作为初学者,现在接触的数据库都属于比较小的哪一种,对于数据库处理以及所提供的数据操纵等功能并没有很深刻的认识。所以接触较大的数据量以及比较复杂的查询操作是进一步认识数据库强大的必要过程。不过在处理较大数据量之前还是要将基础的知识学扎实。
先从比较小的数据量开始。
例1
下面列举一个高中某班高考录取情况的表格。
要求:
1.按照大学名称进行降序排列,将结果另存为csv文件
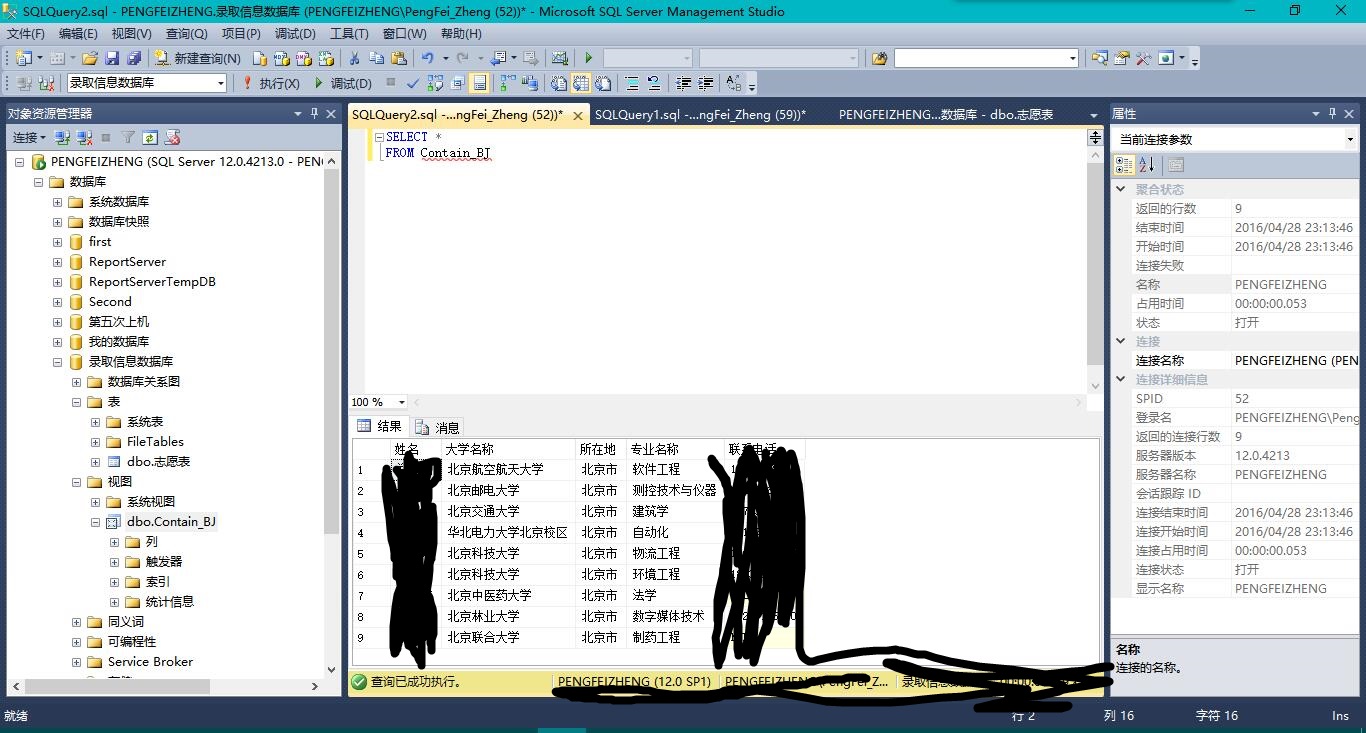
2.创建一个视图,显示找到大学名称中包含‘北京’二字的所有信息,将结果另存为csv文件
实现工具:SQL Server 2014 、以及录取情况的表格
过程:
1.创建一个表(这里命名为志愿表吧)
可以选择使用SQL语言创建新表
create table 志愿表( 姓名 varchar(50) not null, 大学名称 varchar(50), 所在地 varchar(50), 专业名称 varchar(50), 联系电话 varchar(50) )
同样也可以选择按照SQL Server直接构建新表操作。

2.导入数据
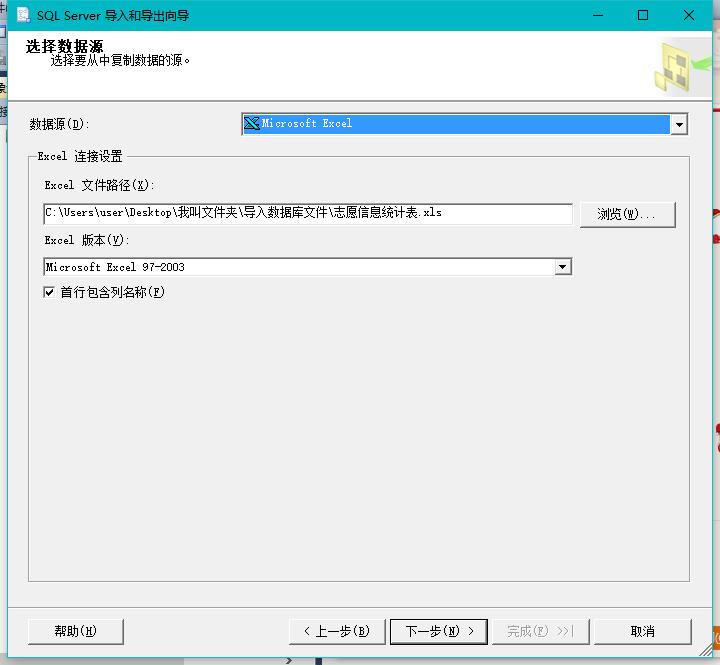
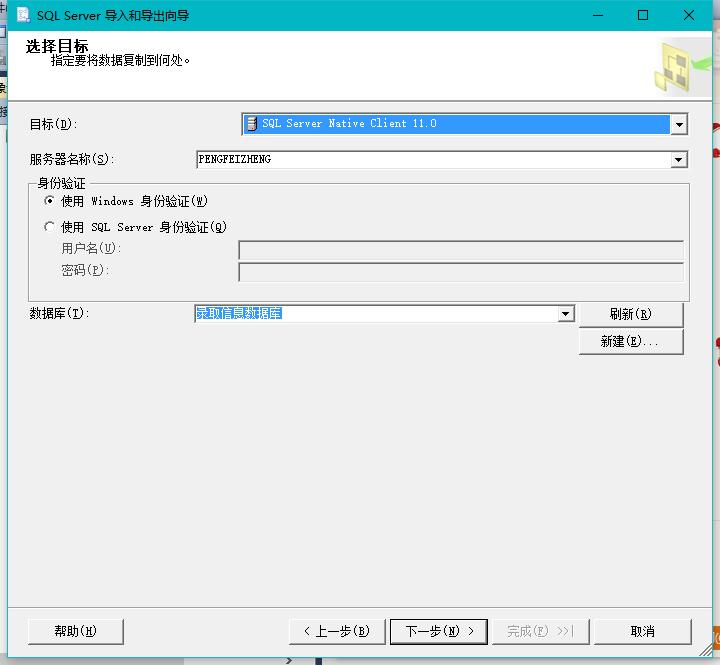
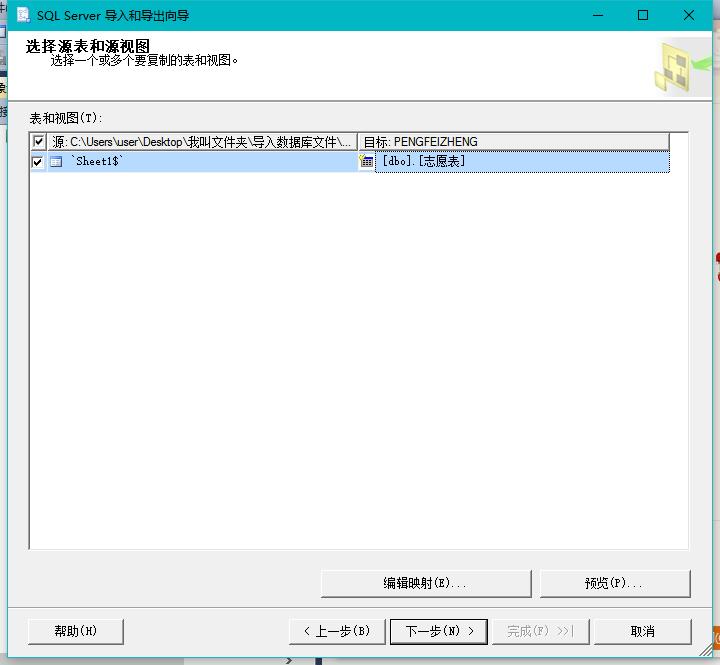
步骤:在自己创建的数据库点击右键--->选择任务--->选择导入数据--->选择导入数据类型(这里的数据存放在xls也就是excel表中,因此这里选择Microsoft Excel文件(注意这里有个选项叫做'首行包含列名称',意思就是excel表的首行就是创建的表的列名),这里用的数据包含了列名称,因此下面截图选择了该选项)---->选择目标(SQL Server Native Client 11.0 数据库就选择自己创建的数据库)---->选择源表和源视图(这里源视图就选择自己创建的志愿表)---->然后进行导入。
3.检查一下数据是否导入
use 录取信息数据库 SELECT * FROM dbo.志愿表

4.完成第一个要求
按照大学名称进行降序排列,将结果另存为csv文件
use 录取信息数据库 SELECT * FROM dbo.志愿表 ORDER BY 大学名称 DESC
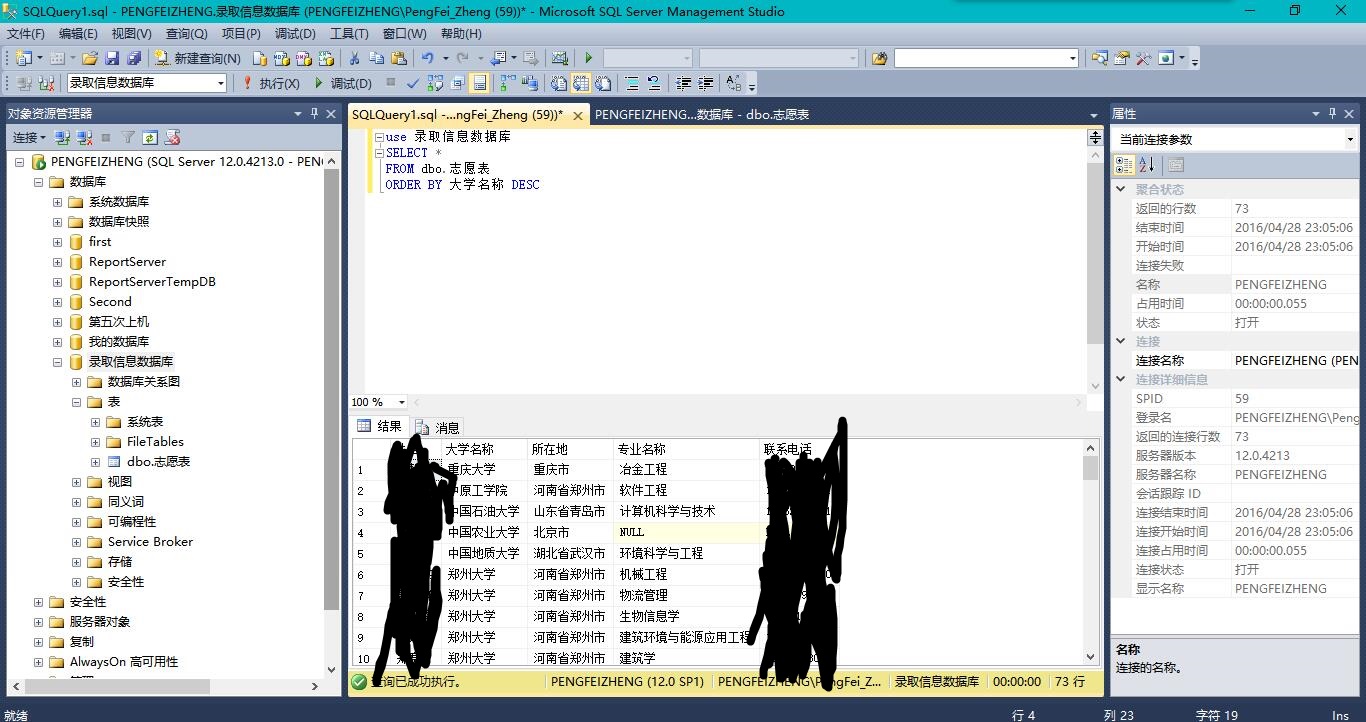
5.完成第二个要求
创建一个视图,显示找到大学名称中包含‘北京’二字的所有信息,将结果另存为csv文件
CREATE VIEW Contain_BJ AS( SELECT * FROM dbo.志愿表 WHERE 大学名称 LIKE '%北京%');