先解释一下几个名词:
metadata :hive元数据,即hive定义的表名,字段名,类型,分区,用户这些数据。一般存储关系型书库mysql中,在测试阶段也可以用hive内置Derby数据库。
metastore :hivestore服务端。主要提供将DDL,DML等语句转换为MapReduce,提交到hdfs中。
hiveserver2:hive服务端。提供hive服务。客户端可以通过beeline,jdbc(即用java代码链接)等多种方式链接到hive。
beeline:hive客户端链接到hive的一个工具。可以理解成mysql的客户端。如:navite cat 等。
连接hive:
./bin/hive
通过 ./bin/hive 启动的hive服务,第一步会先启动metastore服务,然后在启动一个客户端连接到metastore。此时metastore服务端和客户端都在一台机器上,别的机器无法连接到metastore,所以也无法连接到hive。这种方式不常用,一直只用于调试环节。
./bin/hive --service metastore
通过hive --service metastore 会启动一个 hive metastore服务默认的端口号为:9083。metastore服务里面配置metadata相关的配置。此时可以有多个hive客户端在hive-site.xml配置hive.metastore.uris=thrift://ipxxx:9083 的方式链接到hive。motestore 虽然能使hive服务端和客户端分别部署到不同的节点,客户端不需要关注metadata的相关配置。但是metastore只能通过只能通过配置hive.metastore.uris的方式连接,无法通过jdbc的方式访问。
./bin/hiveserver2
hiveserver2 会启动一个hive服务端默认端口为:10000,可以通过beeline,jdbc,odbc的方式链接到hive。hiveserver2启动的时候会先检查有没有配置hive.metastore.uris,如果没有会先启动一个metastore服务,然后在启动hiveserver2。如果有配置hive.metastore.uris。会连接到远程的metastore服务。这种方式是最常用的。部署在图如下:

有问题暂时没搞明白metastore 只能部署在namenode节点吗?datanode可以吗?或者干脆不用和hadoop部署一起?后续要关注一下
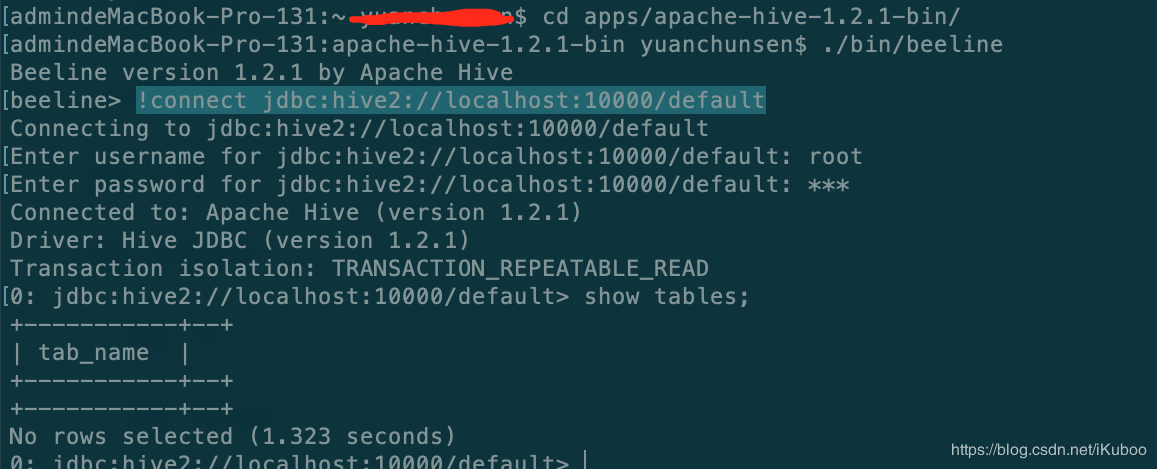
./bin/beeline
beeline 可以启动客户端链接到hiveserver2。执行beeline后在控制输入 !connect jdbc:hive2://localhost:10000/default root 123 就可以链接到 hiveserver2了;default表示链接到default database, root 和123 分别为密码。注意这里的密码不是mysql的密码,是hive中的用户。如图: