Java中不止提供了集合框架中的接口,还提供了许多具体的实现。
| 集合类型 | 描述 |
| ArrayList | 一种可以动态增长和缩减的索引序列 |
| LinkedList | 一种可以在任何位置进行高效地插入和删除操作的有序序列 |
|
ArrayDeque |
一种用循环数组实现的双端队列 |
| HashSet | 一种没有重复元素的无序集合 |
| EnumSet | 一种包含枚举类型值的集 |
| LinkedHashSet | 一种可以记住元素插入次序的集 |
| PriorityQueue | 一种允许高效删除最小元素的集合 |
| HashMap | 一种存储键/值对的数据结构 |
| TreeMap | 一种键值有序排列的映射表 |
| EnumMap | 一种键值属于枚举类型的映射表 |
| LinkedHashMap | 一种可以记住键/值项添加次序的映射表 |
| WeakHashMap | 一种其值无用武之地后可以被垃圾回收器回收的映射表 |
| IdentityHashMap | 一种用 == 而不是用 equals 比较键值的映射表 |
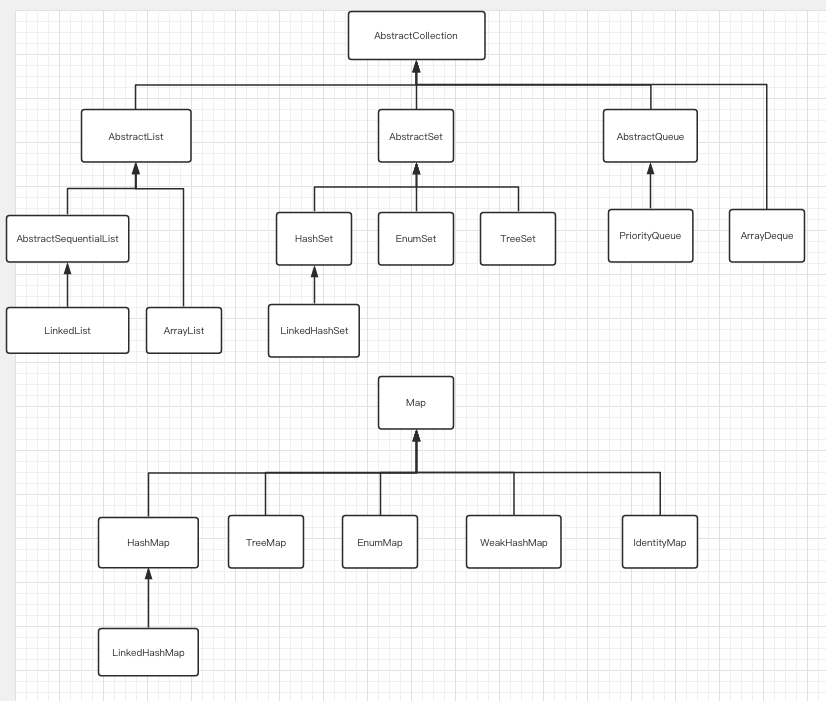
上表中的集合,除Map结尾的集合均实现了Collection接口,以Map结尾的集合实现了Map接口,继承结构图如下:
1 链表
在Java中,所有的链表实际上都是双向链表——每个结点还存放着指向前驱结点的引用。
Iterator 与 ListIterator
链表是一个有序集合,LinkedList.add方法添加元素时添加至表尾,但是有时候需要将元素插入到表中间,迭代器是负责描述集合位置的,所以这种添加方法应该由iterator负责,但是由于iterator也支持无序集合如Set的使用,所以无序集合使用iterator时应没有add方法,鉴于这种原因,集合类库提供了Iterator的子接口ListIterator。
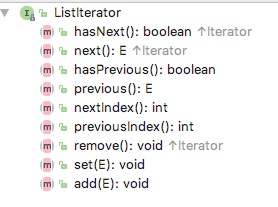
和Collection中的add不同,ListIterator的add返回值为void,它假定操作总会成功。除此以外,它还提供了hasPervious和Pervious方法用来反向遍历。
add方法在迭代器位置之前添加一个对象,如以下代码将越过第一个元素,并在第二个元素前插入"2018/03/02":
1 List list = new LinkedList(); 2 Iterator iterator = list.iterator(); 3 4 LinkedList<String> dates = new LinkedList<>(); 5 dates.add("2017/03/01"); 6 dates.add("2017/03/03"); 7 dates.add("2017/03/04"); 8 9 System.out.println("插入前" + dates); 10 11 ListIterator<String> datesIterator = dates.listIterator(); 12 datesIterator.next(); 13 datesIterator.add("2017/03/02"); 14 15 System.out.println("插入后:" + dates);
输出结果:

add方法与remove方法
当对一个刚由listIterator返回的iterator对象调用add方法,新添加的元素将成为表头;
当迭代器对象越过最后一个对象(hasNext返回false),新添加的元素将成为表尾;
和remove不同,add方法可以多次调用,并按照调用的次序依次把元素添加到表中迭代器的位置之前。
add方法只依赖于迭代器的位置,而remover方法依赖于迭代器的状态。
set方法:用一个新元素取代调用next或pervious方法返回的上一个元素。
iterator的并发修改问题
在一个迭代器修改集合时,另一个迭代器对集合进行遍历,将会出现混乱。ListItearator的设计可以检测到这种状态,并会抛出一个ConcurrentModificationException异常。如以下代码:
List<String> list = ...; ListIterator<String> itr1 = list.listIterator(); ListIterator<String> itr2 = list.listIterator(); itr1.next(); itr1.remove(); itr2.next(); // throw ConcurrentModificationException
为了避免并发修改的异常,应该遵循一个原则:根据需要给容器附加许多的迭代器,但是这些迭代器只读,另外再声明一个可读写的迭代器。
链表只负责跟踪对列表的结构性修改,如add、remove,但set不在此列,可以将多个迭代器附加给一个链表,并都调用set方法 进行修改。
注意:
当选择链表作为数据结构时,尽量使用迭代器进行访问元素,而不要使用get方法,当经常需要用get方法时,可能使用ArrayList是一个更好的选择。
for(int i = 0;i < list.size;i++){ list.get(i); }
一定不要对链表使用以上循环,这段代码每次从list.get(i)获取数据时,都将从链表头开始遍历一遍。(其实get方法索引大于size()/2时,将从链尾搜索元素,但还是应该避免使用get方法)
ListIterator还有两个方法 : nextIndex() 和 perviousIndex() ,nextIndex() 返回下一次调用next()的索引, perviousIndex() 返回下一次调用pervious()的索引,但两者的返回值只差1,意味着迭代器位于两个相邻的元素中间。
如果有一个索引n,list.listItereator(n)将返回一个指向索引n前面的迭代器,即:iterator.next()将返回list.get(n)。
2 ArrayList
List接口实现的另一种形式,可以使用get()和set()进行随机访问,ArrayList封装了一个动态再分配的对象数组。
ArrayList内部用Object[]进行存储数据,当存储区满时,用以下代码进行内存再分配:
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
ArrayList 和 Vector
Vector 的所有方法都是同步的,意味着Vector是线程安全的,可以有两个线程安全的访问同一个Vector。
但是,如果只有一个线程访问Vector,会在同步操作上耗费大量的时间。所以,在不需要同步时使用ArrayList ,而不要使用Vector。
3 散列表
有一种可以快速查找所需要的对象的数据结构,就是hashtable,即散列表。散列表为每个对象计算一个整数的散列码,具体来说,具有不同数据域的对象将产生不同的散列码,这就是为什么重写equals方法时要重写hashCode方法,使拥有相同数据域的对象应拥有相同的hashcode,以便对象可以插入散列表。散列码应能够快速的计算出来,且这个计算只与散列的对象的状态有关,与散列表的其他对象无关。
在Java中,散列表通过链表数组实现(Java8中,桶满时会从链表变成平衡二叉树,这样在散列表中存在多个相同散列码值的对象时可以提高性能),每个链表被称为桶,要查找表中对象的位置,先计算其散列码,然后与桶的总数取余,所得到的结果就是保存这个元素的索引。如:某个对象的散列码为76268,桶数为128,对象应该保存在108号桶中。
当在散列表中插入新对象时,通过散列码对桶数取余得到桶的索引,然后根据这个索引找到对应的桶,如果桶中没有元素,便直接插入桶中;如果桶中已有数据,便将待插入对象的散列码与桶中所有对象进行比较。
如果想更多地控制散列表的运行性能,应为散列表设置一个初始的桶数,桶数指用于收集具有相同散列值的桶的数目,以降低插入桶中的元素太多,产生散列冲突的可能性。
一般来说,通常将桶的数目设置为预计元素数目的0.75~1.50,Java类库中使用的桶数是2的幂,默认值为16。
如果初始的估计过低,就需要再散列,即创建一个桶数更多的表,并把原表的数据插入到新表中,然后丢弃原表。装填因子决定何时进行再散列,Java类库中默认值为0.75,即当原表超过75%的位置已经填入元素,这个表就会用双倍的桶数进行自动再散列,对于大多数程序而言,装填因子为0.75是比较合理的。
散列表的迭代器将依次访问所有的桶,由于散列将元素的顺序分散在表的各个位置,所以访问的顺序几乎是随机的。
散列表可以用于实现几个重要的数据结构,其中最简单的是set,set是一种没有重复元素的集合,set的add方法首先在集中查找要添加的对象,如果不存在,就将此对象添加进去。Java集合类库提供了一个实现了基于散列表的集,HashSet类,可以用add方法添加元素,用contains快速查看某个元素是否在集中。
4 树集
TreeSet与HashSet十分类似,不过它比HashSet有所改进,TreeSet是一个有序集合,可以以任意顺序将元素插入到集合中,对集合进行遍历时每个值将自动地按照排序后的顺序呈现,如:
SortedSet<String> set = new TreeSet<String>(); set.add("Liverpool"); set.add("Beijing"); set.add("Zhanjiang"); set.forEach(System.out::println);
输出结果:

TreeSet 使用树结构实现的,每次将一个元素添加到树中,都被放置在正确的排序位置上,所以迭代器总是以排好序的顺序访问每个元素。
要使用TreeSet ,其元素必须实现Comparable接口,或者构造TreeSet时提供一个Comparator。
将一个元素添加到TreeSet中要比添加到HashSet中慢,如果不需要对数据进行排序,就没必要付出排序的开销。
5 队列与双端队列
- 队列:可以从队尾添加元素,从队头删除元素。
- 双端队列:可以在队头和队尾添加和删除元素,但不支持在队列中间添加元素。
Java集合类库中引入了Deque接口,并由ArrayDeque和LinkedList实现,这两个类都提供了双端队列,而且在必要时可以增加队列的长度。
入队方法
- add(双端队列中为 addFirst 和 addLast )
- offer (双端队列中为 offerFirst 和 offerLast )
如果队列未满,将给定元素入队,并返回true,如果队列已满,add方法将抛出一个IllegalStateException异常,offer方法返回false。
出队方法
- remove (双端队列中为 removeFirst 和 removeLast )
- poll (双端队列中为 pollFirst 和 pollLast )
如果队列非空,将队头(双端队列中可指定队尾)元素出队,如果队列为空,remove方法将抛出一个NoSuchElementException异常,poll方法返回false。
查看元素方法
- element(双端队列中为 getFirst 和 getLast 方法)
- peek (双端队列中为 peekFirst 和 peekLast )
如果队列非空返回队头(双端队列中可指定队尾)元素,但不删除;如果队列为空,element方法将抛出一个NoSuchElementException异常,peek方法返回null。
优先级队列(PriorityQueue)
优先级队列中的元素可以按照任意的顺序插入,却总是按照排序的顺序进行检索。也就是说,无论何时调用 poll 或 remove 方法,总会将当前队列中的最小元素出列。
优先级队列并没有对所有的元素进行排序,而是使用了堆的数据结构,堆是一个可以自我调整的二叉树,对树进行添加和删除操作,可以让最小的元素移动到根,而不必花费时间对元素进行排序。
与TreeSet不同,PriorityQueue的迭代并不是按照排序访问的,但出队时却永远将最小元素出队。
类似于TreeSet ,PriorityQueue中的元素必须实现Comparable接口或者在构造器中提供Comparator对象。
优先级队列一般应用于任务调度中,每个任务有一个优先级(由于习惯上把 1 设为最高优先级),当任务以随机顺序添加进任务队列中,当执行任务时,优先执行优先级高的任务。