ceph是目前开源分布式存储里面最好的一个,但是在高负载下会有很多异常的情况会发生,有些问题无法完全避免,但是可以进行一定的控制,比如:在虚拟化场景下,重启osd会让虚拟机挂起的情况
重新启动osd会给这个osd进程所在的磁盘带来额外的负载,随着前面业务的需求的增长,会增加对存储的I/O的需求,虽然这个对于整个业务系统来说是好事,但是在某些情况下,会越来越接近存储吞吐量的极限,通常情况下没有异常发生的时候,都是正常的,一旦发生异常,集群超过了临界值,性能会变得剧烈的抖动
对于这种情况,一般会升级硬件来避免集群从一个高负载的集群变成一个过载的集群。本章节的重点在重启osd进程这个问题
问题分析
OSD重启是需要重视的,这个地方是ceph的一个设计的弱点。ceph集群有很多的OSD进程,OSD管理对磁盘上的对象的访问,磁盘的对象被分布到PG组当中,对象有相同的分布,副本会在相同的PG当中存在,如果不理解可以看看(ceph概览)
当集群OSD进程出现down的情况,会被mon认为 "OUT" 了,这个 "OUT" 不是触发迁移的那个 "OUT",是不服务的 "OUT" ,这个OSD上受影响的PG的I/O请求会被其他拥有这个PG的OSD接管,当OSD重新启动的时候,OSD会被加入进来,将会检查PG,看是否有在down的期间错过东西,然后进行更新,这里问题就来了,启动之后会访问磁盘检查PG是否有缺失的东西进行更新,会进行一定量的数据恢复,同时会开始接受新的IO的请求,如果本来磁盘就只剩很少的余量,那么一旦请求发送到这个OSD上,那么性能将会开始下降
如果去看ceph的邮件列表,在极端情况下,这种效应会让整个集群停机,这发生在OSD太忙了,连心跳都无法回复,然后mon就会把它标记为down,这个时候OSD的进程都还在的,这个时候客户端的请求会导入到其他的OSD上,然后负载小了,OSD又会自己进来,然后又开始响应请求了,然后之前没有受影响的OSD节点,需要把新写入的数据同步过来,这个又增加了其他的OSD的负载了,一旦集群接近I/O的限制,也会让其他的OSD无法响应了,结果就是整个集群的OSD在反复的"in"和"out"状态之间变化了,集群在这种情况下,就无法接收客户端的请求了,如果不人工干预甚至无法恢复正常,这个在高负载下是很好复现出来的;另外一种较轻的情况,在OSD重启过程,I/O可能会hung住,影响性能.如果不能避免,至少能想办法去降低这个影响
我们能做些什么?在ceph开发者列表当中有开发者提出了这个设计上需要修复,这个估计需要等很久以后的事情了,我们能做什么来降低这个的影响?最明显的一点是要保证集群有足够的I/O的余量,另一种思路就是减少关键过程启动检查和接收I/O的竞争
减少OSD启动过程当中的IO
OSD在启动的时候可以预测到磁盘的访问的模式。我们可以了解这个访问模式,然后提前将文件读取到内核的缓存当中。这样这些文件在启动的时候就不需要再次访问磁盘了,意味着更少的磁盘消耗和更好的性能
现在来定位下OSD启动过程中做了哪些事情,使用性能大师 Brendan Gregg 的 opensnoop 工具,一个OSD启动的过程如下:
OSD启动过程
[root@lab8106 ~]# opensnoop ceph-7
Tracing open()s for filenames containing "ceph-7". Ctrl-C to end.
COMM PID FD FILE
ceph osd 0x3 /var/lib/ceph/osd/ceph-7/
ceph osd 0x4 /var/lib/ceph/osd/ceph-7/type
ceph osd 0x4 /var/lib/ceph/osd/ceph-7/magic
ceph osd 0x4 /var/lib/ceph/osd/ceph-7/whoami
ceph osd 0x4 /var/lib/ceph/osd/ceph-7/ceph_fsid
ceph osd 0x4 /var/lib/ceph/osd/ceph-7/fsid
ceph osd 0xb /var/lib/ceph/osd/ceph-7/fsid
ceph osd 0xb /var/lib/ceph/osd/ceph-7/fsid
ceph osd 0xc /var/lib/ceph/osd/ceph-7/store_version
ceph osd 0xc /var/lib/ceph/osd/ceph-7/superblock
ceph osd 0xc /var/lib/ceph/osd/ceph-7
ceph osd 0xd /var/lib/ceph/osd/ceph-7/fiemap_test
ceph osd 0xd /var/lib/ceph/osd/ceph-7/xattr_test
ceph osd 0xd /var/lib/ceph/osd/ceph-7/current
ceph osd 0xe /var/lib/ceph/osd/ceph-7/current/commit_op_seq
ceph osd 0xf /var/lib/ceph/osd/ceph-7/current/omap/LOCK
ceph osd 0x10 /var/lib/ceph/osd/ceph-7/current/omap/CURRENT
ceph osd 0x10 /var/lib/ceph/osd/ceph-7/current/omap/MANIFEST-000135
开始的时候,OSD读取了很多元数据文件,没有什么特别的
下面读取omap的数据库文件,读取了一部分的osdmap文件
ceph osd 0x10 /var/lib/ceph/osd/ceph-7/current/omap/000137.log
ceph osd 0x11 /var/lib/ceph/osd/ceph-7/current/omap/000143.sst
ceph osd 0x11 /var/lib/ceph/osd/ceph-7/current/omap/000143.sst
ceph osd 0x10 /var/lib/ceph/osd/ceph-7/current/omap/000144.log
ceph osd 0x11 /var/lib/ceph/osd/ceph-7/current/omap/MANIFEST-000142
ceph osd 0x12 /var/lib/ceph/osd/ceph-7/current/omap/000142.dbtmp
ceph osd 0x12 /var/lib/ceph/osd/ceph-7/current/omap/000138.sst
ceph osd 0x12 /var/lib/ceph/osd/ceph-7/journal
ceph osd 0x12 /var/lib/ceph/osd/ceph-7/journal
ceph osd 0x13 /var/lib/ceph/osd/ceph-7/store_version
ceph osd 0x13 /var/lib/ceph/osd/ceph-7/current/meta/osdusuperblock__0_23C2FCDE__none
ceph osd 0x14 /var/lib/ceph/osd/ceph-7/current/meta/DIR_5/osdmap.298__0_AC96EE75__none
ceph osd 0x15 /var/lib/ceph/osd/ceph-7/current/0.3b_head
ceph osd 0x15 /var/lib/ceph/osd/ceph-7/current/meta/DIR_5/osdmap.297__0_AC96EEA5__none
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.7_head
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.34_head
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.20_head
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.22_head
可以看到读取一个sst后,就会继续读取pg的目录
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/omap/000139.sst
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.ec_head
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.7e_head
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.14b_head
[···]
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/omap/000141.sst
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.2fb_head
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.cf_head
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.10f_head
[···]
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/omap/000140.sst
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.8f_head
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.10c_head
ceph osd 0x16 /var/lib/ceph/osd/ceph-7/current/0.14e_head
[···]
然后会读取每个pg里面的_head_文件
tp_fstore_op 23688 0x17 /var/lib/ceph/osd/ceph-7/current/0.23a_head/__head_0000023A__0
tp_fstore_op 23688 0x18 /var/lib/ceph/osd/ceph-7/current/0.1a2_head/DIR_2/DIR_A/DIR_1/__head_000001A2__0
<...> 23689 0x19 /var/lib/ceph/osd/ceph-7/current/0.2ea_head/__head_000002EA__0
[···]
然后会进行osdmap文件的操作
tp_fstore_op 23688 0x3a /var/lib/ceph/osd/ceph-7/current/meta/DIR_2/incuosdmap.299__0_C67CF872__none
tp_fstore_op 23688 0x4e /var/lib/ceph/osd/ceph-7/current/meta/DIR_5/osdmap.299__0_AC96EF05__none
tp_fstore_op 23688 0x14 /var/lib/ceph/osd/ceph-7/current/meta/DIR_2/incuosdmap.300__0_C67CF142__none
tp_fstore_op 23688 0x4f /var/lib/ceph/osd/ceph-7/current/meta/DIR_5/osdmap.300__0_AC96E415__none
tp_fstore_op 23688 0x15 /var/lib/ceph/osd/ceph-7/current/meta/osdusuperblock__0_23C2FCDE__none
tp_fstore_op 23689 0x6e /var/lib/ceph/osd/ceph-7/current/meta/DIR_2/incuosdmap.301__0_C67CF612__none
tp_fstore_op 23689 0x55 /var/lib/ceph/osd/ceph-7/current/meta/DIR_5/osdmap.301__0_AC96E5A5__none
tp_fstore_op 23689 0xbf /var/lib/ceph/osd/ceph-7/current/meta/DIR_2/incuosdmap.302__0_C67CF7A2__none
tp_fstore_op 23689 0x60 /var/lib/ceph/osd/ceph-7/current/meta/DIR_5/osdmap.302__0_AC96E575__none
tp_fstore_op 23688 0x86 /var/lib/ceph/osd/ceph-7/current/meta/DIR_2/incuosdmap.303__0_C67CF772__none
tp_fstore_op 23688 0x6a /var/lib/ceph/osd/ceph-7/current/meta/DIR_5/osdmap.303__0_AC96FA05__none
s
我们无法确定哪些对象将需要读取,单我们知道,所有的OMAP和元数据文件将会打开,_head_文件将会打开
使用vmtouch进行预读取
下面将进入 vmtouch ,这个小工具能够读取文件并锁定到内存当中,这样后续的I/O请求能够从缓存当中读取它们,这样就减少了对磁盘的访问请求
在这里我们的访问模式是这样的:
[root@lab8106 ceph-7]# vmtouch -t /var/lib/ceph/osd/ceph-7/current/meta/ /var/lib/ceph/osd/ceph-7/current/omap/
Files: 618
Directories: 6
Touched Pages: 3972 (15M)
Elapsed: 0.009621 seconds
关于这个vmtouch很好使用也很强大,可以使用 vmtouch -L 将数据锁定到内存当中去,这里用 -t 也可以,使用 -v 参数能打印更多详细的信息,这个效果有多大?这个原作者的效果很好,我的环境太小,看不出太多的效果,但是从原理上看,应该是会有用的,我的读取过程跟原作者的读取过程有一定的差别,作者的数据库文件是 ldb ,我的环境是 sst,并且作者的压力应该是很大的情况下的,我的环境较小
判断是否有作用
一个很好的衡量的方法就是看启动过程当中的 peering 的阶段的长度, peering 状态是osd做相互的协调的,PG的请求在这个时候是无法响应的,理想状况下这个过程会很快,无法察觉,如果集群集群处于高负载或者过载状态,这个持续的时间就会很久,然后关闭一个OSD,然后等待一分钟,以便让一部分写入只写到了其他OSD,在down掉的OSD启动后,需要从其他OSD恢复一些数据,然后重新打开,从日志当中,绘制一段时间的 peering 状态PG的数目,score是统计的所有时间线上 peering 状态的计数的总和
为了验证这个vmtouch将会减少 peering 的状态,将负载压到略小于集群满载情况
第一个实验是OSD重启(无vmtouch)
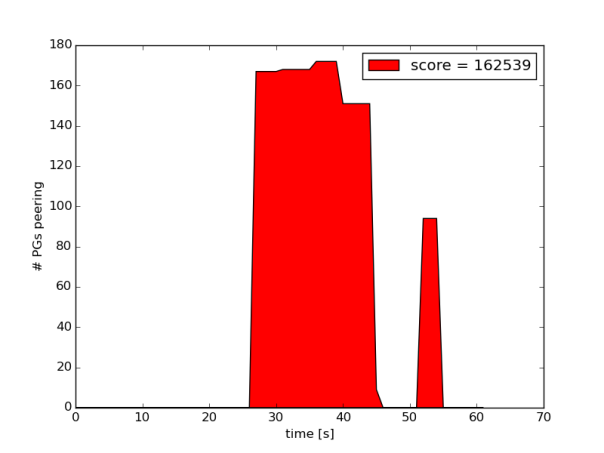
可以看到超过30s时,大量的pg是peering状态,导致集群出现缓慢
第二个实验中使用vmtouch预读取OMAP的数据库文件
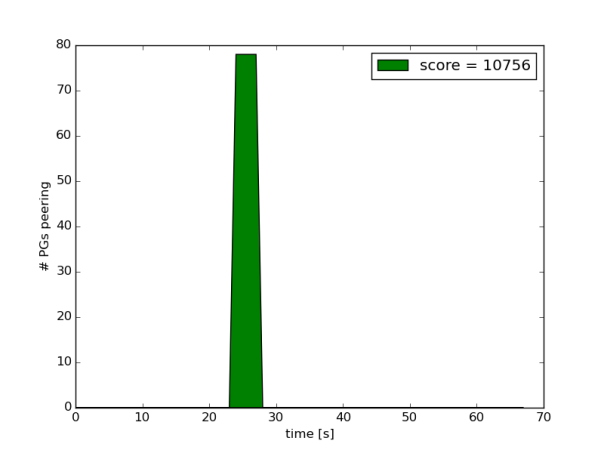
这些 peering 状态并没有消失,但是可以看到有很大的改善 peering 会更早的开始(OMAP已经加载),总体的score也要小很多,这个是一个很不错的结果
结论
根据之前监测到的读取数据的情况,预读取文件,能够有不错的改善,虽然不是完整的解决方案,但是能够帮助改善一个痛点,从长远来看,希望ceph能改进设计,是这个情况消失
总结
本章节里面介绍了两个工具
opensnoop
这个工具已经存在了很久很久了,也是到现在才看到的,一个用于监控文件的操作,是Gregg 大师的作品,仅仅是一个shell脚本就能实现监控,关键还在于其对操作系统的了解
vmtouch
这个是将数据加载到内存的,以前关注的是清理内存,其实在某些场景下,能够预加载到内存将会解决很多问题,关键看怎么去用了
参考文章
Improving Ceph OSD start-up behaviour with vmtouch
opensnoop
vmtouch
变更记录
| Why | Who | When |
|---|---|---|
| 创建 | 武汉-运维-磨渣 | 2016-06-07 |