小程序反编译(比较匆忙,之后加图)
需要的工具
因为阿里云盘不能分享压缩包,用的奶牛
node.js
下载地址:[ 小程序反编译工具 ] 传输链接:https://cowtransfer.com/s/04ec0d0a737745 或 打开【奶牛快传】cowtransfer.com 使用传输口令:7chgsl 提取;
小程序解密包 工具
下载地址:[ 小程序反编译工具 ] 传输链接:https://cowtransfer.com/s/04ec0d0a737745 或 打开【奶牛快传】cowtransfer.com 使用传输口令:7chgsl 提取;
wxappUnpacker
下载地址:https://github.com/Siffre/wxappUnpacker
下载地址:[ 小程序反编译工具 ] 传输链接:https://cowtransfer.com/s/04ec0d0a737745 或 打开【奶牛快传】cowtransfer.com 使用传输口令:7chgsl 提取;
先安装node.js
下载wxappunpacker 进入这个目录后 运行cmd 执行命令
npm install
npm install esprima
npm install css-tree
npm install cssbeautify
npm install vm2
npm install uglify-es
npm install js-beautify
介绍
通过微信PC版,打开需要反编译的小程序,小程序将产生缓存文件(但他是加密的),通过"小程序解密包"工具将加密的缓存文件解密成为".wxapkg"文件
然后通过wxappunpacker工具反编译
具体操作
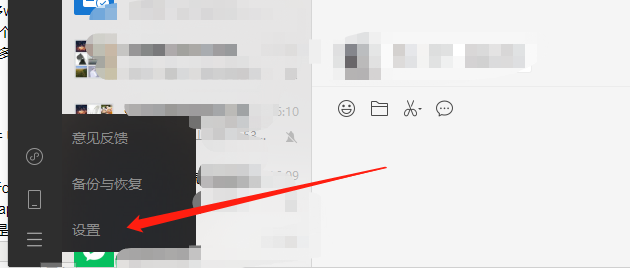
1.找到小程序加密文件
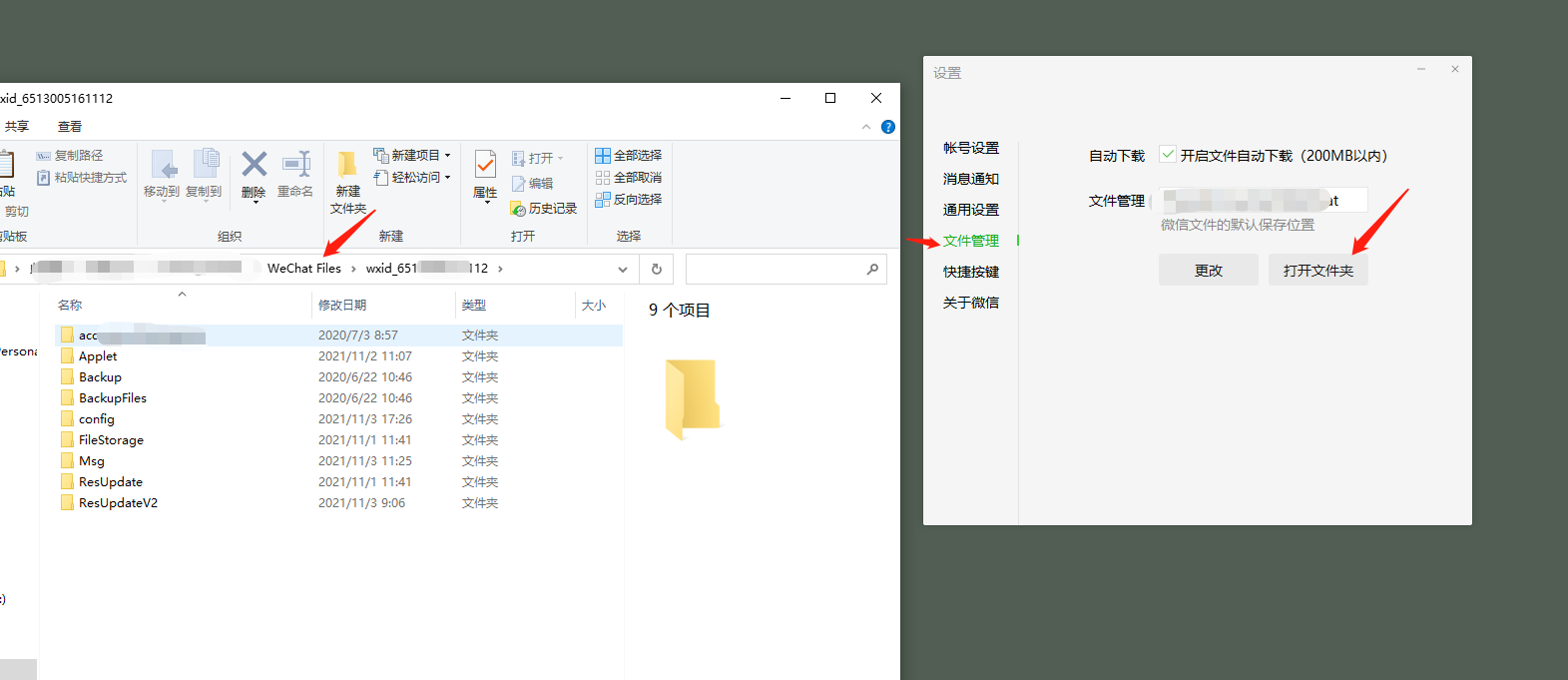
微信PC版查看 设置->文件管理->打开文件夹 然后往上一层返回一步 例如:W:weixin_liaotianWeChat Fileswxid_65130XX12 返回一步 就是 W:weixin_liaotianWeChat Files
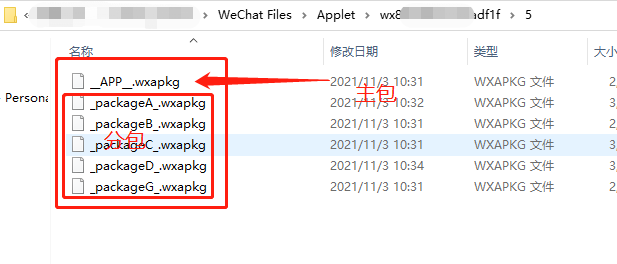
打开里面的 Applet 文件夹,有很多wx开头的文件夹(这些就是各种小程序的缓存文件),先全部删除
然后打开想要反编译的小程序,这个时候 Applet 里面就会新增一个wx开头的文件夹,打开进入 会有一个数字文件夹,再打开 就看到至少有一个".wxapkg"后缀文件 如:_APP_.wxapkg
这个就是小程序的主文件,如果是多个文件,那么其他的就是分包小程序文件

2.解密文件
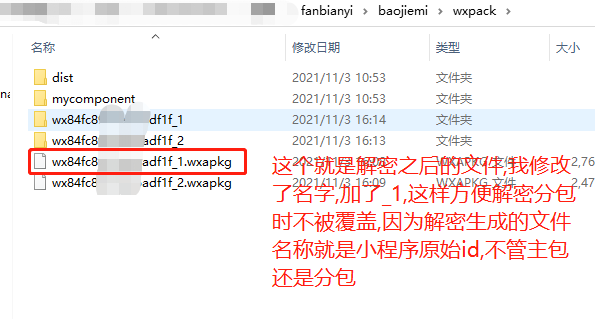
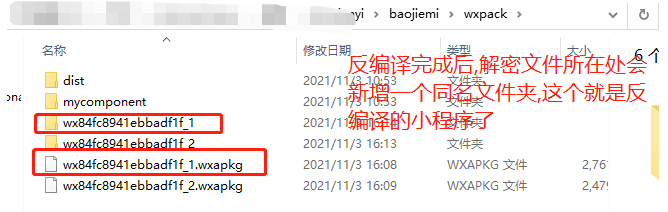
打开小程序解密包里面的exe文件 UnpackMiniApp.exe 点击"选择小程序加密包" 按钮;选择_APP_.wxapkg;然后就会生成解密的程序文件,放在'wxpack'文件夹,同样是'.wxapkg'结尾

3.反编译文件
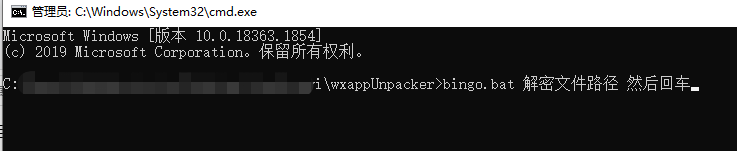
进入 wxappunpacker文件夹,运行cmd命令
bingo.bat testpkg/master-xxx.wxapkg
"testpkg/master-xxx.wxapkg" 就是步骤2生成的文件的路径,然后回车运行,就会在步骤2的文件路径里生成一个和文件名一样的文件夹,这个就是主小程序了
分包
重新开始说分包的方式;
重复步骤1
重复步骤2,然后生成的文件改一下文件名,比如生成的文件是nihao.wxapkg 改为nihao_1.apkg 这个是主包
重复步骤2,但是选择的是其他的分包,有生成了一个nihao.wxapkg 改为nihao_2.apkg 以此类推解密所有的 分包
重复步骤3,但这个步骤仅限珠宝
然后是分包命令如下
node wuWxapkg.js XXX
ihao_2.wxapkg -s=XXX
ihao_1
"XXX
ihao_2.wxapkg" 是解密的分包路径+文件名
"XXX
ihao_1" 是反编译主包时生成的文件夹路径
然后执行命令,其他分包也用此命令,只需要修改nihao_2.wxapkg解密文件的名字即可