分类
混淆矩阵1
- True Positive(真正, TP):将正类预测为正类数.
- True Negative(真负 , TN):将负类预测为负类数.
- False Positive(假正, FP):将负类预测为正类数 →→ 误报 (Type I error).
- False Negative(假负 , FN):将正类预测为负类数 →→ 漏报 (Type II error).
.png)
精确率(precision)定义为:
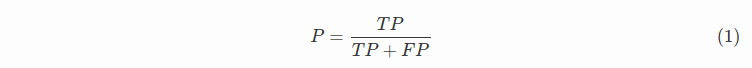
需要注意的是精确率(precision)和准确率(accuracy)是不一样的,
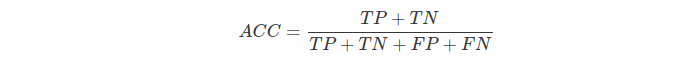
在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc 也有 99% 以上,没有意义。
召回率(recall,sensitivity,true positive rate)定义为:

此外,还有 F1F1 值,是精确率和召回率的调和均值,
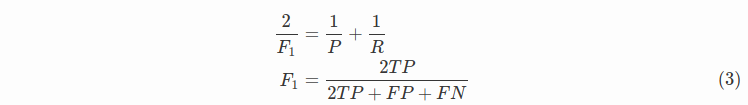
精确率和准确率都高的情况下,F1F1 值也会高。
通俗版本
刚开始接触这两个概念的时候总搞混,时间一长就记不清了。
实际上非常简单,精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是对的。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP)。
而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。

在信息检索领域,精确率和召回率又被称为查准率和查全率,

ROC 曲线
我们先来看下维基百科的定义,
In signal detection theory, a receiver operating characteristic (ROC), or simply ROC curve, is a graphical plot which illustrates the performance of a binary classifier system as its discrimination threshold is varied.
比如在逻辑回归里面,我们会设一个阈值,大于这个值的为正类,小于这个值为负类。如果我们减小这个阀值,那么更多的样本会被识别为正类。这会提高正类的识别率,但同时也会使得更多的负类被错误识别为正类。为了形象化这一变化,在此引入 ROC ,ROC 曲线可以用于评价一个分类器好坏。
ROC 关注两个指标,
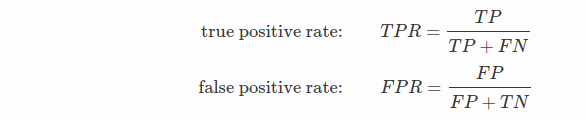
直观上,TPR 代表能将正例分对的概率,FPR 代表将负例错分为正例的概率。在 ROC 空间中,每个点的横坐标是 FPR,纵坐标是 TPR,这也就描绘了分类器在 TP(真正率)和 FP(假正率)间的 trade-off2。

AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。
The AUC value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example.
翻译过来就是,随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率就是 AUC 值。
简单说:AUC值越大的分类器,正确率越高3。
- AUC=1AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5<AUC<10.5<AUC<1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC=0.5AUC=0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC<0.5AUC<0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测,因此不存在 AUC<0.5AUC<0.5 的情况。

既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反)
回归4
平均绝对误差
平均绝对误差MAE(Mean Absolute Error)又被称为 l1l1 范数损失(l1-norm loss):

平均平方误差
平均平方误差 MSE(Mean Squared Error)又被称为 l2l2 范数损失(l2-norm loss):
