1.哨兵?
哨兵(sentinel)是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障是通过投票机制选择新的master并将所有slave连接到新的master。
2.哨兵的作用?
- 监控
- 不断的检查master和slave是否正常运行
- master存活检测、master与slave运行情况检测
- 通知(提醒)
- 当被监控的服务出现问题时,向其他(哨兵间、客户端)发送通知
- 自动故障转移
- 断开master与slave连接,选取一个slave作为master,将其他slave连接到新的master,并告知客户端新的服务器地址。
注意:
1.哨兵也是一台redis服务器,只是不提供数据服务
2.通常哨兵配置数量为单数
配置哨兵:
◆ 首先哨兵的配置文件(sentinel.conf)是下载的安装包经过编译安装(make install)后出现的------>意思是我们必须先要下载redis安装包然后在安装它之后在进行配置
◆ 注意:一般的我们的哨兵服务器和redis服务是不会放到同一台物理机上
基本配置:vi sentinel.conf (这个文件最好也拷贝到/data/26379目录下) 这里我们是一个哨兵对应一个目录/data/{26379,26380,26381}/sentinel.conf
port 26379 dir /data/26379 ####哨兵sentinel的工作目录 sentinel monitor mymaster 127.0.0.1 6379 2 #### 这行的意思是当有2个哨兵服务器认为master失联,那么这时客观上就认为主节点失联了。这里的按照所有的(哨兵节点/2)+1的个数来判断 sentinel down-after-milliseconds mymaster 30000 #### 指定多少毫秒之后,主节点没有应答哨兵sentinel 此时,哨兵主观上认为主节点下线,默认是30秒 sentinel parallel-syncs mymaster 1 #### 这个配置是指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行同步,如果这个数字越小,完成failover时间就越长,
如果这个数字越大,对物理机的CPU、内存资源消耗的就越大。
sentinel failover-timeout mymaster 180000 ###故障转移的超时时间(1:同一个sentinel对同一个master两次failover之间的间隔时间。
2:当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确master那里同步数据时。
3:当先要取消一个正在进行的failover所需要的时间,
4:当进行failover时,配置所有slave指向新的master所需要的最大时间。不过,即使过了这个超时,slaves依然被正确配置为执向master,但是就不按parallel-syncs所配置的规则)
以上配置就可以正常的启动哨兵
实例:
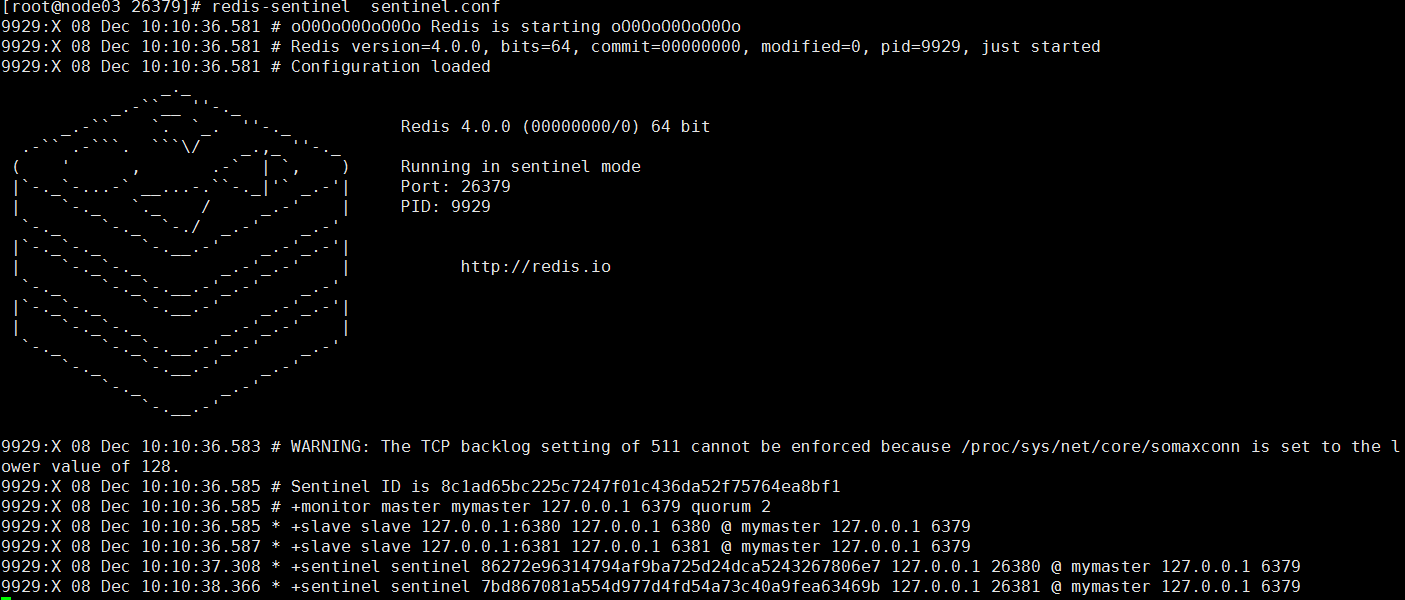
sentinel管理命令
Sentinel管理命令: redis-cli -p 26380 PING :返回 PONG 。 SENTINEL masters :列出所有被监视的主服务器 SENTINEL slaves <master name> SENTINEL get-master-addr-by-name <master name> : 返回给定名字的主服务器的 IP 地址和端口号。 SENTINEL reset <pattern> : 重置所有名字和给定模式 pattern 相匹配的主服务器。 SENTINEL failover <master name> : 当主服务器失效时, 在不询问其他 Sentinel 意见的情况下, 强制开始一次自动故障迁移。
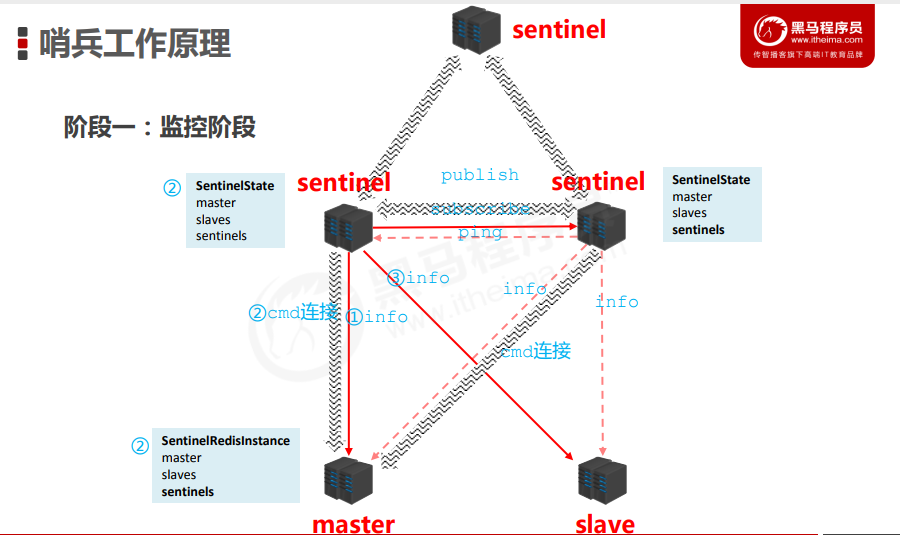
3.哨兵工作原理
阶段一:
用于同步各个节点的状态信息
-
- 获取各个sentinel的状态信息
- 获取master的状态信息
- master属性
- runid
- role:master
- 各个slave的详细信息
- master属性
- 获取slave的状态(根据master中的slave信息)
- slave属性
- runid
- role:slave
- master_host、master_port
- offset
- ..........
- slave属性
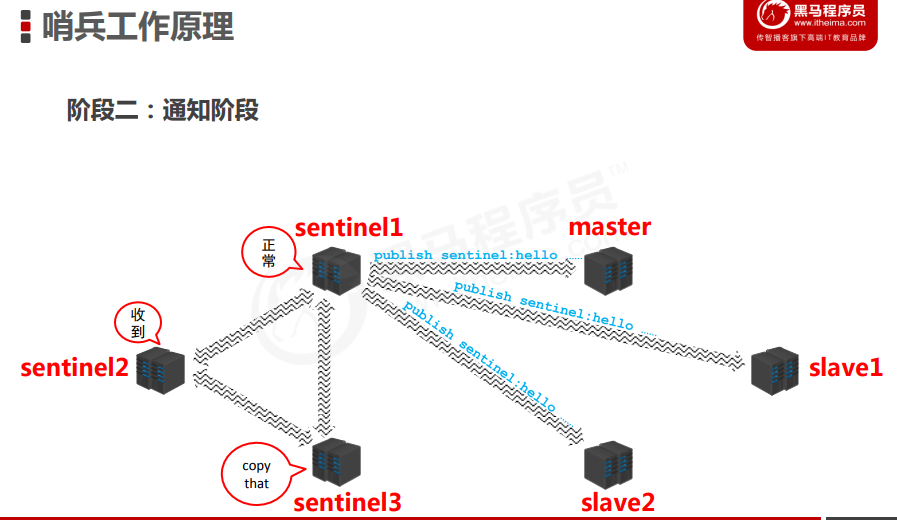
阶段二:通知阶段
阶段三:故障转移阶段

故障转移阶段:
- 服务器列表中挑选备选master
- 在线的
- 响应慢的
- 与原master断开时间久的
- 优先原则
- 优先级
- offset
- runid
- 发送指令(sentinel)
- 向新的master发送salveof no one
- 向其他slave发送slaveof新masterIP端口
工作流程:
发现问题--->竞选负责人---->优选新的master------->新master上任,其它slave切换master,原master作为slave故障恢复后连接