很早之前就写了这个代码,今天重新更新一下
发现对千分位数字的匹配有些bug
另外对来自不同地区的数据没进行爬取。
爬取数据:http://s04.flagcounter.com/more7/XTPq/
处理逻辑:
1. 爬取数据
2. 构造数组:日期,博客访问量,flag访问量
3. 保存数据到文件
4. 保存pickle文件
5. 生成访问折线图
爬取代码如下所示,详细代码见开源访问:https://github.com/zpfbuaa/blogVisitors
# -*- coding: utf-8 -*- # @Time : 2018/5/25 下午1:15 # @Author : 伊甸一点 # @FileName: getHtml.py # @Software: PyCharm # @Blog : http://zpfbuaa.github.io import requests import re import time import os date_pt = re.compile('<font face=arial size=-1>(w+ d+, d+)') visitors_pt = re.compile('<font face=arial size=2>(w+)</td><td>') flagViews_pt = re.compile('<font face=arial size=2>(S+)</font></td></tr>') def getTotalBlog(url, pages): date = [] visitors = [] flagViews = [] for page in range(1, pages+1): newUrl = url + str(page) print(newUrl) html = requests.get(newUrl).text item_date = date_pt.findall(html) item_visitors = visitors_pt.findall(html) item_flagViews = flagViews_pt.findall(html) date.extend(item_date) visitors.extend(item_visitors) flagViews.extend(item_flagViews) return date, visitors, flagViews def change_data(date, visitors, flagViews): print(len(visitors)) print(len(flagViews)) for i in range(0, len(date)): str_visitor = str(visitors[i]) str_flagViews = str(flagViews[i]) if (str_visitor.find(',') != -1): v_split = str_visitor.split(',') visitors[i] = int(v_split[0]) * 1000 + int(v_split[1]) else: visitors[i] = int(str_visitor) if (str_flagViews.find(',') != -1): f_split = str_flagViews.split(',') flagViews[i] = int(f_split[0]) * 1000 + int(f_split[1]) else: flagViews[i] = int(str_flagViews) return date, visitors, flagViews def printData(date, visitors, flagViews): print('Date Visitors Flag Counter Views') for i in range(0, len(date)): print(date[i],visitors[i],flagViews[i]) def writeToFile(date, visitors, flagViews, data_root='data/'): today = time.strftime('%Y%m%d', time.localtime(time.time())) data_file = data_root+'blog_'+str(today) f = open(data_file,'w+') header = 'Date Visitors Flag Counter Views'+' ' f.write(header) for i in range(0, len(date)): line = date[i]+' '+str(visitors[i])+' '+str(flagViews[i])+' ' f.write(line) f.close() return 1 url = 'http://s04.flagcounter.com/more7/XTPq/' pages = 23 date, visitors, flagViews = getTotalBlog(url, pages) # printData(date, visitors, flagViews) date, visitors, flagViews = change_data(date, visitors, flagViews) # printData(date, visitors, flagViews) flag = writeToFile(date, visitors, flagViews) print('Data Prepare Done!')
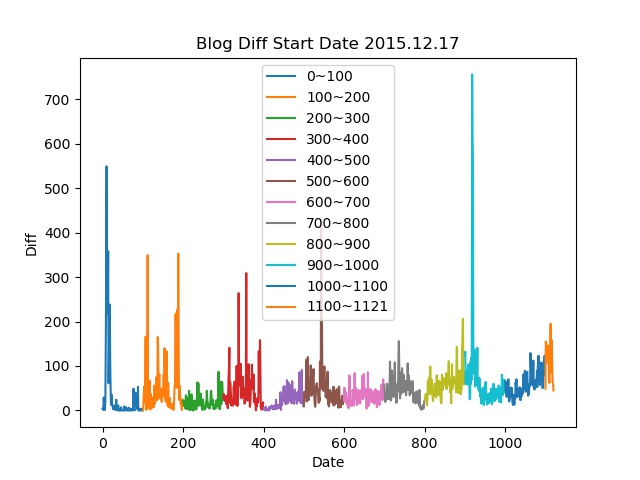
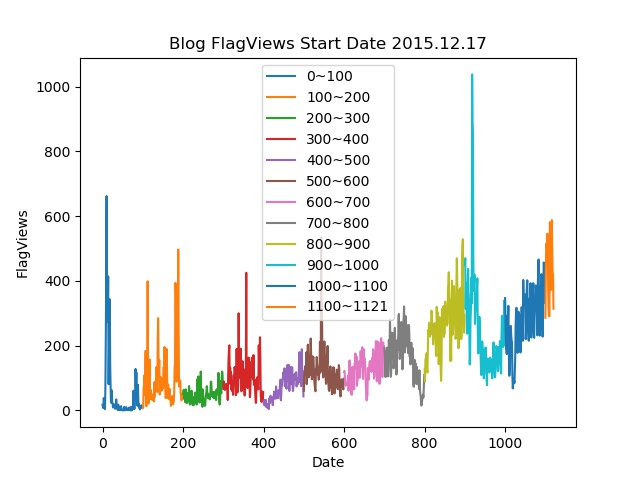
以下为截止到当前2019年01月12日的访问量折线图
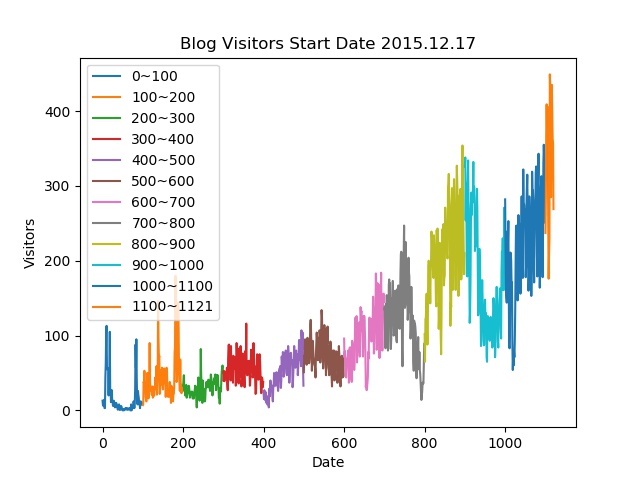
访问入口flag统计图
两者diff差值