开启Map输出阶段压缩
减少job中map和reduce task间数据传输量
1.开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
2.开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
3.设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
开启Reduce输出阶段压缩
1.开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
2.开启mapreduce最终输出数据压缩
···xml
set mapreduce.output.fileoutputformat.compress=true;
3.设置mapreduce最终数据输出压缩方式
```xml
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
4.设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
文件存储格式
1.TextFile
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
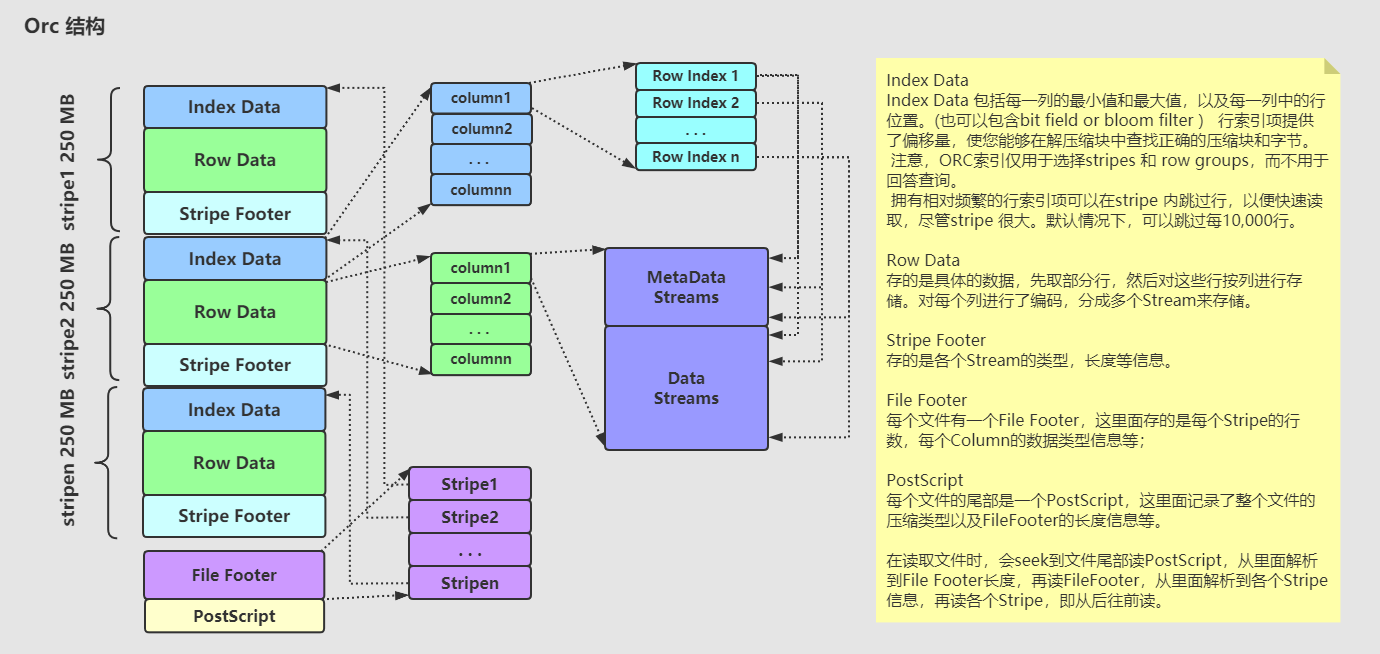
2.Orc
是hive 0.11引入的新的存储格式。默认是zlib压缩方式
每个Orc文件由1个或多个stripe组成,每个stripe 250MB大小,这个stripe实际相当于RowGroup概念,不过大小由4MB->250MB,能提升顺序读的吞吐率。每个Stripe有三部分,分别为index data,row data, Stripe Footer。
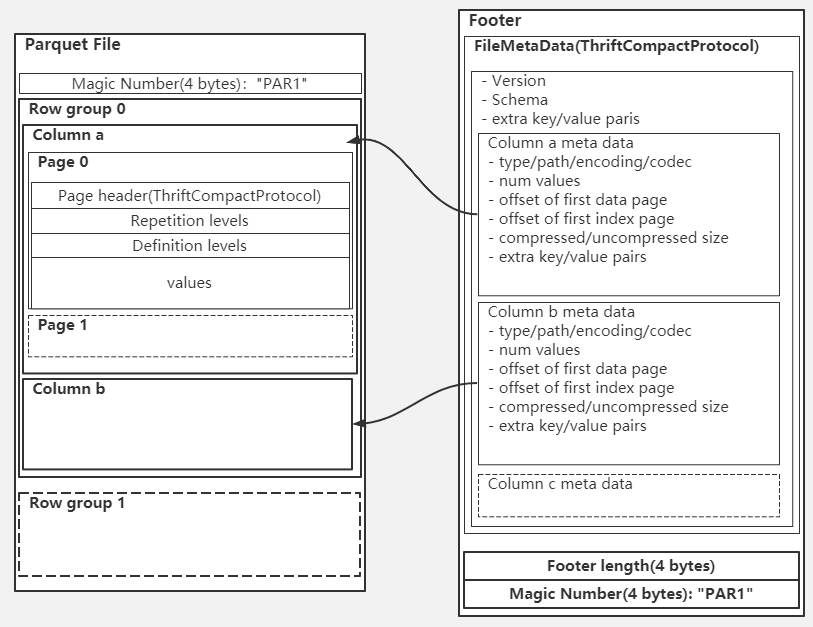
3.Parquet
面向分析型业务的列式存储格式,以二进制方式存储,不可用直接读取,文件中包括该文件的数据和元数据,因此Parquet是自解析的。