1.前言
本小结属于怎样判断innodb内部怎样加锁的,数据innodb的核心篇,也是非常重要的一节
2.加锁的规则
两个原则、两个优化、一个bug --->这里的默认隔离级别是:可重复读隔离级别
- 原则1:加锁的基本单位是next-key-lock,是前开后闭区间
- 原则2: 查找过程中访问到的对象才会加锁
- 优化1: 索引上的等值查询,给唯一索引加锁的时候,next-key-lock退化为行锁。
- 优化2: 索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁。
- 一个bug: 唯一索引上的范围查询会访问到不满足条件的第一个值为止。
3.案例
这里先创建一个表
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
案例一:等值查询间隙锁

分析:
由于id=7用的是唯一索引(主键索引),且id=7是在id=5和id=10之间,因此根据原则1,加锁规则是next-key lock,索引加锁的区间是(5,10];
然后再根据优化2:索引上进行等值查询时,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁,因此此时索引加锁区间是(5,10)
案例二:非唯一索引等值锁
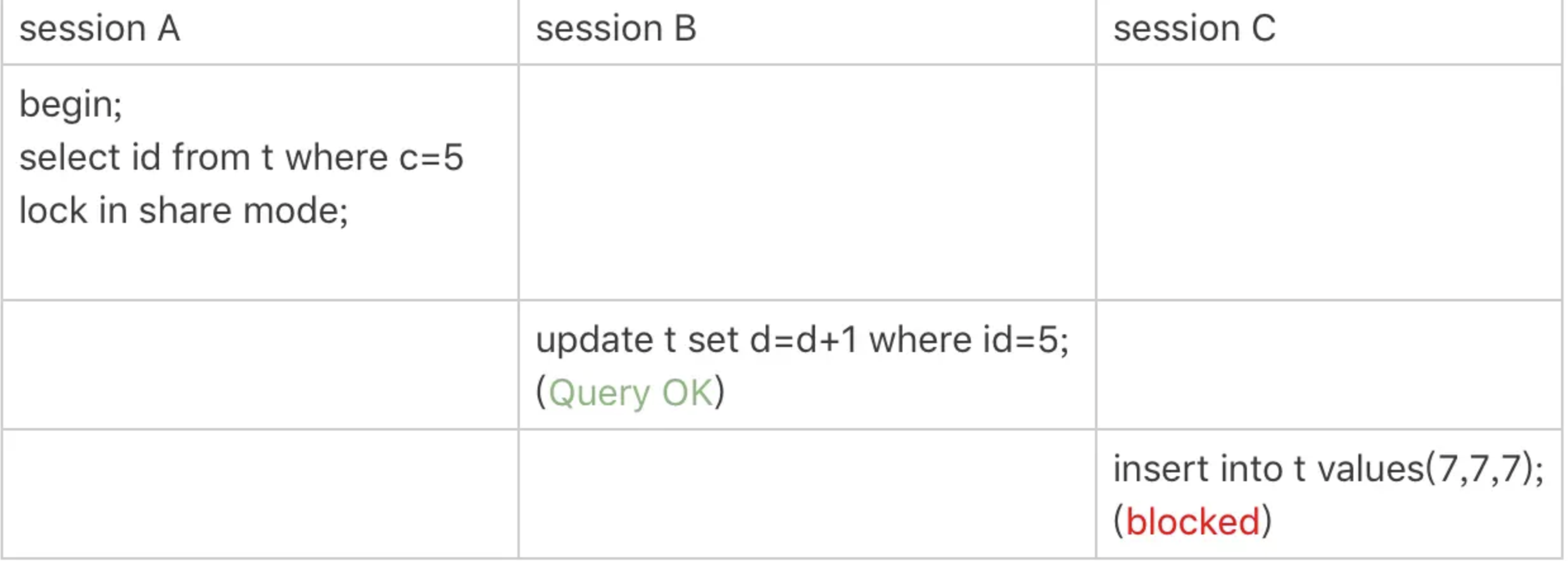
分析:
1.此时看到c是普通索引
2.根据原则1:加锁的单位是next-key lock,因此此时加锁区间是(0,5],又因此c是普通索引,所以还需要向右遍历,查到c=10才放弃。因此根据原则2,访问到的都要加锁,因此需要给(5,10]
加上next-key lock
3.但是同时这个符合优化 2:等值判断,向右遍历,最后一个值不满足 c=5 这个等值条件,因此退化成间隙锁 (5,10),因此最终的加锁区间是(0,5]和(5,10)
案例三:主键索引范围锁
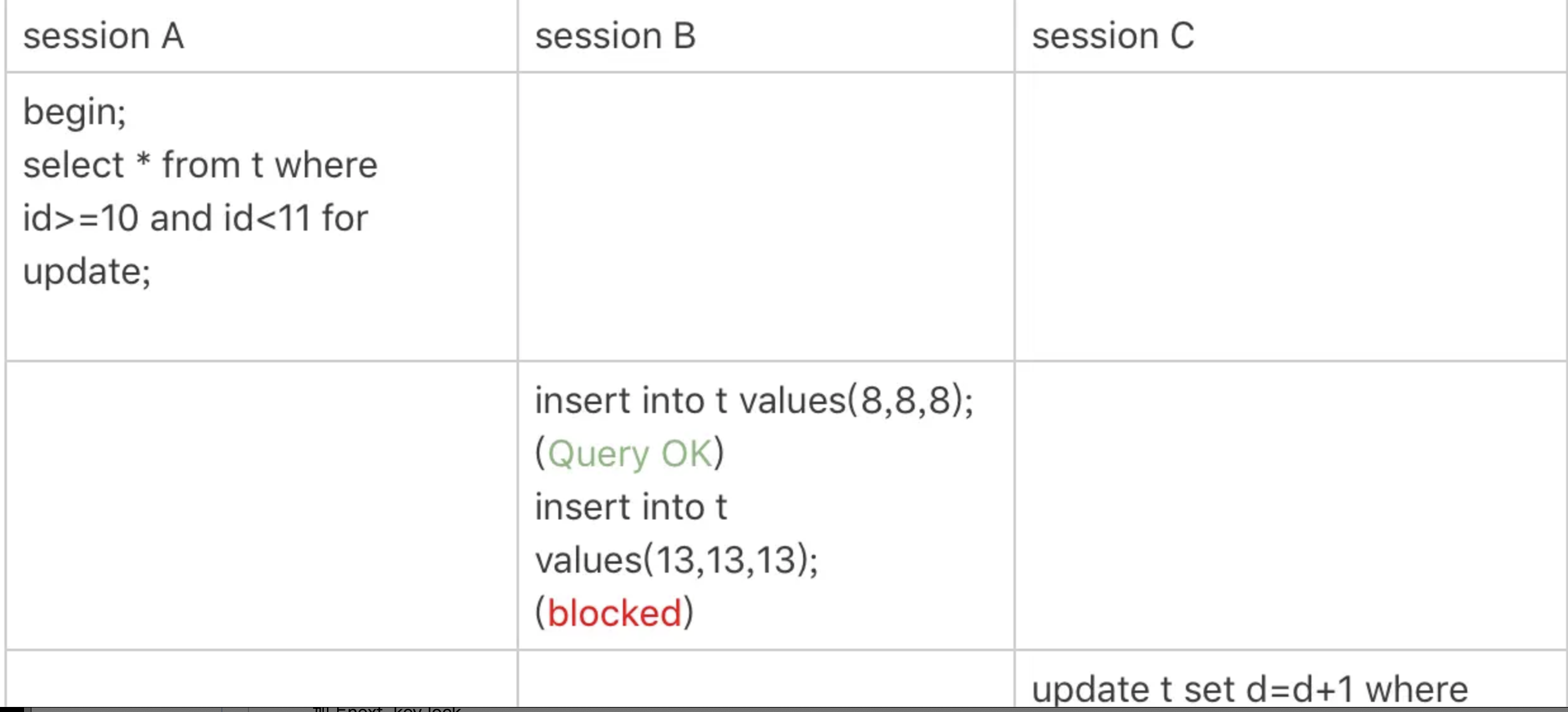
分析:
1.开始执行的时候,要找到第一个id=10的行,因此本该是next-key lock(5,10].根据优化1,主键id上的等值条件,退化为行锁,只加了id=10这一行的行锁。
2.范围查找就往后继续找,找到id=15这一行停下来,因此需要加next-key lock(10,15].
所以,session A这时候锁的范围就是主键索引上,行锁id=10和next-key lock(10,15].这样session B和session C的结果你就能理解了。
案例四:非唯一索引范围锁
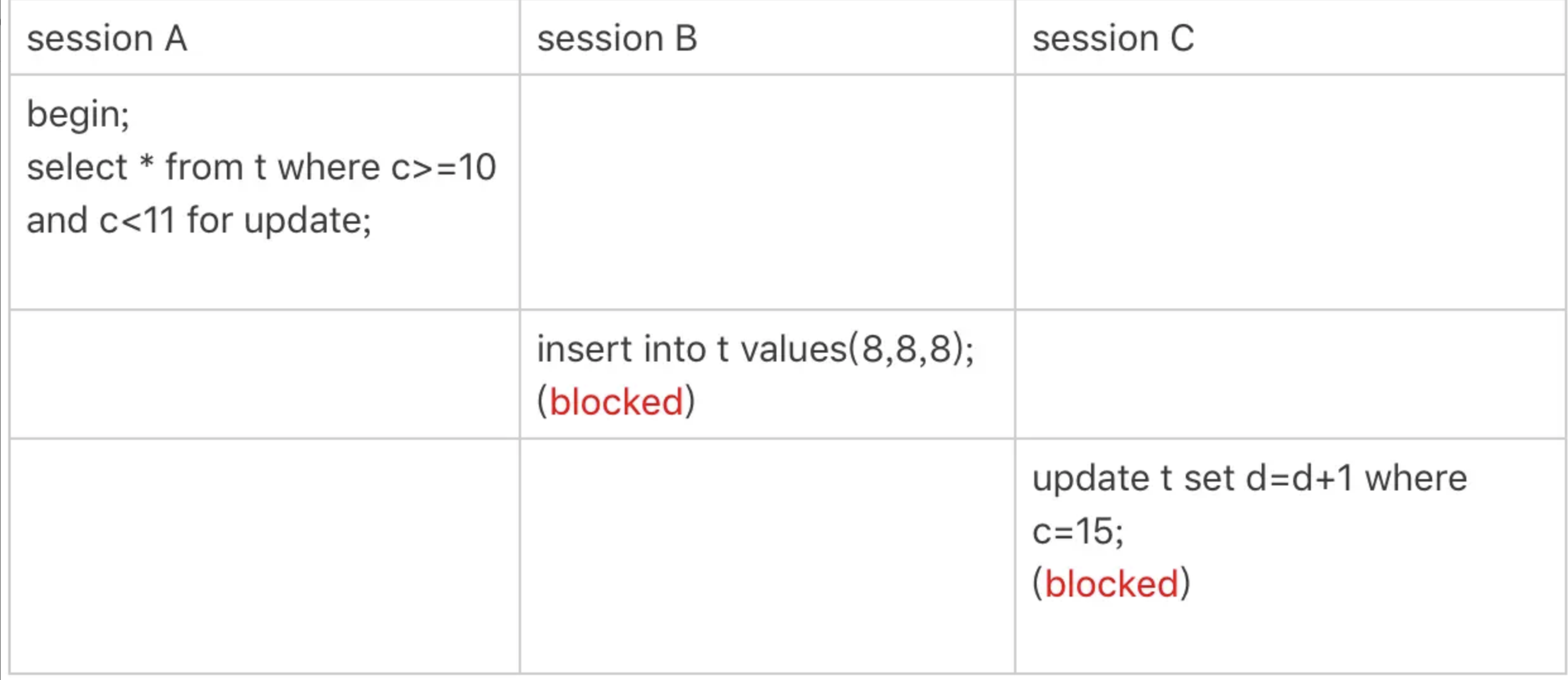
分析:
1.注意此时的约束条件时c字段
2.这次session A用字段c来判断,加锁规则跟案例三唯一不同的是:在第一次用c=10定位记录的时候,索引c上加了(5,10]这个next-key lock之后,由于索引c是非唯一索引,没有优化规则,也就是说不会蜕变为行锁,因此最终session A加的锁是,索引c上的(5,10]和(10,15]这两个next-key lock.
所以从结果上来看,session B要插入(8,8,8)的这个insert 语句时就被堵住了。
这里需要扫描到c=15才停止扫描,是合理的,因为innodb要扫到c=15,才知道不需要继续往后找了。