配置:
编辑master my.cnf添加
[mysqld] server-id=1 #各个mysql实例 id不能重复 log-bin=mysql-bin #这个一定得设置,否则没有日志的话,从数据库上会报错 binlog-ignore-db=mysql,test #表示不同步mysql test库 binlog_format=MIXED expire_logs_days =30 //binlog过期清理时间 max_binlog_size=100m //binlog每个日志文件大小 binlog_cache_size=4m //binlog缓存大小 max_binlog_cache_size=512m //最大binlog缓存大小
编辑slave my.cnf
[mysqld] server-id=2 #各个mysql实例 id不能重复 log-bin=mysql-bin #这个一定得设置,否则没有日志的话,从数据库上会报错 relay-log=relay-log #定义relay_log的位置和名称 relay-log-index=relay-log.index #同relay_log,定义relay_log的位置和名称 skip_name_resolve=ON binlog-ignore-db=mysql binlog_format=MIXED slave_skip_errors=1062 ## relay_log配置中继日志 log_slave_updates=1 read_only=1 #将slave从库设置为只读状态
登录master数据库
1、设置主从复制的账号
grant replication CLIENT, REPLICATION SLAVE on *.* to 'backup'@'%' identified by '123';
flush privileges;
2、查看当前日志位置
SHOW MASTER STATUS;

登录slave数据库
1、设置同步参数
change master to master_host='192.168.7,2', master_port=3306, master_user='backup', master_password='123', master_log_file='replicas-mysql-bin.000003', #master 查询的日志 master_log_pos=154; #master 查询的位置
2、启动同步
start slave;
3、查看状态
show slave status G
如下俩个yes 说明配置成功了
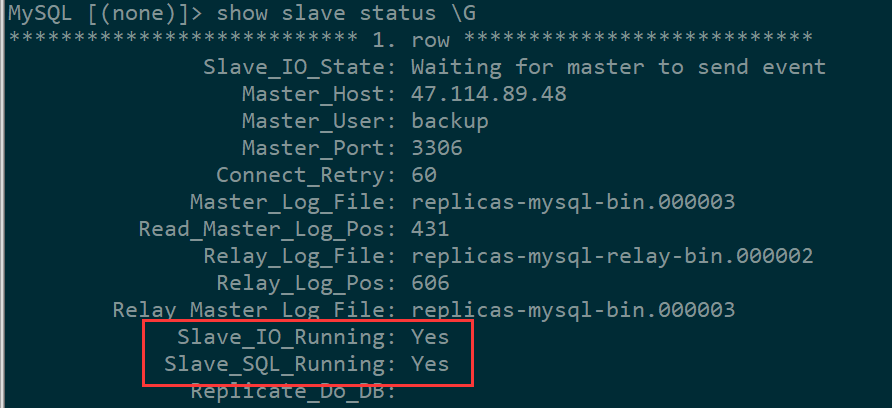
另一个重要参数Seconds_Behind_Master:0 这个是和主库比同步延迟秒数
如果出错了,可以先停止同步,重新配置再开启同步
stop slave; set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;