其实对一些基本的概念都没有弄清楚,这里从网上找一些来普及下
一、结构化数据与非结构化数据
结构化数据就是能变成二维的行数据,主要应用在关系型数据库中。
非结构化数据是不可以变的,例如视频,音频文件,没有办法变成二维的行数据。所以一般不能用简单的关系型数据库存储,所以就引入了别的存储方式。
相对于结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)而言,不方便用数据库二维逻辑表来表现的数据即称为非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
字段可根据需要扩充,即字段数目不定,可称为半结构化数据,例如Exchange存储的数据。
非结构化数据库
在信息社会,信息可以划分为两大类。一类信息能够用数据或统一的结构加以表示,我们称之为结构化数据,如数字、符号;而另一类信息无法用数字或统一的结构表示,如文本、图像、声音、网页等,我们称之为非结构化数据。结构化数据属于非结构化数据,是非结构化数据的特例。
随着网络技术的发展,特别是Internet和Intranet技术的飞快发展,使得非结构化数据的数量日趋增大。这时,主要用于管理结构化数据的关
系数据库的局限性暴露地越来越明显。因而,数据库技术相应地进入了“后关系数据库时代”,发展进入基于网络应用的非结构化数据库时代。所谓非结构化数据
库,是指数据库的变长纪录由若干不可重复和可重复的字段组成,而每个字段又可由若干不可重复和可重复的子字段组成。简单地说,非结构化数据库就是字段可变的数据库。
数据清洗从名字上也看的出就是把“脏”的“洗掉”。因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗.而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。
(1)不完整的数据
这一类数据主要是一些应该有的信息缺失,如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,要求在规定的时间内补全。补全后才写入数据仓库。
(2)错误的数据
这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
(3)重复的数据
对于这一类数据——特别是维表中会出现这种情况——将重复数据记录的所有字段导出来,让客户确认并整理。
数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。对于是否过滤,是否修正一般要求客户确认,对于过滤掉的数据,写入Excel文件或者将过滤数据写入数据表,在ETL开发的初期可以每天向业务单位发送过滤数据的邮件,促使他们尽快地修正错误,同时也可以做为将来验证数据的依据。数据清洗需要注意的是不要将有用的数据过滤掉,对于每个过滤规则认真进行验证,并要用户确认。
二、现有存储的类型
三种存储类型比较-文件、块、对象存储 ,转发:http://limu713.blog.163.com/blog/static/15086904201222024847744/
块存储和文件存储是我们比较熟悉的两种主流的存储类型,而对象存储(Object-based Storage)是一种新的网络存储架构,基于对象存储技术的设备就是对象存储设备(Object-based Storage Device)简称OSD。
首先,我们介绍这两种传统的存储类型。通常来讲,所有磁盘阵列都是基于Block块的模式,而所有的NAS产品都是文件级存储。
1、块存储
以下列出的两种存储方式都是块存储类型:
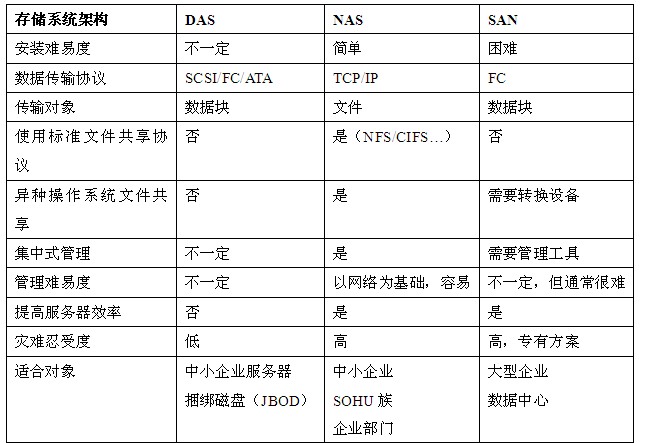
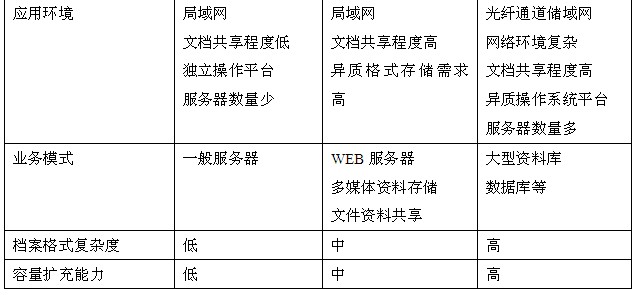
1) DAS(Direct Attach STorage):是直接连接于主机服务器的 一种储存方式,每一台主机服务器有独立的储存设备,每台主机服务器的储存设备无法互通,需要跨主机存取资料时,必须经过相对复杂的设定,若主机服务器分属 不同的操作系统,要存取彼此的资料,更是复杂,有些系统甚至不能存取。通常用在单一网络环境下且数据交换量不大,性能要求不高的环境下,可以说是一种应用 较为早的技术实现。
2)SAN(Storage Area Network):是一种用高速(光纤)网络联接专业主机服务器的一种储存方式,此系统会位于主机群的后端,它使用高速I/O 联结方式, 如 SCSI, ESCON 及 Fibre- Channels。一般而言,SAN应用在对网络速度要求高、对数据的可靠性和安全性要求高、对数据共享的性能要求高的应用环境中,特点是代价高,性能 好。例如电信、银行的大数据量关键应用。它采用SCSI 块I/O的命令集,通过在磁盘或FC(Fiber Channel)级的数据访问提供高性能的随机I/O和数据吞吐率,它具有高带宽、低延迟的优势,在高性能计算中占有一席之地,但是由于SAN系统的价格 较高,且可扩展性较差,已不能满足成千上万个CPU规模的系统。
2、文件存储
通常,NAS产品都是文件级存储。 NAS(Network Attached Storage):是一套网络储存设备,通常是直接连在网络上并提供资料存取服务,一套 NAS 储存设备就如同一个提供数据文件服务的系统,特点是性价比高。例如教育、政府、企业等数据存储应用。
它采用NFS或CIFS命令集访问数据,以文件为传输协议,通过TCP/IP实现网络化存储,可扩展性好、价格便宜、用户易管理,如目前在集群计算中应用较多的NFS文件系统,但由于NAS的协议开销高、带宽低、延迟大,不利于在高性能集群中应用。
下面,我们对DAS、NAS、SAN三种技术进行比较和分析:
表格 1 三种技术的比较
针对Linux集群对存储系统高性能和数据共享的需求,国际上已开始研究全新的存储架构和新型文件系统,希望能有效结合SAN和NAS系统的优点,支持直 接访问磁盘以提高性能,通过共享的文件和元数据以简化管理,目前对象存储系统已成为Linux集群系统高性能存储系统的研究热点,如Panasas公司的 Object Base Storage Cluster System系统和Cluster File Systems公司的Lustre等。下面将详细介绍对象存储系统。
3、对象存储
总体上来讲,对象存储同兼具SAN高速直接访问磁盘特点及NAS的分布式共享特点。
核心是将数据通路(数据读或写)和控制通路(元数据)分离,并且基于对象存储设备(Object-based Storage Device,OSD)构建存储系统,每个对象存储设备具有一定的智能,能够自动管理其上的数据分布。
对象存储结构组成部分(对象、对象存储设备、元数据服务器、对象存储系统的客户端):
3.1、对象
对
象是系统中数据存储的基本单位,一个对象实际上就是文件的数据和一组属性信息(Meta
Data)的组合,这些属性信息可以定义基于文件的RAID参数、数据分布和服务质量等,而传统的存储系统中用文件或块作为基本的存储单位,在块存储系统
中还需要始终追踪系统中每个块的属性,对象通过与存储系统通信维护自己的属性。在存储设备中,所有对象都有一个对象标识,通过对象标识OSD命令访问该对
象。通常有多种类型的对象,存储设备上的根对象标识存储设备和该设备的各种属性,组对象是存储设备上共享资源管理策略的对象集合等。
3.2、对象存储设备
对象存储设备具有一定的智能,它有自己的CPU、内存、网络和磁盘系统,OSD同块设备的不同不在于存储介质,而在于两者提供的访问接口。OSD的主要功能包括数据存储和安全访问。目前国际上通常采用刀片式结构实现对象存储设备。OSD提供三个主要功能:
(1) 数据存储。OSD管理对象数据,并将它们放置在标准的磁盘系统上,OSD不提供块接口访问方式,Client请求数据时用对象ID、偏移进行数据读写。
(2) 智能分布。OSD用其自身的CPU和内存优化数据分布,并支持数据的预取。由于OSD可以智能地支持对象的预取,从而可以优化磁盘的性能。
(3)
每个对象元数据的管理。OSD管理存储在其上对象的元数据,该元数据与传统的inode元数据相似,通常包括对象的数据块和对象的长度。而在传统的NAS
系统中,这些元数据是由文件服务器维护的,对象存储架构将系统中主要的元数据管理工作由OSD来完成,降低了Client的开销。
3.3、元数据服务器(Metadata Server,MDS)
MDS控制Client与OSD对象的交互,主要提供以下几个功能:
(1) 对象存储访问。
MDS构造、管理描述每个文件分布的视图,允许Client直接访问对象。MDS为Client提供访问该文件所含对象的能力,OSD在接收到每个请求时将先验证该能力,然后才可以访问。
(2) 文件和目录访问管理。
MDS在存储系统上构建一个文件结构,包括限额控制、目录和文件的创建和删除、访问控制等。
(3) Client Cache一致性。
为了提高Client性能,在对象存储系统设计时通常支持Client方的Cache。由于引入Client方的Cache,带来了Cache一致性问
题,MDS支持基于Client的文件Cache,当Cache的文件发生改变时,将通知Client刷新Cache,从而防止Cache不一致引发的问
题。
3.4、对象存储系统的客户端Client
为了有效支持Client支持访问OSD上的对象,需要在计算节点实现对象存储系统的Client,通常提供POSIX文件系统接口,允许应用程序像执行标准的文件系统操作一样。
4、GlusterFS 和对象存储
GlusterFS是目前做得最好的分布式存储系统系统之一,而且已经开始商业化运行。但是,目前GlusterFS3.2.5版本还不支持对象存储。如 果要实现海量存储,那么GlusterFS需要用对象存储。值得高兴的是,GlusterFS最近宣布要支持对象存储。它使用openstack的对象存 储系统swift的上层PUT、GET等接口,支持对象存储。