实现爬取一个大V的知乎用户开始爬取开始,我选了轮子哥,然后通过爬取轮子哥的粉丝和他关注的用户信息,再逐一对爬取到的用户进行进一步地获取粉丝和关注的用户信息,这样一直爬下去就能爬到很多很多用户,相当于能够把知乎所有的用户都能够爬取完,不过有一点不太完善的地方就是我这个需要在中间的时候中断爬虫,不然的话会被知乎反爬虫策略给禁掉IP,因为这段反爬虫还没有学会,感觉好像有点卡住了,之后解决了就会重新上代码,现在就出来一个初始版的吧
废话不多说,贴代码:(当然爬取的第一步就是对知乎网站的一个分析,就是看一下到底是怎么加载出来的,就比如说这个就是Ajax局部刷新的,对于之前进行过Java和C#开的的人来说,处理Json文件对于html代码来说感觉更加地舒服和爽)
zhihu.py(spiders里面的爬虫逻辑):
# -*- coding: utf-8 -*-
import json
import scrapy
from zhihuUser.items import UserItem
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
start_user='excited-vczh'
follow_url='https://www.zhihu.com/api/v4/members/{user}/{follow}?include={include}&offset={offset}&limit={limit}'
follow_include='data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics'
user_url='https://www.zhihu.com/api/v4/members/{user}?include={include}'
user_include='allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics'
def start_requests(self): #这个就是刚开始的时候的url地址
#<editor-fold desc="起始信息">
#用户的详细信息
# url='https://www.zhihu.com/api/v4/members/joan-84-74?include=allow_message%2Cis_followed%2Cis_following%2Cis_org%2Cis_blocking%2Cemployments%2Canswer_count%2Cfollower_count%2Carticles_count%2Cgender%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics'
#用户的关注列表信息
# url = 'https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20'
#</editor-fold>
#一个是起始的用户信息(轮子哥),起始的关注者和粉丝列表的爬取
yield scrapy.Request(self.user_url.format(user=self.start_user, include=self.user_include),callback=self.parse_user)
yield scrapy.Request(self.follow_url.format(user=self.start_user, follow='followers', include=self.follow_include, offset=0,limit=20), callback=self.parse_follow)
yield scrapy.Request(self.follow_url.format(user=self.start_user,follow='followees',include=self.follow_include,offset=0,limit=20),callback=self.parse_follow)
def parse_user(self, response):
results=json.loads(response.text)
item=UserItem()
for field in item.fields:
if field in results.keys():
item[field]=results.get(field)
yield item
yield scrapy.Request(self.follow_url.format(user=results.get('url_token'), follow='followers', include=self.follow_include,offset=0, limit=20), callback=self.parse_follow)
yield scrapy.Request(self.follow_url.format(user=results.get('url_token'),follow='followees',include=self.follow_include,offset=0,limit=20),callback=self.parse_follow)
def parse_follow(self, response):
results=json.loads(response.text)
if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_url.format(user=result.get('url_token'),include=self.user_include),callback=self.parse_user)
if 'paging' in results.keys():
if results.get('paging').get('is_end')==False:
next_page=results.get('paging').get('next')
yield scrapy.Request(next_page,callback=self.parse_follow)
items.py(这个就是一个存储的字段的一个字段的结构了,因为麻烦,就贴了这么几条字段信息,如果你觉得少的话自己再多贴几条上去)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
from scrapy import Field,Item
class UserItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
avatar_url=Field()
headline=Field()
id=Field()
name=Field()
type=Field()
url=Field()
url_token=Field()
pipeline.py(对item进行处理,这里主要就是储存到数据库中去):
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
class MongoDbPipeline(object):
def __init__(self,mongoUrl,mongoDb):
self.mongourl=mongoUrl
self.mongodb=mongoDb
@classmethod
def from_crawler(cls, crawler):
return cls(
mongoUrl=crawler.settings.get('MONGOURL'),
mongoDb=crawler.settings.get('MONGODB')
)
def open_spider(self,spider):
self.client=pymongo.MongoClient(self.mongourl) #只要是用self都会设置一个全局的变量
self.db=self.client[self.mongodb]
def close_spider(self,spider):
self.client.close()
def process_item(self, item, spider):
name=item.__class__.__name__
self.db[name].update({'url_token':item['url_token']},{'$set':item},True)
return item
还有最后记得在settings中把pipeline给启用上还有里面的几个变量的赋值,我这里也贴上吧
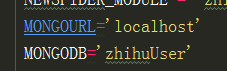
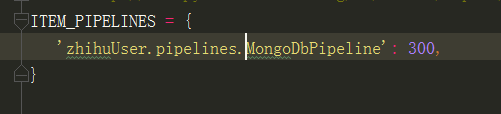
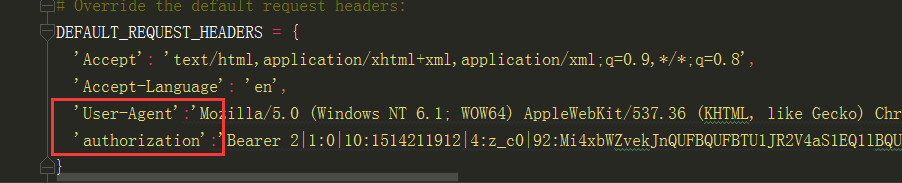
刚刚去看了一下settings的信息,值得注意的就是记得把settings里面的robots规则改为false,还有就是要记得有user—Agent信息(不然服务器会没有响应),
还有一个就是登陆的信息,我记得有些好像是cookie,这个好像是不一样的