
一、前言
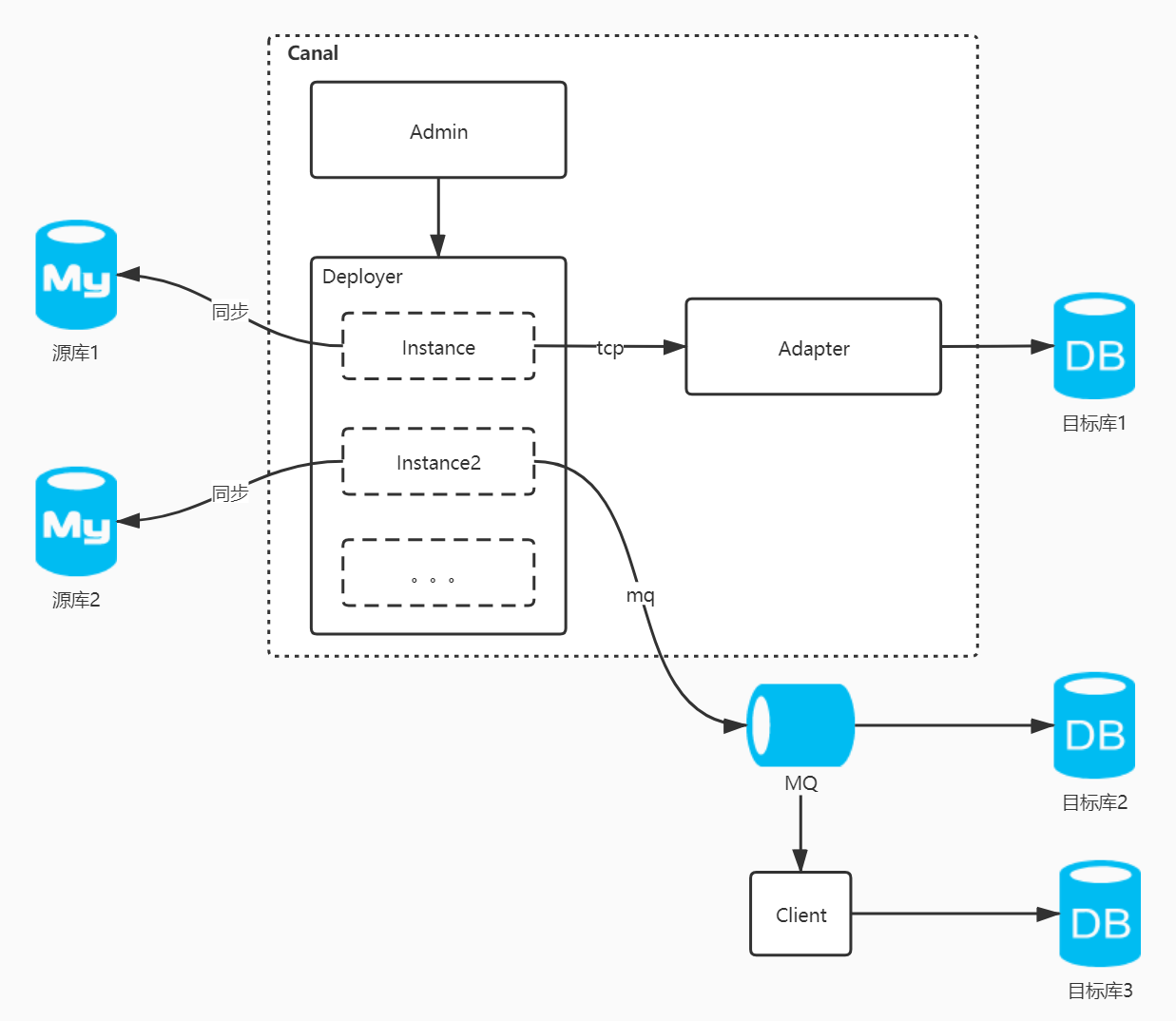
canal 是阿里的一款开源项目,纯 Java 开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了 MySQL(也支持 mariaDB)。

- canal 模拟 mysql slave 的交互协议,伪装自己为 mysql slave,向 mysql master发送 dump 协议;
- mysql master 收到 dump 请求,开始推送binary log给 slave(也就是canal)
- canal 解析 binary log对象(原始为byte流)。
总体架构:
二、部署准备
下载地址:
https://github.com/alibaba/canal/releases
分别下载:canal.admin、canal.deployer、canal.adapter
PS:只有1.1.5以上版本才支持es7.x
其他依赖:
- JDK1.8
- MySQL:用于canal-admin存储配置和节点等相关数据
- Zookeeper
三、HA机制
整个 HA 机制的控制主要是依赖了zookeeper的两个特性:watcher、EPHEMERAL节点。canal的 HA 机制实现分为两部分,canal server 和 canal client分别有对应的实现。
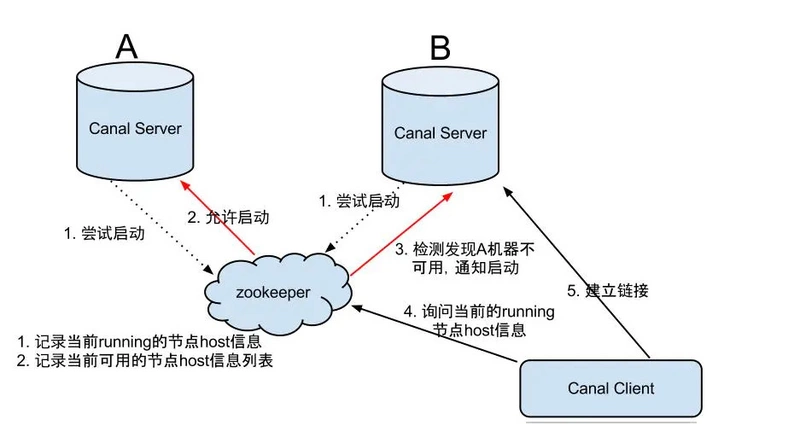
canal server实现流程如下:
- canal server 要启动某个 canal instance 时都先向 zookeeper 进行一次尝试启动判断 (实现:创建 EPHEMERAL 节点,谁创建成功就允许谁启动);
- 创建 zookeeper 节点成功后,对应的 canal server 就启动对应的 canal instance,没有创建成功的 canal instance 就会处于 standby 状态;
- 一旦 zookeeper 发现 canal server A 创建的节点消失后,立即通知其他的 canal server 再次进行步骤1的操作,重新选出一个 canal server 启动instance;
- canal client 每次进行connect时,会首先向 zookeeper 询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect。
PS: 为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态。
canal client实现流程
- canal client 的方式和 canal server 方式类似,也是利用 zookeeper 的抢占EPHEMERAL 节点的方式进行控制
- 为了保证有序性,一份 instance 同一时间只能由一个 canal client 进行get/ack/rollback操作,否则客户端接收无法保证有序。
四、集群部署
4.1. MySQL准备
4.1.1. 开启binlog
MySQL的 my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
注意:如果订阅的是mysql的从库,需求增加配置让从库日志也写到binlog里面
log_slave_updates=1
可以通过在 mysql 终端中执行以下命令判断配置是否生效:
show variables like 'log_bin';
show variables like 'binlog_format';
4.1.2. 授权账号权限
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant:
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
4.2. 部署canal-admin
4.2.1. 作用
- 通过图形化界面管理配置参数。
- 动态启停
Server和Instance - 查看日志信息
4.2.2. 执行数据库脚本
执行 conf 目录下载的 canal_manager.sql 脚步,初始化所需的库表。
初始化SQL脚本里会默认创建canal_manager的数据库,建议使用root等有超级权限的账号进行初始化
4.2.3. 配置修改
执行 vim conf/application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 127.0.0.1:3306
database: canal_manager
username: canal
password: canal
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
修改
address、database、username、password四个参数
4.2.4. 启停命令
启动
sh bin/startup.sh
停止
sh bin/stop.sh
4.2.5. 使用
通过 http://127.0.0.1:8089/ 访问,默认密码:admin/123456
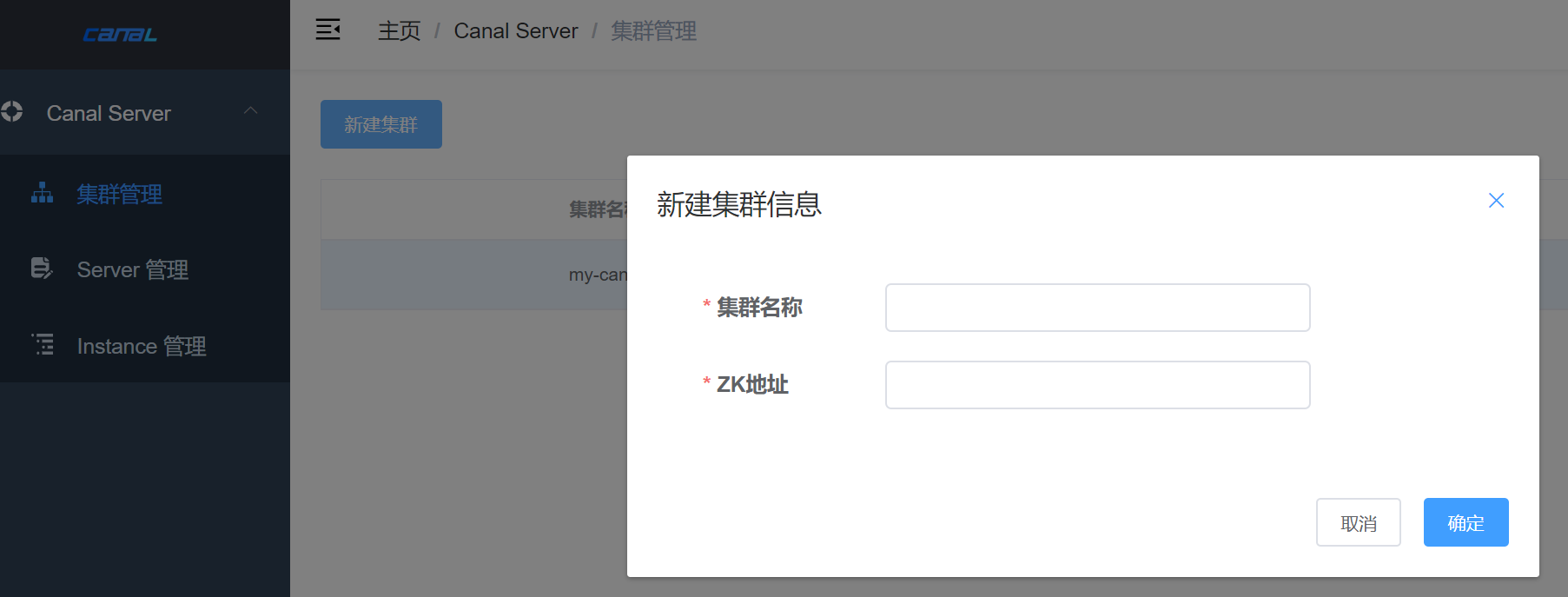
4.2.5.1. 创建集群
配置 集群名称 与 ZK地址
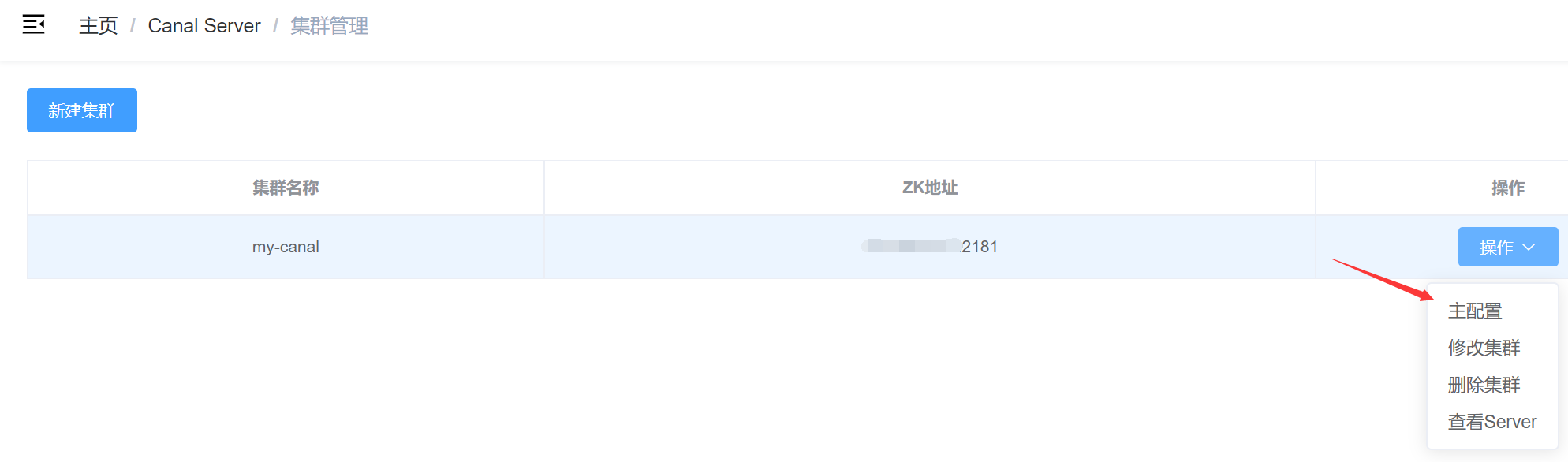
配置 主配置,该配置为集群内的所有Server实例共享的
主要修改以下配置:
- canal.zkServers 配置zookeeper集群地址
- canal.instance.global.spring.xml 改为classpath:spring/default-instance.xml
4.2.5.2. 创建Server
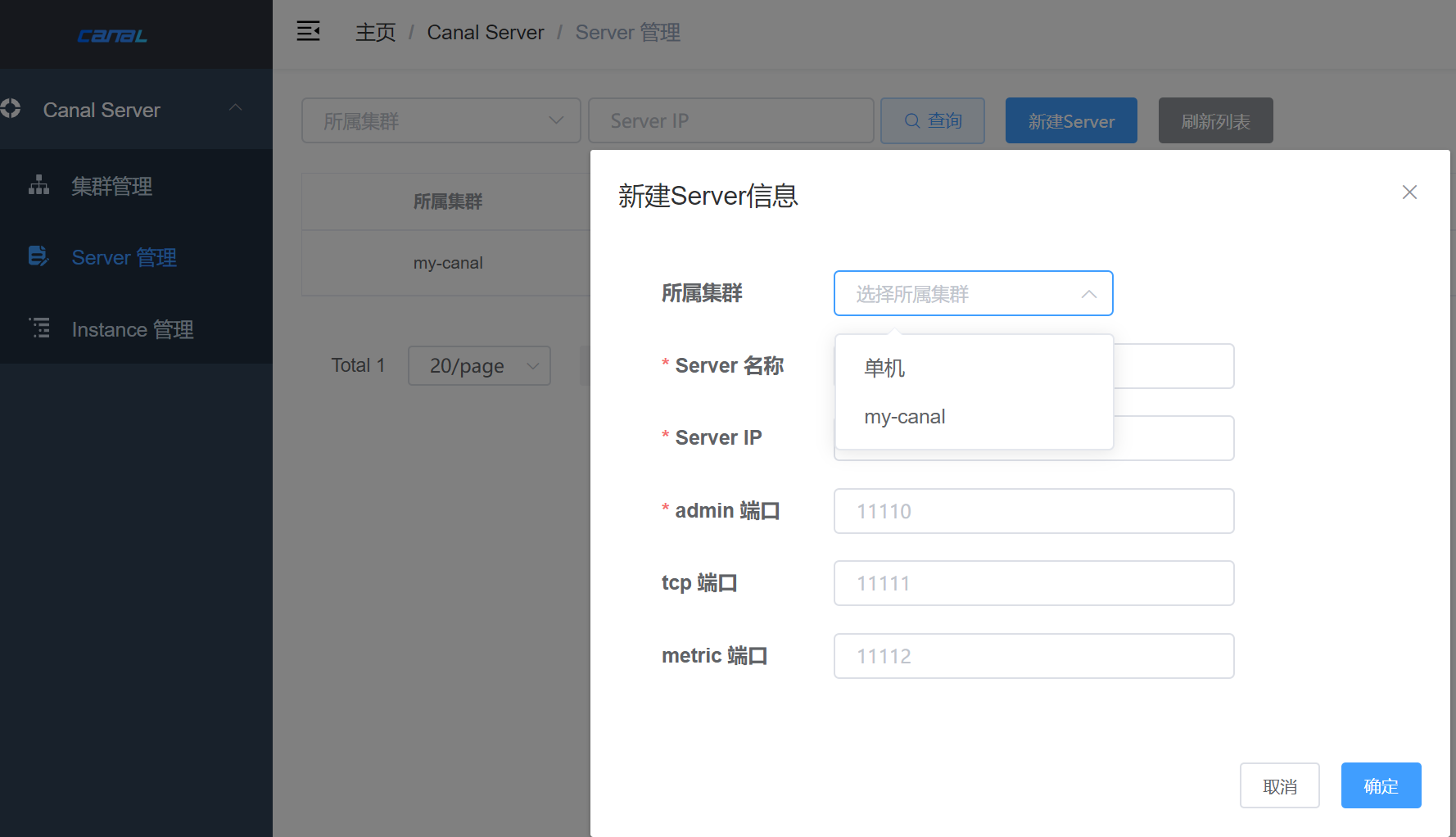
配置项:
- 所属集群,可以选择为单机 或者 集群。一般单机Server的模式主要用于一次性的任务或者测试任务
- Server名称,唯一即可,方便自己记忆
- Server Ip,机器ip
- admin端口,canal 1.1.4版本新增的能力,会在canal-server上提供远程管理操作,默认值11110
- tcp端口,canal提供netty数据订阅服务的端口
- metric端口, promethues的exporter监控数据端口 (未来会对接监控)
多台Server关联同一个集群即可形成主备HA架构
4.2.5.3. 创建Instance
每个 Instance 关联一个同步的数据源,如果有多个数据源需要同步则需要创建多个 实例
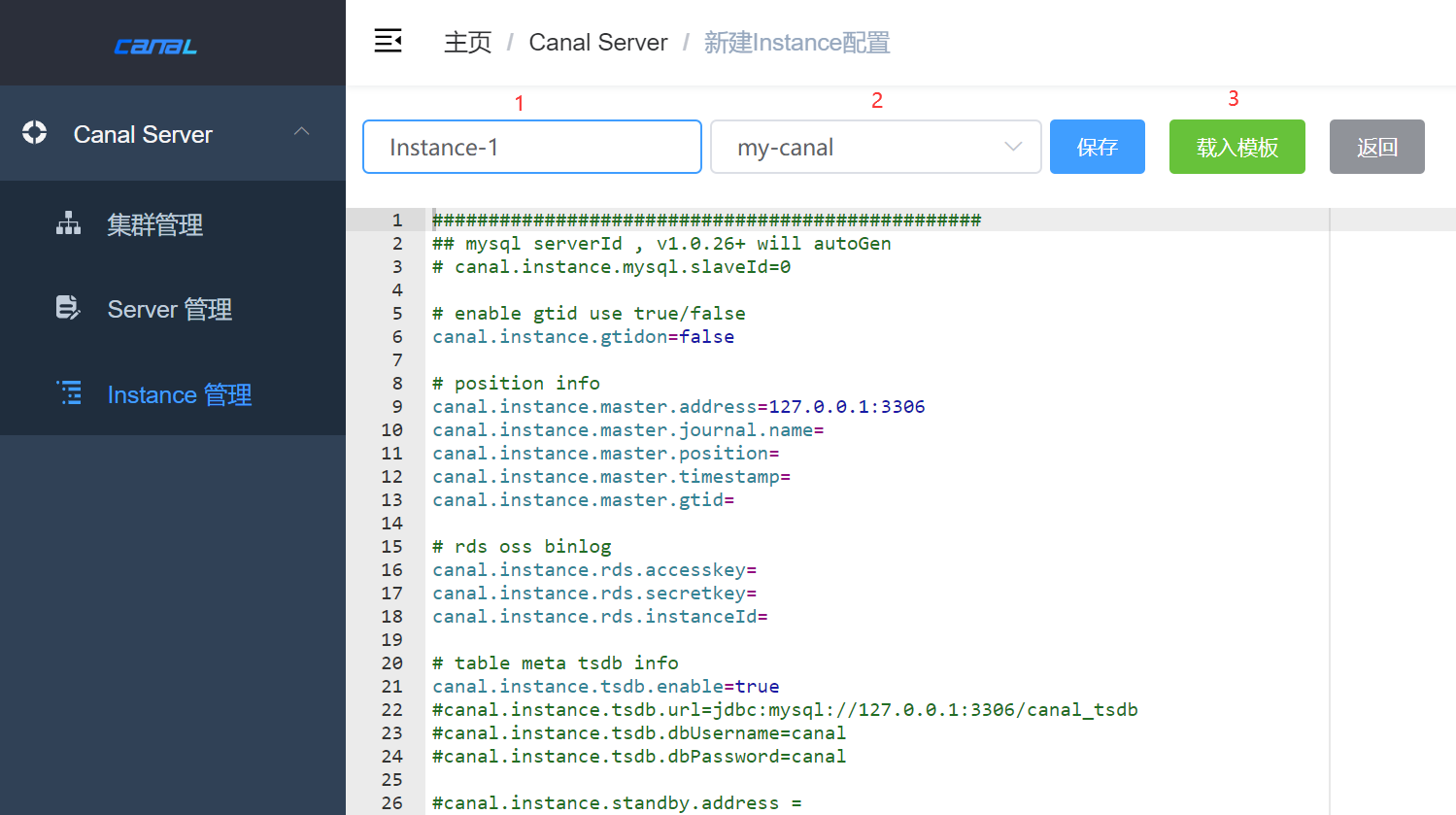
- 先填写实例名
- 选择刚刚创建的集群
- 载入模板配置
主要修改以下配置:
- canal.instance.master.address 配置要同步的数据库地址
- canal.instance.dbUsername 数据库用户名(需同步权限)
- canal.instance.dbPassword 数据库密码
- canal.instance.filter.regex mysql 数据解析关注的表,Perl正则表达式.多个正则之间以逗号(,)分隔,转义符需要双斜杠()
canal.instance.filter.regex常见例子:
- 所有表:.* or ...
- canal schema下所有表: canal..*
- canal下的以canal打头的表:canal.canal.*
- canal schema下的一张表:canal.test1
- 多个规则组合使用:canal..*,mysql.test1,mysql.test2 (逗号分隔)
注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
4.3. 部署canal-deployer
4.3.1. 作用
- 伪装成
MySQL的从库,同步主库的binlog日志。 - 解析并结构化
binary log对象。
4.3.2. 修改配置
执行 vim conf/canal_local.properties 修改配置项 canal.admin.manager 为canal-admin的地址
4.3.3. 启停命令
使用 local 配置启动
bin/startup.sh local
停止
bin/stop.sh
4.4. 部署canal-adapter
4.4.1. 作用
- 对接上游消息,包括kafka、rocketmq、canal-server
- 实现mysql数据的增量同步
- 实现mysql数据的全量同步
- 下游写入支持mysql、es、hbase等
4.4.2. 修改配置
注意:目前
adapter是支持动态配置的,也就是说修改配置文件后无需重启,任务会自动刷新配置!
(1) 修改application.yml
执行 vim conf/application.yml 修改consumerProperties、srcDataSources、canalAdapters的配置
canal.conf:
mode: tcp # kafka rocketMQ # canal client的模式: tcp kafka rocketMQ
flatMessage: true # 扁平message开关, 是否以json字符串形式投递数据, 仅在kafka/rocketMQ模式下有效
syncBatchSize: 1000 # 每次同步的批数量
retries: 0 # 重试次数, -1为无限重试
timeout: # 同步超时时间, 单位毫秒
consumerProperties:
canal.tcp.server.host: # 对应单机模式下的canal
canal.tcp.zookeeper.hosts: 127.0.0.1:2181 # 对应集群模式下的zk地址, 如果配置了canal.tcp.server.host, 则以canal.tcp.server.host为准
canal.tcp.batch.size: 500 # tcp每次拉取消息的数量
srcDataSources: # 源数据库
defaultDS: # 自定义名称
url: jdbc:mysql://127.0.0.1:3306/mytest?useUnicode=true # jdbc url
username: root # jdbc 账号
password: 121212 # jdbc 密码
canalAdapters: # 适配器列表
- instance: example # canal 实例名或者 MQ topic 名
groups: # 分组列表
- groupId: g1 # 分组id, 如果是MQ模式将用到该值
outerAdapters: # 分组内适配器列表
- name: es7 # es7适配器
mode: rest # transport or rest
hosts: 127.0.0.1:9200 # es地址
security.auth: test:123456 # 访问es的认证信息,如没有则不需要填
cluster.name: my-es # 集群名称,transport模式必需配置
......
- 一份数据可以被多个group同时消费, 多个group之间会是一个并行执行, 一个group内部是一个串行执行多个outerAdapters, 比如例子中logger和hbase
- 目前client adapter数据订阅的方式支持两种,直连canal server 或者 订阅kafka/RocketMQ的消息
(2) conf/es7目录下新增映射配置文件
adapter将会自动加载
conf/es7下的所有.yml结尾的配置文件
新增表映射的配置文件,如 sys_user.yml 内容如下:
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: sys_user
_id: id
upsert: true
sql: "select id, username,
, case when sex = 0 then '男' else '女' end sex
, case when is_del = 0 then '否' else '是' end isdel
from sys_user"
etlCondition: "where update_time>={}"
commitBatch: 3000
- dataSourceKey 配置
application.yml里srcDataSources的值 - destination 配置
canal.deployer的Instance名 - groupId 配置
application.yml里canalAdapters.groups的值 - _index 配置索引名
- _id 配置主键对应的字段
- upsert 是否更新
- sql 映射sql
- etlCondition etl 的条件参数,全量同步时可以使用
- commitBatch 提交批大小
sql映射支持多表关联自由组合, 但是有一定的限制:
- 主表不能为子查询语句
- 只能使用left outer join即最左表一定要是主表
- 关联从表如果是子查询不能有多张表
- 主sql中不能有where查询条件(从表子查询中可以有where条件但是不推荐, 可能会造成数据同步的不一致, 比如修改了where条件中的字段内容)
- 关联条件只允许主外键的'='操作不能出现其他常量判断比如: on a.role_id=b.id and b.statues=1
- 关联条件必须要有一个字段出现在主查询语句中比如: on a.role_id=b.id 其中的 a.role_id 或者 b.id 必须出现在主select语句中
Elastic Search的mapping 属性与sql的查询值将一一对应(不支持 select *), 比如: select a.id as _id, a.name, a.email as _email from user, 其中name将映射到es mapping的name field, _email将 映射到mapping的_email field, 这里以别名(如果有别名)作为最终的映射字段. 这里的_id可以填写到配置文件的 _id: _id映射
4.4.3. 启停命令
启动
bin/startup.sh
关闭
bin/stop.sh
4.5. 遗留问题
目前使用的 1.1.5-SNAPSHOT 版本由于还不是发布版,发现 canal-adapter 的集群部署有个bug,配置 zookeeper 地址后启动会出现以下异常:
java.lang.LinkageError: loader constraint violation: when resolving method "com.alibaba.otter.canal.common.zookeeper.ZkClientx.create(Ljava/lang/String;Ljava/lang/Object;Lorg/apache/zookeeper/CreateMode;)Ljava/lang/String;" the class loader (instance of com/alibaba/otter/canal/connector/core/spi/URLClassExtensionLoader) of the current class, com/alibaba/otter/canal/client/impl/running/ClientRunningMonitor, and the class loader (instance of sun/misc/Launcher$AppClassLoader) for the method's defining class, org/I0Itec/zkclient/ZkClient, have different Class objects for the type org/apache/zookeeper/CreateMode used in the signature
at com.alibaba.otter.canal.client.impl.running.ClientRunningMonitor.initRunning(ClientRunningMonitor.java:122) [connector.tcp-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]
at com.alibaba.otter.canal.client.impl.running.ClientRunningMonitor.start(ClientRunningMonitor.java:93) [connector.tcp-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]
at com.alibaba.otter.canal.client.impl.SimpleCanalConnector.connect(SimpleCanalConnector.java:108) [connector.tcp-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]
at com.alibaba.otter.canal.client.impl.ClusterCanalConnector.connect(ClusterCanalConnector.java:64) [connector.tcp-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]
at com.alibaba.otter.canal.connector.tcp.consumer.CanalTCPConsumer.connect(CanalTCPConsumer.java:59) [connector.tcp-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]
有以下3个解决思路:
- adapter暂时使用单实例模式,等待官方解决问题。
- 自行修复bug
- 使用
MQ模式(adapter则无需注册到zookeeper了)
该 BUG 已修复:https://github.com/zlt2000/canal
五、监控
canal 默认已通过 11112 端口暴露同步相关的 metrics 信息,只需通过集成 prometheus 与 grafana 即可实现实时监控同步情况,效果图如下:
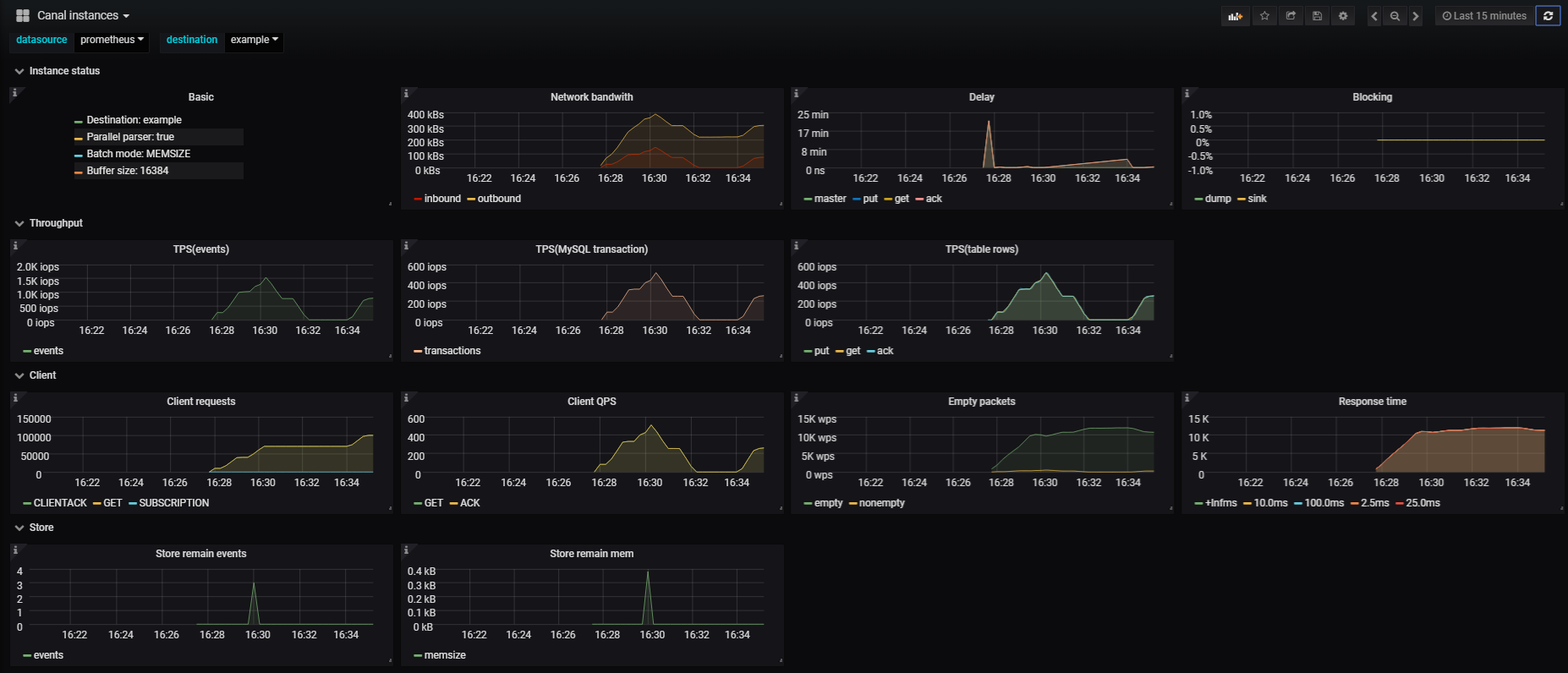
| 指标 | 简述 |
|---|---|
| Basic | Canal instance 基本信息。 |
| Network bandwith | 网络带宽。包含inbound(canal server读取binlog的网络带宽)和outbound(canal server返回给canal client的网络带宽)。 |
| Delay | Canal server与master延时;store 的put, get, ack操作对应的延时。 |
| Blocking | sink线程blocking占比;dump线程blocking占比(仅parallel mode)。 |
| TPS(events) | Canal instance消费所有binlog事件的TPS, 以MySQL binlog events为单位计算。 |
| TPS(transaction) | Canal instance 处理binlog的TPS,以MySQL transaction为单位计算。 |
| TPS(tableRows) | 分别对应store的put, get, ack操作针对数据表变更行的TPS。 |
| Client requests | Canal client请求server的请求数统计,结果按请求类型分类(比如get/ack/sub/rollback等)。 |
| Client QPS | client发送请求的QPS,按GET与CLIENTACK分类统计。 |
| Empty packets | Canal client请求server返回空结果的统计。 |
| Response time | Canal client请求server的响应时间统计。 |
| Store remain events | Canal instance ringbuffer中堆积的events数量。 |
| Store remain mem | Canal instance ringbuffer中堆积的events内存使用量。 |
六、总结
- 准备MySQL
- 开启binlog(row模式)
- 准备同步权限的用户
- 创建canal-admin的库表
- 准备zookeeper
- 部署canal-admin
- 创建集群
- 创建server:关联集群
- 创建Instance:关联集群,并配置源库信息
- 启动canal-deployer
- 关联canal-admin
- 启动canal-adapter
- 关联zookeeper
- 配置源库信息
- 关联Instance
- 配置目标库信息(es)
- 新增映射配置文件
扫码关注有惊喜!
