传统的数据传输方法
在互联网时代,从某台机器将一份数据(比如一个文件)通过网络传输到另外一台机器,是再平常不过的事情了。如果按照一般的思路,用Java语言来描述发送端的逻辑,大致如下:
Socket socket = new Socket(HOST, PORT);
InputStream inputStream = new FileInputStream(FILE_PATH);
OutputStream outputStream = new DataOutputStream(socket.getOutputStream());
byte[] buffer = new byte[4096];
while (inputStream.read(buffer) >= 0) {
outputStream.write(buffer);
}
outputStream.close();
socket.close();
inputStream.close();
看起来当然是很简单的。但是如果我们深入到操作系统的层面,就会发现实际的微观操作要更复杂,具体来说有以下步骤:
-
JVM向OS发出read()系统调用,触发上下文切换,从用户态切换到内核态。
-
从外部存储(如硬盘)读取文件内容,通过直接内存访问(DMA)存入内核地址空间的缓冲区。
-
将数据从内核缓冲区拷贝到用户空间缓冲区,read()系统调用返回,并从内核态切换回用户态。
-
JVM向OS发出write()系统调用,触发上下文切换,从用户态切换到内核态。
-
将数据从用户缓冲区拷贝到内核中与目的地Socket关联的缓冲区。
-
数据最终经由Socket通过DMA传送到硬件(如网卡)缓冲区,write()系统调用返回,并从内核态切换回用户态。
如果语言描述看起来有些乱的话,通过时序图描述会更清楚一些。
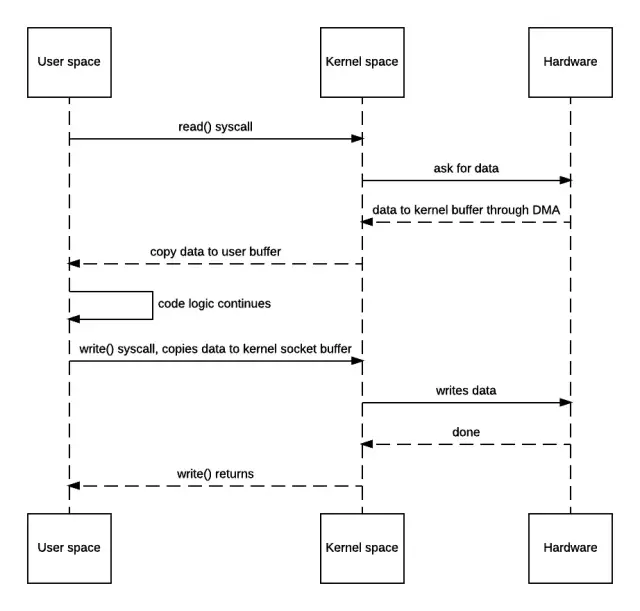
到了这一步,你是否觉得简单的代码逻辑下隐藏着很累赘的东西了?事实也确实如此,这个过程一共发生了4次上下文切换(严格来讲是模式切换),并且数据也被来回拷贝了4次。如果忽略掉系统调用的细节,整个过程可以用下面的两张简图表示。
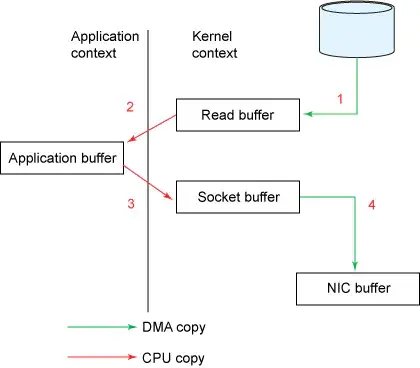
传统方法的流程框图
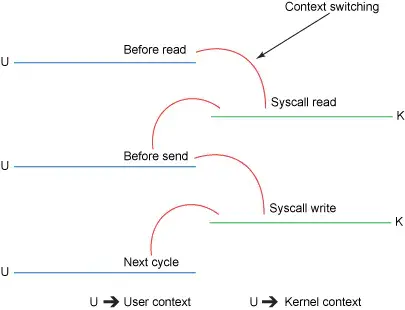
传统方法的上下文切换过程
我们都知道,上下文切换是CPU密集型的工作,数据拷贝是I/O密集型的工作。如果一次简单的传输就要像上面这样复杂的话,效率是相当低下的。零拷贝机制的终极目标,就是消除冗余的上下文切换和数据拷贝,提高效率。
零拷贝的数据传输方法
“基础的”零拷贝机制
通过上面的分析可以看出,第2、3次拷贝(也就是从内核空间到用户空间的来回复制)是没有意义的,数据应该可以直接从内核缓冲区直接送入Socket缓冲区。零拷贝机制就实现了这一点。不过零拷贝需要由操作系统直接支持,不同OS有不同的实现方法。大多数Unix-like系统都是提供了一个名为sendfile()的系统调用,在其man page中,就有这样的描述:
sendfile() copies data between one file descriptor and another.
Because this copying is done within the kernel, sendfile() is more efficient than the combination of read(2) and write(2), which would require transferring data to and from user space.
下面是零拷贝机制下,数据传输的时序图。
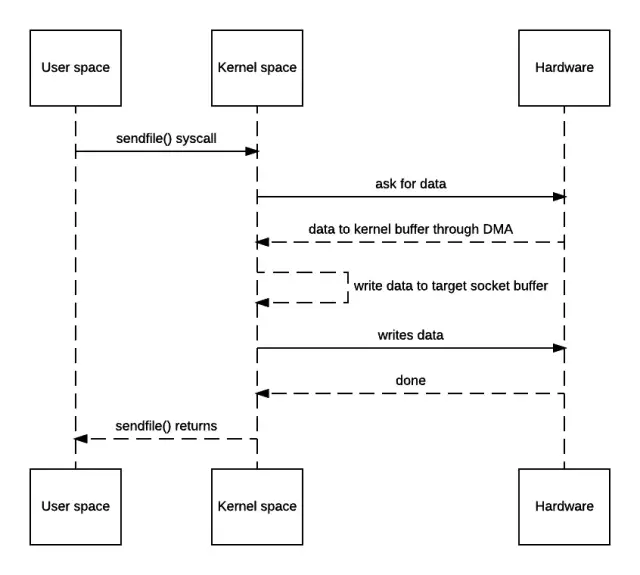
可见确实是消除了从内核空间到用户空间的来回复制,因此“zero-copy”这个词实际上是站在内核的角度来说的,并不是完全不会发生任何拷贝。
在Java NIO包中提供了零拷贝机制对应的API,即FileChannel.transferTo()方法。不过FileChannel类是抽象类,transferTo()也是一个抽象方法,因此还要依赖于具体实现。FileChannel的实现类并不在JDK本身,而位于sun.nio.ch.FileChannelImpl类中,零拷贝的具体实现自然也都是native方法,看官如有兴趣可以自行查找源码来看,这里不再赘述。
将传统方式的发送端逻辑改写一下,大致如下:
SocketAddress socketAddress = new InetSocketAddress(HOST, PORT); SocketChannel socketChannel = SocketChannel.open(); socketChannel.connect(socketAddress); File file = new File(FILE_PATH); FileChannel fileChannel = new FileInputStream(file).getChannel(); fileChannel.transferTo(0, file.length(), socketChannel); fileChannel.close(); socketChannel.close();
借助transferTo()方法的话,整个过程就可以用下面的简图表示了。
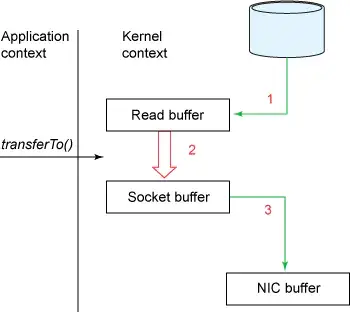
零拷贝方法的流程框图
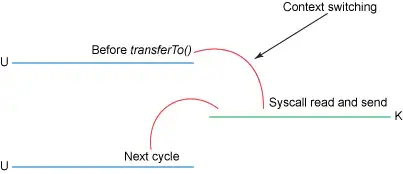
零拷贝方法的上下文切换过程
可见,不仅拷贝的次数变成了3次,上下文切换的次数也减少到了2次,效率比传统方式高了很多。但是它还并非完美状态,下面看一看让它变得更优化的方法。
对Scatter/Gather的支持
在“基础”零拷贝方式的时序图中,有一个“write data to target socket buffer”的回环,在框图中也有一个从“Read buffer”到“Socket buffer”的大箭头。这是因为在一般的Block DMA方式中,源物理地址和目标物理地址都得是连续的,所以一次只能传输物理上连续的一块数据,每传输一个块发起一次中断,直到传输完成,所以必须要在两个缓冲区之间拷贝数据。
而Scatter/Gather DMA方式则不同,会预先维护一个物理上不连续的块描述符的链表,描述符中包含有数据的起始地址和长度。传输时只需要遍历链表,按序传输数据,全部完成后发起一次中断即可,效率比Block DMA要高。也就是说,硬件可以通过Scatter/Gather DMA直接从内核缓冲区中取得全部数据,不需要再从内核缓冲区向Socket缓冲区拷贝数据。因此上面的时序图还可以进一步简化。
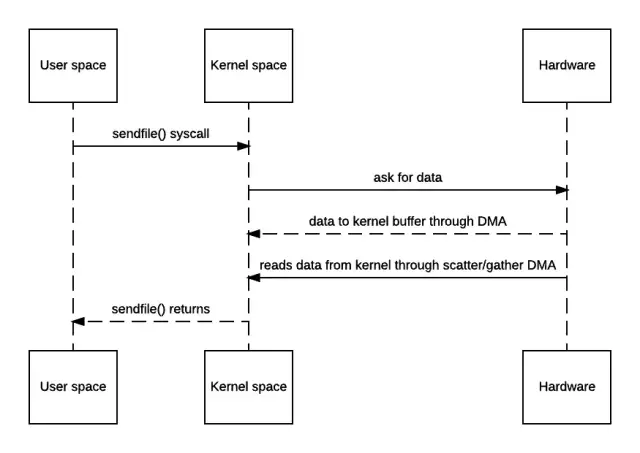
支持Scatter/Gather的零拷贝时序图
这就是完全体的零拷贝机制了,是不是清爽了很多?相对地,它的流程框图如下。
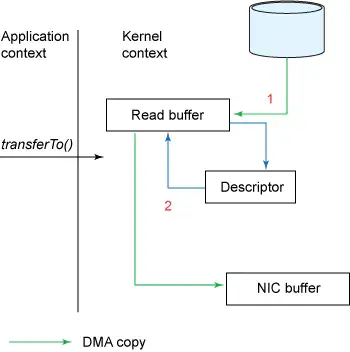
支持Scatter/Gather的零拷贝流程框图
对内存映射(mmap)的支持
上面讲的机制看起来一切都很好,但它还是有个缺点:如果我想在传输时修改数据本身,就无能为力了。不过,很多操作系统也提供了内存映射机制,对应的系统调用为mmap()/munmap()。通过它可以将文件数据映射到内核地址空间,直接进行操作,操作完之后再刷回去。其对应的简要时序图如下。
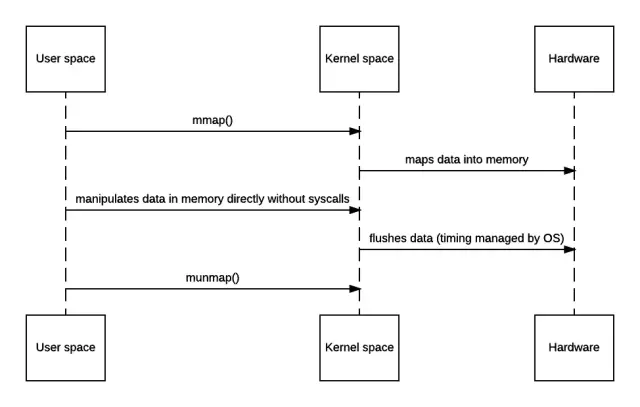
支持mmap的零拷贝时序图
当然,天下没有免费的午餐,上面的过程仍然会发生4次上下文切换。另外,它需要在快表(TLB)中始终维护着所有数据对应的地址空间,直到刷写完成,因此处理缺页的overhead也会更大。在使用该机制时,需要权衡效率。
NIO框架中提供了MappedByteBuffer用来支持mmap。它与常用的DirectByteBuffer一样,都是在堆外内存分配空间。相对地,HeapByteBuffer在堆内内存分配空间。
零拷贝机制的应用
零拷贝在很多框架中得到了广泛应用,一般都以Netty为例来分析。但作为大数据工程师,我就以Kafka与Spark为例来简单说两句吧。
在Kafka中的应用
在使用Kafka时,我们经常会想,为什么Kafka能够达到如此巨大的数据吞吐量?这与Kafka的很多设计哲学是分不开的,比如分区并行、ISR机制、顺序写入、页缓存、高效序列化等等,零拷贝当然也是其中之一。由于Kafka的消息存储涉及到海量数据读写,所以利用零拷贝能够显著地降低延迟,提高效率。
在Kafka中,底层传输动作由TransportLayer接口来定义。它对SocketChannel进行了简单的封装,其中transferFrom()方法定义如下。(Kafka版本为0.10.2.2)
/**
* Transfers bytes from `fileChannel` to this `TransportLayer`.
*
* This method will delegate to {@link FileChannel#transferTo(long, long, java.nio.channels.WritableByteChannel)},
* but it will unwrap the destination channel, if possible, in order to benefit from zero copy. This is required
* because the fast path of `transferTo` is only executed if the destination buffer inherits from an internal JDK
* class.
*
* @param fileChannel The source channel
* @param position The position within the file at which the transfer is to begin; must be non-negative
* @param count The maximum number of bytes to be transferred; must be non-negative
* @return The number of bytes, possibly zero, that were actually transferred
* @see FileChannel#transferTo(long, long, java.nio.channels.WritableByteChannel)
*/
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException;
该方法的功能是将FileChannel中的数据传输到TransportLayer,也就是SocketChannel。在实现类PlaintextTransportLayer的对应方法中,就是直接调用了FileChannel.transferTo()方法。
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
对该方法的调用则位于FileRecords.writeTo()方法中,用于将Kafka收到的缓存数据零拷贝地写入目的Channel。
@Override
public long writeTo(GatheringByteChannel destChannel, long offset, int length) throws IOException {
long newSize = Math.min(channel.size(), end) - start;
int oldSize = sizeInBytes();
if (newSize < oldSize)
throw new KafkaException(String.format(
"Size of FileRecords %s has been truncated during write: old size %d, new size %d",
file.getAbsolutePath(), oldSize, newSize));
long position = start + offset;
int count = Math.min(length, oldSize);
final long bytesTransferred;
if (destChannel instanceof TransportLayer) {
TransportLayer tl = (TransportLayer) destChannel;
bytesTransferred = tl.transferFrom(channel, position, count);
} else {
bytesTransferred = channel.transferTo(position, count, destChannel);
}
return bytesTransferred;
}
在Spark中的应用
Spark虽然是一个高效的积极使用内存的计算框架,但在需要使用磁盘时也会适当地溢写。零拷贝机制在Spark Core中主要就被用来优化Shuffle过程中的溢写逻辑。由于Shuffle过程涉及大量的数据交换,因此效率当然是越高越好。
在启用Bypass机制的Sort Shuffle(参见https://www.jianshu.com/p/aba0f35fa2a0)以及Tungsten Sort Shuffle的shuffle write阶段(参见https://www.jianshu.com/p/1d714f0c5e07),都使用了零拷贝来快速合并溢写文件的分片,有一个专门的配置项spark.file.transferTo来控制是否启用零拷贝(默认当然是true)。以BypassMergeSortShuffleWriter为例,它最终是调用了通用工具类Utils中的copyFileStreamNIO()方法。
def copyFileStreamNIO(
input: FileChannel,
output: FileChannel,
startPosition: Long,
bytesToCopy: Long): Unit = {
val initialPos = output.position()
var count = 0L
// In case transferTo method transferred less data than we have required.
while (count < bytesToCopy) {
count += input.transferTo(count + startPosition, bytesToCopy - count, output)
}
assert(count == bytesToCopy,
s"request to copy $bytesToCopy bytes, but actually copied $count bytes.")
val finalPos = output.position()
val expectedPos = initialPos + bytesToCopy
assert(finalPos == expectedPos,
s"""
|Current position $finalPos do not equal to expected position $expectedPos
|after transferTo, please check your kernel version to see if it is 2.6.32,
|this is a kernel bug which will lead to unexpected behavior when using transferTo.
|You can set spark.file.transferTo = false to disable this NIO feature.
""".stripMargin)
}
可见,该方法用于将数据从一个FileChannel零拷贝到另一个FileChannel。通过控制起始位置和长度参数,就可以精确地将所有溢写文件拼合在一起了。
这是一个多月之前留下的烂尾文,今天终于想起来了,就补全并且发出来吧。
零拷贝(Zero-copy)是一种高效的数据传输机制,在追求低延迟的传输场景中十分常用。本文先通过传统方案引出零拷贝机制,然后分析其细节,最后介绍它的部分应用。
文中涉及到的操作系统理论知识都可以参考英文维基或者相关书籍,如Abraham Silberschatz著《操作系统概念》、Andrew S. Tanenbaum著《现代操作系统》等。
作者:LittleMagic
链接:https://www.jianshu.com/p/193cae9cbf07