以下配置是logstash切分tomcat catalina.out日志。
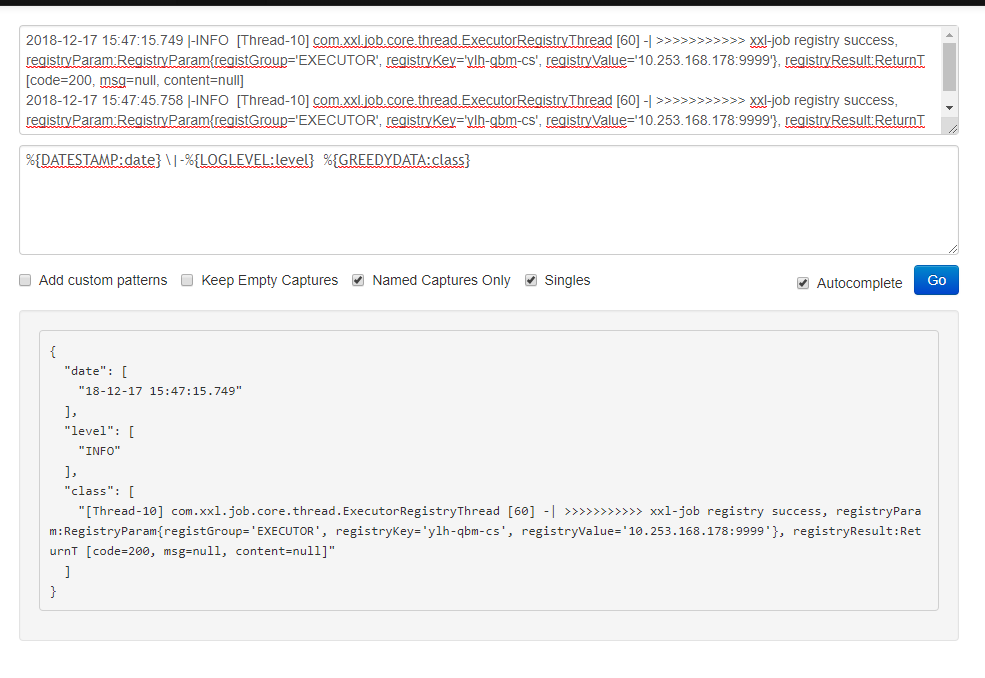
http://grok.qiexun.net/ 分割时先用这个网站测试下语句对不对,能不能按需切割日志。
1 input { 2 file { 3 type => "01-catalina" 4 path => ["/usr/local/tomcat-1/logs/catalina.out"] 5 start_position => "beginning" 6 ignore_older => 3 7 codec=> multiline { 8 pattern => "^2018" 9 negate => true 10 what => "previous" 11 } 12 } 13 14 file { 15 type => "02-catalina" 16 path => ["/usr/local/tomcat-2/logs/catalina.out"] 17 start_position => "beginning" 18 ignore_older => 3 19 codec=> multiline { 20 pattern => "^2018" 21 negate => true 22 what => "previous" 23 } 24 } 25 26 } 27 28 filter { 29 grok { 30 match => { 31 "message" => "%{DATESTAMP:date} |-%{LOGLEVEL:level} [%{DATA:class}] %{DATA:code_info} -| %{GREEDYDATA:log_info}" 32 } 33 } 34 } 35 36 37 38 output { 39 elasticsearch { 40 hosts => ["192.168.1.1:9200"] 41 index => "tomcat-%{type}" 42 } 43 stdout { 44 codec => rubydebug 45 } 46 }
跨行匹配 比如java 堆栈信息
1 input { 2 file { 3 type => "10.139.32.68" 4 path => ["/data1/application/api/apache-tomcat/logs/catalina.out"] 5 start_position => "beginning" 6 ignore_older => 3 7 codec=> multiline { 8 pattern => "^d{4}-d{2}-d{2}sd{2}:d{2}:d{2}" 9 negate => true 10 what => "previous" 11 } 12 }
codec=> multiline 引用 multiline插件
pattern 正则匹配 ^d{4}-d{2}-d{2}sd{2}:d{2}:d{2} 表示以 2018-10-10 10:10:10 日期形式开通的
negate
what 值为previous 表示未匹配的内容属于上一个匹配内容
自定义正则表达式
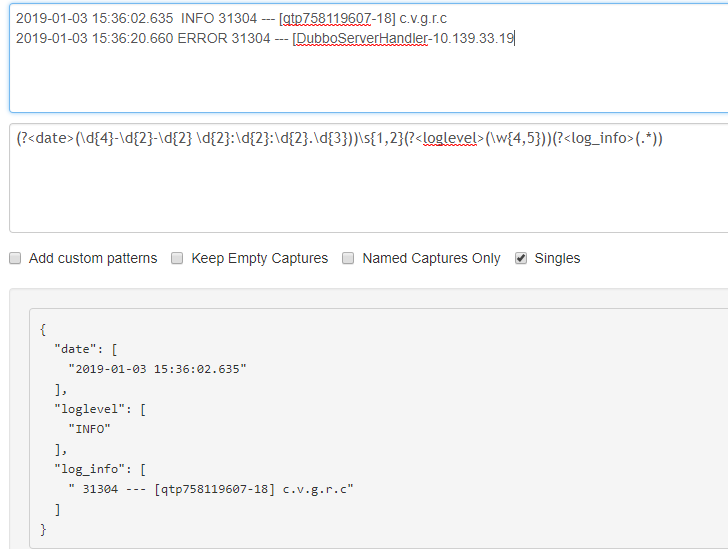
其中(?<>())格式表示一个正则开始,<>里是正则匹配名,()里是正则表达式
上图正则分四段,分别是
(?<date>(d{4}-d{2}-d{2} d{2}:d{2}:d{2}.d{3})) 匹配日期
s{1,2} 匹配1或2个空格
(?<loglevel>(w{4,5})) 匹配4或5个字母
(?<log_info>(.*)) 匹配所有字符
又如下面这个
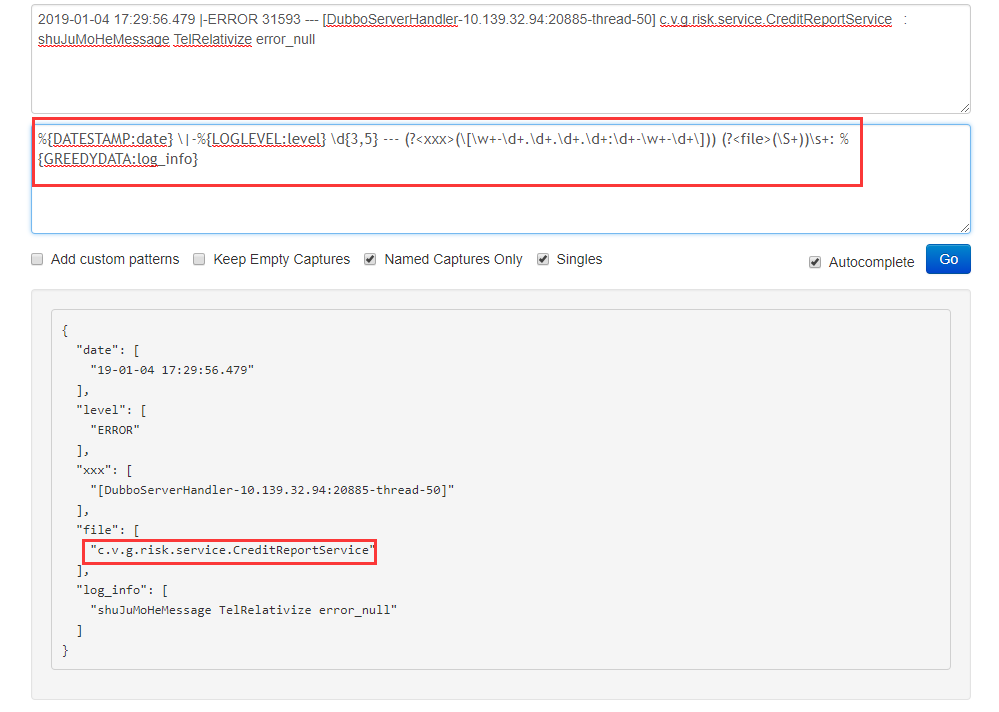
2019-01-04 17:29:56.479 |-ERROR 31593 --- [DubboServerHandler-10.139.32.94:20885-thread-50] c.v.g.risk.service.CreditReportService : shuJuMoHeMessage TelRelativize error_null
%{DATESTAMP:date} |-%{LOGLEVEL:level} d{3,5} --- (?<xxx>([w+-d+.d+.d+.d+:d+-w+-d+])) (?<file>(S+))s+: %{GREEDYDATA:log_info}
logstash 启动多个配置文件
logstash 启动多个配置文件,比如conf目录下有cs.conf和server.conf就可以用下面命令启动
./logstash -f ../conf/
记住conf后面不能加上* 如./logstash -f ../conf/* ,这样只会读取conf目录下的一个配置文件。
另外虽然可以同时启动多个配置文件,但实际上是把多个配置文件拼接成一个的配置文件的,也就是多个配置文件里的input、filter、output不是相互独立的。
如有俩个配置文件cs.conf和server.conf 配置如下:
cs.conf配置:
1 input { 2 file { 3 type => "192.168.1.1" 4 path => ["/data1/application/cs/tomcat-1/logs/catalina.out"] 5 start_position => "beginning" 6 ignore_older => 3 7 codec=> multiline { 8 pattern => "^d{4}-d{2}-d{2}sd{2}:d{2}:d{2}" 9 negate => true 10 what => "previous" 11 } 12 } 13 14 } 15 16 filter { 17 grok { remove_tag => ["multiline"] #打印多行时有时会无法解析,因为tags里会多出一个multiline ,进而报错,报错信息如文末备注1
18 match => {
19 "message" => "%{DATESTAMP:date} |-%{LOGLEVEL:level} %{GREEDYDATA:log_info}"
20 }
21 }
22 }
23
24
25
26 output {
27 elasticsearch {
28 hosts => ["192.168.0.1:9200"]
29 index => "qwe-cs-tomcat"
30 }
31 stdout {
32 codec => rubydebug
33 }
34 }
server.conf配置
1 input { 2 file { 3 type => "192.168.1.1" 4 path => ["/data1/application/server/tomcat-2/logs/catalina.out"] 5 start_position => "beginning" 6 ignore_older => 3 7 codec=> multiline { 8 pattern => "^d{4}-d{2}-d{2}sd{2}:d{2}:d{2}" 9 negate => true 10 what => "previous" 11 } 12 } 13 14 } 15 16 filter { 17 grok { 18 match => { 19 "message" => "%{DATESTAMP:date} |-%{LOGLEVEL:level} %{GREEDYDATA:log_info}" 20 } 21 } 22 } 23 24 25 26 output { 27 elasticsearch { 28 hosts => ["192.168.0.1:9200"] 29 index => "qwe-server-tomcat" 30 } 31 stdout { 32 codec => rubydebug 33 } 34 }
上面俩个配置就算同时启动,但实际上俩个配置文件会拼接成一个,input里的内容会输出俩个,导致elk里数据看起来是重复的,打印了俩次
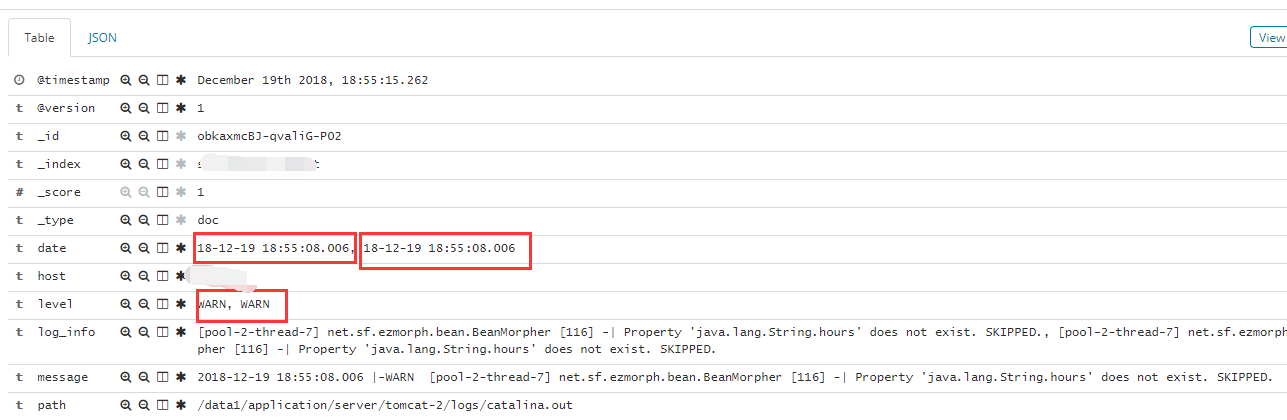
一般这种情况建议,input里建议使用tags或者type这两个特殊字段,即在读取文件的时候,添加标识符在tags中或者定义type变量。
如下面这种
1 input { 2 file { 3 type => "192.168.1.1" 4 tags =>"cs" 5 path => ["/data1/application/cs/tomcat-1/logs/catalina.out"] 6 start_position => "beginning" 7 ignore_older => 3 8 codec=> multiline { 9 pattern => "^d{4}-d{2}-d{2}sd{2}:d{2}:d{2}" 10 negate => true 11 what => "previous" 12 } 13 } 14 15 file { 16 type => "192.168.1.1" 17 tags =>"server" 18 path => ["/data1/application/server/tomcat-2/logs/catalina.out"] 19 start_position => "beginning" 20 ignore_older => 3 21 codec=> multiline { 22 pattern => "^d{4}-d{2}-d{2}sd{2}:d{2}:d{2}" 23 negate => true 24 what => "previous" 25 } 26 } 27 28 } 29 30 filter { 31 grok {
remove_tag =>["multiline"] 32 match => { 33 "message" => "%{DATESTAMP:date} |-%{LOGLEVEL:level} %{GREEDYDATA:log_info}" 34 } 35 } 36 } 37 38 39 40 output { 41 elasticsearch { 42 hosts => ["192.168.0.1:9200"] 43 index => "ulh-%{tags}-tomcat" 44 } 45 stdout { 46 codec => rubydebug 47 } 48 }
这样我们就可以根据tpye和tags分别日志是哪台服务器上的哪个应用了
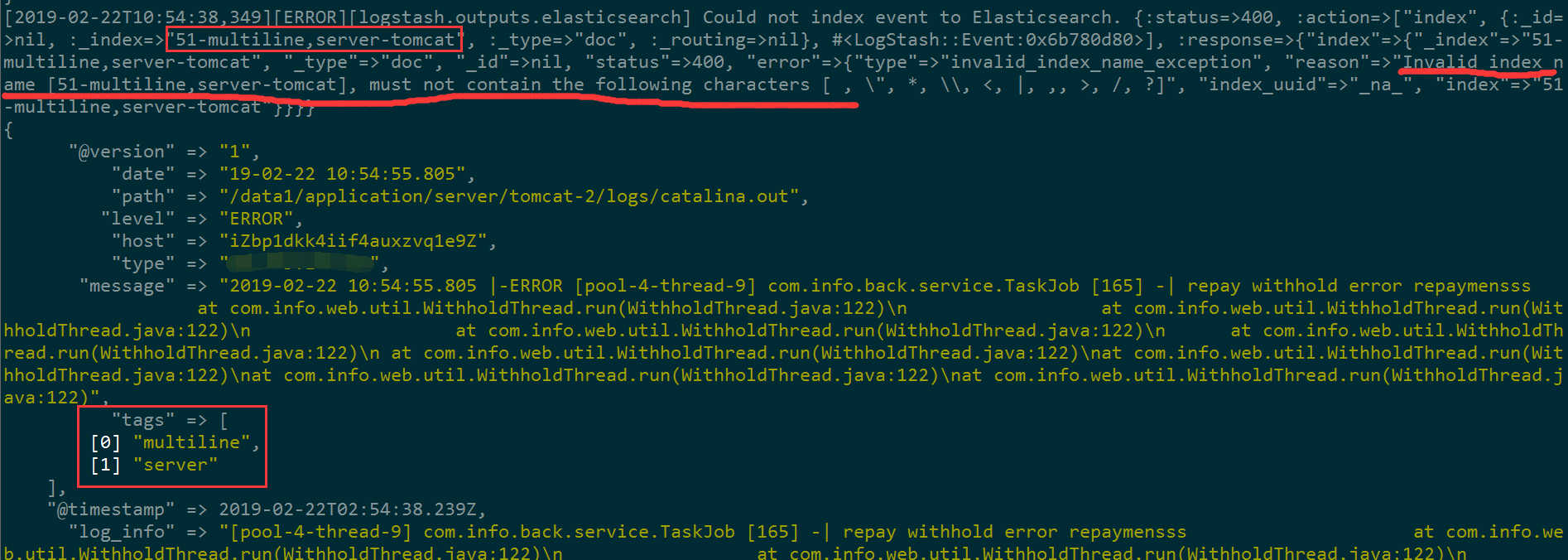
注1:跨行解析时因为多个tags导致无法解析异常的截图,解决方法就是在 filter grok里添加 remove_tag =>["multiline"]
注2:logstash中multiline更多用法
input { stdin { codec =>multiline { charset=>... #可选 字符编码 max_bytes=>... #可选 bytes类型 设置最大的字节数 max_lines=>... #可选 number类型 设置最大的行数,默认是500行 multiline_tag... #可选 string类型 设置一个事件标签,默认是multiline pattern=>... #必选 string类型 设置匹配的正则表达式 patterns_dir=>... #可选 array类型 可以设置多个正则表达式 negate=>... #可选 boolean类型 设置true是向前匹配,设置false向后匹配,默认是FALSE what=>... #必选 设置未匹配的内容是向前合并还是先后合并,previous,next两个值选择 } } }