本部分主要涉及到TensorFlow的运作方式和主要操作
所需的代码在https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/tutorials/mnist
需要用到的代码文件有:
mnist.py 构建一个完全连接(full connected)的MNIST模型所需要的代码
fully_connected_feed.py 利用下载的数据集训练构建好的MNIST模型的主要代码,以数据反馈字典的形式为输出模型
只需要运行fully_connected_feed.py 就可以开始学习模型
准备数据
下载
在run_training()方法的一开始,input_data.read_dat_sets()函数会确保你的本地训练文件夹里,已经下载了正确的数据,然后将这些数据解压并返回一个含有DataSet实例的字典。
data_sets = input_data.read_data_sets(FLAGS.input_data_dir, FLAGS.fake_data)
注意:fake_data标记是用于单元测试的
数据集包括
data_sets.train |
55000个图像和标签(labels),作为主要训练集。 |
data_sets.validation |
5000个图像和标签,用于迭代验证训练准确度。 |
data_sets.test |
10000个图像和标签,用于最终测试训练准确度(trained accuracy) |
输入与占位符
placeholder_inputs()函数将生成两个tf.placeholder操作,定义传入图表中的shape参数,shape参数包括batch_size值,后续还会将实际的训练用例传入图表。(batch_size是预设的每次读入数据量大小)
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,
mnist.IMAGE_PIXELS))
labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size))
在后续的训练循环中,传入的整个图像和标签集会被切片输入,已符合每个操作设置的batch_size值,在运行阶段用feed_dict参数,将数据传入sess.run()函数
构建图表
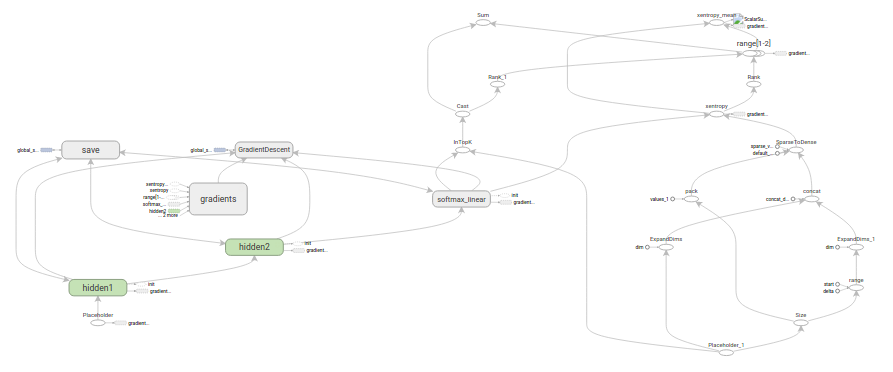
在为数据创建占位符后,就可以运行mnist.py文件,经过三阶段的模式函数操作:inferen(),loss()和training(),图表就构建完成了
inference() 尽可能的构建好图表,满足促使神经网路向前反馈并做出预测的要求
loss() 往inference图表中添加损失函数所必须的操作
training() 往损失图表中添加计算并应用梯度所需的操作
·推理(Inference)
inference()函数会尽可能地构建图表,做到返回包含了预测结果(output prediction)的Tensor 。
它接受图像占位符为输入,在此基础上借助ReLU激活函数,构建一对完全连接层,以及一个又啄是个节点,知名了输出logits模型的线性层。
每一层都创建于一个唯一的tf.name_scope之下,创建ゆ该作用域下的所有元素都将带有其前缀。
with tf.name_scope('hidden1') as scope:
在定义的作用域中,每一层所使用的权重和偏差都在tf.Variable实例中生成,并且包含了各自期望的shape。
weights = tf.Variable(tf.truncated_normal([IMAGE_PIXELS, hidden1_units], stddev = 1.0 / math.sqrt(float(IMAGE_PIXELS))), name = 'weight')
biases = tf.Variable(tf.zero([hidden1_units]), name = 'biases')
例如,当这些层是在hidden1作用域下生成时,赋予权重变量的独特名称将会是'hidden1/weights'。
每个变量在构建时都会获得初始化操作,
在这种最常见的情况下,通过tf.truncated_normal 函数初始化权重变量,给赋予的shape 则是一个二维tensor,其中第一个维度代表该层中权重变量索连接的(connect from)单元数量,第二个维度表示该层中权重变量所连接到的(connect to)单元数量。对于名叫hidden1的第一层,相应的维度则是[IMAGE_PIXELS, hidden1_units],因为权重变量将图像输入连接到了hidden1层。tf.trubcated_normal初始函数将根据所得到的均值ヘ标准差,生成一个随机分布。
然后,通过tf.zero 函数初始化偏差变量(biases),确保所有偏差的起始值都是0,而它们的shape则是其在该层中所连接到的单元数量
凸包的三个操作,分别是两个tf.nn.relu操作,它们中嵌入了隐藏层书序的tf.matmul;以及logits模型所需的另外一个tf.matmul。三者一次生成,各自的tf.Variable 实例则与输入占位符或下一层的输出tensor所连接。
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases)logits = tf.matmul(hidden2, weights) + biases#最后一层没有加激励函数
最后程序会返回包含了输出结果的logits Tensor
Loss 损失
loss()函数通过添加所需的损失操作,进一步构建图表
首先,label_placeholder中的值,将被编码为一个含有1-hot values的Tensor。
batch_size = tf.size(labels)
labels = tf.expand_dims(labels, 1)
indices = tf.expand_dims(tf.range(0, batch_size, 1), 1)
concated = tf.concat(1, [indices, labels])
onehot_labels = tf.sparse_to_dense(
concated, tf.pack([batch_size, NUM_CLASSES]), 1.0, 0.0)之后,添加一个tf.nn.softmax_cross_entropy_with_logits操作,用来比较inference()函数ゆ1-hoot标签所输出的logits Tensor。
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits,
onehot_labels,
name='xentropy')然后使用rf.reduce_mean函数,计算batcch维度(第一维度)下交叉熵(cross entropy)的平均值,将该值作为总损失。
loss = tf.reduce_mean(cross_entropy, name='xentropy_mean')最后程序会返回包含了损失值的Tensor
以上是教程中说的计算Loss的方法,然而在实际文件中,Loss()函数非常简洁
def loss(logits, labels):
labels = tf.to_int64(labels)
return tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
训练
training()函数添加了通过梯度下降将损失最小化的操作
首先,该函数从loss()函数中获取损失Tensor,将其交个tf.scalar_summary , 后者在与SummartWriter配合使用时,会向实践文件(events file)中生成汇总值(summary values)。在本篇中,每次写入汇总值时,都会释放损失Tensor 的当前值。(这一步是为了可视化学习)
# Add a scalar summary for the snapshot loss.
tf.summary.scalar('loss', loss)
接下来我们实例化一个tf.train.GradientDescentOptimizer,负责按照所要求的学习效率(learning rate)应用梯度下降法
optimizer = tf.train.GradientDescentOptimizer(learning_rate)之后,我们生成一个变量用于保存全局训练步骤的数值,并使用 minimize()函数更新系统的三角权重、增加全局步骤的操作哦。根据惯例,这个操作被称为train_op,是TensorFlow会话(session)诱发一个完整训练步骤所必须运行的操作。
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)
(global_step 的意义是代表全局步数,类似于一个钟表,会随着迭代递增)
最后,程序返回包含了训练操作(training op)输出结果的Tensor。
训练模型
一旦图表构建完毕,就通过fully_connected_feed.py文件中的用户代码循环的迭代式训练与评估。
图表
在run_training)(这个函数的一开始,是一个Python的with命令,表示所有已经构建的操作都要与默认的tf.Graph全局实例关联起来。
with tf.Graph().as_default():
tf.Graph 实例是一系列可以作为整体执行的操作。TensorFlow的大部分场景只需要依赖默认图表一个实例即可。
利用多个图表的更加复杂的使用场景也是可能的,但是超出了本教程的范围。
会话
完成全部的构建准备、生成全部所需的操作之后,我们可以创建一个tf.Session,用于运行图表。最好用with语句生成,限制其作用域。
with tf.Session() as sess:Session函数没有传入参数,表明该代码将会依附于默认的本地会话(若没有,则会创建一个对话)。
生成对话后,所有格tf.Variable实例都会立即通过各自初始化操作中的sess.run()函数进行初始化
init = tf.initialize_all_variables()
sess.run(init)sess.run方法将会运行图表中ゆ作为参数传入的操作相对应的完整自己。在初次调用时,init操作只包含了变量初始化程序tf.group。图表的其他部分不会在这里,而是在下面的训练循环运行。
训练循环
完成会话中变量的初始化之后,就可以开始训练的了。
训练的每一步都是通过用户代码控制,而能实现有效训练的最简单循环就是
for step in xrange(max_steps):
sess.run(train_op)但是这里我们采用更复杂的方法,原因是我们必须把输入的数据根据每一步的情况进行切分,以匹配之前生成的占位符。这一步称之为提供反馈(feed)
向图表提供反馈
执行每一步时,我们的代码就会生成一个反馈字典(feed dictionary),其中包含对应步骤中训练所要使用的例子,这些例子的哈希值就是其所代表的占位符操作。
fill_feed_dict 函数会查询给定的Dataset,索要下一批次的batch_size的图像和标签,与占位符相匹配的Tenso则会包含下一批次的图像和标签。
images_feed, labels_feed = data_set.next_batch(FLAGS.batch_size)
然后,以占位符为哈希键(key),创建一个python字典对象,key值则是其代表的反馈tensor
feed_dict = {
images_placeholder: images_feed,
labels_placeholder: labels_feed,
}这个字典随后作为feed_dict参数,传入sess.run()函数中,为这一步的训练提供输入样例。
检查状态
在运行sess.run函数时,要在代码中明确其需要获取的两个值:[train_op, loss]。
for step in xrange(FLAGS.max_steps):
start_time = time.time()
feed_dict = fill_feed_dict(data_sets.train,
images_placeholder,
labels_placeholder)
_, loss_value = sess.run([train_op, loss],
feed_dict=feed_dict)
duration = time.time() - start_time
因为要获取这两个值,sess.run()会返回一个有两个元素的元组。其中每一个tensor对象,对应了返回 的元组中的numpy数组,而这些数组中包含了当前这不训练中对应的tensor的值由于train_op并不会产生输出,其在返回的元组中的对应元素就是None,所以会被抛弃。但是,如果模型在训练中出现偏差,loss tensor的值可能变为NaN,所以我们要获取它的值,并记录下来。
假设训练一切正常,没有出现NaN,训练循环会每隔100个训练步骤,就打印一行简单的状态文本,告知用户当前的训练状态。
if step % 100 == 0:
# Print status to stdout.
print('Step %d: loss = %.2f (%.3f sec)' % (step, loss_value, duration))
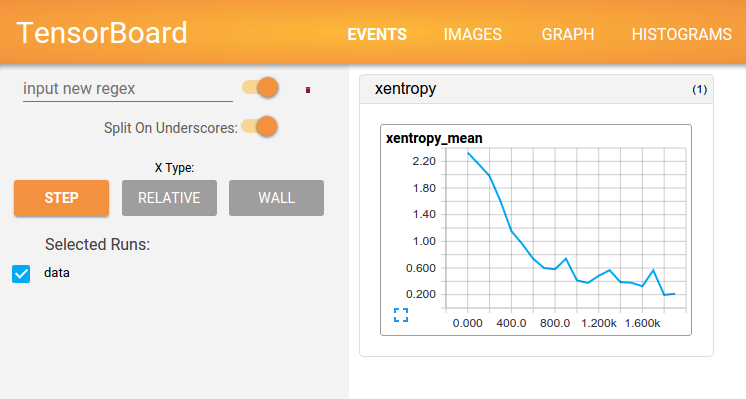
状态可视化
为了释放TensorBoard所使用的事件文件(events file),所有的即时数据(在这里只有一个)都要在图表构建阶段合并至一个操作(op)中。
summary = tf.summary.merge_all()
在创建好会话(session)之后,可以实例化一个
ummary_writer = tf.train.SummaryWriter(FLAGS.train_dir, graph_def=sess.graph_def)#这个是教程中的
summary_writer = tf.summary.FileWriter(FLAGS.log_dir, sess.graph)
最后,每次运行 summary_op 时,都会往事件文件中写入最新的即时数据,函数的输出会传入时间文件读写器(writer)的add_summary() 函数。。。
if step % 100 == 0:
# Print status to stdout.
print('Step %d: loss = %.2f (%.3f sec)' % (step, loss_value, duration))
# Update the events file.
summary_str = sess.run(summary, feed_dict=feed_dict)
summary_writer.add_summary(summary_str, step)
summary_writer.flush()
事件文件写入完毕之后,可以就训练文件夹打开一个TensorBoard,查看即时数据的情况。
保存检查点(checkpoint)
为了得到得到可以用来后续恢复模型以进一步训练或评估的检查点文件(checkpoint file),我们实例化一个tf.train.Saver。
saver = tf.train.Saver()
在训练循环中,将定期调用 saver.save() 方法,向训练文件中写入包含了当前所有可训练变量值得检查点文件。
saver.save(sess, checkpoint_file, global_step=step)
这样我们以后就可以使用saver.restore() 方法,重载模型的参数,继续训练。
saver.restore(sess, FLAGS.train_dir)评估模型
每隔一千个训练步骤,我们的代码会尝试使用训练数据集与测试数据集,对模型进行评估。do_eval 函数会被调用三次,分别使用训练集,验证集和测试集(do_eval是自己定义的函数)
print('Training Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.train)
# Evaluate against the validation set.
print('Validation Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.validation)
# Evaluate against the test set.
print('Test Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.test)
构建评估图表(Eval Graph)
在打开默认图表(Graph)之前,我们应该先调用get_datta(train=False),抓取测试数据集。
test_all_images, test_all_labels = get_data(train=False)#教程中的语句data_sets = input_data.read_data_sets(FLAGS.input_data_dir, FLAGS.fake_data)#源程序中的语句
在进入训练循环之前,我们应该先调用mnist.py文件中的evaluation函数,传入的logits和标签参数要与loss函数的一致。这样做是为了先构建Eval操作。
eval_correct = mnist.evaluation(logits, labels_placeholder)
mnist.py中该函数的描述如下:
def evaluation(logits, labels):
correct = tf.nn.in_top_k(logits, labels, 1)
return tf.reduce_sum(tf.cast(correct, tf.int32))
其中tf.nn.in_top_k 的函数的意思是如果在Kげ最有可能的预测中可以发现真的标签,这个操作就会ば模型输出标注为正确。这里把k 设为了1,表示只有在预测し真的标签时,才判定为正确的
评估图表的输出(Eval Output)
之后我们可以创建一个循环,往其中添加feed_dict, 并在调用sess.run()时传入 eval_correcct操作,目的就是用给定的数据集评估模型。
for step in xrange(steps_per_epoch):
feed_dict = fill_feed_dict(data_set,
images_placeholder,
labels_placeholder)
true_count += sess.run(eval_correct, feed_dict=feed_dict)
true_count 变量会累加所有的 in_top_k 操作判定为正确的预测值之和。接下来,只需要将正确测试的总数除以例子总数,就可以得出准确率了。
precision = float(true_count) / num_examples
print('Num examples: %d Num correct: %d Precision @ 1: %0.04f' %
(num_examples, true_count, precision))
(这部分代码在do_eval 定义函数里面)