google api获取及使用
1 生成KEY
访问该地址:https://developers.google.com/custom-search/v1/overview?hl=en_US点击“Get a KEY”,此处需要登录谷歌账号,以及注册谷歌云账号并创建一个project。
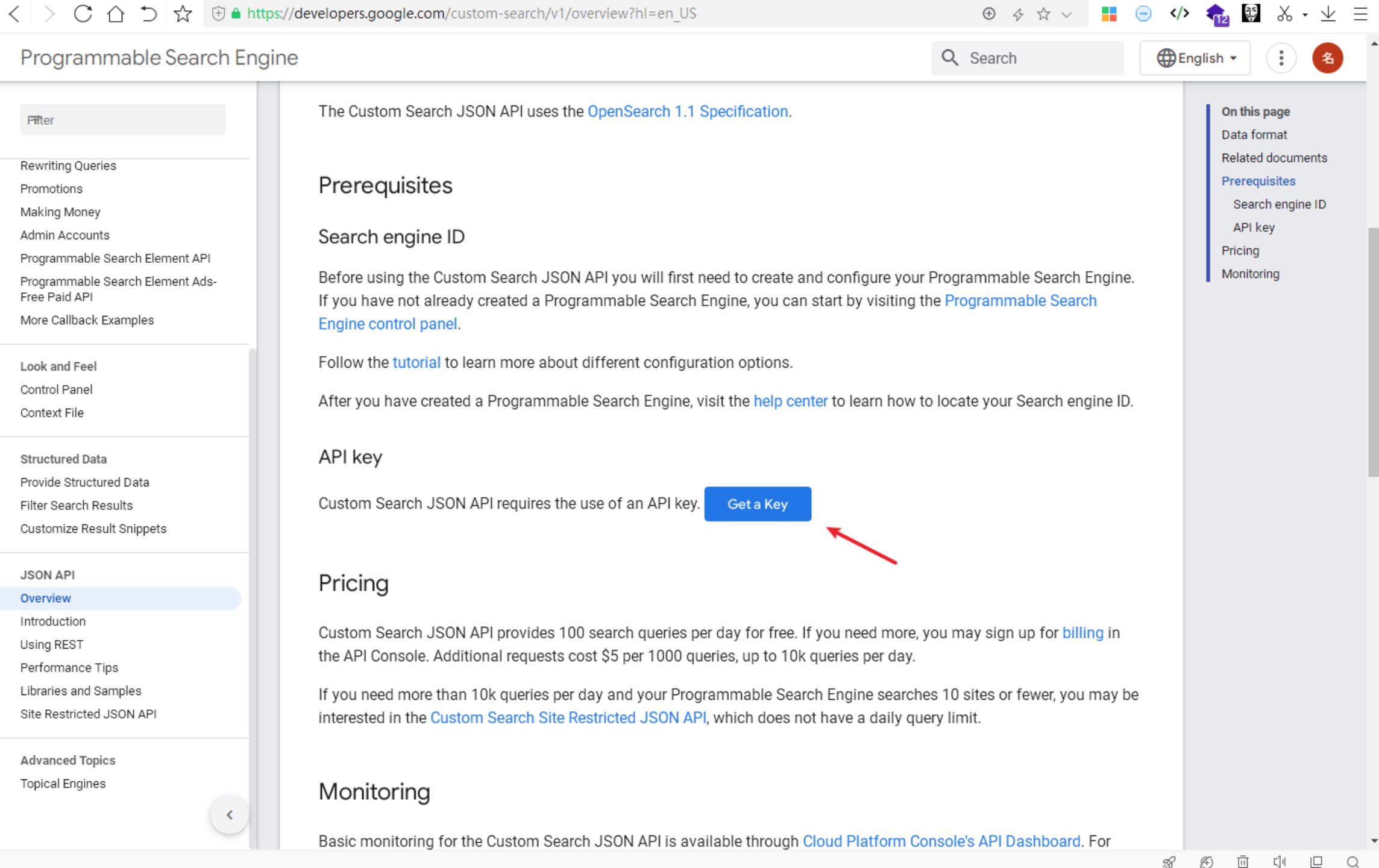
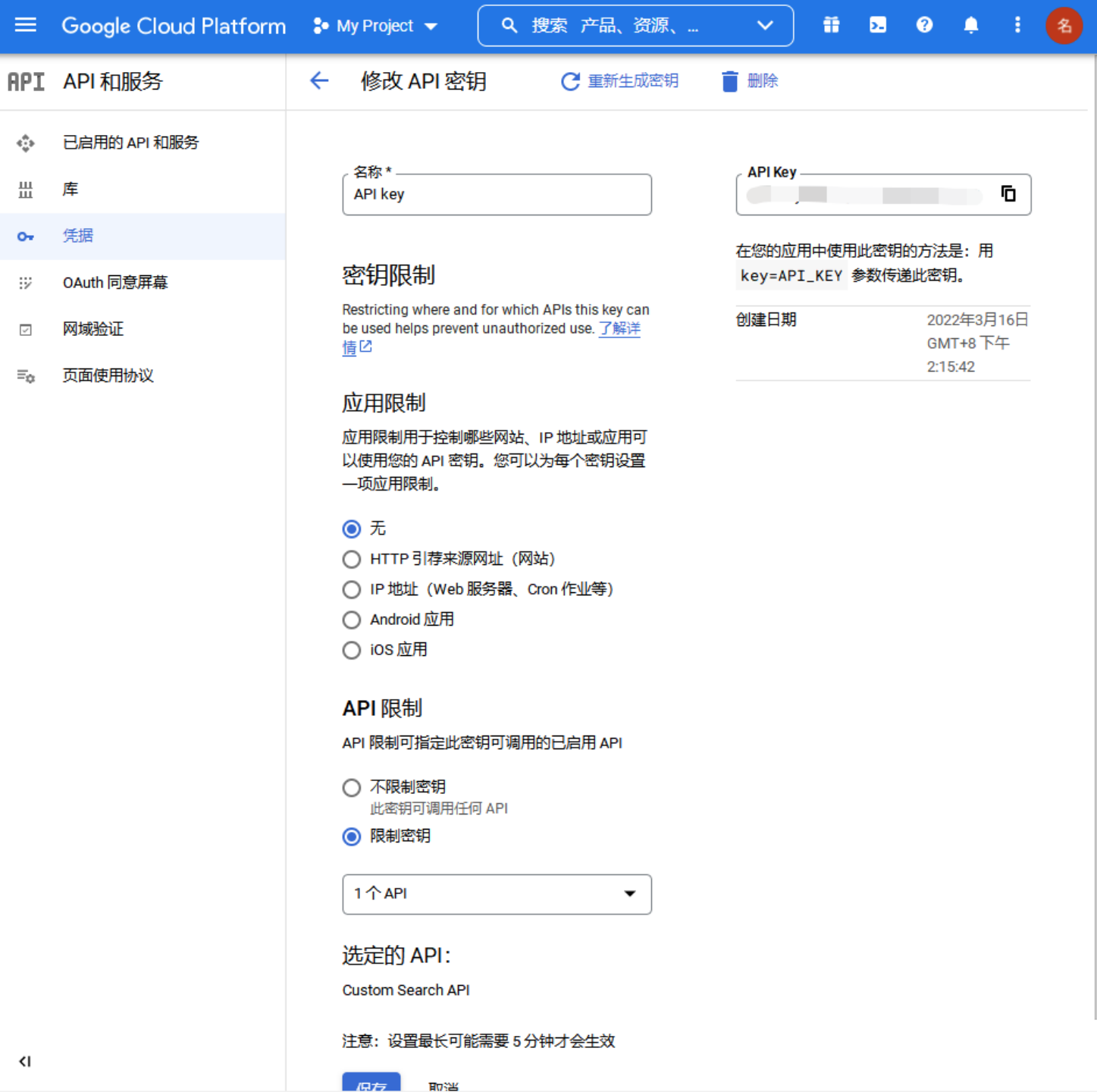
2 这个key可以从谷歌云控制台中看到,建议加上应用限制和API限制,防止泄露后被滥用。
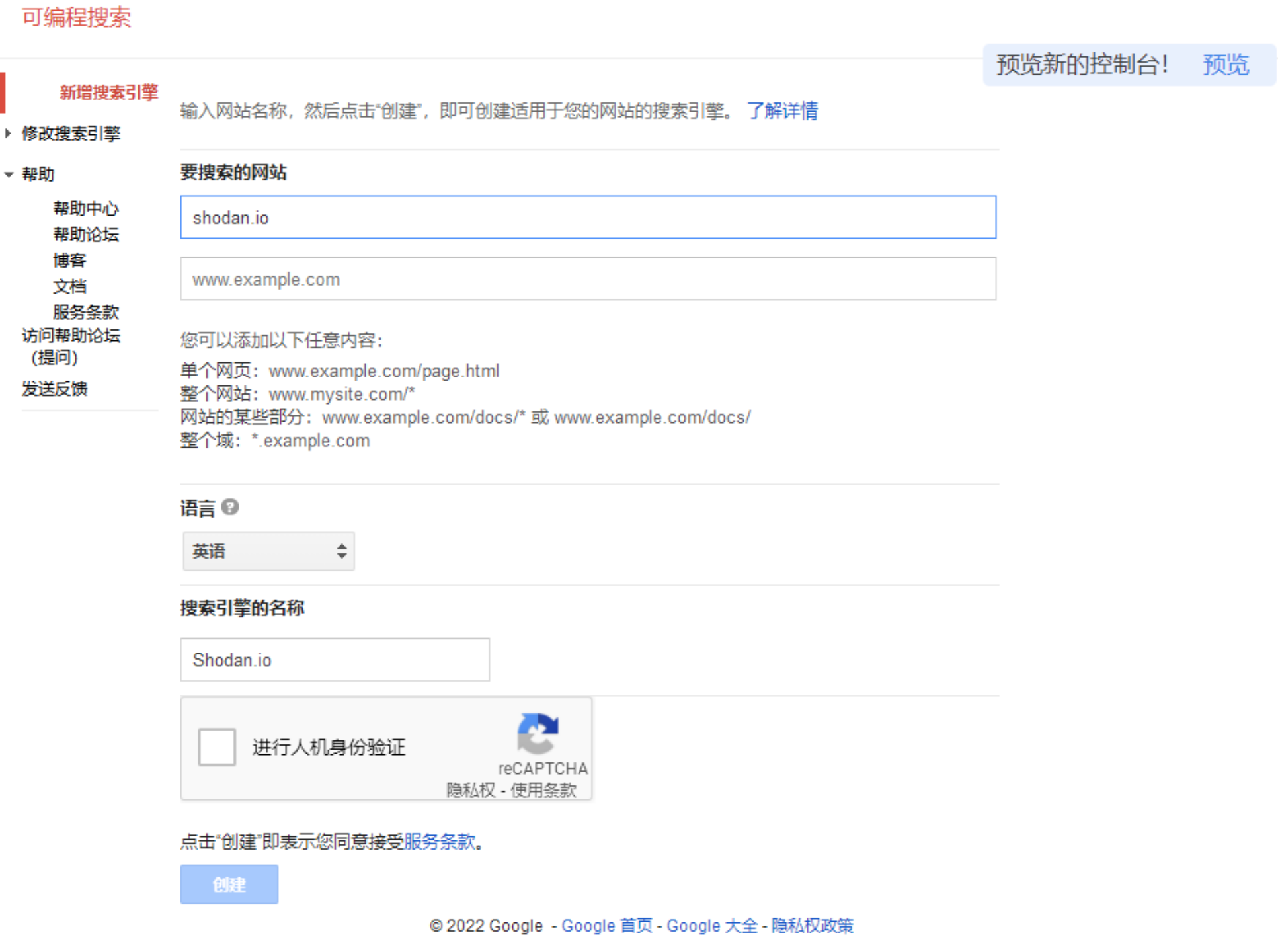
3 生成CX
https://programmablesearchengine.google.com/cse/create/new
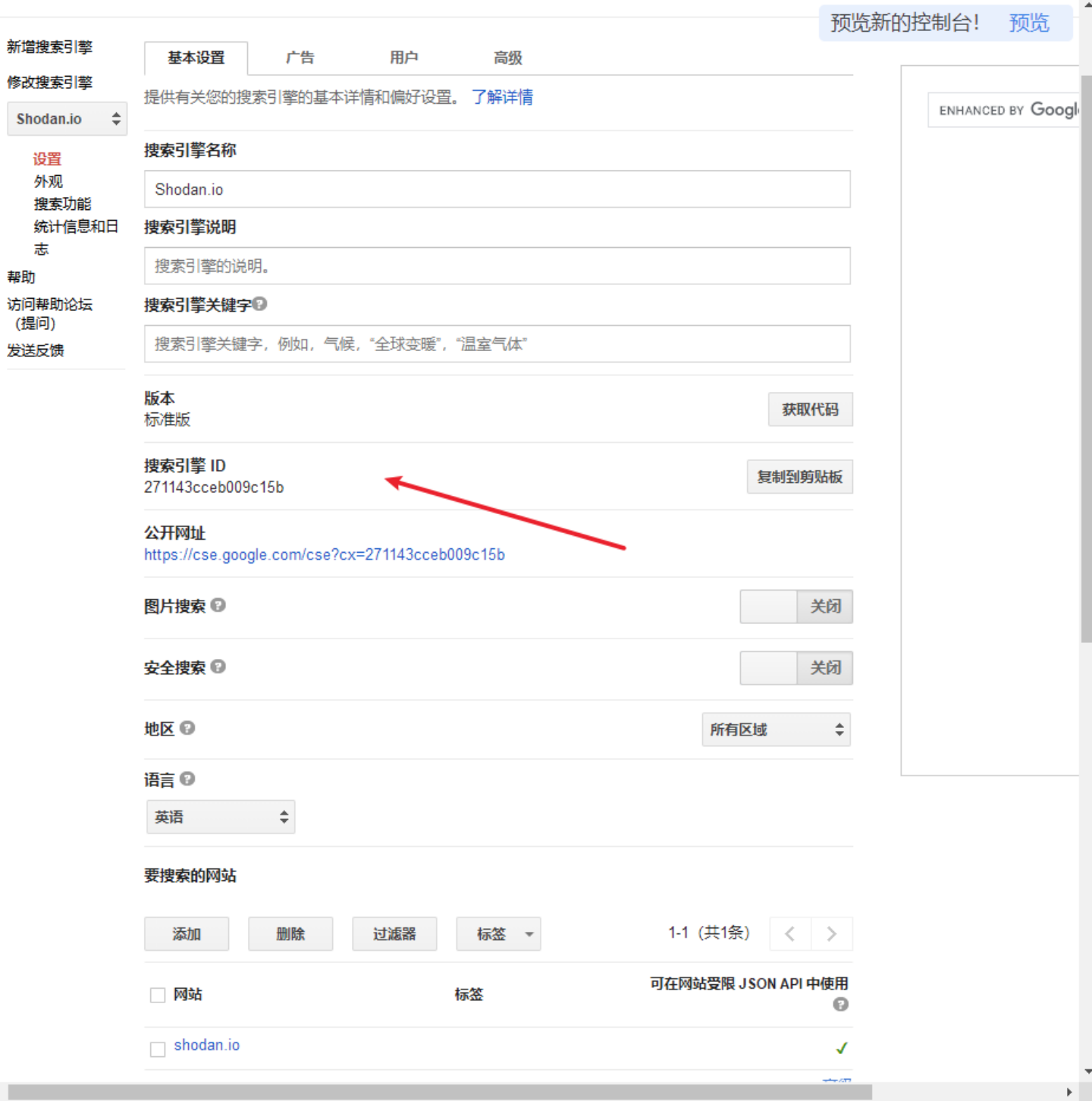
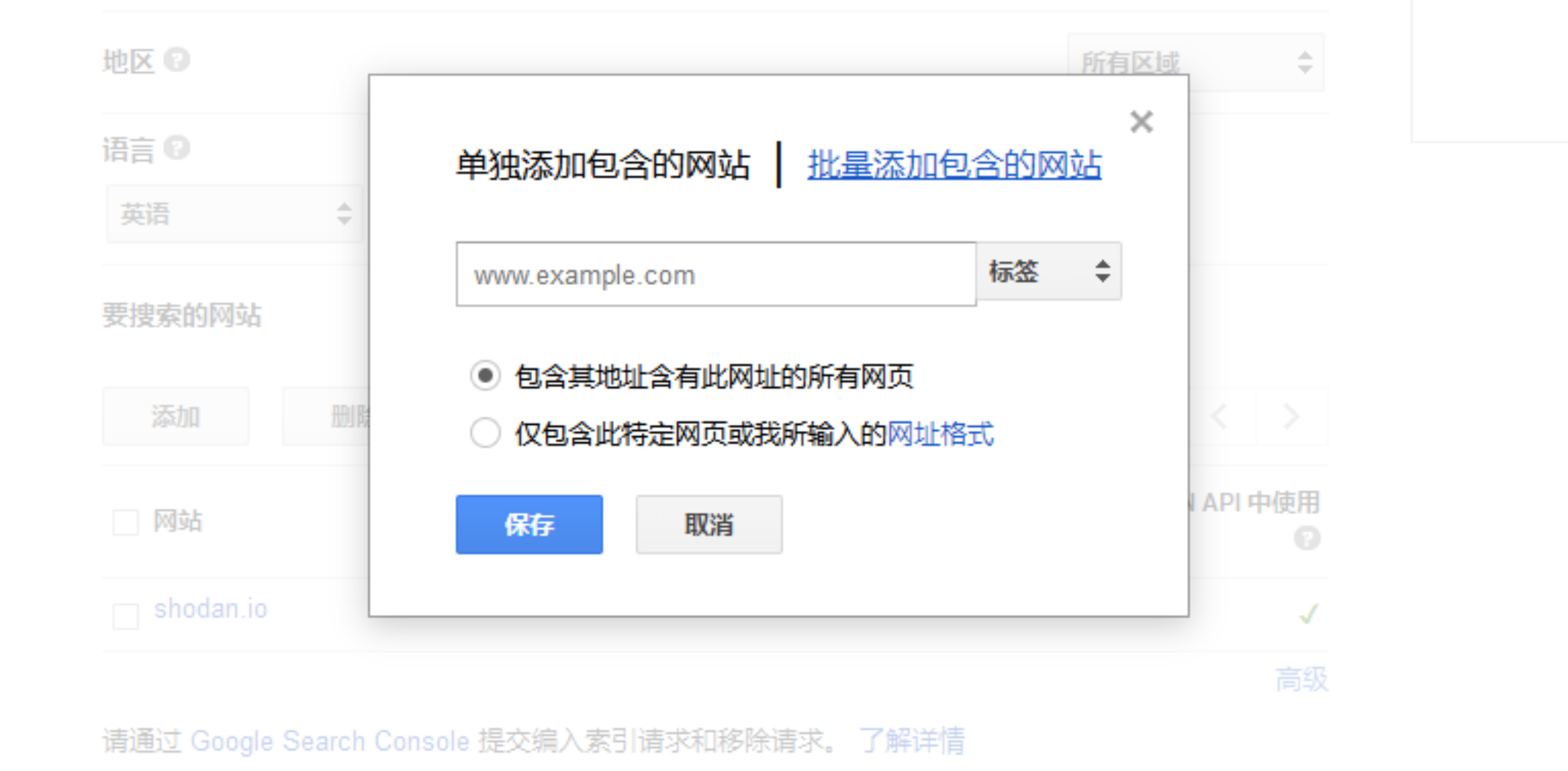
cx 是 Google 可编程搜索引擎(Programmable Search Engine)的 id 标识,在此处 新增搜索引擎 可以获取。这里可以指定要搜索的网站,比如说我只希望通过该 API 搜索出来的网站是 shodan.io,谷歌语法里面相当于 site:shodan.io,可以这么设置
爬虫脚本
import requests
import time
import random
import re
import os
def check_response(method, resp):
"""
检查响应 输出非正常响应返回json的信息
:param method: 请求方法
:param resp: 响应体
:return: 是否正常响应
"""
if resp.status_code == 200 and resp.content:
return True
content_type = resp.headers.get('Content-Type')
if content_type and 'json' in content_type and resp.content:
try:
msg = resp.json()
except Exception as e:
pass
else:
pass
return False
def match_subdomains(domain, html, distinct=True, fuzzy=True):
"""
Use regexp to match subdomains
:param str domain: main domain
:param str html: response html text
:param bool distinct: deduplicate results or not (default True)
:param bool fuzzy: fuzzy match subdomain or not (default True)
:return set/list: result set or list
"""
if fuzzy:
regexp = r'(?:[a-z0-9](?:[a-z0-9\-]{0,61}[a-z0-9])?\.){0,}' \
+ domain.replace('.', r'\.')
result = re.findall(regexp, html, re.I)
if not result:
return set()
deal = map(lambda s: s.lower(), result)
if distinct:
return set(deal)
else:
return list(deal)
else:
regexp = r'(?:\>|\"|\'|\=|\,)(?:http\:\/\/|https\:\/\/)?' \
r'(?:[a-z0-9](?:[a-z0-9\-]{0,61}[a-z0-9])?\.){0,}' \
+ domain.replace('.', r'\.')
result = re.findall(regexp, html, re.I)
if not result:
return set()
regexp = r'(?:http://|https://)'
deal = map(lambda s: re.sub(regexp, '', s[1:].lower()), result)
if distinct:
return set(deal)
else:
return list(deal)
class Module(object):
def __init__(self):
self.module = 'Module'
self.source = 'BaseModule'
self.cookie = None
self.header = dict()
self.proxy = None
self.delay = 1 # 请求睡眠时延
self.timeout = (13, 27) # 请求超时时间
self.verify = False # 请求SSL验证
self.domain = str() # 当前进行子域名收集的主域
self.subdomains = set() # 存放发现的子域
self.infos = dict() # 存放子域有关信息
self.results = list() # 存放模块结果
self.start = time.time() # 模块开始执行时间
self.end = None # 模块结束执行时间
self.elapse = None # 模块执行耗时
def have_api(self, *apis):
"""
Simply check whether the api information configure or not
:param apis: apis set
:return bool: check result
"""
if not all(apis):
return False
return True
def begin(self):
"""
begin log
"""
pass
def finish(self):
"""
finish log
"""
self.end = time.time()
self.elapse = round(self.end - self.start, 1)
pass
def head(self, url, params=None, check=True, **kwargs):
"""
Custom head request
:param str url: request url
:param dict params: request parameters
:param bool check: check response
:param kwargs: other params
:return: response object
"""
session = requests.Session()
session.trust_env = False
try:
resp = session.head(url,
params=params,
cookies=self.cookie,
headers=self.header,
proxies=self.proxy,
timeout=self.timeout,
verify=self.verify,
**kwargs)
except Exception as e:
pass
return None
if not check:
return resp
if check_response('HEAD', resp):
return resp
return None
def get(self, url, params=None, check=True, ignore=False, raise_error=False, **kwargs):
"""
Custom get request
:param str url: request url
:param dict params: request parameters
:param bool check: check response
:param bool ignore: ignore error
:param bool raise_error: raise error or not
:param kwargs: other params
:return: response object
"""
session = requests.Session()
session.trust_env = False
level = 'ERROR'
if ignore:
level = 'DEBUG'
try:
resp = session.get(url,
params=params,
cookies=self.cookie,
headers=self.header,
proxies=self.proxy,
timeout=self.timeout,
verify=self.verify,
**kwargs)
except Exception as e:
if raise_error:
if isinstance(e, requests.exceptions.ConnectTimeout):
raise e
return None
if not check:
return resp
if check_response('GET', resp):
return resp
print('xx')
print(resp.text)
return None
def post(self, url, data=None, check=True, **kwargs):
"""
Custom post request
:param str url: request url
:param dict data: request data
:param bool check: check response
:param kwargs: other params
:return: response object
"""
session = requests.Session()
session.trust_env = False
try:
resp = session.post(url,
data=data,
cookies=self.cookie,
headers=self.header,
proxies=self.proxy,
timeout=self.timeout,
verify=self.verify,
**kwargs)
except Exception as e:
print(e)
return None
if not check:
return resp
if check_response('POST', resp):
return resp
return None
def delete(self, url, check=True, **kwargs):
"""
Custom delete request
:param str url: request url
:param bool check: check response
:param kwargs: other params
:return: response object
"""
session = requests.Session()
session.trust_env = False
try:
resp = session.delete(url,
cookies=self.cookie,
headers=self.header,
proxies=self.proxy,
timeout=self.timeout,
verify=self.verify,
**kwargs)
except Exception as e:
print(e)
return None
if not check:
return resp
if check_response('DELETE', resp):
return resp
return None
def get_header(self):
"""
Get request header
:return: header
"""
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:27.0) Gecko/20100101 Firefox/27.0)',}
if isinstance(headers, dict):
self.header = headers
return headers
return self.header
def get_proxy(self, module):
"""
Get proxy
:param str module: module name
:return: proxy
"""
pass
def match_subdomains(self, resp, distinct=True, fuzzy=True):
if not resp:
return set()
elif isinstance(resp, str):
return match_subdomains(self.domain, resp, distinct, fuzzy)
elif hasattr(resp, 'text'):
return match_subdomains(self.domain, resp.text, distinct, fuzzy)
else:
return set()
def collect_subdomains(self, resp):
subdomains = self.match_subdomains(resp)
self.subdomains.update(subdomains)
return self.subdomains
def save_json(self):
"""
Save the results of each module as a json file
:return bool: whether saved successfully
"""
pass
def gen_result(self):
"""
Generate results
"""
if not len(self.subdomains): # 该模块一个子域都没有发现的情况
result = {'id': None,
'alive': None,
'request': None,
'resolve': None,
'url': None,
'subdomain': None,
'port': None,
'level': None,
'cname': None,
'ip': None,
'public': None,
'cdn': None,
'status': None,
'reason': None,
'title': None,
'banner': None,
'header': None,
'history': None,
'response': None,
'ip_times': None,
'cname_times': None,
'ttl': None,
'cidr': None,
'asn': None,
'org': None,
'addr': None,
'isp': None,
'resolver': None,
'module': self.module,
'source': self.source,
'elapse': self.elapse,
'find': None}
self.results.append(result)
else:
for subdomain in self.subdomains:
url = 'http://' + subdomain
level = subdomain.count('.') - self.domain.count('.')
info = self.infos.get(subdomain)
if info is None:
info = dict()
cname = info.get('cname')
ip = info.get('ip')
ip_times = info.get('ip_times')
cname_times = info.get('cname_times')
ttl = info.get('ttl')
if isinstance(cname, list):
cname = ','.join(cname)
ip = ','.join(ip)
ip_times = ','.join([str(num) for num in ip_times])
cname_times = ','.join([str(num) for num in cname_times])
ttl = ','.join([str(num) for num in ttl])
result = {'id': None,
'alive': info.get('alive'),
'request': info.get('request'),
'resolve': info.get('resolve'),
'url': url,
'subdomain': subdomain,
'port': 80,
'level': level,
'cname': cname,
'ip': ip,
'public': info.get('public'),
'cdn': info.get('cdn'),
'status': None,
'reason': info.get('reason'),
'title': None,
'banner': None,
'header': None,
'history': None,
'response': None,
'ip_times': ip_times,
'cname_times': cname_times,
'ttl': ttl,
'cidr': info.get('cidr'),
'asn': info.get('asn'),
'org': info.get('org'),
'addr': info.get('addr'),
'isp': info.get('isp'),
'resolver': info.get('resolver'),
'module': self.module,
'source': self.source,
'elapse': self.elapse,
'find': len(self.subdomains)}
self.results.append(result)
def save_db(self):
"""
Save module results into the database
"""
pass
class Search(Module):
"""
Search base class
"""
def __init__(self):
Module.__init__(self)
self.page_num = 0 # 要显示搜索起始条数
self.per_page_num = 50 # 每页显示搜索条数
self.recursive_search = False
self.recursive_times = 2
self.full_search = False
@staticmethod
def filter(domain, subdomain):
"""
生成搜索过滤语句
使用搜索引擎支持的-site:语法过滤掉搜索页面较多的子域以发现新域
:param str domain: 域名
:param set subdomain: 子域名集合
:return: 过滤语句
:rtype: str
"""
common_subnames = {'i', 'w', 'm', 'en', 'us', 'zh', 'w3', 'app', 'bbs',
'web', 'www', 'job', 'docs', 'news', 'blog', 'data',
'help', 'live', 'mall', 'blogs', 'files', 'forum',
'store', 'mobile'}
statements_list = []
subdomains_temp = set(map(lambda x: x + '.' + domain, common_subnames))
subdomains_temp = list(subdomain.intersection(subdomains_temp))
for i in range(0, len(subdomains_temp), 2): # 同时排除2个子域
statements_list.append(''.join(set(map(lambda s: ' -site:' + s,
subdomains_temp[i:i + 2]))))
return statements_list
def match_location(self, url):
"""
匹配跳转之后的url
针对部分搜索引擎(如百度搜索)搜索展示url时有显示不全的情况
此函数会向每条结果的链接发送head请求获取响应头的location值并做子域匹配
:param str url: 展示结果的url链接
:return: 匹配的子域
:rtype set
"""
resp = self.head(url, check=False, allow_redirects=False)
if not resp:
return set()
location = resp.headers.get('location')
if not location:
return set()
return set(self.match_subdomains(location))
def check_subdomains(self, subdomains):
"""
检查搜索出的子域结果是否满足条件
:param subdomains: 子域结果
:return:
"""
if not subdomains:
# 搜索没有发现子域名则停止搜索
return False
if not self.full_search and subdomains.issubset(self.subdomains):
# 在全搜索过程中发现搜索出的结果有完全重复的结果就停止搜索
return False
return True
def recursive_subdomain(self):
# 递归搜索下一层的子域
# 从1开始是之前已经做过1层子域搜索了,当前实际递归层数是layer+1
for layer_num in range(1, self.recursive_times):
for subdomain in self.subdomains:
# 进行下一层子域搜索的限制条件
count = subdomain.count('.') - self.domain.count('.')
if count == layer_num:
yield subdomain
def export(name, domain, content):
file = os.path.join(str(name)+'-' + str(domain) + '.txt')
if not os.path.exists('result'):
os.mkdir('result')
with open('result/' + file, 'a+', encoding='utf-8') as f:
if isinstance(content, (list)):
content = '\n'.join(content)
f.write(str(content))
f.write('\n')
class Google(Search):
def __init__(self, domain):
Search.__init__(self)
self.domain = domain
self.module = 'Search'
self.source = 'GoogleAPISearch'
self.addr = 'https://www.googleapis.com/customsearch/v1'
self.delay = 1
self.key = 'AIzqPnTT3LR4tSuPJP2WDkOQUdxC7wOs'
self.id = 'xxx'
self.per_page_num = 10 # 每次只能请求10个结果
def search(self, filtered_subdomain=''):
"""
发送搜索请求并做子域匹配
:param str domain: 域名
:param str filtered_subdomain: 过滤的子域
"""
self.page_num = 1
data = []
while True:
word = 'site:' + self.domain + filtered_subdomain
time.sleep(self.delay)
self.header = self.get_header()
params = {'key': self.key, 'cx': self.id,
'q': word, #'fields': 'items/link',
'start': self.page_num, 'num': self.per_page_num}
resp = self.get(self.addr, params)
print(resp.text)
data.append(resp.text)
subdomains = self.match_subdomains(resp)
if not self.check_subdomains(subdomains):
break
self.subdomains.update(subdomains)
self.page_num += self.per_page_num
if self.page_num > 100: # 免费的API只能查询前100条结果
break
if data:
export(self.__class__.__name__, self.domain, data)
'''
替换476和477行 api-key
输出方法在455行,455往上基本不需要管
免费用户单次只能查询到100条数据,如果有会员,注释504行那儿
爬取站点需要在google后台添加站点
'''
if __name__ == '__main__':
file = "targets.txt" # 此处添加文件名
with open(file, 'r', encoding='utf-8') as f:
for domain in f.readlines():
google = Google(domain.strip())
google.search()