作业来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
爬取豆瓣电影《无双》影评
1.首先分析网页
在豆瓣网站中,需要浏览影评,是需要用户登录的;因此,要爬取影评网页,就需要注册用户、登录,捉取cookie,模拟用户登录。
def headerRandom(): ua = UserAgent() uheader=ua.random return uheader def url_xp(url): header={'User-Agent':headerRandom(), 'referer': 'https: // movie.douban.com / subject / 26425063 / collections', 'host': 'movie.douban.com'} cookie={'Cookie':'bid=1b6T3XfY1Lg; ll="118296"; __yadk_uid=8Rh5yYIVjjTiWVlvXwLMTjTiysdDbnhc; _vwo_uuid_v2=D004713234FC45F9F75852DA2C22AA70D|64d0230cd2e8f38db28c1e01475587bc; douban-fav-remind=1; __utma=30149280.1603033016.1527918356.1539482818.1555739204.4; __utmc=30149280; __utmz=30149280.1555739204.4.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; dbcl2="195240672:1OaW66LYWvU"; ck=XrRZ; ap_v=0,6.0; push_noty_num=0; push_doumail_num=0; __utmv=30149280.19524; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1555739431%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=223695111.1276142029.1532846523.1532846523.1555739431.2; __utmb=223695111.0.10.1555739431; __utmc=223695111; __utmz=223695111.1555739431.2.1.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; douban-profile-remind=1; __utmt=1; __utmb=30149280.14.10.1555739204; _pk_id.100001.4cf6=d5d70594f72eeb39.1532846523.2.1555744004.1532846523.'} response = requests.get(url=url,cookies=cookie,headers=header) time.sleep(random.random() * 2) response.encoding = 'utf-8' soup = bs(response.content,"lxml") return soup
影评页面:

需要爬取的信息有:评论用户名、评分等级、评论时间、评论内容、该评论的赞同和反对数量。如图所示。
经过初步分析,评论用户名、评分等级、评论时间、该评论的赞同和反对数量都可以在本网页中爬取到;但是,评论内容却不在本网页中。那就只能继续观察。最后,可以发现,所有的评论内容,隐藏在这样的'https://movie.douban.com/j/review/9682284/full',经过仔细观察,这样的网页是有关则的:https://movie.douban.com/j/review/+该用户id+/full组成的。
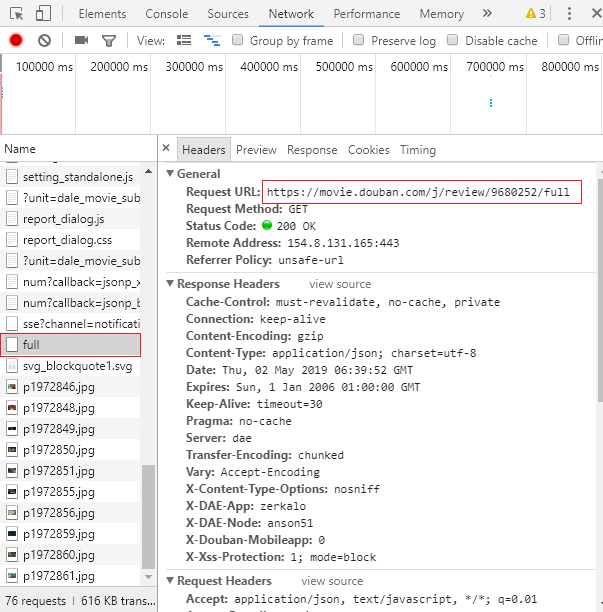
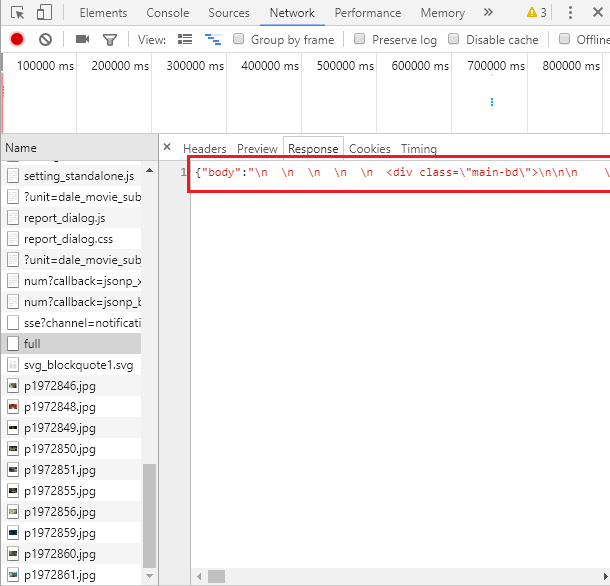
在该该网址的内容中存在一个小坑,它的内容一眼看过去是以一个字典的模式存放的,当我想取字典内容出来时,却发现报错,经过观察和修改,其实它的内容就是一个很长的字符串。
2.爬取数据
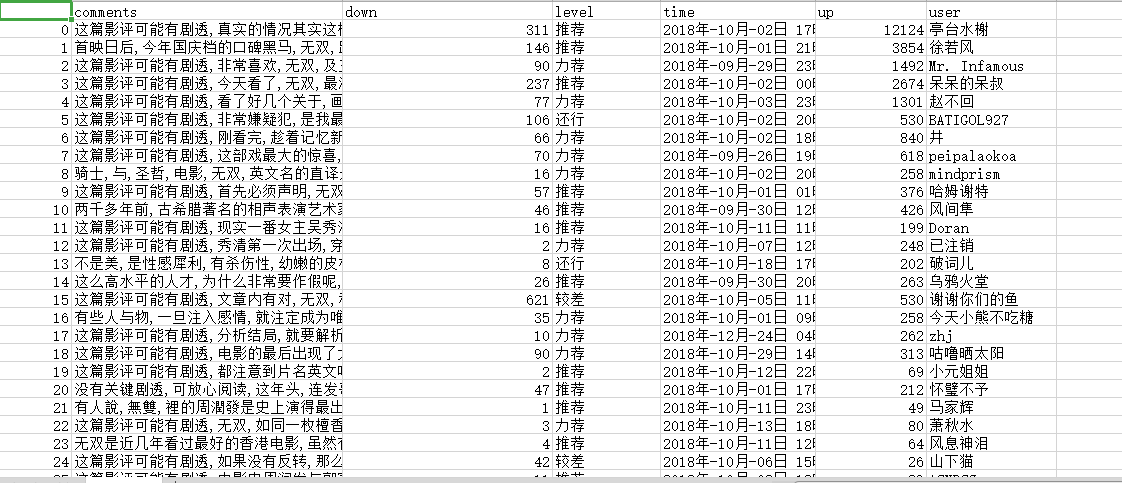
1.csv保存评论用户名、评分等级、评论时间、评论内容、该评论的赞同和反对数量

2.txt保存评论内容

3.分析数据
在分析用户评论星级中,根据数据绘制出的统计表,如下图所示:

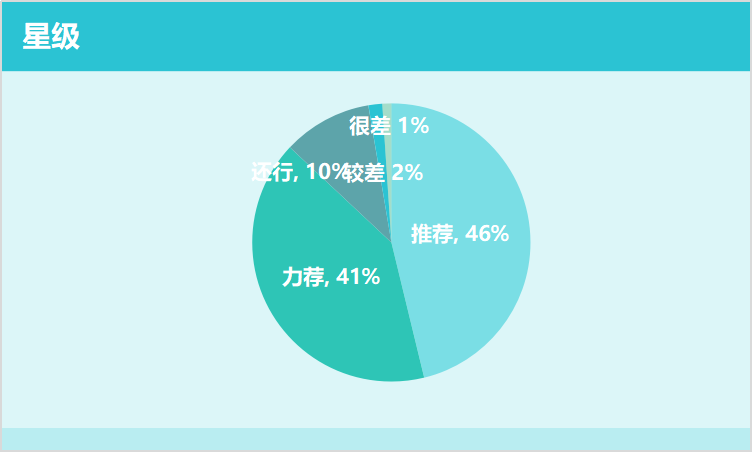
整体而言,用户给《无双》评分还是挺高的,力荐42%,推荐46%,意味着好评就占了88%了。
在全部评论中,有赞同评论和反对评论数量统计,分析数据如下图:
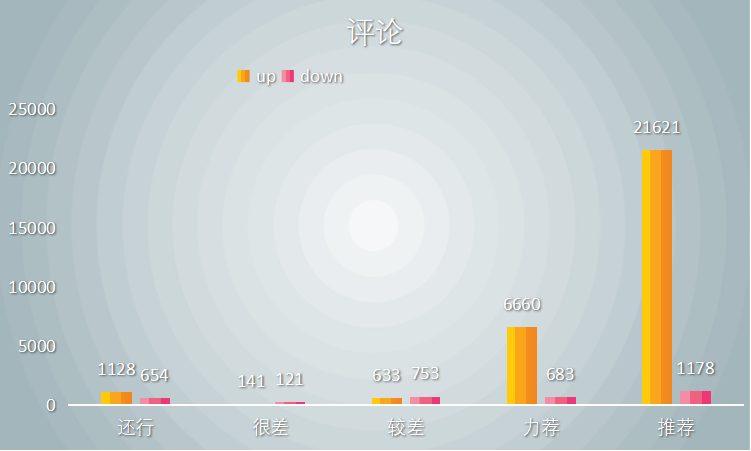
如上图统计表所示,用户评论给电影《无双》星级评分“力荐”和“推荐”的,赞同数远远高于所有,说明用户给出的评分还是被绝大多数人认可的,也证明《无双》对的起豆瓣的8.1评分,是一部值得推荐的好电影。
再来看看关键的评论字眼:


总结:
1.《无双》这部影片,在国产影片中,还是比较不错的,虽然它是在香港主拍,但也融入了很多内地的元素,结合的不错。
2.根据用户评论的关键词中可见,港片千年好评的警匪题材还是一样受欢迎。
3.‘剧情’、‘反转’、‘真’、‘架’是《无双》的评论关键字眼,只有这样结局出乎意料、有些思考逻辑、新奇的剧情的影片,才可能会深受网友欢迎
4.网友对影片的要求还是:影片不要太过于浅显易懂,能让人引发思考的更能吸引要求和更能体现好片的趋向
完整代码:
import requests import bs4 from bs4 import BeautifulSoup as bs from datetime import datetime import re import pandas as pd from lxml import etree import time import random import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt from scipy.misc import imread import fake_useragent from fake_useragent import UserAgent def headerRandom(): ua = UserAgent() uheader=ua.random return uheader def url_xp(url): header={'User-Agent':headerRandom(), 'referer': 'https: // movie.douban.com / subject / 26425063 / collections', 'host': 'movie.douban.com'} cookie={'Cookie':'bid=1b6T3XfY1Lg; ll="118296"; __yadk_uid=8Rh5yYIVjjTiWVlvXwLMTjTiysdDbnhc; _vwo_uuid_v2=D004713234FC45F9F75852DA2C22AA70D|64d0230cd2e8f38db28c1e01475587bc; douban-fav-remind=1; __utma=30149280.1603033016.1527918356.1539482818.1555739204.4; __utmc=30149280; __utmz=30149280.1555739204.4.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; dbcl2="195240672:1OaW66LYWvU"; ck=XrRZ; ap_v=0,6.0; push_noty_num=0; push_doumail_num=0; __utmv=30149280.19524; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1555739431%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=223695111.1276142029.1532846523.1532846523.1555739431.2; __utmb=223695111.0.10.1555739431; __utmc=223695111; __utmz=223695111.1555739431.2.1.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; douban-profile-remind=1; __utmt=1; __utmb=30149280.14.10.1555739204; _pk_id.100001.4cf6=d5d70594f72eeb39.1532846523.2.1555744004.1532846523.'} response = requests.get(url=url,cookies=cookie,headers=header) time.sleep(random.random() * 2) response.encoding = 'utf-8' soup = bs(response.content,"lxml") return soup def url_bs(url): header={'User-Agent':headerRandom(), 'referer': 'https: // movie.douban.com / subject / 26425063 / collections', 'host': 'movie.douban.com'} cookie={'Cookie':'bid=1b6T3XfY1Lg; ll="118296"; __yadk_uid=8Rh5yYIVjjTiWVlvXwLMTjTiysdDbnhc; _vwo_uuid_v2=D004713234FC45F9F75852DA2C22AA70D|64d0230cd2e8f38db28c1e01475587bc; douban-fav-remind=1; __utma=30149280.1603033016.1527918356.1539482818.1555739204.4; __utmc=30149280; __utmz=30149280.1555739204.4.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; dbcl2="195240672:1OaW66LYWvU"; ck=XrRZ; ap_v=0,6.0; push_noty_num=0; push_doumail_num=0; __utmv=30149280.19524; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1555739431%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=223695111.1276142029.1532846523.1532846523.1555739431.2; __utmb=223695111.0.10.1555739431; __utmc=223695111; __utmz=223695111.1555739431.2.1.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; douban-profile-remind=1; __utmt=1; __utmb=30149280.14.10.1555739204; _pk_id.100001.4cf6=d5d70594f72eeb39.1532846523.2.1555744004.1532846523.'} response = requests.get(url=url,cookies=cookie,headers=header) time.sleep(random.random() * 2) response.encoding = 'utf-8' soup = bs(response.text, 'html.parser') return soup #评论用户名 def user(url): html = etree.HTML(url_xp(url).decode()) users= html.xpath("//div[@class='main review-item']//a[@class='name']//text()") return users #时间 def times(url): html = etree.HTML(url_xp(url).decode()) time= html.xpath("//div[@class='main review-item']//span[@class='main-meta']//text()") timeList = [] for i in time: now1 = datetime.strptime(i, '%Y-%m-%d %H:%M:%S') newstime = datetime.strftime(now1, '%Y{y}-%m{m}-%d{d} %H{H}:%M{M}:%S{S}').format(y='年', m='月', d='日', H='时', M='分', S='秒') timeList.append(newstime) return timeList #星级 def levels(url): html = etree.HTML(url_xp(url).decode()) level = html.xpath("//div[@class='main review-item']//span//@title") return level #用户id def userId(url): html = etree.HTML(url_xp(url).decode()) ids = html.xpath("//div[@class='review-list']//div//@data-cid") return ids #评论 def comments(url): commentList = [] #根据每个用户的id,获取评论 for i in userId(url): curl = 'https://movie.douban.com/j/review/{}/full'.format(i) o = url_bs(curl).text #re正则匹配中文 pinglun = re.findall(r'[u4e00-u9fa5]+', o) strs = '' for j in pinglun: strs = strs + j + ',' commentList.append(strs) return commentList #有用的数量 def yes(url): html = etree.HTML(url_xp(url).decode()) count = html.xpath("//div[@class='action']//a[@class='action-btn up']//span//text()") yy = [] for i in count: yy.append(i.replace(' ', '').replace(' ', '')) return yy #没用的数量 def no(url): html = etree.HTML(url_xp(url).decode()) count = html.xpath("//div[@class='action']//a[@class='action-btn down']//span//text()") nn = [] for i in count: nn.append(i.replace(' ', '').replace(' ', '')) return nn #字典 def dist(url): uu = user(url) tt = times(url) ll = levels(url) cc=comments(url) yy=yes(url) nn=no(url) new_list = [] new_dict = [] mid = map(list, zip(uu, tt, ll,cc,yy,nn)) for item in mid: new_dict = dict(zip(['user', 'time', 'level','comments','up','down'], item)) new_list.append(new_dict) return new_list #保存评论 def save_comment(url): co = comments(url) print("第 1 页爬取完成!") j=1 for i in range(2, 279): if i % 2 == 0: url = 'https://movie.douban.com/subject/26425063/reviews?start={}'.format(str(i) + '0') j=j+1 else: continue co.extend(comments(url)) print("第",j,"页爬取完成!") file = open(r'F:doubancomments.txt', 'a', encoding='utf-8') for i in range(len(co)): s = co[i] + ' ' file.write(s) file.close() #读取评论、分词 def cut_comment(): file = open(r'F:doubancomments.txt', 'r', encoding='utf-8').read() ss = ",。;!?”“ ufeff" for i in ss: file = file.replace(i, '') # 分词 cun = jieba.lcut(file) return cun #去除停用词 def cut_stop(): #读取停用词 fe = open(r'F:doubanstops_chinese.txt', 'r', encoding='UTF-8').read() stops = fe.split(' ') tokens = [token for token in cut_comment() if token not in stops] return tokens #关键词统计 def count_comment(): diss = {} for j in cut_stop(): if j not in diss: diss[j] = 1 else: diss[j] = diss[j] + 1 words_list = list(diss.items()) words_list.sort(key=getNumber, reverse=True) return words_list #处理数字 def getNumber(x): y=x[1] return y #词云 def show_comment(): # 读入图片 im = imread(r'F:douban img.jpg') wl_split = ''.join(cut_comment()) mywc = WordCloud( mask=im, height=600, width=800, background_color='#000000', max_words=1000, max_font_size=200, font_path="C:WindowsFontsmsyh.ttc" ).generate(wl_split) plt.imshow(mywc) plt.axis("off") # 显示词云 plt.show() url='https://movie.douban.com/subject/26425063/reviews' cc='https://movie.douban.com/j/review/9682284/full' #用户、评论日期、评分 datas = dist(url) print("第 1 页爬取完成!") j = 1 for i in range(2, 279): if i % 2 == 0: url = 'https://movie.douban.com/subject/26425063/reviews?start={}'.format(str(i) + '0') j = j + 1 else: continue datas.extend(dist(url)) print("第", j, "页爬取完成!") newsdf = pd.DataFrame(datas) newsdf.to_csv(r'F:doubandouban.csv',mode='a') save_comment(url) for i in range(20): print(count_comment()[i]) show_comment()