WAV为微软公司(Microsoft)开发的一种声音文件格式,它符合RIFF(Resource Interchange File Format)文件规范,用于保存Windows平台的音频信息资源,被Windows平台及其应用程序所广泛支持,
该格式也支持MSADPCM,CCITT A LAW等多种压缩运算法,支持多种音频数字,取样频率和声道,标准格式化的WAV文件和CD格式一样,也是44.1K的取样频率,16位量化数字,因此在声音文件质量和CD相差无几。
WAVE文件为了与RIFF保持一致,数据采用“chunk”来存储。
因此,如果想要在WAVE文件中补充一些新的信息,只需要在在新chunk中添加信息,而不需要改变整个文件。这也是设计IFF最初的目的。
对于一个基本的WAVE文件而言,最少包含以下三种Chunk:
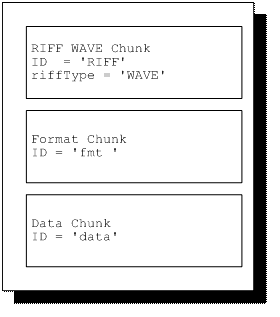
以上三个chunk 顺序固定,对于其它的chunk,顺序没有严格的限制。
具体格式如下:
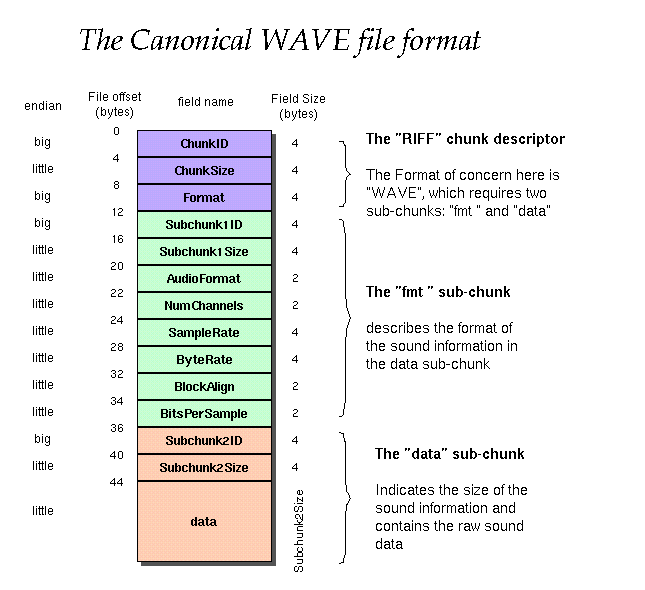
然而,所有基于压缩编码的WAV文件必须含有fact块。此外所有其它块都是可选的。fmt,Data及fact块均为RIFF块的子块。WAV文件的文件格式类型标识符为“WAVE”。

各个chunk中字段的意义如下:
RIFF chunk
| ID | big-endian | FOURCC 值为'R' 'I' 'F' 'F' |
| Size | little-endian | data字段中数据的字节数 |
| Data | big-endian | 包含其它的chunk |
Format chunk
| ID | big-endian | FOURCC 值为 'f' 'm' 't' ' ' | |
| Size | little-endian | 数据字段包含数据的大小。如无扩展块,则值为16;有扩展块,则值为 16 + 2字节扩展块长度 + 扩展块长度或者值为18(只有扩展块的长度为2字节,值为0) | |
| Data | little-endian | format_tag | 2字节,表示音频数据的格式。如值为1,表示使用PCM格式。 |
| little-endian | channels | 2字节,声道数。值为1则为单声道,为2则是双声道。 | |
| little-endian | samples_per_sec | 采样率,主要有22.05KHz,44.1kHz和48KHz。 | |
| little-endian | bytes_per sec | 音频的码率,每秒播放的字节数。samples_per_sec * channels * bits_per_sample / 8,可以估算出使用缓冲区的大小 | |
| little-endian | block_align | 数据块对齐单位,一次采样的大小,值为声道数 * 量化位数 / 8,在播放时需要一次处理多个该值大小的字节数据。 | |
| little-endian | bits_per_sample | 音频sample的量化位数,有16位,24位和32位等。 | |
| cbSize | 扩展区的长度 | ||
| 扩展格式块内容 | 22字节,具体介绍请看下面 | ||
其中 format_tag 可以取如下值:
| 格式代码 | 格式名称 | fmt 块长度 | fact 块 |
| 1(0x0001) | PCM/非压缩格式 | 16 | |
| 2(0x0002 | Microsoft ADPCM | 18 | √ |
| 3(0x0003) | IEEE float | 18 | √ |
| 6(0x0006) | ITU G.711 a-law | 18 | √ |
| 7(0x0007) | ITU G.711 μ-law | 18 | √ |
| 49(0x0031) | GSM 6.10 | 20 | √ |
| 64(0x0040) | ITU G.721 ADPCM | √ | |
| 65,534(0xFFFE) | 见子格式块中的编码格式 | 40 |
其中的扩展格式块:
当WAV文件使用的不是PCM编码方式是,就需要扩展格式块,它是在基本的Format chunk又添加一段数据。
该数据的前两个字节,表示的扩展块的长度。紧接其后的是扩展的数据区,含有扩展的格式信息,其具体的长度取决于压缩编码的类型。
当某种编码方式(如 ITU G.711 a-law)使扩展区的长度为0,扩展区的长度字段还必须保留,只是其值设置为0。
扩展区的各个字节的含义如下:
| Size | 扩展区的数据长度 ,可以为0或22 |
| valid_bits_per_sample | 有效的采样位数,最大值为采样字节数 * 8。可以使用更灵活的量化位数,通常音频sample的量化位数为8的倍数,但是使用了WAVE_FORMAT_EXTENSIBLE时,量化的位数有扩展区中的valid bits per sample来描述,可以小于Format chunk中制定的bits per sample |
| channle mask | 4字节,声道掩码 |
| sub format | 16字节,GUID,include the data format code,数据格式码。 |
在Format chunk中的format_tag设置为0xFFFE时,表示使用扩展区中的sub_format来决定音频的数据的编码方式。在以下几种情况下必须要使用WAVE_FORMAT_EXTENSIBLE
- PCM数据的量化位数大于16
- 音频的采样声道大于2
- 实际的量化位数不是8的倍数
- 存储顺序和播放顺序不一致,需要指定从声道顺序到声卡播放顺序的映射情况。
Fact chunk (可选)
| ID | FOURCC 值为 'f' 'a' 'c' 't' |
| Size | 数据域的长度,4(最小值为4) |
| Data | 每个声道的采样总数 4字节 |
Data chunk
| ID | FOURCC 值为'd' 'a' 't' 'a' |
| Size | 数据域的长度 |
| Data |
具体的音频数据存放在这里 |
Data块中存放的是音频的采样数据。每个sample按照采样的时间顺序写入,对于使用多个字节的sample,使用小端模式存放(低位字节存放在低地址,高位字节存放在高地址)。对于多声道的sample采用交叉存放的方式。例如:立体双声道的sample存储顺序为:声道1的第一个sample,声道2的第一个sample;声道1的第二个sample,声道2的第二个sample;依次类推....。对于PCM数据,有以下两种的存储方式:
- 单声道,量化位数为8,使用偏移二进制码
- 除上面之外的,使用补码方式存储。
描述WAVE文件的基本单元是“Sample”,一个Sample代表采样一次得到的数据。因此如果用44KHz采样,将在一秒中得到44000个Sample。
每个Sample可以用8位、24位,甚至32位表示(位数没有限制,只要是8的整数倍即可),位数越高,音频质量越好。
注意:8位代表无符号的数值,而16位或16位以上代表有符号的数值
每秒数据大小(字节)=采样率 * 声道数 * sample比特数 / 8