控制器选举
Kafka 当前选举控制器的规则是:Kafka 集群中第一个启动的 broker 通过在 ZooKeeper 里创建一个临时节点 /controller 让自己成为 controller 控制器。其他 broker 在启动时也会尝试创建这个节点,但是由于这个节点已存在,所以后面想要创建 /controller 节点时就会收到一个 节点已存在 的异常。然后其他 broker 会在这个控制器上注册一个 ZooKeeper 的 watch 对象,/controller 节点发生变化时,其他 broker 就会收到节点变更通知。这种方式可以确保只有一个控制器存在。那么只有单独的节点一定是有个问题的,那就是单点问题。
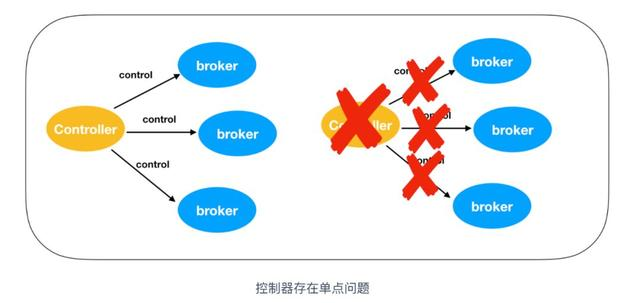
如果控制器关闭或者与 ZooKeeper 断开链接,ZooKeeper 上的临时节点就会消失。集群中的其他节点收到 watch 对象发送控制器下线的消息后,其他 broker 节点都会尝试让自己去成为新的控制器。其他节点的创建规则和第一个节点的创建原则一致,都是第一个在 ZooKeeper 里成功创建控制器节点的 broker 会成为新的控制器,那么其他节点就会收到节点已存在的异常,然后在新的控制器节点上再次创建 watch 对象进行监听。
控制器作用
Kafka 被设计为一种模拟状态机的多线程控制器,它可以作用有下面这几点
- 主题管理 : Kafka Controller 可以帮助我们完成对 Kafka 主题创建、删除和增加分区的操作,简而言之就是对分区拥有最高行使权。
- 换句话说,当我们执行kafka-topics 脚本时,大部分的后台工作都是控制器来完成的。
- 分区重分配: 分区重分配主要是指,kafka-reassign-partitions 脚本提供的对已有主题分区进行细粒度的分配功能。这部分功能也是控制器实现的。
- Prefered 领导者选举 : Preferred 领导者选举主要是 Kafka 为了避免部分 Broker 负载过重而提供的一种换 Leader 的方案。
- 集群成员管理: 主要管理 新增 broker、broker 关闭、broker 宕机
- 数据服务: 控制器的最后一大类工作,就是向其他 broker 提供数据服务。控制器上保存了最全的集群元数据信息,其他所有 broker 会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据。
Broker Controller数据存储
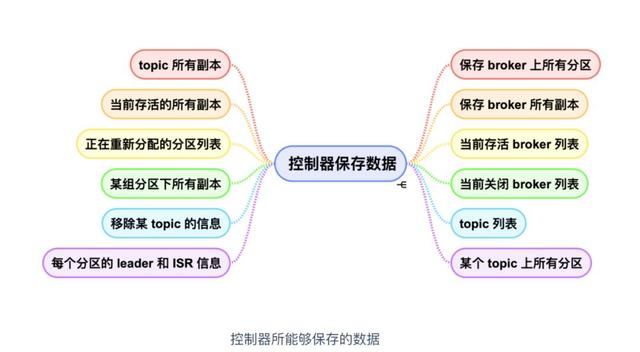
- roker 上的所有信息,包括 broker 中的所有分区,broker 所有分区副本,当前都有哪些运行中的 broker,哪些正在关闭中的 broker 。
- 所有主题信息,包括具体的分区信息,比如领导者副本是谁,ISR 集合中有哪些副本等。
- 所有涉及运维任务的分区。包括当前正在进行 Preferred 领导者选举以及分区重分配的分区列表。
Kafka 是离不开 ZooKeeper的,所以这些数据信息在 ZooKeeper 中也保存了一份。每当控制器初始化时,它都会从 ZooKeeper 上读取对应的元数据并填充到自己的缓存中。
Broker Controller故障转移
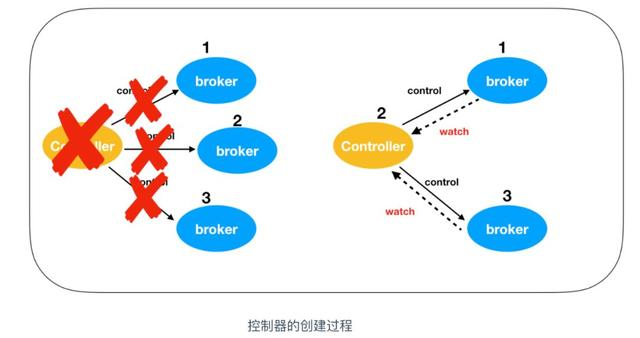
第一个在 ZooKeeper 中的 /brokers/ids下创建节点的 broker 作为 broker controller,也就是说 broker controller 只有一个,那么必然会存在单点失效问题。kafka 为考虑到这种情况提供了故障转移功能,也就是 Fail Over。

最一开始,broker1 会抢先注册成功成为 controller,然后由于网络抖动或者其他原因致使 broker1 掉线,ZooKeeper 通过 Watch 机制觉察到 broker1 的掉线,之后所有存活的 brokers 开始竞争成为 controller,这时 broker3 抢先注册成功,此时 ZooKeeper 存储的 controller 信息由 broker1 -> broker3,之后,broker3 会从 ZooKeeper 中读取元数据信息,并初始化到自己的缓存中。
Broker Controller存在问题
- controller 状态的更改由不同的监听器并发执行,因此需要进行很复杂的同步,并且容易出错而且难以调试。
状态传播不同步,broker 可能在时间不确定的情况下出现多种状态,这会导致不必要的额外的数据丢失。 - controller 控制器还会为主题删除创建额外的 I/O 线程,导致性能损耗。
- controller 的多线程设计还会访问共享数据,我们知道,多线程访问共享数据是线程同步最麻烦的地方,为了保护数据安全性,控制器不得不在代码中大量使用ReentrantLock 同步机制,这就进一步拖慢了整个控制器的处理速度。
Broker Controller内部设计原理
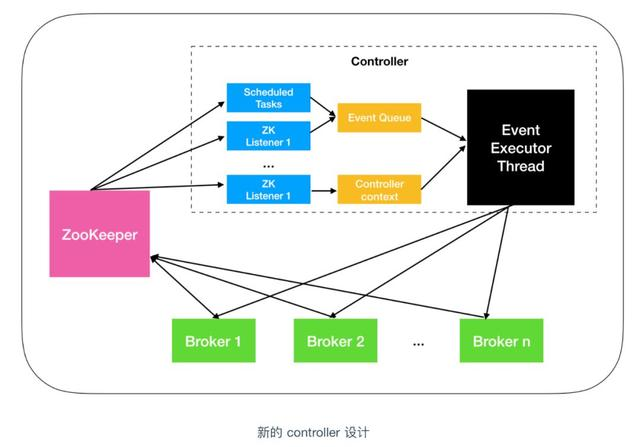
在 Kafka 0.11 之后,Kafka controller 采用了新的设计,把多线程的方案改成了单线程加事件队列的方案。
主要所做的改变有下面这几点
-
第一个改进是增加了一个 Event Executor Thread,事件执行线程,从图中可以看出,不管是 Event Queue 事件队列还是 Controller context 控制器上下文都会交给事件执行线程进行处理。将原来执行的操作全部建模成一个个独立的事件,发送到专属的事件队列中,供此线程消费。
-
第二个改进是将之前同步的 ZooKeeper 全部改为异步操作。ZooKeeper API 提供了两种读写的方式:同步和异步。之前控制器操作 ZooKeeper 都是采用的同步方式,这次把同步方式改为异步,据测试,效率提升了10倍。
-
第三个改进是根据优先级处理请求,之前的设计是 broker 会公平性的处理所有 controller 发送的请求。什么意思呢?公平性难道还不好吗?在某些情况下是的,比如 broker 在排队处理 produce 请求,这时候 controller 发出了一个 StopReplica 的请求,你会怎么办?还在继续处理 produce 请求吗?这个 produce 请求还有用吗?此时最合理的处理顺序应该是,赋予 StopReplica 请求更高的优先级,使它能够得到抢占式的处理。
原文链接:https://baijiahao.baidu.com/s?id=1655359291726496245&wfr=spider&for=pc