一、简介
RDD(Resilient Distributed Datasets)弹性-分布式-数据集。
1、RDD是spark中最基本的抽象,它代表的是一个只读的不能被改变的被分区的数据集。在spark中存在很多的方法,这些方法都可以进行操作RDD,而这些方法就叫做算子。算子用来操作RDD的,算子的分类:转换类[transFormation]和行动类[action]。
2、特点
-
只读:一旦创建,不能被修改,因为RDD是一个抽象。
-
不可变:一旦创建,不能被修改,只能生成新的RDD.
-
弹性:可变大变小,默认优先使用内存,如果超大的话借助磁盘。
-
分布式:其实就是分区的概念,并行处理执行的,逻辑一样,但是数据不一样。
-
数据集:一系列数据放在集合中的表示。
-
高容错性:通过RDD中的血缘关系,也就是上一个RDD和下一个RDD之间通过算子的相互依赖关系。
-
分区:RDD肯定是分区的,不然不可能被多个Executor执行。每个Executor中的task任务对应的是一个分区中的数据。所以有多少个分区就有多少个task任务。所以RDD在创建的时候会被分区。
-
底层:RDD是一个抽象类,在抽象类中有很多的实现类。
二、创建方式
1、makeRDD-集合并行化
(1)集合并行化或者makeRDD产生的RDD是:ParallelCollectionRDD
[将集合转换为RDD的方式称为集合并行化的创建方式,用于测试]
(2)makeRDD: 【只要是集合都可以进行创建RDD】
val a=Array(1,2,3) sc.makeRDD(a) //or: sc.parallelize(a)

说明:makeRDD底层调用的就是parallelize(collection集合并行化)
2、读取外部文件形式
(1)读取外部文件产生的RDD是:MapPartitionsRDD
(2)textFile就是读取文件的--可读本地文件,同时也能读取hdfs文件。
sc.textFile("hdfs://1803-spark4:50070/in/word.txt")
(3)读取本地文件:做测试的时候偶尔可以使用,但是后期在处理数据的时候都是读取外部文件的形式。
sc.textFile("/home/data/a.txt")
3、使用转换类算子进行创建
(1)通过算子产生RDD,会产生各种类型的RDD
val rdd1: RDD[String] = sc.textFile(input) val rdd2 = rdd1.flatMap(a=>a.split(" ")) val rdd3 = rdd2.map(a=>(a,1)) val rdd4 = rdd3.reduceByKey(_+_)
(2)调用转换类算子会生成新的rdd,而调用行动类算子不会生成新的rdd,行动类算子只能是执行。
转换类算子: 一个RDD转换为另一个RDD,map、flatMap、groupBy、sortBy ....遇到行动类才触发程序执行
行动类算子: colleact、reduce、foreach.....
三、RDD分区
1、创建
(1)、集合并行化的方式创建分区: [默认根据cores数自动分区,可以手动设置分区数量]

总共4个cores,所以创建了4个分区,有多少cores创建多少个分区。Cpu有多少个cores,就证明这个集群能并行执行处理多少个任务,所以系统在创建RDD的时候做到了最大并行化。
问题:excutor总共有3个,每个excutor有4个cores,一个Executor可以并行处理4个分区中的数据,也就是可以同时执行4个task.
(2)、读取外部文件的形式创建分区:

读取外部文件的时候分区的数量是变化的。因为读取外部文件的时候分区的数量=文件的block数量【如果block的数量如果小于2,那么分区默认就是2,如果大于2那么就是具体的block的数量,有多少个block就有多少个分区,然后要给task任务处理一个分区中的任务】。
(3)、转换类算子产生的分区: [转换类算子产生的新的RDD,分区默认不改变]
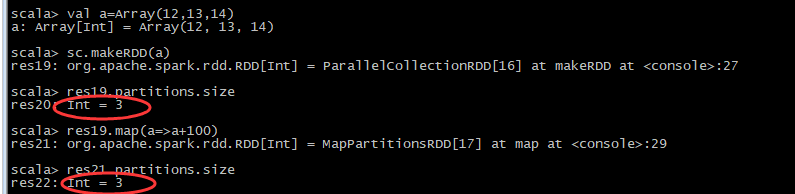
(4)总结:
-
1-通过集合并行化的形式:有多少个cores就会产生多少个分区;可以手动修改;
-
2-通过读取HDFS文件的形式产生分区,有多少个block块就会产生多少个分区。
-
3-调用转换类算子产生的分区,转换类算子产生新的RDD默认分区数量不变。
2、修改分区数量的方法
分区的数量决定了任务并行化处理任务的程度
(1)集合并行化创建RDD的时候可以手动的设置分区数量
(2)读取外部文件的形式,使用手动修改分区数量的方式失效。可以控制,但是不能完全控制读取HDFS文件数据的分区
(3)通过算子转换的RDD默认情况下分区数量不变,但是可以使用算子修改分区数量
sc.makeRDD(a,3) res0.reduceByKey(_+_,4)
3、总结
(1)一般情况下,不会手动设置分区数量。
(2)使用3个特殊的转换类算子。
使用reduceByKey groupByKey distinct 一般不常用
常用的改变分区的算子有:coalesce(合并) repartition(再分配)
四、总结
1、集合并行化;默认的分区数量是集群cores的总数
makeRDD(seq,numpartition)
parallelize(seq,numpartition)
2、读取hdfs文件,默认的分区数量是block块的数量,如果block的数量小于2,默认就是2
sc.textFile(“path”,numberPartitions),如果修改分区的时候,必须大于block,不一定设定多少就是多少,是自适配的。
3、RDD转换类算子生成新的RDD,默认情况下,分区数量不会发生改变,除了3个特殊的转换类算子。
简单来说,RDD的分区数量决定了任务并行化的程度,根据核数进行合适的分区。