selenium选择之Xpath
根据xpath语法查找,从/根节点开始找第一个
html=driver.find_element_by_xpath('/html') html=driver.find_element_by_xpath('/head')#报错,因为根部是从html开始的 print(html.tag_name)
//表示节点开始找任意一个节点
div = driver.find_element_by_xpath('//div') print(div.tag_name)
查找id为imagesdediv标签
div = driver.find_element_by_xpath('//div[@id="images"]') print(div.tag_name) print(div.text)
找到第一个a节点
a = driver.find_element_by_xpath('//a') print(a.tag_name)
找到所有a节点
a_s= driver.find_elements_by_xpath('//a')#注意这里用了elements print(a_s)
找到第一个a节点的href属性
#get_attribute:获取节点中某个属性 a = driver.find_element_by_xpath('//a').get_attribute('href') print(a)
完整代码为:
from selenium import webdriver import time driver=webdriver.Chrome() driver.maximize_window() try: #隐式等待,写在get请求之前###若为显示等待,写在get请求之后 driver.implicitly_wait(10) driver.get('https://doc.scrapy.org/en/latest/_static/selectors-sample1.html') #根据xpath语法查找 #从/根节点开始找第一个 html=driver.find_element_by_xpath('/html') html=driver.find_element_by_xpath('/head')#报错 print(html.tag_name) #//从根节点开始找任意一个节点 div = driver.find_element_by_xpath('//div') print(div.tag_name) #@ #查找id为imagesdediv标签 div = driver.find_element_by_xpath('//div[@id="images"]') print(div.tag_name) print(div.text) #找到第一个a节点 a = driver.find_element_by_xpath('//a') print(a.tag_name) #找到所有a节点 a_s= driver.find_elements_by_xpath('//a') print(a_s) #找到第一个a节点的href属性 #get_attribute:获取节点中某个属性 a = driver.find_element_by_xpath('//a').get_attribute('href') print(a) finally: driver.close()
实现自动打开三个网页,自动前进回退的过程
''' 前进、后退 ''' from selenium import webdriver import time driver = webdriver.Chrome() driver.maximize_window() try: driver.implicitly_wait(10) driver.get('https://www.jd.com/') driver.get('https://www.baidu.com/') driver.get('https://www.cnblogs.com/') time.sleep(2) # 回退操作 driver.back() time.sleep(1) # 前进操作 driver.forward() time.sleep(1) driver.back() time.sleep(10) finally: driver.close()
用selenium实现自动那个登录京东输入“围城”后自动清除再搜索“墨菲定律”的过程
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver=webdriver.Chrome() driver.maximize_window() try: driver.implicitly_wait(10) #往京东发送请求 driver.get('http://www.jd.com/') #找到输入框输入围城 input_tag=driver.find_element_by_id('key') input_tag.send_keys('围城') #键盘回车 input_tag.send_keys(Keys.ENTER) time.sleep(2) #找到输入框输入墨菲定律 input_tag=driver.find_element_by_id('key') input_tag.clear() input_tag.send_keys('墨菲定律') #找到搜索按钮点击搜索 button=driver.find_element_by_class_name('button') button.click() time.sleep(10) finally: driver.close()
选项卡之向一个网页发送百度请求后,新建一个选项卡,为其请求淘宝链接,返回第一个时又向新浪发送链接
''' 选项卡 ''' from selenium import webdriver from selenium.webdriver.common.keys import Keys import time browser=webdriver.Chrome() browser.maximize_window() try: browser.implicitly_wait(10) browser.get('http://www.baidu.com/') #execute_script:执行javascript代码 #弹窗操作 #browser.execute_script( 'alert("zmm")') #新建浏览器窗口 browser.execute_script( ''' window.open() ''') print(browser.window_handles)#获取所有选项卡 #切换到第二个窗口 #新的表示法 #browser.switch_to.window(browser.window_handles[1]) #旧的 browser.switch_to_window(browser.window_handles[1]) #网第二个窗口发送淘宝请求 browser.get("http://www.taobao.com/") time.sleep(5) #切换到第一个窗口 browser.switch_to_window(browser.window_handles[0]) browser.get("http://www.sina.com/") time.sleep(10) finally: browser.close()
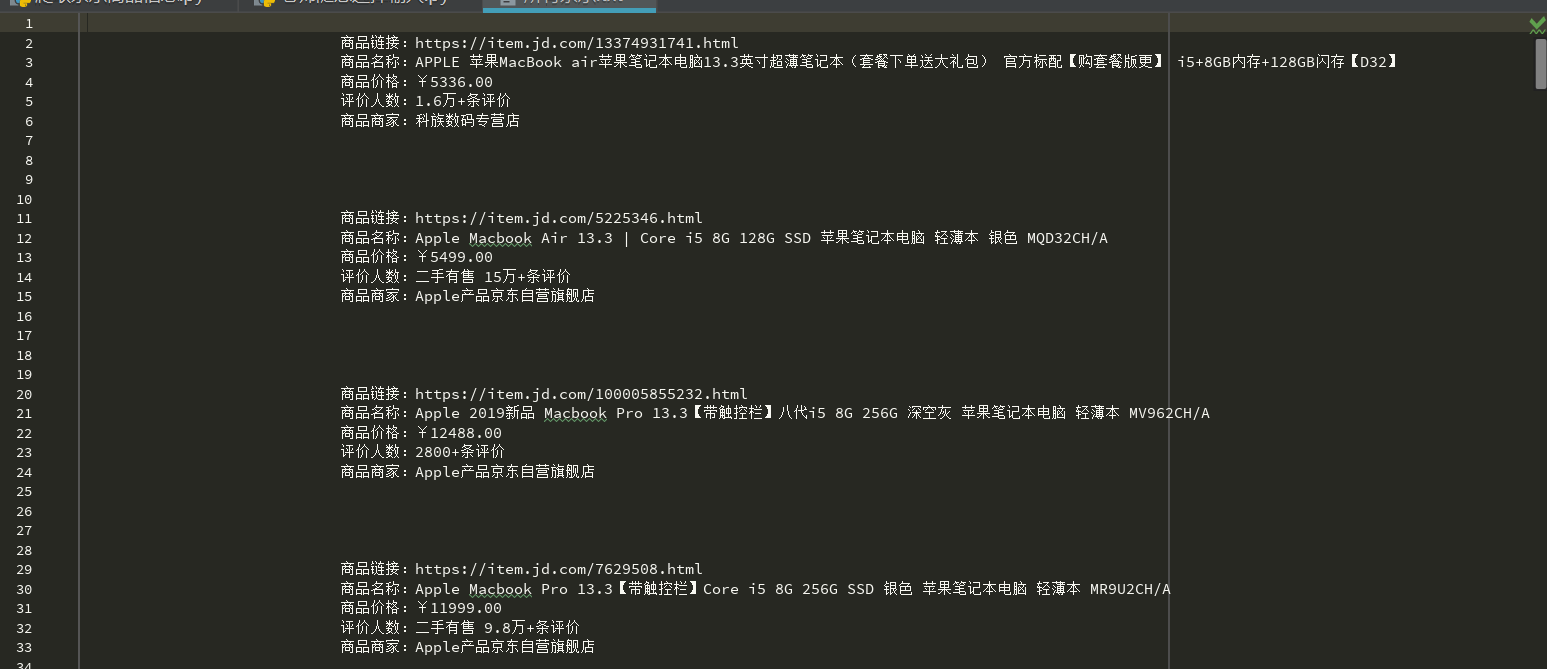
通过selenium爬取京东第一页macbook的代码:
''' 请求url: https://www.jd.com/ 提取商品信息 1、商品详情页 2、商品名称 3、商品价格 4、评鉴人数 5商品商家 ''' from selenium import webdriver import time from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome() driver.maximize_window() try: # 隐式等待,写在get请求之前###若为显示等待,写在get请求之后 driver.implicitly_wait(10) #1往京东主页发送请求 driver.get('https://www.jd.com/') #2、输入商品名称,并输入回车 input_tag=driver.find_element_by_id('key') input_tag.send_keys('macbook') input_tag.send_keys(Keys.ENTER) #3查找所商品div good_list=driver.find_elements_by_class_name('gl-item') for good in good_list: #根据属性选择器查找 #商品链接 good_url=good.find_element_by_css_selector('.p-img a').get_attribute('href') #商品名称 good_name=good.find_element_by_css_selector('.p-name em').text.replace(" ","--") #商品价格 good_price=good.find_element_by_class_name('p-price').text.replace(" ",":") #评价人数 good_commit=good.find_element_by_class_name('p-commit').text.replace(" "," ") #尚品尚家 good_from = good.find_element_by_class_name('J_im_icon').text.replace(" ", " ") good_content=f''' 商品链接:{good_url} 商品名称:{good_name} 商品价格:{good_price} 评价人数:{good_commit} 商品商家:{good_from} ''' print(good_content) with open('jd.txt','a',encoding='utf-8') as f: f.write(good_content) time.sleep(10) finally: driver.close()
增加滚轮模块和爬取京东所有内容的代码:
''' 爬取京东商品信息: 请求url: https://www.jd.com/ 提取商品信息: 1.商品详情页 2.商品名称 3.商品价格 4.评价人数 5.商品商家 ''' from selenium import webdriver from selenium.webdriver.common.keys import Keys import time def get_good(driver): try: # 通过JS控制滚轮滑动获取所有商品信息 js_code = ''' window.scrollTo(0,5000); ''' driver.execute_script(js_code) # 执行js代码 # 等待数据加载 time.sleep(2) # 3、查找所有商品div # good_div = driver.find_element_by_id('J_goodsList') good_list = driver.find_elements_by_class_name('gl-item') n = 1 for good in good_list: # 根据属性选择器查找 # 商品链接 good_url = good.find_element_by_css_selector( '.p-img a').get_attribute('href') # 商品名称 good_name = good.find_element_by_css_selector( '.p-name em').text.replace(" ", "--") # 商品价格 good_price = good.find_element_by_class_name( 'p-price').text.replace(" ", ":") # 评价人数 good_commit = good.find_element_by_class_name( 'p-commit').text.replace(" ", " ") good_content = f''' 商品链接: {good_url} 商品名称: {good_name} 商品价格: {good_price} 评价人数: {good_commit} ''' print(good_content) with open('jd.txt', 'a', encoding='utf-8') as f: f.write(good_content) next_tag = driver.find_element_by_class_name('pn-next') next_tag.click() time.sleep(2) # 递归调用函数 get_good(driver) time.sleep(10) finally: driver.close() if __name__ == '__main__': good_name = input('请输入爬取商品信息:').strip() driver = webdriver.Chrome() driver.implicitly_wait(10) # 1、往京东主页发送请求 driver.get('https://www.jd.com/') # 2、输入商品名称,并回车搜索 input_tag = driver.find_element_by_id('key') input_tag.send_keys(good_name) input_tag.send_keys(Keys.ENTER) time.sleep(2) get_good(driver)
通过今天的学习,又学到新的lenium模块,学习新的知识痛并快乐着,期待下次课程的学习。