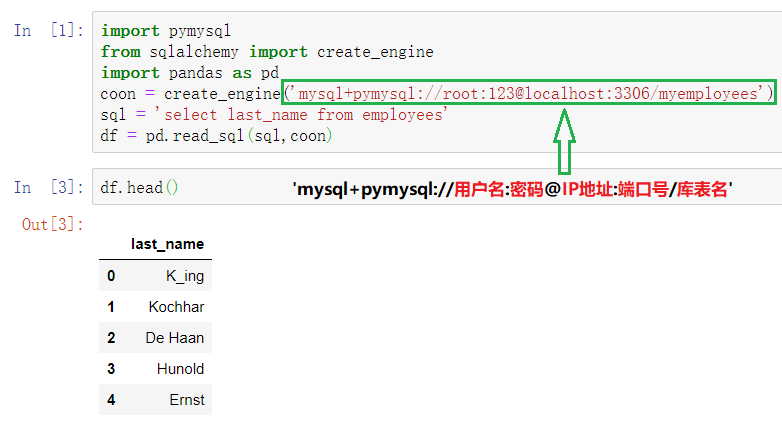
-连接数据库文件
import pymysql
from sqlalchemy import create_engine
import pandas as pd
coon = create_engine('mysql+pymysql://root:123@localhost:3306/myemployees')
sql = 'select last_name from employees'
df = pd.read_sql(sql,coon)
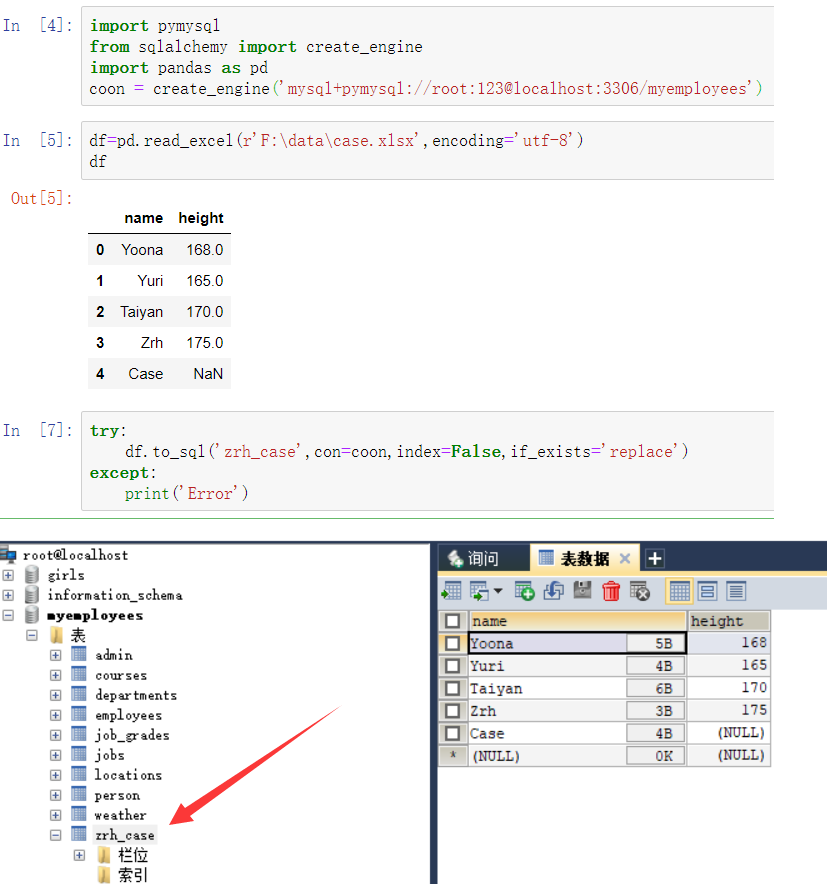
将数据保存到数据库中:
透视表是一种可以对数据动态排布并且分类汇总的表格格式
大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table
pivot_table的重要参数:
lndex :行分组键
columns:列分组键
values:分组的字段,只能为数值型变量
aggfunc:聚合函数
margins:是否需要总计
import numpy as np
import pandas as pd
df = pd.read_csv(r'F:dataasketball.csv')
df.head()
输出结果:
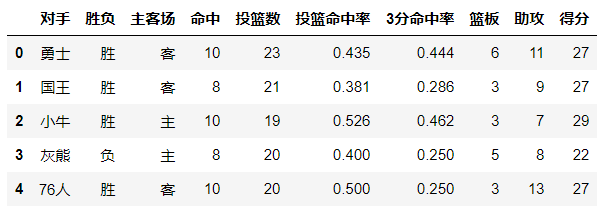
-index参数:分类汇总的分类条件
每个pivot_table必须拥有一个index。如果想查看哈登对阵每个队伍的得分则需要对每一个队进行分类并计算其各类得分的平均值
例如想看看哈登对阵同一对手在不同主客场下的数据,分类条件则为对手和主客场:
df.pivot_table(index=['对手','主客场']).head(8)
输出结果:
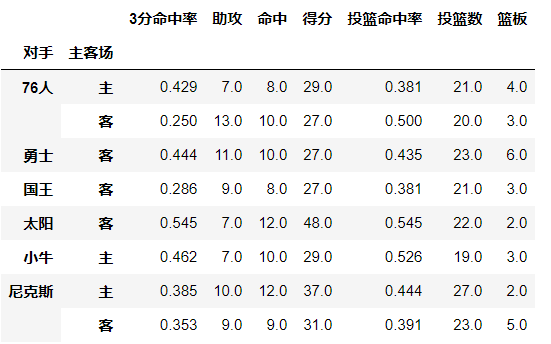
-values参数:对计算的数据进行筛选(values只能为数值型变量)
如果我们只需要哈登在主客场和不同胜负情况下的得分、篮板与助攻三项数据:
df.pivot_table(index=['主客场','胜负'],values=['助攻','得分','篮板'])
输出结果:
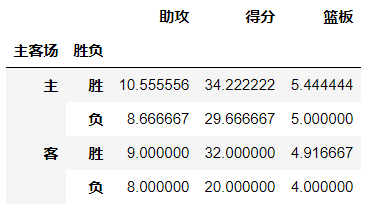
-aggfunc参数:设置我们对数据聚合时进行的函数操作
当我们未设置aggfunc时,它默认aggfunc='mean'计算均值。
例如:我们想获得哈登在主客场和不同胜负情况下的总得分、总篮板、总助攻时:
df.pivot_table(index=['主客场','胜负'],values=['助攻','得分','篮板'],aggfunc=np.sum)
输出结果:
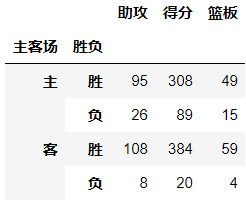
-columns:可以设置列层次字段,是对values字段进行分类
作用:可以在已有分类的基础上,对Values再次进行一个细致的分类

-margins参数
margins表示是否显示合计,margins_name表示合计列的名字
注意:margins合计的方式也是aggfunc决定的
df.pivot_table(index='主客场',columns='胜负',values=['助攻','得分','篮板'],aggfunc=np.sum,margins=True,margins_name='合计')
输出结果:
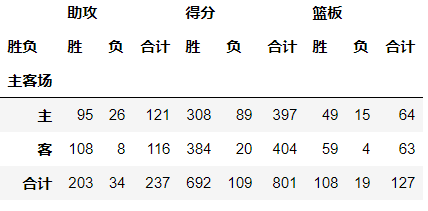
是一种用于计算分组的特殊透视图,对数据进行汇总
pd.crosstab(index,colums)
index:分组数据,交叉表的行索引
columns:交叉表的列索引
import numpy as np
import pandas as pd
import pandas as pd
from pandas import DataFrame
df = DataFrame({'sex':['man','man','women','women','man','women','man','women','women'],
'age':[15,23,25,17,35,57,24,31,22],
'smoke':[True,False,False,True,True,False,False,True,False],
'height':[168,179,181,166,173,178,188,190,160]})
df
输出结果:
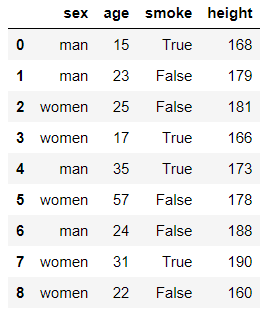
#求各个性别抽烟人数
pd.crosstab(index=df['sex'],columns=df['smoke'])
输出结果:

#求各个年龄段抽烟人数
df_case = pd.crosstab(index=df['age'],columns=df['smoke'])
df_case
输出结果:

修改一下格式:
df_case = pd.crosstab(index=df['age'],columns=df['smoke']) df_case.drop(labels=False,axis=1,inplace=True) df_case.rename(columns={True:'抽烟人数'},inplace=True) df_case
注意:布尔值不能加引号
输出结果:
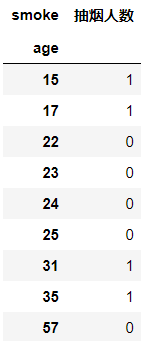
交叉表一般用于计算频数,或者频率,上面已经介绍了计算频数,下面介绍计算频率
-计算频率
import numpy as np
import pandas as pd
import pandas as pd
from pandas import DataFrame
df = DataFrame({'sex':['man','man','women','women','man','women','man','women','women'],
'age':[15,23,25,17,35,57,24,31,22],
'smoke':[True,False,False,True,True,False,False,True,False],
'height':[168,179,181,166,173,178,188,190,160]})
df
输出结果:
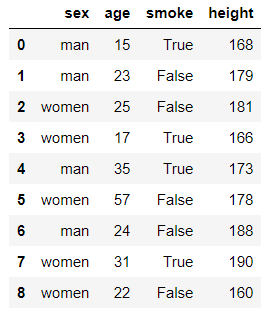
pd.crosstab(index=df['sex'],columns=df['smoke'],margins=True) #margins=True表示计算总计
输出结果:
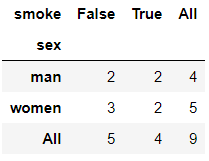
pd.crosstab(index=df['sex'],columns=df['smoke'],normalize='all') #normalize='all’表示每一个元素相对于总数的频率,总数为9
输出结果:
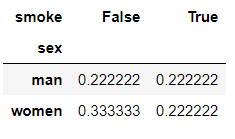
pd.crosstab(index=df['sex'],columns=df['smoke'],normalize='index') #normalize='index'表示每一个元素相对于每一行的总数的频率
输出结果:
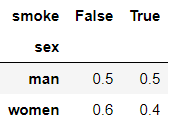
pd.crosstab(index=df['sex'],columns=df['smoke'],normalize='columns') #normalize='columns'表示每一个元素相对于每一列的总数的频率
输出结果:
