今天,简单的聊聊架构方案,我们是如何平滑进行机房迁移的。
【1】核心问题一,被迁移的系统是一个什么样的架构呢?
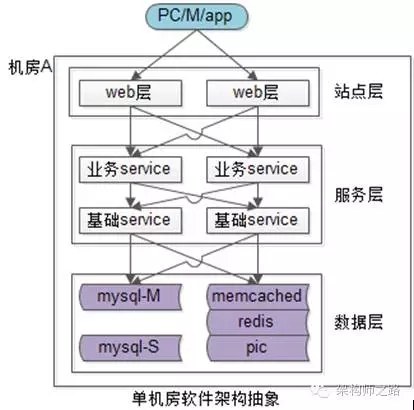
上图是一个典型的互联网单机房系统架构:
- 上游是客户端,PC浏览器或者APP;
- 然后是站点接入层,做了高可用集群;
- 接下来是服务层,服务层又分为两层,业务服务层和基础服务层,也都做了高可用集群;
- 底层是数据层,包含缓存与数据库;
该单机房分层架构,所有的应用、服务、数据是部署在同一个机房,其架构特点是“全连接”:
- 站点层调用业务服务层,业务服务复制了多少份,上层就要连接多少个服务;
- 业务服务层调用基础服务层,基础服务复制了多少份,上层就要连多少个服务;
- 服务层调用数据库,数据库冗余了多少份,就要连多少个数据库;
例如:站点接入层某一个应用有2台机器,业务服务层某一个服务有4台机器,那肯定是上游的2台会与下游的4台进行一个全相连。
全连接如何保证系统的负载均衡与高可用?
全连接架构的负载均衡与高可用保证,是通过连接池实现的。不管是NG连web,web连业务服务,业务服务连接基础服务,服务连接数据库,都是这样。
划重点1:单机房架构的核心是“全连接”。
【2】核心问题二,机房迁移的目标是什么?
单机房架构的特点是“全连接”,机房迁移要做一个什么样的事情呢?
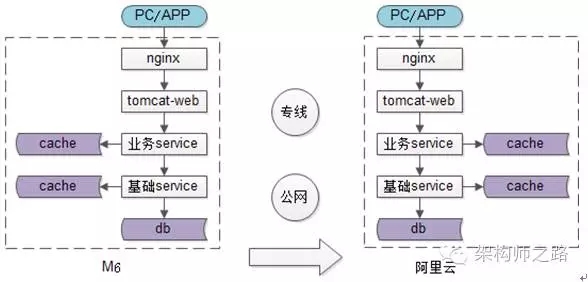
如上图:迁移之前,系统部署在机房A(M6)内,是单机房架构。迁移之后,系统部署在机房B(阿里云)内,仍然是单机房架构,只是换了一个机房而已。
有什么好的迁移方案?最容易想到的一个方案,把所有服务在新机房全都部署一套,然后把流量切过来。
这个方案存在什么问题?问题1:得停止服务,丧失了可用性。
问题2:即使可以接受停服,当有几百台机器,几千个系统的时候,“部署一套,切流量”一步成功的概率很低,风险极高,因为系统实在太复杂了。
机房迁移的难点,是“平滑”迁移,整个过程不停服务,并能够“蚂蚁搬家”式迁移。
划重点2:机房迁移方案的设计目标是:
- 平滑迁移,不停服务;
- 可以分批迁移;
- 随时可以回滚;
【3】核心问题三,暂时性的多机房架构能否避免?
如果想要平滑的迁移机房,不停服务,且逐步迁移,迁移的过程中,势必存在一个中间过渡阶段,两边机房都有流量,两边机房都对外提供服务,这就是一个多机房的架构。
迁移过程中,多机房架构不可避免。
前文提到的单机房架构,是一个“全连接”架构,能不能直接将单机房的全连架构套用到多机房呢?
如果直接将单机房“全连接”的架构复制到多机房,会发现,会有很多跨机房的连接:
- 站点层连接业务服务层,一半的请求跨机房;
- 业务服务层连接基础服务层,一半的请求跨机房;
- 基础服务层连数据层,一半的请求跨机房;
大量的跨机房连接会带来什么问题?同机房连接,内网的性能损耗几乎可以忽略不计。
一旦涉及到跨机房的访问,即使机房和机房之间有专线,访问的时延可能增加到几毫秒,甚至几十毫秒(跟机房间光纤距离有关)。
举个例子,假设户访问一个页面,需要用到很多数据,这些数据可能需要20次相互调用(站点调用服务,服务调用缓存和数据库等),如果有一半调用跨机房(10次调用),机房之间延迟是20毫秒,因为跨机房调用导致的请求迟延就达到了200毫秒,这个是绝不能接受的。
划重点3:想要平滑的实施机房迁移,临时性的多机房架构不可避免。
小结:
- 单机房架构的核心是“全连接”。
- 机房迁移方案的设计目标是:平滑迁移,不停服务;可以分批迁移;随时可以回滚;
- 想要平滑的实施机房迁移,临时性的多机房架构不可避免;
多机房架构应该如何设计?系统迁移步骤又该如何?
《当年,我们是怎么平滑上云的?》一文中提到了上云的背景,将所有的系统,从一个机房,迁移到另一个机房。
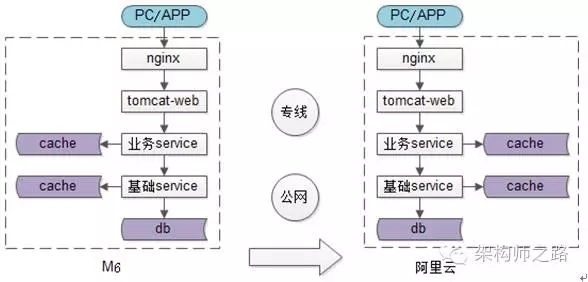
如上图:
- 迁移之前,系统部署在机房A(M6)内,是单机房架构。
- 迁移之后,系统部署在机房B(阿里云)内,换了一个机房。
《当年,我们是怎么平滑上云的?》有三结论:
- 单机房架构的核心是“全连接”;
- 机房迁移方案的设计目标是:平滑迁移,不停服务;可以分批迁移;随时可以回滚;
- 想要平滑的实施机房迁移,临时性的多机房架构不可避免;
【4】核心问题四,临时性多机房架构如何实施?
如前文所述,如果将单机房“全连接”架构复制到多机房,会有大量跨机房调用,极大增加请求时延,是业务无法接受的,要想降低这个时延,必须实施“同机房连接”。
多机房多活架构,什么是理想状态下的“同机房连接”?
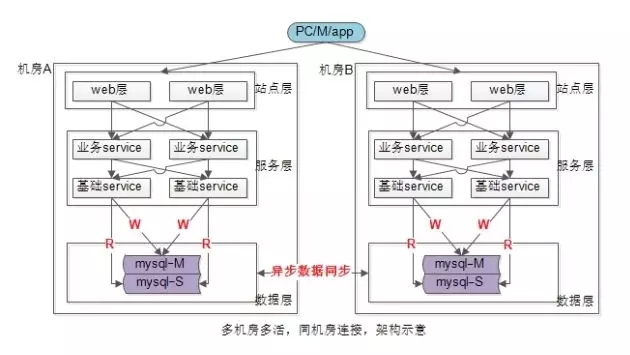
如上图所示,多机房多活架构,最理想状态下,除了异步数据同步跨机房通讯,其他所有通讯均为“同机房连接”:
- web连业务服务;
- 业务服务连基础服务;
- 服务连数据库,主库写,从库读,读写分离;
上述架构,每个机房是一套独立的系统,仅仅通过异步数据同步获取全量数据,当发生机房故障时,将流量切到另一个机房,就能冗余“机房级”故障,实现高可用。
上述多机房架构存在什么问题?
“异步数据同步”存在延时(例如:1min),这个延时的存在,会使得两个机房的数据不一致,从而导致严重的业务问题。
举个例子,某一个时刻,用户X有余额100元,两个机房都存储有该余额的精准数据,接下来:
- 余额100,X在北京(就近访问机房A)消费了80元,余额仅剩20元,该数据在1分钟后会同步到机房B;
- 余额100,X的夫人在广州(就近访问机房B)用X的账号消费了70元,余额剩余30元,该数据在1分钟后也会同步到机房A;
从而导致:
- 超额消费(100余额,却买了150的东西);
- 余额异常(余额是20,还是30?);
上述架构适合于什么业务场景?
任何脱离业务的架构设计都是耍流氓。
当每个机房都有很多全局业务数据的访问场景时,上述多机房架构并不适用,会存在大量数据不一致。但当每个机房都访问局部业务数据时,上述多机房架构仍然是可行的。
典型的业务:滴滴,快狗打车。
这些业务具备数据聚集效应:
- 下单用户在同一个城市;
- 接单司机在同一个城市;
- 交易订单在同一个城市;
这类业务非常适合上述多机房多活架构,多个机房之间即使存在1分钟延时的“异步数据同步”,对业务也不会造成太大的影响。
多机房多活架构,做不到理想状态下的“同机房连接”,有没有折中方案?
如果完全避免跨机房调用的理想状态做不到,就尽量做到“最小化”跨机房调用。
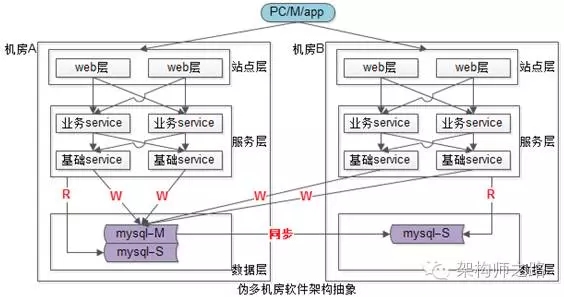
如上图所示,在非必须的情况下,优先连接同机房的站点与服务:
- 站点层只连接同机房的业务服务层;
- 业务服务层只连接同机房的基础服务层;
- 服务层只连接同机房的“读”库;
- 对于写库,没办法,只有跨机房读“写”库了;
该方案没有完全避免跨机房调用,但它做到了“最小化”跨机房调用,只有写请求是跨机房的。
但互联网的业务,绝大部分是读多写少的业务:
- 百度的搜索100%是读业务;
- 京东淘宝电商99%的浏览搜索是读业务,只有下单支付是写业务;
- 58同城99%帖子的列表详情查看是读业务,只有发布帖子是写业务;
写业务比例相对少,只有很少请求会跨机房调用。
该多机房多活架构,并没有做到100%的“同机房连接”,通常称作伪多机房多活架构。
伪多机房多活架构,有“主机房”和“从机房”的差别。
多机房多活架构的初衷是容机房故障,该架构当出现机房故障时,可以把入口处流量切到另一个机房:
- 如果挂掉的是,不包含主库的从机房,迁移流量后能直接容错;
- 如果挂掉的是,包含主库的主机房,只迁移流量,系统整体99%的读请求可以容错,但1%的写请求会受到影响,此时需要将从库变为主库,才能完全容错。这个过程需要DBA介入,不需要所有业务线上游修改。
画外音:除非,站点和服务使用内网IP,而不是内网域名连接数据库。架构师之路已经强调过很多次,不要使用内网IP,一定要使用内网域名。
伪多机房多活架构,是一个实践性,落地性很强的架构,它对原有架构体系的冲击非常小,和单机房架构相比,仅仅是:
- 跨机房主从同步数据,会多10毫秒延时;画外音:主从同步数据,本来就会有延时。
- 跨机房写,会多10毫秒延时;
小结:
- 理想多机房多活架构,是纯粹的“同机房连接”,仅有异步数据同步会跨机房;
- 理想多机房多活架构,会有较严重数据一致性问题,仅适用于具备数据聚集效应的业务场景,例如:滴滴,快狗打车;
- 伪多机房多活架构,思路是“最小化跨机房连接”,机房区分主次,落地性强,对原有架构冲击较小,强烈推荐;
临时性多机房多活架构,是机房迁移过程中的一个过渡状态,机房迁移步骤又该如何?
思路比结论重要。