
一、前言
程序访问 MySQL 数据库时,当查询出来的数据量特别大时,数据库驱动把加载到的数据全部加载到内存里,就有可能会导致内存溢出(OOM)。
其实在 MySQL 数据库中提供了流式查询,允许把符合条件的数据分批一部分一部分地加载到内存中,可以有效避免OOM;本文主要介绍如何使用流式查询并对比普通查询进行性能测试。
二、JDBC实现流式查询
使用JDBC的 PreparedStatement/Statement 的 setFetchSize 方法设置为 Integer.MIN_VALUE 或者使用方法 Statement.enableStreamingResults() 可以实现流式查询,在执行 ResultSet.next() 方法时,会通过数据库连接一条一条的返回,这样也不会大量占用客户端的内存。
public int execute(String sql, boolean isStreamQuery) throws SQLException {
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null;
int count = 0;
try {
//获取数据库连接
conn = getConnection();
if (isStreamQuery) {
//设置流式查询参数
stmt = conn.prepareStatement(sql, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(Integer.MIN_VALUE);
} else {
//普通查询
stmt = conn.prepareStatement(sql);
}
//执行查询获取结果
rs = stmt.executeQuery();
//遍历结果
while(rs.next()){
System.out.println(rs.getString(1));
count++;
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
close(stmt, rs, conn);
}
return count;
}
PS:上面的例子中通过参数
isStreamQuery来切换流式查询与普通查询,用于下面做测试对比。
三、性能测试
创建了一张测试表 my_test 进行测试,总数据量为 27w 条,分别使用以下4个测试用例进行测试:
- 大数据量普通查询(27w条)
- 大数据量流式查询(27w条)
- 小数据量普通查询(10条)
- 小数据量流式查询(10条)
3.1. 测试大数据量普通查询
@Test
public void testCommonBigData() throws SQLException {
String sql = "select * from my_test";
testExecute(sql, false);
}
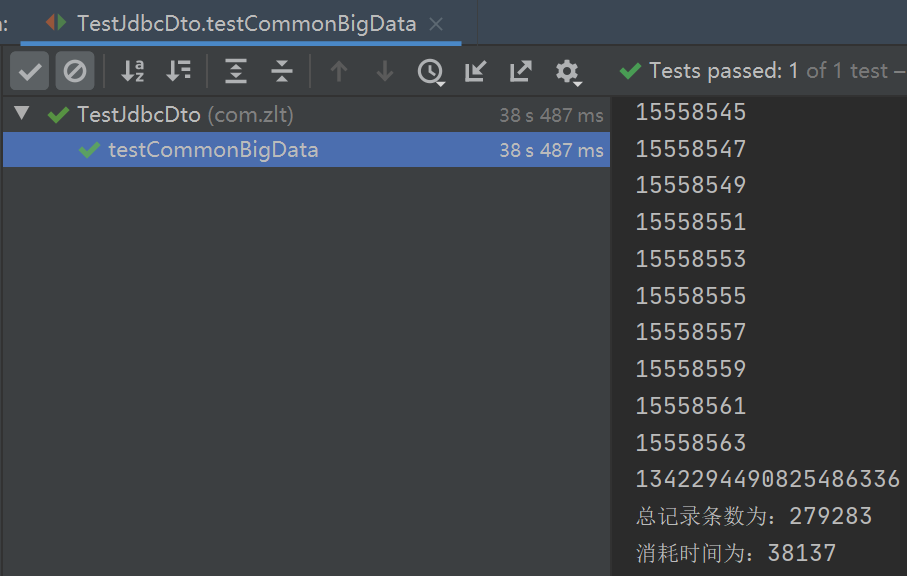
3.1.1. 查询耗时
27w 数据量用时 38 秒
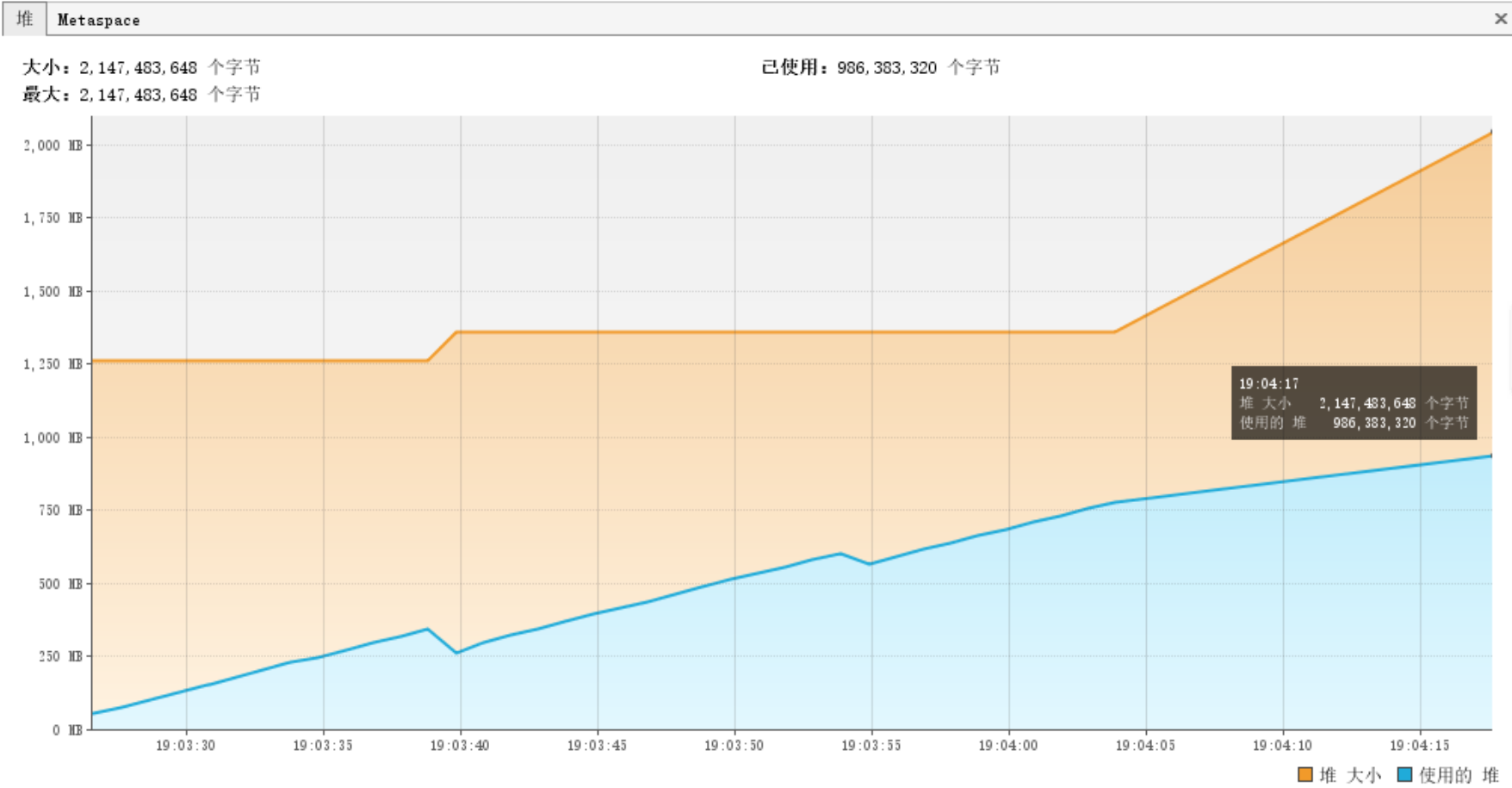
3.1.2. 内存占用情况
使用将近 1G 内存
3.2. 测试大数据量流式查询
@Test
public void testStreamBigData() throws SQLException {
String sql = "select * from my_test";
testExecute(sql, true);
}
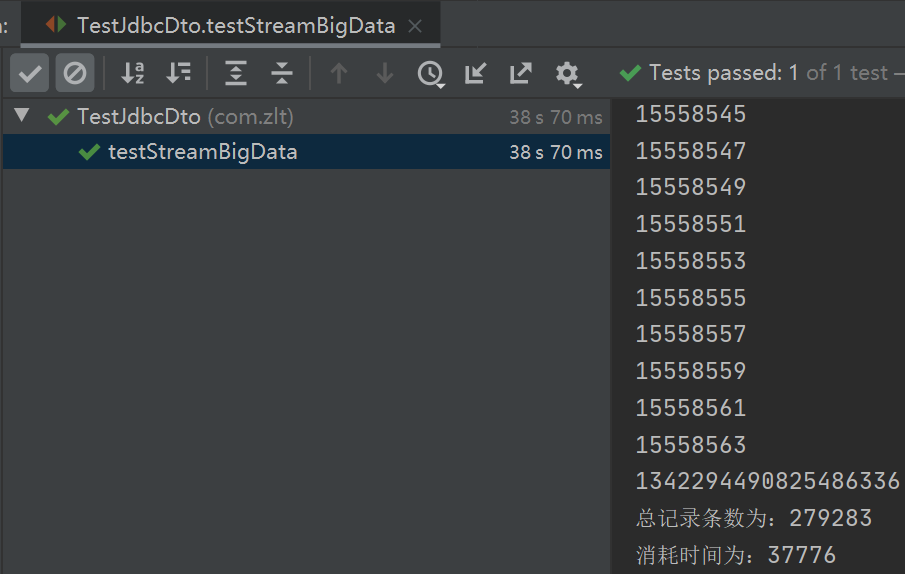
3.2.1. 查询耗时
27w 数据量用时 37 秒
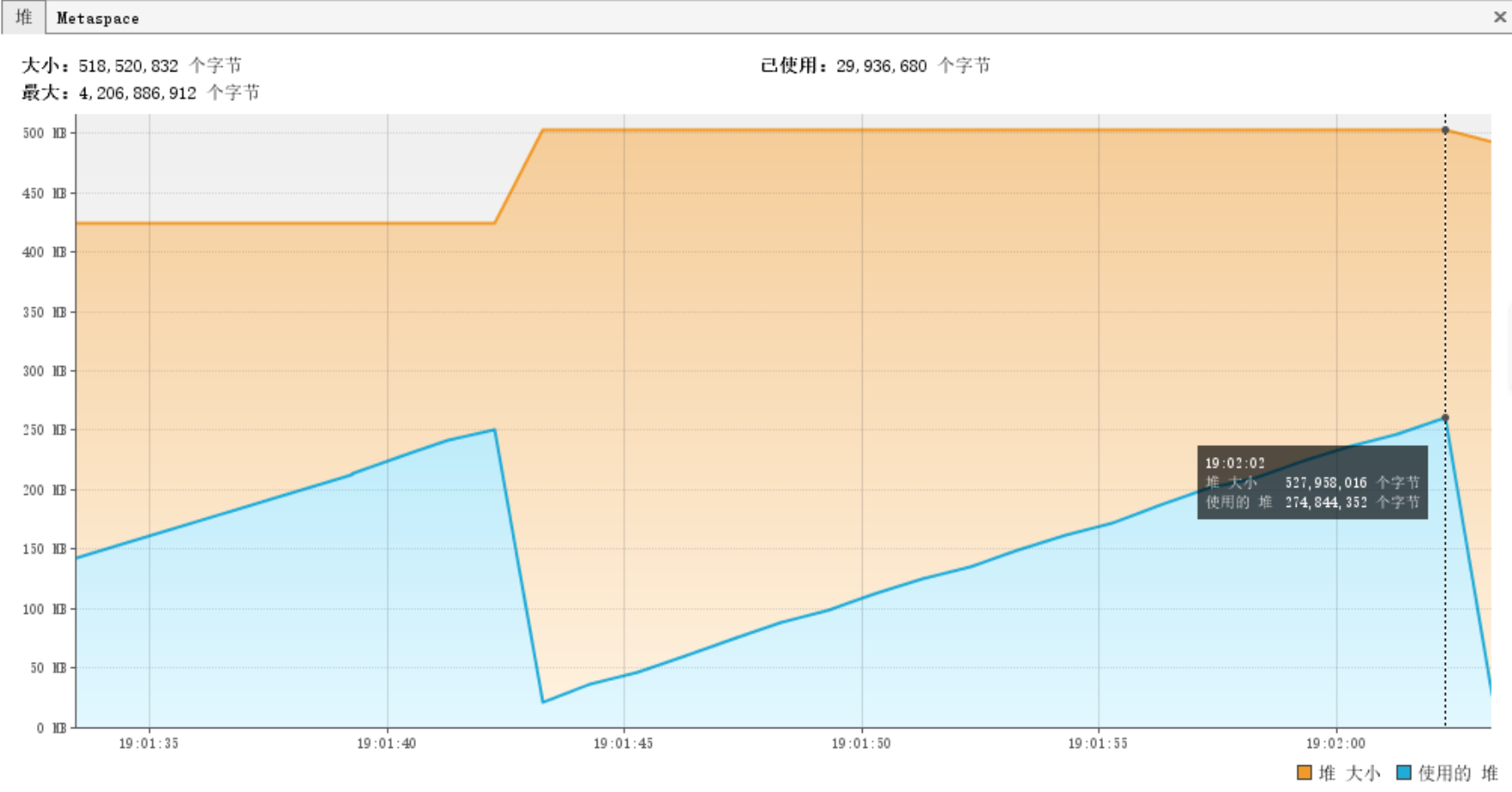
3.2.2. 内存占用情况
由于是分批获取,所以内存在30-270m波动
3.3. 测试小数据量普通查询
@Test
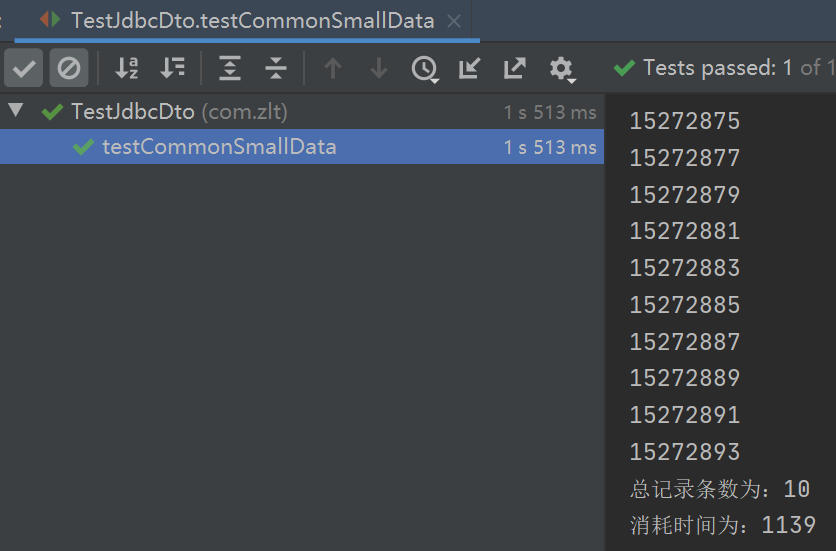
public void testCommonSmallData() throws SQLException {
String sql = "select * from my_test limit 100000, 10";
testExecute(sql, false);
}
3.3.1. 查询耗时
10 条数据量用时 1 秒
3.4. 测试小数据量流式查询
@Test
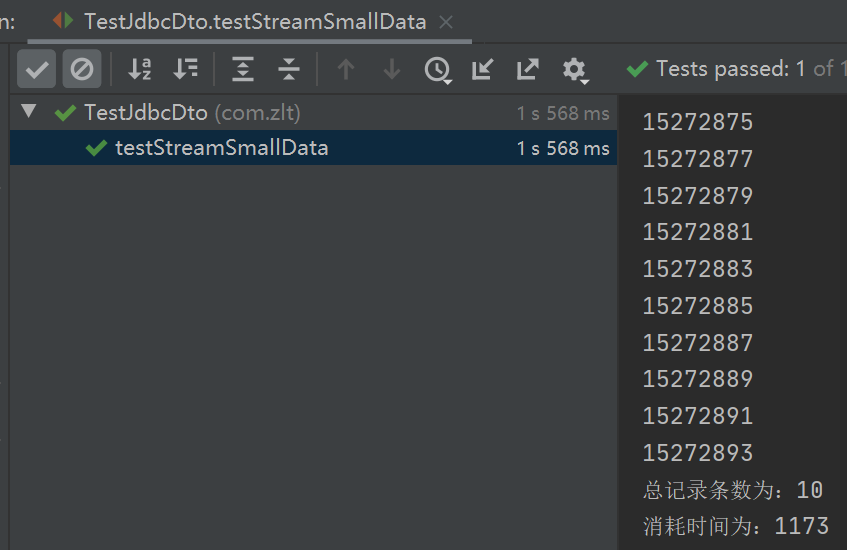
public void testStreamSmallData() throws SQLException {
String sql = "select * from my_test limit 100000, 10";
testExecute(sql, true);
}
3.4.1. 查询耗时
10 条数据量用时 1 秒
四、总结
MySQL 流式查询对于内存占用方面的优化还是比较明显的,但是对于查询速度的影响较小,主要用于解决大数据量查询时的内存占用多的场景。
DEMO地址:https://github.com/zlt2000/mysql-stream-query
扫码关注有惊喜!
