前言
awk是一种很棒的语言,它适合文本处理和报表生成。
- 模式扫描和处理。处理文本流。
awk不仅仅是Linux系统中的一个命令,而是一种编程语言,可以用来处理数据和生成报告。
处理的数据:
- 可以是一个或多个文件
- 可以是来自标准输入
- 也可以通过管道获取标准输入
awk可以在命令行上直接编辑命令进行操作,也可以编写成awk程序来进行更为复杂的运用。
awk中的概念:
- 字段(域)与记录
- 模式匹配
- 基本的awk执行过程
- awk常用内置变量
- awk数组(工作常用)
- awk语法:循环,条件
- awk常用函数
- 向awk传递参数
- awk引用shell变量
- awk编程
1. awk实战讲解
1.1 awk的环境简介
涉及的awk为gawk,即为GNU版本的awk。
[root@oldboy test]# cat /etc/redhat-release
CentOS release 6.7 (Final)
[root@oldboy test]# uname -r
2.6.32-573.el6.x86_64
[root@oldboy test]# ll `which awk`
lrwxrwxrwx. 1 root root 4 Aug 30 07:19 /bin/awk -> gawk
[root@oldboy test]# awk --version
GNU Awk 3.1.7
1.2 awk的格式
awk指令是由模式,动作,或者模式和动作的组合组成。
模式pattern,可以类似理解成sed的模式匹配,可以由表达式组成,也可以是两个正斜杠之间的正则表达式。比如NR==1,这就是模式,可以把他理解为一个条件。
动作action,是由在大括号{} 里面的一条或多条语句组成,语句之间使用分号隔开。
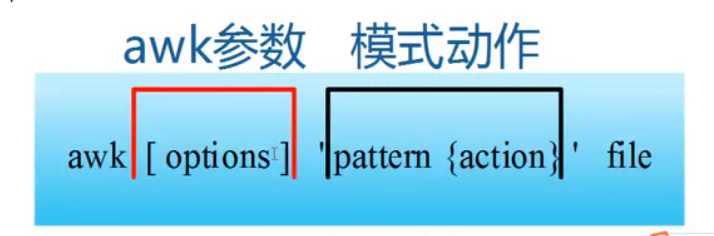
awk处理的内容可以来自标准输入,一个或多个文本或管道。

1.3 awk的原理
通过一个简单的命令,我们来了解其工作原理。
awk '{print $0}' /etc/passwd
echo hhh|awk '{print "hello,world"}'
awk '{print "hiya"}' /etc/passwd
输出:


[root@oldboy /]# awk '{print $0}' /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin ... stu06:x:831:831::/home/stu06:/bin/bash stu07:x:832:832::/home/stu07:/bin/bash stu08:x:833:833::/home/stu08:/bin/bash stu09:x:834:834::/home/stu09:/bin/bash stu10:x:835:835::/home/stu10:/bin/bash [root@oldboy /]# echo hhh|awk '{print "hello,world"}' hello,world [root@oldboy /]# awk '{print "hiya"}' /etc/passwd hiya hiya ... hiya hiya hiya hiya hiya # 行数和/etc/passwd的行数相等
通过上面的示例,解释awk做了些什么:
- 调用awk时,我们指定/etc/passwd作为输入文件。
- 执行awk时,它依次对/etc/passwd中的每一行执行print命令。
- 所有输出都发送到stdout,所得到的结果与执行cat /etc/passwd完全相同。
现在,解释{print} 代码块:
- 在awk中,花括号{} 将几块代码组合到一起,这一点类似C语言。
- 在代码块中只有一条print命令。在awk中,如果只出现print命令,那么将打印当前行的全部内容。
再次说明,awk对输入文件中的每一行都执行这个脚本:

awk是通过一行一行的处理文件。
这条命令中包括模式部分(条件)和动作部分(动作),awk将处理模式指定的行。
awk执行过程小结:
- awk读入第一行内容
- 判断是否符合模式中的条件(NR>=2)
- 如果匹配,则执行对应的动作{print NR,$0}
- 如果不匹配,继续读取下一行
- 继续读取下一行
- 重复读取--判断--执行,直到读取到最后一行EOF(end of file)
1.4 AWK基本语法:命令行 和 程序文件
AWK的使用很简单,我们可以从命令行提供AWK或在具有AWK命令的文本文件的形式的命令。
1.4.1 AWK命令行
[root@oldboy test]# cat marks.txt
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
[root@oldboy test]# awk '{print}' marks.txt
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
1.4.2 AWK程序文件
提供AWK命令在脚本文件中:
awk [options] -f file ...
首先,创建一个包含AWK命令的文本文件command.awk文件:
[root@oldboy test]# echo "{print}" > command.awk
[root@oldboy test]# cat command.awk
{print}
[root@oldboy test]# awk -f command.awk marks.txt
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
[root@oldboy test]# cat command.awk
NR == 1{print $NF}
[root@oldboy test]# awk -f command.awk marks.txt
80
1.4.3 AWK标准选项
- -v 分配一个值的变量,允许程序执行前分配。
-
[root@oldboy test]# awk -v name=Jerry 'BEGIN{printf "Name=%s ",name}' Name=Jerry [root@oldboy test]# awk -v name=Jerry 'BEGIN{print "Name = ",name}' Name = Jerry
-
- --dump-variables[=file] 打印全局变量和最终值到文件的一个排序列表。默认的文件是awkvars.out
-
[root@oldboy test]# awk --dump-variables '' [root@oldboy test]# cat awk cat: awk: No such file or directory [root@oldboy test]# awk --dump-variables '' [root@oldboy test]# ls awk_test_file.txt awkvars.out command.awk marks.txt recode.txt test.txt [root@oldboy test]# cat awkvars.out ARGC: number (1) ARGIND: number (0) ARGV: array, 1 elements BINMODE: number (0) CONVFMT: string ("%.6g") ERRNO: number (0) FIELDWIDTHS: string ("") FILENAME: string ("") FNR: number (0) FS: string (" ") IGNORECASE: number (0) LINT: number (0) NF: number (0) NR: number (0) OFMT: string ("%.6g") OFS: string (" ") ORS: string (" ") RLENGTH: number (0) RS: string (" ") RSTART: number (0) RT: string ("") SUBSEP: string ("�34") TEXTDOMAIN: string ("messages")
-
- --help 在标准输出的帮助信息
-
[root@oldboy test]# awk --help Usage: awk [POSIX or GNU style options] -f progfile [--] file ... Usage: awk [POSIX or GNU style options] [--] 'program' file ... POSIX options: GNU long options: -f progfile --file=progfile -F fs --field-separator=fs -v var=val --assign=var=val -m[fr] val -O --optimize -W compat --compat -W copyleft --copyleft -W copyright --copyright -W dump-variables[=file] --dump-variables[=file] -W exec=file --exec=file -W gen-po --gen-po -W help --help -W lint[=fatal] --lint[=fatal] -W lint-old --lint-old -W non-decimal-data --non-decimal-data -W profile[=file] --profile[=file] -W posix --posix -W re-interval --re-interval -W source=program-text --source=program-text -W traditional --traditional -W usage --usage -W use-lc-numeric --use-lc-numeric -W version --version To report bugs, see node `Bugs' in `gawk.info', which is section `Reporting Problems and Bugs' in the printed version. gawk is a pattern scanning and processing language. By default it reads standard input and writes standard output. Examples: gawk '{ sum += $1 }; END { print sum }' file gawk -F: '{ print $1 }' /etc/passwd
-
- --lint[=fatal] 允许检查非便携式或可疑的构造。当提供的一个参数是致命的,它会警告消息为错误。
-
[root@oldboy test]# awk --lint '' /bin/ls awk: warning: empty program text on command line awk: warning: source file does not end in newline awk: warning: no program text at all!
-
- --posix 打开严格的POSIX兼容,其中所有普通和awk特定的扩展将被禁用
- --profile[=file] 生成文件的程序相当于打印版本。默认的文件是awkprof.out。
-
[root@oldboy test]# awk --profile 'BEGIN{print "---|Header|-- "}{print} END{print "---|Footer|--- "}' marks.txt >/dev/null [root@oldboy test]# cat awkprof.out # gawk profile, created Mon Nov 25 18:31:11 2019 # BEGIN block(s) BEGIN { print "---|Header|-- " } # Rule(s) { print $0 } # END block(s) END { print "---|Footer|--- " }
-
- --traditional 可以禁用所有gawk特定的扩展
- --version 显示awk程序的版本信息
1.5 BEGIN和END模块
通常,对于每个输入行,awk都会执行每个脚本代码块一次。
然而,在许多变成情况中,可能需要在awk开始处理文件的文本之前执行初始化代码。
对于这种情况,awk允许定义一个BEGIN块。
awk在开始处理输入文件之前会执行BEGIN块,因此,它是初始化FS(字段分隔符)变量、打印页眉或初始化其它在程序中以后会使用的全局变量的极佳位置。
awk还提供了另一个特殊块,叫做END块。
awk在处理了输入文件中的所有行之后执行END块。
通常,END块用于执行最终计算或打印应该出现在输出流结尾的摘要信息。
1.6 运算符
- 赋值运算符
- =
- +=
- -=
- *=
- /=
- %=
- ^=
- **=
- 逻辑运算符
- || 逻辑或
- && 逻辑与
- 正则运算符
- ~ 匹配正则表达式
- !~ 不匹配正则表达式
- 关系运算符
- <
- <=
- >
- >=
- !=
- ==
- 算术运算符
- + - * / % 加减乘除,求余
- + - ! 一元加,减 逻辑非
- ^ ** 求幂
- ++ -- 增加或减少,作为前缀或后缀
- 其它运算符
- $ 字段引用
- 空格 字符串连接符
- ?: 三元运算符 expr ? statement1: statement2
- in 数组中是否存在某种键值
示例:
赋值运算符:=,+=,-=,*=,/=,%=,^=,**=
# a+=5等价于a=a+5 [root@oldboy test]# awk 'BEGIN{a=5;a+=5;print a}' awk_test_file.txt 10 # 其余和+=等价 [root@oldboy test]# awk 'BEGIN{a=5;a-=5;print a}' awk_test_file.txt 0 [root@oldboy test]# awk 'BEGIN{a=5;a*=5;print a}' awk_test_file.txt 25 [root@oldboy test]# awk 'BEGIN{a=5;a/=5;print a}' awk_test_file.txt 1 [root@oldboy test]# awk 'BEGIN{a=5;a%=5;print a}' awk_test_file.txt 0 [root@oldboy test]# awk 'BEGIN{a=5;a^=5;print a}' awk_test_file.txt 3125 [root@oldboy test]# awk 'BEGIN{a=5;a**=5;print a}' awk_test_file.txt 3125
逻辑运算符:||, &&
# 根据a,b的赋值,逻辑判断true or false # a>2&&b>1 false # a=1|b>1 true
[root@oldboy test]# awk 'BEGIN{a=1;b=2;print(a>2&&b>1, a=1||b>1)}' 0 1 [root@oldboy test]# awk 'BEGIN{a=1;print(a>1)}' 0 [root@oldboy test]# awk 'BEGIN{a=2;print(a>1)}' 1
正则运算法:~, !~
[root@oldboy test]# awk -F ":" '$NF~/nologin$/{print $NF}' awk_test_file.txt /sbin/nologin /sbin/nologin /sbin/nologin /sbin/nologin /sbin/nologin /sbin/nologin [root@oldboy test]# awk 'BEGIN{a="100testaaa";if(a~/100/){print "ok"}}' ok [root@oldboy test]# echo|awk 'BEGIN{a="100testaaa"}a~/100/{print "ok"}' ok
关系运算符:<, <=, >, >=, !=, ==
> < 可以作为字符串比较,也可以用作数值比较,关键看操作数如果是字符串 就会转换为字符串比较。两个都为数字 才转为数值比较。字符串比较:按照ascii码顺序比较。
# 11字符串和数字9无法进行比较 [root@oldboy test]# awk 'BEGIN{a="11";if(a>=9){print "ok"}}' # 数字11和9之间的比较。两个都为数字 才转为数值比较 [root@oldboy test]# awk 'BEGIN{a=11;if(a>=9){print "ok"}}' ok # 字符串比较,按照ascii码顺序比较 [root@oldboy test]# awk 'BEGIN{a;if(a>=b){print "ok"}}' ok
算术运算符:+, -, *, /, &, +, - , !, ^, **, ++, --;+,-,!(一元加减,逻辑非)
说明,所有用作算术运算符 进行操作,操作数自动转为数值,所有非数值都变为0。
# 加
[root@oldboy test]# awk 'BEGIN{a="1";b=2;print(a+b)}' 3
# 减 [root@oldboy test]# awk 'BEGIN{a="1";b=2;print(a-b)}' -1
# 乘 [root@oldboy test]# awk 'BEGIN{a="1";b=2;print(a*b)}' 2
# 除 [root@oldboy test]# awk 'BEGIN{a="1";b=2;print(a/b)}' 0.5
# 取余数,其中&是网络整理文档错误,结果一堆文档都是照抄的错误,取余就是mod,%符号 [root@oldboy test]# awk 'BEGIN{a="1";b=2;print(a&b)}' awk: BEGIN{a="1";b=2;print(a&b)} awk: ^ syntax error [root@oldboy test]# awk 'BEGIN{a="1";b=2;print(a%b)}' 1
# 求幂,^,** (***也是文档错误,大面积copy出错) [root@oldboy test]# awk 'BEGIN{a="1";b=2;print(a^b)}' 1 [root@oldboy test]# awk 'BEGIN{a="1";b=2;print(b^a)}' 2 [root@oldboy test]# awk 'BEGIN{a="1";b=2;print(b**a)}' 2 [root@oldboy test]# awk 'BEGIN{a="1";b=2;print(b***a)}' awk: BEGIN{a="1";b=2;print(b***a)} awk: ^ syntax error
# ++,--增加或减少,作为前缀或后缀
# a++ 即a输出原值,再次调用a++,则是a+=1
[root@oldboy ~]# awk 'BEGIN{a=1;b=2;print a++}'
1
[root@oldboy ~]# awk 'BEGIN{a=1;b=2;print a++,b++}'
1 2
# ++b即为b+=1;--b即为b-=1;b--即先输出原值,如再次调用则为b-=1
[root@oldboy ~]# awk 'BEGIN{a=1;b=2;print ++b}'
3
[root@oldboy ~]# awk 'BEGIN{a=1;b=2;print --b}'
1
[root@oldboy ~]# awk 'BEGIN{a=1;b=2;print b--}'
2
一元加减,逻辑非 +,-,!
- 一元加法运算,由+表示,通过+1乘以单操作数。
- 一元减法运算,由-表示,通过-1乘以单个操作数。
# a = +a 即 a=a*1
[root@oldboy ~]# awk 'BEGIN{a=-10; print a= +a}'
-10
# -10*1=-10; -10 *1 =-10
[root@oldboy ~]# awk 'BEGIN{a=-10; print a= +a,a = +a}'
-10 -10
# -10 + (-10)=-20
[root@oldboy ~]# awk 'BEGIN{a=-10; print a= +a,a = +a+a}'
-10 -20
# -10 * -1 = 10
[root@oldboy ~]# awk 'BEGIN{a=-10; print a= +a,a = -a}'
-10 10
其它运算符:$, 空格 ,?:, in
三元运算轻松实现条件表达式。
语法:
condition expression ? statement1: statement2
当条件表达式返回值为true时,statement1被执行,否则执行statement2
[root@oldboy ~]# awk 'BEGIN{a=10;b=10;(a>b) ? max=a : max=b; print "Max =",max}'
Max = 10
数组成员运算符 in
通过in表示。在访问数组元素时使用。

[root@oldboy ~]# awk 'BEGIN{arr[0]=1;arr[1]=2;arr[2]=3;for (i in arr) printf "arr[%d]=%d
",i,arr[i]}'
arr[0]=1
arr[1]=2
arr[2]=3
1.7 常用awk内置变量
- $0 当前记录
- $1~$n 当前记录的第n个字段
- FS 输入字符分隔符,默认是空格 field seperator
- RS 输入记录分隔符,默认为换行符 record seperator
- NF 当前记录中的字段个数,就是有多少列 number of field
- NR 已经读出的记录数,就是行号,从1开始 number of record
- OFS 输出字段分隔符,默认也是空格 ouput field seperator
- ORS 输出的记录分隔路,默认为换行符 output record seperator
1.7.1 字段(区域)和记录Field 和 Record
- field:字段,区域,域
- record:记录,默认一整行
1.7.1.1 字段(区域)field
每条记录都是由多个字段field组成的,默认情况下,字段之间的分隔符是由空白符(即空格,或制表符)来分隔,并且将分隔符记录在内置变量FS中。
每行记录的字段数保存在awk的内置变量NF中。

# 输出行号NR(number of record),NF为字段数(number of filed),FS为字段分隔符(field seperator)
[root@oldboy test]# awk -F ':' 'NR>=2 && NR<5 {print NR,NF,FS,$0}' awk_test_file.txt 2 7 : bin:x:1:1:bin:/bin:/sbin/nologin 3 7 : daemon:x:2:2:daemon:/sbin:/sbin/nologin 4 7 : adm:x:3:4:adm:/var/adm:/sbin/nologin
行号NR(number of record),NF为字段数(number of filed),FS为字段分隔符(field seperator)
字符分隔符FS是可以指定多个的。
FS指定的值对应的是一个正则表达式。
一定要注意在指定多分隔符的时候,字段会有对应的变化。
[root@oldboy test]# ifconfig eth3|awk 'NR==2'
inet addr:192.168.0.109 Bcast:192.168.0.255 Mask:255.255.255.0
[root@oldboy test]# ifconfig eth3|awk -F '[: ]+' 'NR==2 {print $2,$3,$4}'
inet addr 192.168.0.109
[root@oldboy test]# ifconfig eth3|awk -F '[: ]+' 'NR==2 {print $2"-->"$3"-->"$4}'
inet-->addr-->192.168.0.109
1.7.1.2 记录record
awk对每个要处理的输出数据认为都是具有格式和结构的,而不仅仅是一堆字符串。
默认情况下,每一行内容都成为一条记录,并以换行符结束。

RS,即record seperator。
- 默认情况下,一行==>即,一个记录,每行,都是一个记录
- RS,record seperator 每个记录读入的时候的分隔符
- NR,number of record 行号,记录的行。awk当前处理着的,记录的数。
- ORS,output record seperator 输出记录时候的分隔符
awk使用内置变量存放 记录分隔符RS。
记录分隔符RS,也可以以特定的方式修改。
awk使用$0表示整行记录。记录分隔符 保存在RS变量中。
awk对每一行的记录号,都由内置变量NR来保存。每处理完一条记录NR的值就会自动+1。
示例:通过BEGIN中,将RS设置为":",将记录的换行符从 换成了":"
[root@oldboy test]# awk 'NR==1{print $0}' awk_test_file.txt|awk 'BEGIN{RS=":"}{print NR,$0}'
1 root
2 x
3 0
4 0
5 root
6 /root
7 /bin/bash
企业案例:计算文件中每个字母的重复数量
[root@oldboy test]# awk 'BEGIN{RS="[/:
0-9]+"}{print $0}' awk_test_file.txt|sort|uniq -c|sort -rn
12 sbin
10 x
6 nologin
5 bin
4 var
3 uucp
3 sync
3 spool
3 shutdown
3 root
3 mail
3 halt
3 adm
2 lp
2 daemon
1 lpd
1 bash
[root@oldboy test]# grep -E '[a-zA-Z]+' awk_test_file.txt -o|sort|uniq -c|sort -rn
12 sbin
10 x
6 nologin
5 bin
4 var
3 uucp
3 sync
3 spool
3 shutdown
3 root
3 mail
3 halt
3 adm
2 lp
2 daemon
1 lpd
1 bash
# 将FS设置为:或/,至少一个或一个以上 作为字段分隔符 # 打印输出第一个字段,第二个字段和最后一个字段 [root@oldboy test]# awk 'BEGIN{FS="[:/]+"}{print $1,$2,$NF}' awk_test_file.txt root x bash bin x nologin daemon x nologin adm x nologin lp x nologin sync x sync shutdown x shutdown halt x halt mail x nologin uucp x nologin # FS="[[:space:]+]" 一个或多个空 白空格,默认的 [root@oldboy test]# awk 'BEGIN{FS="[[:space:]+]"}{print $1}' test.txt test01 test11 test21 # 查看NF,字段数量 # $NF,显示每行最后一个字段的值,相当于$7 [root@oldboy test]# awk -F ':' 'NR==1{print NF}' awk_test_file.txt 7 [root@oldboy test]# awk -F ':' 'NR==1{print NF,$NF}' awk_test_file.txt 7 /bin/bash
[root@oldboy test]# cat recode.txt Jimmy the Weasel 100 Pleasant Drive San Francisco, CA 12345 Big Tony 200 Incognito Ave. Suburia, WA 67890 # 将FS设置为 , 将RS设置为空白,会将每条记录都由 空白行分隔 [root@oldboy test]# awk 'BEGIN{FS=" ";RS=""}{print $1"-->"$2"===>"$3}' recode.txt Jimmy the Weasel-->100 Pleasant Drive===>San Francisco, CA 12345 Big Tony-->200 Incognito Ave.===>Suburia, WA 67890
[root@oldboy test]# awk 'BEGIN{FS=":"}{print $1,$2,$3}' awk_test_file.txt root x 0 bin x 1 daemon x 2 adm x 3 lp x 4 sync x 5 shutdown x 6 halt x 7 mail x 8 uucp x 10
# 将OFS设置为***作为输出的字段分隔符 [root@oldboy test]# awk 'BEGIN{FS=":";OFS="***"}{print $1,$2,$3}' awk_test_file.txt root***x***0 bin***x***1 daemon***x***2 adm***x***3 lp***x***4 sync***x***5 shutdown***x***6 halt***x***7 mail***x***8 uucp***x***10
# 将ORS设置为??,作为输出的行的分隔符 [root@oldboy test]# awk 'BEGIN{FS=":";OFS="***";ORS="??"}{print $1,$2,$3}' awk_test_file.txt root***x***0??bin***x***1??daemon***x***2??adm***x***3??lp***x***4??sync***x***5??shutdown***x***6??halt***x***7??mail***x***8??uucp***x***10??[root@oldboy test]#
1.7.2 其它AWK变量:
1. ARGC,ARGV
ARGC 在命令行提供参数的个数argument count
ARGV 存储在命令行参数的数组。数组的有效索引范围是0到ARGC-1,即[0, ARGC-1]。
[root@oldboy test]# awk 'BEGIN {print "Arguments =", ARGC}' 1 2 3 4
Arguments = 5
[root@oldboy test]# awk 'BEGIN{for (i=0;i <= ARGC-1;++i) {printf "ARGV[%d] = %s ",i,ARGV[i]}}' 1 2 3 4 ARGV[0] = awk ARGV[1] = 1 ARGV[2] = 2 ARGV[3] = 3 ARGV[4] = 4
CONVFMT 数字转换的格式和它的默认值是 %.6g convert format
[root@oldboy test]# awk 'BEGIN {print "Conversion Format =", CONVFMT}'
Conversion Format = %.6g
ENVIRON 环境变量的关联数组。
[root@oldboy test]# awk 'BEGIN{print ENVIRON["USER"]}'
root
要找到其它的环境变量名称,使用GNU/Linux的env命令。
FILENAME 代表了当前的文件名。
[root@oldboy test]# awk 'END{print FILENAME}' marks.txt marks.txt [root@oldboy test]# awk 'BEGIN{print FILENAME}' marks.txt # FILENAME在BEGIN块中是未定义的 [root@oldboy test]#
FNR 类似NR,但相对于当前文件。这个当AWK工作在多个文件 非常游泳。FNR的值将重置使用新的文件。
[root@oldboy test]# awk '{print "FNR:",FNR," NR:",NR}' marks.txt awk_test_file.txt FNR: 1 NR: 1 FNR: 2 NR: 2 FNR: 3 NR: 3 FNR: 4 NR: 4 FNR: 5 NR: 5 # 上面五行是marks.txt文件的行号 FNR: 1 NR: 6 # 下面是awk_test_file.txt文件的行号 FNR: 2 NR: 7 FNR: 3 NR: 8 FNR: 4 NR: 9 FNR: 5 NR: 10 FNR: 6 NR: 11 FNR: 7 NR: 12 FNR: 8 NR: 13 FNR: 9 NR: 14 FNR: 10 NR: 15
OFMT 输出格式数量和它的默认值是%.6g output format
[root@oldboy test]# awk 'BEGIN{print "OFMT=" OFMT}' OFMT=%.6g
RLENGTH 代表匹配match函数字符串的长度。AWK的匹配功能搜索输入字符串。
[root@oldboy test]# awk 'BEGIN{if (match("One Two Three","re")) {print RLENGTH}}' 2
RSTART 表示匹配match函数字符串中的第一个位置。(注意,位置索引的起始点为1)
[root@oldboy test]# awk 'BEGIN{if (match("One Two Three","Three")) {print RSTART }}'
9
SUBSEP 代表数组下标分隔符,它的默认值是 ^$。
[root@oldboy test]# awk 'BEGIN {print "SUBSEP =",SUBSEP}'|cat -vte SUBSEP = ^$
# cat -t参数相当于-vT,-e参数相当于-vE
# -v参数相当于 --show-nonprinting
# -T参数相当于 --show-tabs
# -E参数相当于 --show-ends
下面是GNU AWK 的特定变量:
ARGIND 表示索引在当前文件的ARGV将在处理。argument index。
# ARGIND显示的是ARGV参数数组中的文件的索引位置。
# ARGV为{0:awk, 1:marks.txt, 2:awk_test_file.txt}
# 因此显示处理的文件的索引分别为1和2
[root@oldboy test]# awk '{print "ARGIND =", ARGIND; print "Filename =", ARGV[ARGIND]}' marks.txt awk_test_file.txt ARGIND = 1 Filename = marks.txt ARGIND = 1 Filename = marks.txt ARGIND = 1 Filename = marks.txt ARGIND = 1 Filename = marks.txt ARGIND = 1 Filename = marks.txt ARGIND = 2 Filename = awk_test_file.txt ARGIND = 2 Filename = awk_test_file.txt ARGIND = 2 Filename = awk_test_file.txt ARGIND = 2 Filename = awk_test_file.txt ARGIND = 2 Filename = awk_test_file.txt ARGIND = 2 Filename = awk_test_file.txt ARGIND = 2 Filename = awk_test_file.txt ARGIND = 2 Filename = awk_test_file.txt ARGIND = 2 Filename = awk_test_file.txt ARGIND = 2 Filename = awk_test_file.txt
BINMODE 用来指定二进制模式对所有文件I/O在非POSIX系统。1,2,或3个数值,指定输入文件,输出文件或所有文件,分别应该使用二进制的I/O。字符串值r或w指定输入文件或输出文件,分别应该使用二进制的I/O。对rw orwr字符串值指定所有文件应使用二进制I/O。
ERRNO 一个字符串,指示错误时重定向失败函数getline或者接近调用失败。
[root@oldboy test]# awk 'BEGIN {ret=getline <"marks.txt"; if (ret == -1) {print "Error:",ERRNO}}' [root@oldboy test]# awk 'BEGIN {ret=getline <"ms.txt"; if (ret == -1) {print "Error:",ERRNO}}' Error: No such file or directory
FIELDWIDTHS 用空格分隔字段宽度列表。当此变量设置,GAWK解析而不是使用FS变量作为字段分隔符的值输入到固定宽度的字段。
IGNORECASE 当此变量设置GAWK变成不区分大小写。
[root@oldboy test]# awk 'BEGIN {IGNORECASE=1} /english/ ' marks.txt 4) Kedar English 85
LINT 提供了从GAWK程序--lint选项的动态控制。当此变量设置GAWK打印 lint警告。当指定的字符串值是致命的,lint 警告成为致命错误,类似 --lint=致命的。
[root@oldboy test]# awk 'BEGIN {LINT=1;a}' awk: warning: statement has no effect awk: warning: reference to uninitialized variable `a'
PROCINFO 包含进程的信息,如真实有效的UID号,进程ID号等关联数组。
[root@oldboy test]# awk 'BEGIN {print PROCINFO["pid"]}' 18678
TEXTDOMAIN 代表AWK程序的文本域。它是用来寻找用于该程序的字符串本地化翻译。
[root@oldboy test]# awk 'BEGIN {print TEXTDOMAIN}' messages
1.8 awk正则
- ^ 以...开头
- $ 以...结尾
- . 匹配任意单个字符
- * 匹配0个或多个前导字符(包括回车)
- + 匹配1个或多个前导字符
- ? 匹配0个或1个前导字符
- [] 匹配指定字符组内的任意一个字符
- [^] 匹配不在指定字符组内的任意一个字符
- () 子表达式组合 如:/(root)+/ 表示一个或多个rool组合,当有一些字符需要组合时,使用括号括起来
- | 或者
- 转义字符
- ~,!~ 匹配,不匹配的条件语句 $1~/root/ 匹配第一个字段$1中包含字符root的所有记录
注意,awk不支持元字符,和需要添加参数才能支持的元字符。
- x{m} x重复m次
- x{m,} x重复至少m次
- x{m,n} x重复m到n次(至少m次,同时不超过n次)
示例:
规则表达式:awk '/REG/{action}' file
- /REG/为正则表达式
# 对$0整行进行正则匹配 [root@oldboy test]# awk '/root/{print $0}' awk_test_file.txt root:x:0:0:root:/root:/bin/bash # 对每行的 $5 进行正则匹配 [root@oldboy test]# awk -F ":" '$5~/root/{print $0}' awk_test_file.txt root:x:0:0:root:/root:/bin/bash # 取ip,将FS这是为 空格和:(1个及以上) 输出指定的字段 [root@oldboy test]# ifconfig eth3|awk 'BEGIN{FS="[[:space:]:]+"} NR==2 {print $4}' 192.168.0.109 # 通过()组的方式设置两个或以上的分隔符 [root@oldboy test]# ifconfig eth3|awk 'BEGIN{FS="([[:space:]]|:)+"} NR==2 {print $4}' 192.168.0.109
布尔表达式:
awk '布尔表达式{action }' file
仅当对前面的布尔表达式得到true时,awk才执行代码块
[root@oldboy test]# awk -F ":" '$1=="root"{print $0}' awk_test_file.txt root:x:0:0:root:/root:/bin/bash [root@oldboy test]# awk -F ":" '($1=="root")&&($5=="root"){print $0}' awk_test_file.txt root:x:0:0:root:/root:/bin/bash
匹配每行中以":"为分隔符,第5个字段正则匹配(以l或u)开头的字段,整行输出。
[root@oldboy test]# awk -F ":" '$5~/^(l|u)/ {print $0}' awk_test_file.txt
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
awk不支持元字符,如果使用至少多少进行条件匹配,则需要使用参数--posix支持。
[root@oldboy test]# awk -F ":" '$5~/^(l|u)/ {print $NF}' awk_test_file.txt
/sbin/nologin
/sbin/nologin
# 没有--posix参数,不支持元字符
[root@oldboy test]# awk -F ":" '$5~/(l|u){1}/ {print $NF,$5}' awk_test_file.txt
# 添加--posix参数后
[root@oldboy test]# awk -F ":" --posix '$5~/(l|u){1}/ {print $NF,$5}' awk_test_file.txt
/sbin/nologin lp
/sbin/shutdown shutdown
/sbin/halt halt
/sbin/nologin mail
1.9 awk的范围模式
awk的范围模式就是 从pattern1 到 pattern2。
awk '/start pos/,/end pos/ {print $0}' file
匹配从条件1到条件2的范围。
awk的范围模式,与sed类似,但又有所不同。
awk不能直接使用行号来作为起始地址,因为awk具有内置变量NR来存储记录号,所以需要使用NR==1,NR==5这样来使用。
[root@oldboy test]# awk 'NR==5{print}' marks.txt 5) Hari History 89 [root@oldboy test]# sed -n '5p' marks.txt 5) Hari History 89
范围模式的处理原则是:
- 先匹配从第一个模式的首次出现到第二个模式的首次出现之间的内容,执行action。
- 然后匹配从第一个模式的下一次出现到第二个模式的下一次出现,直到文本结束。
- 如果匹配到第一个模式而没有匹配到第二个模式,则awk处理从第一个模式开始直到文本结束全部的行。
- 如果第一个模式不匹配,就算第二个模式匹配,awk依旧不处理任何行。
范围模式的时候,范围条件的时候,表达式必须能匹配一行。
# 行号NR从匹配第一行到第5行
[root@oldboy test]# awk 'NR==1,NR==5 {print $0}' marks.txt 1) Amit Physics 80 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
# 行号NR,匹配第二行到第5行 [root@oldboy test]# awk 'NR==2,NR==5 {print $0}' marks.txt 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
# 匹配第二行到含有History的行 [root@oldboy test]# awk 'NR==2,/History/ {print $0}' marks.txt 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
# 匹配Maths所在的行,到history的行 [root@oldboy test]# awk '/Maths/,/History/ {print $0}' marks.txt 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
# 匹配到第一行Maths的所在行,patter2未能匹配到,则输出后面的所有行 [root@oldboy test]# awk '/Maths/,/Historyll/ {print $0}' marks.txt 2) Rahul Maths 90 3) Shyam Biology 87 4) Kedar English 85 5) Hari History 89
# pattern1能匹配到,则不处理所有行 [root@oldboy test]# awk '/hh/,/History/ {print $0}' marks.txt
小结:
1. 模式 就是条件
2. 正则表达式 /REG/
3. 条件表达式 NR>=2 NR==2
4. 范围表达式
5. (NR==2,NR==5) 从第2行到第5行
6. /正则表达式-开始/, /正则结束/
7. $1~/正则表达式-开始/,$3~/正则 - 结束/ 行,记录
[root@oldboy test]# awk '$1~/2/,$3~/s/{print $0}' marks.txt # 匹配同一行,模式匹配结束 2) Rahul Maths 90
[root@oldboy test]# awk '$1~/2/,$3~/y/{print $0}' marks.txt
2) Rahul Maths 90
3) Shyam Biology 87