1. 线性回归
简述
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合(自变量都是一次方)。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。
优点:结果易于理解,计算上不复杂。
缺点:对非线性数据拟合不好。
适用数据类型:数值型和标称型数据。
算法类型:回归算法
线性回归的模型函数如下: 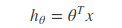
它的损失函数如下:
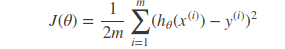
通过训练数据集寻找参数的最优解,即求解可以得到minJ(θ)的参数向量θ,其中这里的参数向量也可以分为参数和w和b,分别表示权重和偏置值。
求解最优解的方法有最小二乘法和梯度下降法。
梯度下降法
梯度下降算法的思想如下(这里以一元线性回归为例):
首先,我们有一个代价函数,假设是J(θ0,θ1)J(θ0,θ1),我们的目标是minθ0,θ1J(θ0,θ1)minθ0,θ1J(θ0,θ1)。
接下来的做法是:
- 首先是随机选择一个参数的组合(θ0,θ1)(θ0,θ1),一般是设θ0=0,θ1=0θ0=0,θ1=0;
- 然后是不断改变(θ0,θ1)(θ0,θ1),并计算代价函数,直到一个局部最小值。之所以是局部最小值,是因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值,选择不同的初始参数组合,可能会找到不同的局部最小值。
下面给出梯度下降算法的公式:
repeat until convergence {
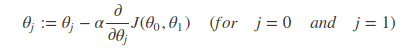
}
也就是在梯度下降中,不断重复上述公式直到收敛,也就是找到局部最小值局部最小值局部最小值局部最小值。其中符号:=是赋值符号的意思。
而应用梯度下降法到线性回归,则公式如下:

公式中的α称为学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈进的步子有多大。
在梯度下降中,还涉及到一个参数更新的问题,即更新(θ0,θ1),一般我们的做法是同步更新。
最后,上述梯度下降算法公式实际上是一个叫批量梯度下降(batch gradient descent),即它在每次梯度下降中都是使用整个训练集的数据,所以公式中是带有 。
。
岭回归(ridge regression):
岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价,获得回归系数更为符合实际、更可靠的回归方法,对病态数据的耐受性远远强于最小二乘法。
岭回归分析法是从根本上消除复共线性影响的统计方法。岭回归模型通过在相关矩阵中引入一个很小的岭参数K(1>K>0),并将它加到主对角线元素上,从而降低参数的最小二乘估计中复共线特征向量的影响,减小复共线变量系数最小二乘估计的方法,以保证参数估计更接近真实情况。岭回归分析将所有的变量引入模型中,比逐步回归分析提供更多的信息。
2. 逻辑回归
简述
Logistic回归算法基于Sigmoid函数,或者说Sigmoid就是逻辑回归函数。Sigmoid函数定义如下:
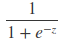
函数值域范围(0,1)。
因此逻辑回归函数的表达式如下:
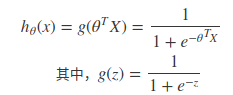
其导数形式为:
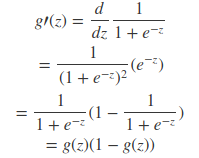
代价函数
逻辑回归方法主要是用最大似然估计来学习的,所以单个样本的后验概率为:
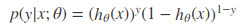
到整个样本的后验概率就是:
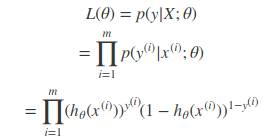
其中, 
通过对数进一步简化有: 
而逻辑回归的代价函数就是−l(θ)−l(θ)。也就是如下所示:
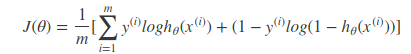
同样可以使用梯度下降算法来求解使得代价函数最小的参数。其梯度下降法公式为:

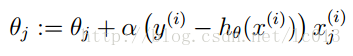
总结
优点:
1、实现简单;
2、分类时计算量非常小,速度很快,存储资源低;
缺点:
1、容易欠拟合,一般准确度不太高
2、只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
适用数据类型:数值型和标称型数据。
类别:分类算法。
适用场景:解决二分类问题。