摘要:上次我们学习了 Golang 的 goroutine 调度策略,今天我们来学习 Golang 的内存管理策略。
思考内存管理如何设计
内存池
最直接的方式是调用 malloc函数,指定要分配的大小,直接向操作系统申请。问题是这种方式会涉及到用户态和内核态的切换过程,那么频繁的切换就会带来很大的性能下降,我们要减少用户态和内核态的频繁切换就需要自己申请一块内存空间,将之分割成大小规格不同的内存块来供程序使用,内存池是再适合不过的组成部分。
GC
内存管理不光需要使用方便,还要保证内存使用过程能够节约,毕竟整个系统的内存资源是有限的,那么就需要GC进行动态的垃圾回收,销毁无用的对象,释放内存来保证整个程序乃至系统运行平稳。
锁
一个应用程序内部之间存在大量的线程,线程之间资源是共享的,那么要保证同一块内存使用过程不出现复用或者污染,就必须保证同一时间只能有一个线程进行申请,第一个想到的肯定是锁,对公共区域的资源一定要加锁,另一种方式就是内存隔离,这个在golang的mcache中会有体现。
基本概念
page
操作系统内存管理中,内存的最粒度是4KB,也就是说分配内存最小4KB起。而golang里面一个page是8KB。
span
span是golang内存管理的基本单位,每个span管理指定规格(以golang 中的 page为单位)的内存块,内存池分配出不同规格的内存块就是通过span体现出来的,应用程序创建对象就是通过找到对应规格的span来存储的,下面是 mspan 结构中的主要部分。


//gosrc untimemheap.go //go:notinheap type mspan struct { next *mspan // next span in list, or nil if none prev *mspan // previous span in list, or nil if none startAddr uintptr // address of first byte of span aka s.base() npages uintptr // number of pages in span nelems uintptr // number of object in the span. allocCache uint64 allocBits *gcBits //bitmap gcmarkBits *gcBits //bitmap baseMask uint16 // if non-0, elemsize is a power of 2, & this will get object allocation base allocCount uint16 // number of allocated objects spanclass spanClass // size class and noscan (uint8) }
那么要想区分不同规格的span,我们必须要有一个标识,每个span通过spanclass标识属于哪种规格的span,golang的span规格一共有67种,具体如下:
//from runtime.gosizeclasses.go // class bytes/obj bytes/span objects tail waste max waste // 1 8 8192 1024 0 87.50% // 2 16 8192 512 0 43.75% // 3 32 8192 256 0 46.88% // 4 48 8192 170 32 31.52% // 5 64 8192 128 0 23.44% // 6 80 8192 102 32 19.07% // 7 96 8192 85 32 15.95% // 8 112 8192 73 16 13.56% // 9 128 8192 64 0 11.72% // 10 144 8192 56 128 11.82% // 11 160 8192 51 32 9.73% // 12 176 8192 46 96 9.59% // 13 192 8192 42 128 9.25% // 14 208 8192 39 80 8.12% // 15 224 8192 36 128 8.15% // 16 240 8192 34 32 6.62% // 17 256 8192 32 0 5.86% // 18 288 8192 28 128 12.16% // 19 320 8192 25 192 11.80% // 20 352 8192 23 96 9.88% // 21 384 8192 21 128 9.51% // 22 416 8192 19 288 10.71% // 23 448 8192 18 128 8.37% // 24 480 8192 17 32 6.82% // 25 512 8192 16 0 6.05% // 26 576 8192 14 128 12.33% // 27 640 8192 12 512 15.48% // 28 704 8192 11 448 13.93% // 29 768 8192 10 512 13.94% // 30 896 8192 9 128 15.52% // 31 1024 8192 8 0 12.40% // 32 1152 8192 7 128 12.41% // 33 1280 8192 6 512 15.55% // 34 1408 16384 11 896 14.00% // 35 1536 8192 5 512 14.00% // 36 1792 16384 9 256 15.57% // 37 2048 8192 4 0 12.45% // 38 2304 16384 7 256 12.46% // 39 2688 8192 3 128 15.59% // 40 3072 24576 8 0 12.47% // 41 3200 16384 5 384 6.22% // 42 3456 24576 7 384 8.83% // 43 4096 8192 2 0 15.60% // 44 4864 24576 5 256 16.65% // 45 5376 16384 3 256 10.92% // 46 6144 24576 4 0 12.48% // 47 6528 32768 5 128 6.23% // 48 6784 40960 6 256 4.36% // 49 6912 49152 7 768 3.37% // 50 8192 8192 1 0 15.61% // 51 9472 57344 6 512 14.28% // 52 9728 49152 5 512 3.64% // 53 10240 40960 4 0 4.99% // 54 10880 32768 3 128 6.24% // 55 12288 24576 2 0 11.45% // 56 13568 40960 3 256 9.99% // 57 14336 57344 4 0 5.35% // 58 16384 16384 1 0 12.49% // 59 18432 73728 4 0 11.11% // 60 19072 57344 3 128 3.57% // 61 20480 40960 2 0 6.87% // 62 21760 65536 3 256 6.25% // 63 24576 24576 1 0 11.45% // 64 27264 81920 3 128 10.00% // 65 28672 57344 2 0 4.91% // 66 32768 32768 1 0 12.50%
另外上表可见最大的对象是32KB大小,超过32KB大小的由特殊的class表示,该class ID为0,每个class只包含一个对象。所以上面只有列出了1-66。
下面还要三个数组,分别是:class_to_size,size_to_class和class_to_allocnpages3个数组,对应下图上的3个箭头:
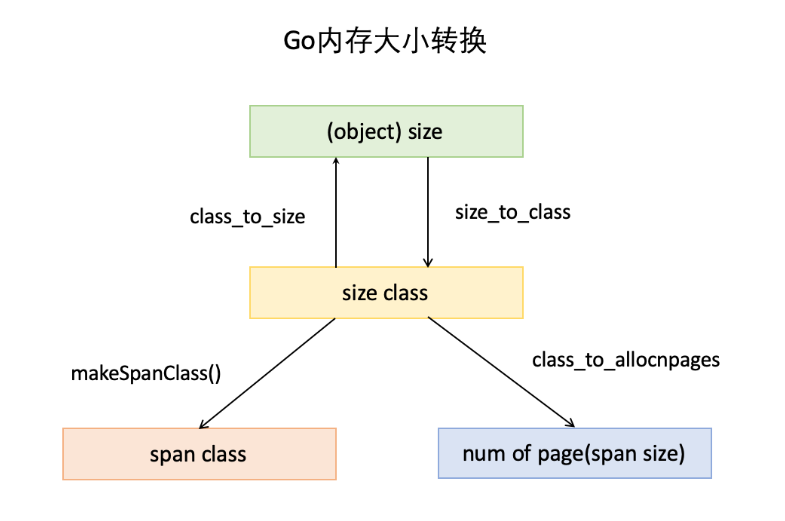
比如:我们只拿第一行举例:
// class bytes/obj bytes/span objects tail waste max waste // 1 8 8192 1024 0 87.50%
就是类别1的对象大小是8bytes,所以class_to_size[1]=8;span大小是8KB,为1页,所以class_to_allocnpages[1]=1
mcache
mcache保存的是各种大小的Span,并按Span class分类,小对象(<=32KB)直接从mcache分配内存,它起到了缓存的作用,并且可以无锁访问。mcache是每个逻辑处理器(P)的本地内存线程缓存。Go中是每个P只拥有1个mcache,所以不用加锁。另外,mcache中每个级别的Span有2类数组链表,但是合在一起的(alloc成员变量)。
//from runtime.gomcache.go type mcache struct { local_scan uintptr // bytes of scannable heap allocated tiny uintptr tinyoffset uintptr local_tinyallocs uintptr // number of tiny allocs not counted in other stats // The rest is not accessed on every malloc. alloc [numSpanClasses]*mspan // numSpanClasses 为 2*67 stackcache [_NumStackOrders]stackfreelist //每个 G 绑定的栈空间 }
mcentral
它按Span class对Span分类,串联成链表,当mcache的某个级别Span的内存被分配光时,它会向mcentral申请1个当前级别的Span。所有线程共享的缓存,需要加锁访问。
//from runtime.gomcentral.go type mcentral struct { lock mutex spanclass spanClass // For !go115NewMCentralImpl. nonempty mSpanList // list of spans with a free object, ie a nonempty free list empty mSpanList // list of spans with no free objects (or cached in an mcache) partial [2]spanSet // list of spans with a free object full [2]spanSet // list of spans with no free objects nmalloc uint64 }
每个mcentral包含两个mspanList
- empty:双向span链表,包括没有空闲对象的span或缓存mcache中的span。当此处的span被释放时,它将被移至non-empty span链表。
- non-empty:有空闲对象的span双向链表。当从mcentral请求新的span,mcentral将从该链表中获取span并将其移入empty span链表。
mheap
它把从OS申请出的内存页组织成Span,并保存起来。当mcentral的Span不够用时会向mheap申请,mheap的Span不够用时会向OS申请,向OS的内存申请是按页来的,然后把申请来的内存页生成Span组织起来,同样也是需要加锁访问的。大对象(>32KB)直接从mheap上分配。
//from runtime.gomheap.go type mheap struct { // lock must only be acquired on the system stack, otherwise a g // could self-deadlock if its stack grows with the lock held. lock mutex pages pageAlloc // page allocation data structure sweepgen uint32 // sweep generation, see comment in mspan; written during STW sweepdone uint32 // all spans are swept sweepers uint32 // number of active sweepone calls allspans []*mspan // all spans out there }
mhead 的结构相对比较复杂,我们知道每个golang程序启动时候会向操作系统申请一块虚拟内存空间,仅仅是虚拟内存空间,真正需要的时候才会发生缺页中断,向系统申请真正的物理空间,在golang1.11版本以后,申请的内存空间会放在一个heapArena数组里,由arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena表示,用于应用程序内存分配,根据源码公式,在64位非windows系统分配大小是64MB,windows 64位是4MB。
内存分配过程
分配过程总览图
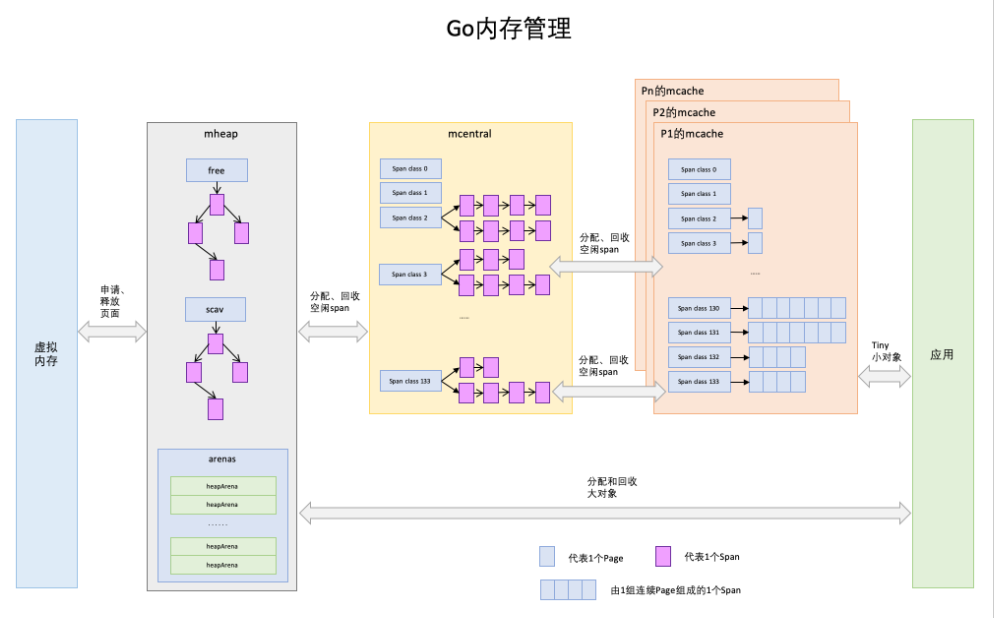
内存关系总览图

简单分配规则
-
tiny对象内存分配,直接向mcache的tiny对象分配器申请,如果空间不足,则向mcache的tinySpanClass规格的span链表申请,如果没有,则向mcentral申请对应规格mspan,依旧没有,则向mheap申请,最后都用光则向操作系统申请。
-
小对象内存分配,先向本线程mcache申请,发现mspan没有空闲的空间,向mcentral申请对应规格的mspan,如果mcentral对应规格没有,向mheap申请对应页初始化新的mspan,如果也没有,则向操作系统申请,分配页。
-
大对象内存分配,直接向mheap申请spanclass=0,如果没有则向操作系统申请。
源码分析
对象分配入口
Tiny 对象(<16B)的分配: golang会通过tiny和tinyoffset组合寻找位置分配内存空间,这样可以更好的节约空间
//from runtime.gomalloc.go //Tiny 对象的分配过程 //step1:先进行内存对齐 off := c.tinyoffset // Align tiny pointer for required (conservative) alignment. if size&7 == 0 { off = alignUp(off, 8) } else if size&3 == 0 { off = alignUp(off, 4) } else if size&1 == 0 { off = alignUp(off, 2) } //step2: 看 tinySpanClass 是否还可以放下当前的 Tiny 对象,如果放不下,再申请一个类型为 tinySpanClass&&noscan 的 span if off+size <= maxTinySize && c.tiny != 0 { // The object fits into existing tiny block. x = unsafe.Pointer(c.tiny + off) c.tinyoffset = off + size c.local_tinyallocs++ mp.mallocing = 0 releasem(mp) return x }else { // otherwise Allocate a new maxTinySize block. span = c.alloc[tinySpanClass] }
小对象[16B, 32KB]的分配:会使用这部分span进行正常的内存分配
//from runtime.gomalloc.go var sizeclass uint8 //step1: 确定规格sizeClass if size <= smallSizeMax-8 { sizeclass = size_to_class8[divRoundUp(size, smallSizeDiv)] } else { sizeclass = size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)] } size = uintptr(class_to_size[sizeclass]) spc := makeSpanClass(sizeclass, noscan) //step2: 分配对应spanClass 的 span span = c.alloc[spc] v := nextFreeFast(span) if v == 0 { v, span, shouldhelpgc = c.nextFree(spc) } x = unsafe.Pointer(v) if needzero && span.needzero != 0 { memclrNoHeapPointers(unsafe.Pointer(v), size) }
大对象(>32KB)的分配:直接在 mheap 上进行分配
//from runtime.gomalloc.go shouldhelpgc = true systemstack(func() { //分配大对象 span = largeAlloc(size, needzero, noscan) }) span.freeindex = 1 span.allocCount = 1 x = unsafe.Pointer(span.base()) size = span.elemsize
向上级申请资源
mcache 向 mcentral 申请: 调用 src untimemcache.go refill 方法
func (c *mcache) refill(spc spanClass) { // Return the current cached span to the central lists. s := c.alloc[spc] if uintptr(s.allocCount) != s.nelems { throw("refill of span with free space remaining") } // Get a new cached span from the central lists. //step1: 从 mcentral 获取资源 s = mheap_.central[spc].mcentral.cacheSpan() if s == nil { throw("out of memory") } if uintptr(s.allocCount) == s.nelems { throw("span has no free space") } // Indicate that this span is cached and prevent asynchronous // sweeping in the next sweep phase. s.sweepgen = mheap_.sweepgen + 3 //step2: 放入mcache 中 c.alloc[spc] = s }
mcentral 向 mheap 申请: 调用 src untimemcental.go grow方法
// grow allocates a new empty span from the heap and initializes it for c's size class. func (c *mcentral) grow() *mspan { npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) size := uintptr(class_to_size[c.spanclass.sizeclass()]) s := mheap_.alloc(npages, c.spanclass, true) if s == nil { return nil } // Use division by multiplication and shifts to quickly compute: // n := (npages << _PageShift) / size n := (npages << _PageShift) >> s.divShift * uintptr(s.divMul) >> s.divShift2 s.limit = s.base() + size*n heapBitsForAddr(s.base()).initSpan(s) return s }
mheap 向 os 申请: 调用src
untimemheap.go grow方法
// Try to add at least npage pages of memory to the heap, // returning whether it worked. // // h must be locked. func (h *mheap) grow(npage uintptr) bool { // We must grow the heap in whole palloc chunks. ask := alignUp(npage, pallocChunkPages) * pageSize totalGrowth := uintptr(0) // This may overflow because ask could be very large // and is otherwise unrelated to h.curArena.base. end := h.curArena.base + ask nBase := alignUp(end, physPageSize) if nBase > h.curArena.end || /* overflow */ end < h.curArena.base { // Not enough room in the current arena. Allocate more // arena space. This may not be contiguous with the // current arena, so we have to request the full ask. av, asize := h.sysAlloc(ask) if av == nil { print("runtime: out of memory: cannot allocate ", ask, "-byte block (", memstats.heap_sys, " in use) ") return false } if uintptr(av) == h.curArena.end { // The new space is contiguous with the old // space, so just extend the current space. h.curArena.end = uintptr(av) + asize } else { // The new space is discontiguous. Track what // remains of the current space and switch to // the new space. This should be rare. if size := h.curArena.end - h.curArena.base; size != 0 { h.pages.grow(h.curArena.base, size) totalGrowth += size } // Switch to the new space. h.curArena.base = uintptr(av) h.curArena.end = uintptr(av) + asize } // The memory just allocated counts as both released // and idle, even though it's not yet backed by spans. // // The allocation is always aligned to the heap arena // size which is always > physPageSize, so its safe to // just add directly to heap_released. mSysStatInc(&memstats.heap_released, asize) mSysStatInc(&memstats.heap_idle, asize) // Recalculate nBase. // We know this won't overflow, because sysAlloc returned // a valid region starting at h.curArena.base which is at // least ask bytes in size. nBase = alignUp(h.curArena.base+ask, physPageSize) } // Grow into the current arena. v := h.curArena.base h.curArena.base = nBase h.pages.grow(v, nBase-v) totalGrowth += nBase - v // We just caused a heap growth, so scavenge down what will soon be used. // By scavenging inline we deal with the failure to allocate out of // memory fragments by scavenging the memory fragments that are least // likely to be re-used. if retained := heapRetained(); retained+uint64(totalGrowth) > h.scavengeGoal { todo := totalGrowth if overage := uintptr(retained + uint64(totalGrowth) - h.scavengeGoal); todo > overage { todo = overage } h.pages.scavenge(todo, false) } return true }
参考资料: