Machine Learing System Design(机器学习系统设计)
Ways to improve the accuracy of a classifier(提高分类器准确性的几个方法)
-
Collect lots of data (for example "honeypot" project but doesn't always work)(收集大量数据,并不总是有用)
-
Develop sophisticated features (for example: using email header data in spam emails)(使用复杂特征)
-
Develop algorithms to process your input in different ways (recognizing misspellings in spam).(使用不同的处理方式)
It is difficult to tell which of the options will be most helpful.(很难说哪种最有用,不过理性思考比靠直觉尝试更可行)
Error Analysis(误差分析)
Manually examine the errors on examples in the cross validation set and try to spot a trend where most of the errors were made.(人工检查验证集的结果,寻找系统性偏差)
Recommended approach to solving machine learning problems(算法实施推荐方法)

- Start with a simple algorithm, implement it quickly, and test it early on your cross validation data.(由简单算法开始构建,在验证集上测试结果)
- Plot learning curves to decide if more data, more features, etc. are likely to help.(绘画学习曲线,确定改进思路)
- Manually examine the errors on examples in the cross validation set and try to spot a trend where most of the errors were made.(进行误差分析,进一步改善)
numerical value(结果的数值评估)

Error Metrics for Skewed Classes(偏斜类的误差度量)
偏斜类指一些分布概率差距较大的分类,例如某件事的发生概率为0.5%,该类别为一个偏斜类,这种情况下,即使不对分类做出任何算法处理,也会得到较高的准确定,即不知道提高准确性是否表明算法的分类效果有所提升,需要新的概念进行进行误差度量。
Precision and Recall(查准率和召回率)
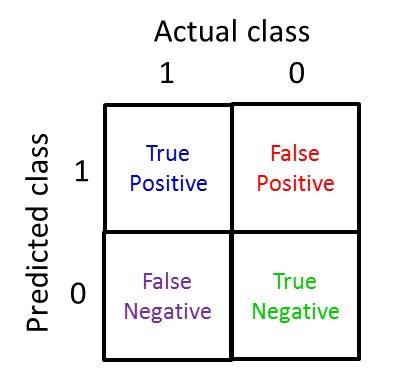

Trading Off Precision and Recall(平衡选择查准率与召回率)
根据不同情况确定合适阈值,选择高查准率,低召回率与高召回率,低查准率的情况。
F1 score(F score)

Data For Machine Learning(ML数据选择)
有较多参数的低偏差算法,训练误差较小,为了提高算法准确性,降低方差,需要增加更多训练实例,使得验证误差降低到和训练误差同一水平,得到低方差的正常算法。
