不多说,直接上干货!

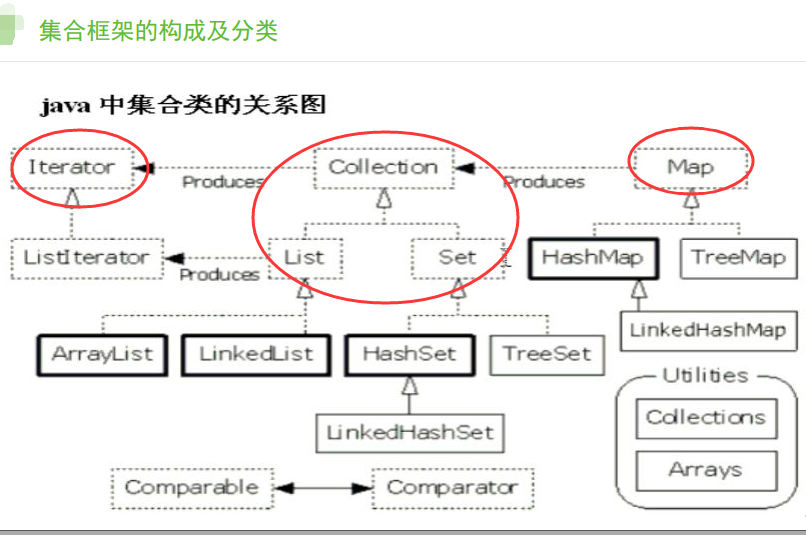
集合框架中包含了大量集合接口、这些接口的实现类和操作它们的算法。
集合容器因为内部的数据结构不同,有多种具体容器。
不断的向上抽取,就形成了集合框架。
Map是一次添加一对元素。Collection是一次添加一个元素。
iterator是迭代获取元素
第一大类:Iterator
迭代器是一个对象,它是遍历并选择序列中的对象。
说比了,就是给后面的Collection接口里的实现类使用搭配的,为了取值罢了。
Iterator 只能正向遍历集合,适用于获取移除元素。
ListIterator 继承自Iterator,专门针对List,可以从两个方向来遍历List,同时还支持元素的修改。
第二大类:Collection
包括List(ArrayList、LinkedList)和Set(HashSet、TreeSet、LinkedHashSet)
ArrayList: 基于数组,不同步,查询较快
LinkedList:基于链表,不同步,查询较慢,增删较快
HashSet: 内部数据结构是哈希表 ,是无序不能排序,是不同步的。
如何保证该集合的元素唯一性呢?
是通过对象的hashCode和equals方法来完成对象唯一性的。
如果对象的hashCode值不同,那么不用判断equals方法,就直接存储到哈希表中。
如果对象的hashCode值相同,那么要再次判断对象的equals方法是否为true。
如果为true,视为相同元素,不存。如果为false,那么视为不同元素,就进行存储。
记住:如果元素要存储到HashSet集合中,必须覆盖hashCode方法和equals方法。
一般情况下,如果定义的类会产生很多对象,比如人,学生,书,通常都需要覆盖equals,hashCode方法。
建立对象判断是否相同的依据。
hash是一种算法,很多存储起来,就是hash表。
TreeSet排序方式有两种。
1, 让元素自身具备比较性。
其实是让元素实现Comparable接口, 覆盖compareTo方法。这称为元素的自然排序。
2, 当元素自身不具备比较性, 或者元素具备的比较性不是所需要的,可以让集合自身具备比较性。
定义一个比较器: 其实就是定义一个类, 实现Comparator接口。 覆盖compare方法。
将Comparator接口的子类对象作为参数传递给TreeSet的构造函数。
LinkedHashSet
元素存入和取出的顺序一致。 是一个有序的集合, 不需要我们自己实现排序功能 。
第三大类:Map
包括(HashMap、TreeMap、LinkedHashMap)
Map与Collection在集合框架中属并列存在。Map是一次添加一对元素(存储的是夫妻,哈哈)。Collection是一次添加一个元素(存储的是光棍,哈哈)。
Map存储的是键值对。
Map存储元素使用put方法, Collection使用add方法。
Map集合没有直接取出元素的方法, 而是先转成Set集合, 再通过迭代获取元素。
Map集合中键要保证唯一性。
Map的两种取值方式keySet、entrySet
keySet
先获取所有键的集合, 再根据键获取对应的值。(即先找到丈夫,去找妻子)
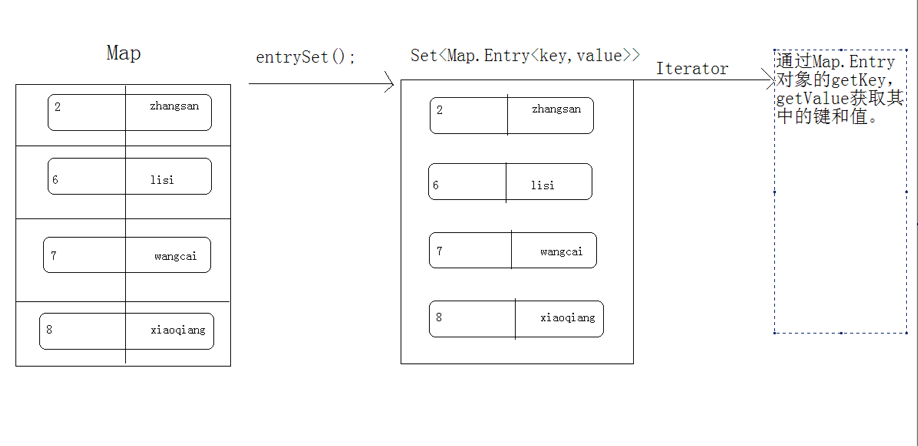
entrySet
先获取map中的键值关系封装成一个个的entry对象, 存储到一个Set集合中,再迭代这个Set集合, 根据entry获取对应的key和value。
向集合中存储自定义对象 (entry类似于是结婚证)
HashMap : 内部结构是哈希表,不是同步的。允许null作为键,null作为值。
TreeMap : 内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
更多,见
牛客网Java刷题知识点之Map的两种取值方式keySet和entrySet、HashMap 、Hashtable、TreeMap、LinkedHashMap、ConcurrentHashMap 、WeakHashMap
java中集合、集合类和集合框架是什么意思?
集合类,是这些集合框架里的集合接口的一些实现类。
为什么出现集合类?
面向对象语言对事物的体现都是以对象的形式, 所以为了方便对多个对象的操作, 就对对象进行存储, 集合就是存储对象最常用的一种方式。
对象用于封装特有数据,对象多了需要存储,如果对象的个数不确定,就使用集合容器进行存储。
数值有很多,用数组存。
数组有很多,用二维数组存。
数据有很多,用对象存。
对象有很多,用集合存。
数组和集合类同是容器, 有何不同?
数组虽然也可以存储对象, 但长度是固定的; 集合长度是可变的。 数组中可以存储基本数据类型。 集合只能存储对象, 不可以存储基本数据类型值。
集合类的特点:
集合只用于存储对象, 集合长度是可变的, 集合可以存储不同类型的对象。
好比水杯是容器,有的带有茶隔,有的不带茶隔。同样,集合容器里也有不同的。每一个容器里的数据结构不一样。
Collections和Collection有什么区别
Collection是一个集合接口,它提供了对集合对象进行基本操作的通用接口方法。
集合接口Collection的实现类有: List 和 Set 。
集合框架Collections是针对集合类的一个包装类,它提供一系列静态方法以实现对各种Collection集合的搜索、排序、线程安全化等操作。
集合框架Collections不能被实例化。
CollectionDemo.java
package zhouls.bigdata.DataFeatureSelection; import java.util.ArrayList; import java.util.Collection; public class CollectionDemo { /** * @param args */ public static void main(String[] args) { Collection coll = new ArrayList(); show(coll); Collection c1 = new ArrayList(); Collection c2 = new ArrayList(); show(c1,c2); } public static void show(Collection c1,Collection c2){ //给c1添加元素。 c1.add("abc1"); c1.add("abc2"); c1.add("abc3"); c1.add("abc4"); //给c2添加元素。 c2.add("abc1"); c2.add("abc2"); c2.add("abc3"); c2.add("abc4"); c2.add("abc5"); System.out.println("c1:"+c1);//c1:[abc1, abc2, abc3,abc4] System.out.println("c2:"+c2);//c2:[abc1, abc2, abc3,abc4,abc5] //演示addAll // c1.addAll(c2);//将c2中的元素添加到c1中。 // System.out.println("c1:"+c1);//c1:[abc1, abc2, abc3,abc4,abc1, abc2, abc3,abc4,abc5] //演示removeAll,跟retainAll相反 // boolean b = c1.removeAll(c2);//将两个集合中的相同元素,从调用removeAll的集合中删除。 // System.out.println("removeAll:"+b);//removeAll:true // System.out.println("c1:"+c1);//c1:[abc1,abc3,abc4] //演示containsAll // boolean b = c1.containsAll(c2); // System.out.println("containsAll:"+b);//containsAll:false //演示retainAll,跟removeAll相反 boolean b = c1.retainAll(c2);//取交集,保留和指定的集合相同的元素,而删除不同的元素。 System.out.println("retainAll:"+b);//retainAll:false System.out.println("c1:"+c1);//c1:[abc1, abc2, abc3,abc4] } public static void show(Collection coll){ //1,添加元素。add. coll.add("abc1"); coll.add("abc2"); coll.add("abc3"); System.out.println(coll);//[abc1, abc2, abc3] //2,删除元素。remove // coll.remove("abc2");//会改变集合的长度 //清空集合. // coll.clear(); System.out.println(coll.contains("abc3"));//true System.out.println(coll); } }
一、集合框架中的迭代器Iterator
其实可以把迭代理解为顺序读取。 即取出元素的方式。它的返回值比较特殊, 是Iterator。
迭代器是一个对象,它是遍历并选择序列中的对象。
使用迭代器可以获取集合中的元素。
注意: 在集合中, 取出元素的格式是固定的。 只要是Collection集合体系, 迭代器就是通用取出方式。
注意: 其实list中存储的都是对象地址。 集合中存储的都是对象引用, 获取迭代器后, 迭代器中持有的也是元素的引用。
注意: 在进行迭代器使用时, next方法在循环中, 建议只定义一个, 定义多个会导致数据错误。 当next方法没有获取到元素时, 会发生NosuchElementException
列表迭代器ListIterator
在对集合中元素迭代的同时进行添加操作, 会发生并发修改异常。
concurrentModifycationException(当方法检测到对象的并发修改, 但不允许这种修改时, 抛出此异常), 属于runtime里面的一个异常。
原因: 使用迭代器进行迭代的同时又使用了集合中的方法。
分析: 这两个不能同时使用。
但是需求就是在迭代的时候要添加元素
解决: 对于List集合。 有一个新的迭代方式。 就是ListIterator 列表迭代器。 ListIterator本身也是Iterator的子接口。 并提供了更多的迭代过程中的操作。 在迭代过程中, 如果需要增删改查元素的操作, 需要使用列表迭代器中的方法。
注意: 该迭代器, 只能用于List集合。
Iterator与ListIterator有什么区别?
Iterator只能正向遍历集合,适用于获取移除元素。
ListIterator继承自Iterator,专门针对List,可以从两个方向来遍历List,同时还支持元素的修改。
//使用for循环进行遍历,开发时优先考虑使用for循环的方式进行遍历 for(Iterator it = c1.iterator();it.hasNext();){ //集合框架中的迭代器Iterator System.out.println(it.next()); }
IteratorDemo.java
package zhouls.bigdata.DataFeatureSelection; import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; public class IteratorDemo { /** * @param args */ public static void main(String[] args) { Collection coll = new ArrayList(); coll.add("abc1"); coll.add("abc2"); coll.add("abc3"); coll.add("abc4"); // System.out.println(coll); //使用了Collection中的iterator()方法。 调用集合中的迭代器方法,是为了获取集合中的迭代器对象。 // Iterator it = coll.iterator(); // while(it.hasNext()){ // System.out.println(it.next()); // }
//开发中,用下面的这种,因为循环后,对象it还可以再用 for(Iterator it = coll.iterator(); it.hasNext(); ){ System.out.println(it.next()); } // System.out.println(it.next()); // System.out.println(it.next()); // System.out.println(it.next()); // System.out.println(it.next()); // System.out.println(it.next());//java.util.NoSuchElementException } }

Iterator iterator():取出元素的方式,迭代器。
该对象必须依赖于具体容器,因为每一个容器的数据结构都不同。
所以该迭代器对象是在容器中进行内部实现的。
对于使用容器者而言,具体的实现不重要,只要通过容器获取到该实现的迭代器的对象即可,
也就是iterator方法。
Iterator接口就是对所有的Collection容器进行元素取出的公共接口。
List:有序(存入和取出的顺序一致),元素都有索引(角标),元素可以重复。
ListDemo.java
package zhouls.bigdata.DataFeatureSelection; import java.util.ArrayList; import java.util.List; public class ListDemo { /** * @param args */ public static void main(String[] args) { List list = new ArrayList(); show(list); } public static void show(List list) { //添加元素 list.add("abc1"); list.add("abc2"); list.add("abc3"); System.out.println(list); //插入元素。 list.add(1,"abc9"); System.out.println(list);//得到[abc1, abc9, abc2, abc3] //删除元素。 System.out.println("remove:"+list.remove(2));//remove:abc2 System.out.println(list);//得到[abc1, abc9, abc3] //修改元素。 System.out.println("set:"+list.set(1, "abc8"));//set:abc9 System.out.println(list);//[abc1, abc8, abc3] //获取元素。 System.out.println("get:"+list.get(0));//get:abc1 System.out.println(list);//[abc1, abc8, abc3] //获取子列表。 System.out.println("sublist:"+list.subList(1, 2));//sublist:[abc8] System.out.println(list);//[abc1, abc8, abc3] } }
ListIterator 在对集合中元素迭代的同时进行添加操作, 会发生并发修改异常。
ListDemo2.java
package zhouls.bigdata.DataFeatureSelection; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.ListIterator; public class ListDemo2 { /** * @param args */ public static void main(String[] args) { List list = new ArrayList(); show(list); list.add("abc1"); list.add("abc2"); list.add("abc3"); System.out.println("list:"+list);//list:[abc1, abc2, abc3, abc4, abc1, abc2, abc3] ListIterator it = list.listIterator();//获取列表迭代器对象 //它可以实现在迭代过程中完成对元素的增删改查。 //注意:只有list集合具备该迭代功能。 while(it.hasNext()){ Object obj = it.next(); if(obj.equals("abc2")){ it.set("abc9"); } } System.out.println("hasNext:"+it.hasNext());//hasNext:false //it.hasNext()分为两个: it 和 .hasNext(); //it:这里应该是上文定义了一个可迭代对象 //.hasNext()是检查序列中是否还有元素,即hasnext()是检测下一个元素是否存在,多用于遍历输出。 System.out.println("hasPrevious:"+it.hasPrevious());//hasPrevious:true //it.hasNext()这句是正序.这句意思就是从第一个开始,有下一个的话继续遍历。hasNext()由前向next后输出。 //it.hasPrevious()这句是倒序遍历,这句就是从最后一个开始,有上一个的话继续遍历。 while(it.hasPrevious()){ System.out.println("previous:"+it.previous());//previous跟next不觉得很熟悉么,这俩就是上一个跟下一个的意思。由后向前输出previous() /*得到 previous:abc3 previous:abc9 previous:abc1 previous:abc4 previous:abc3 previous:abc9 previous:abc1 */ } System.out.println("list:"+list); /*Iterator it = list.iterator(); while(it.hasNext()){ Object obj = it.next();//java.util.ConcurrentModificationException //在迭代器过程中,不要使用集合操作元素,容易出现异常。 //可以使用Iterator接口的子接口ListIterator来完成在迭代中对元素进行更多的操作。 if(obj.equals("abc2")){ list.add("abc9"); } else System.out.println("next:"+obj); } System.out.println(list); */ } public static void show(List list) { list.add("abc1"); list.add("abc2"); list.add("abc3"); list.add("abc4"); Iterator it = list.iterator(); while(it.hasNext()){ System.out.println("next:"+it.next()); } //list特有的取出元素的方式之一。 for(int x=0; x<list.size(); x++){ System.out.println("get:"+list.get(x)); } } }
二、集合框架中的Collection接口
Collection接口有两个子接口:List(列表) , Set(集合)
List: 可存放重复元素(因为元素有索引角标), 元素存取是有序的。
Set: 不可以存放重复元素, 元素存取是无序的。
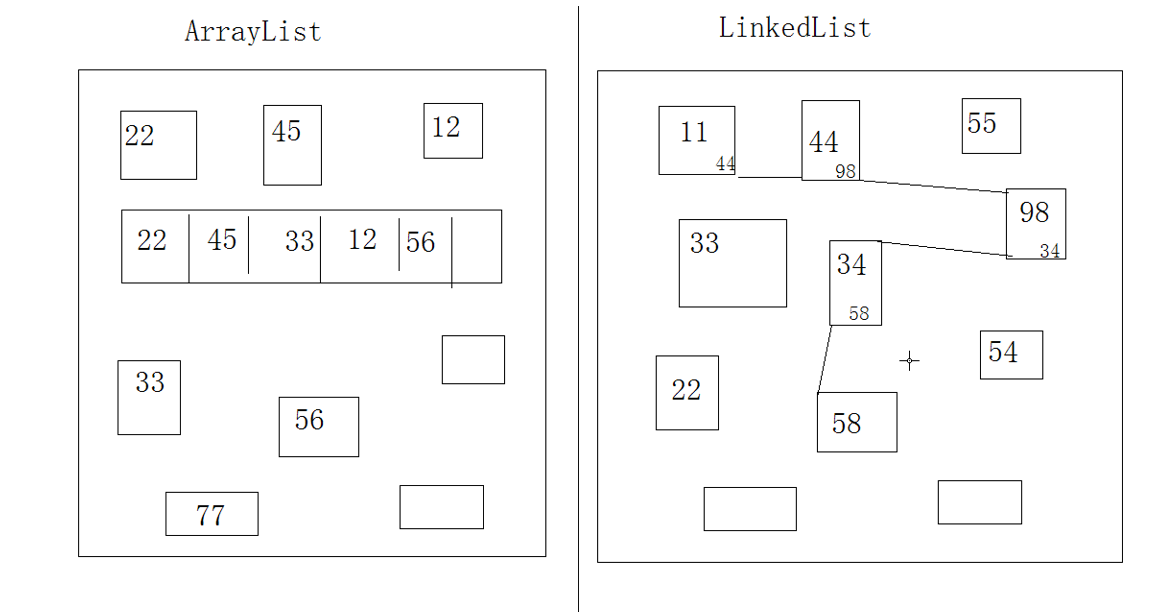
List集合中子类 Vector、ArrayList、LinkedList
List:有序, 可重复, 有索引。三者均为可伸缩数组。
Vector:底层数据结构是数组结构。 jdk1.0版本。 线程安全的。 无论增删还是查询都非常慢。默认扩充为原来的2倍。
ArrayList:底层数据结构是数组结构。 线程不安全的。 所以ArrayList的出现替代了Vector, 但是查询的速度很快。默认扩充为原来的1.5倍。
LinkedList:底层是链表数据结构。 线程不安全的, 同时对元素的增删操作效率很高。但查询慢。
注意: 链表结构是这样的: 让后一个元素记住前一个元素的地址。
Vector 和 ArrayList都是基于存储元素的Object[ ] array来实现的。
LinkedList是采用双向列表来实现的。
LinkdedList,增删改查很快: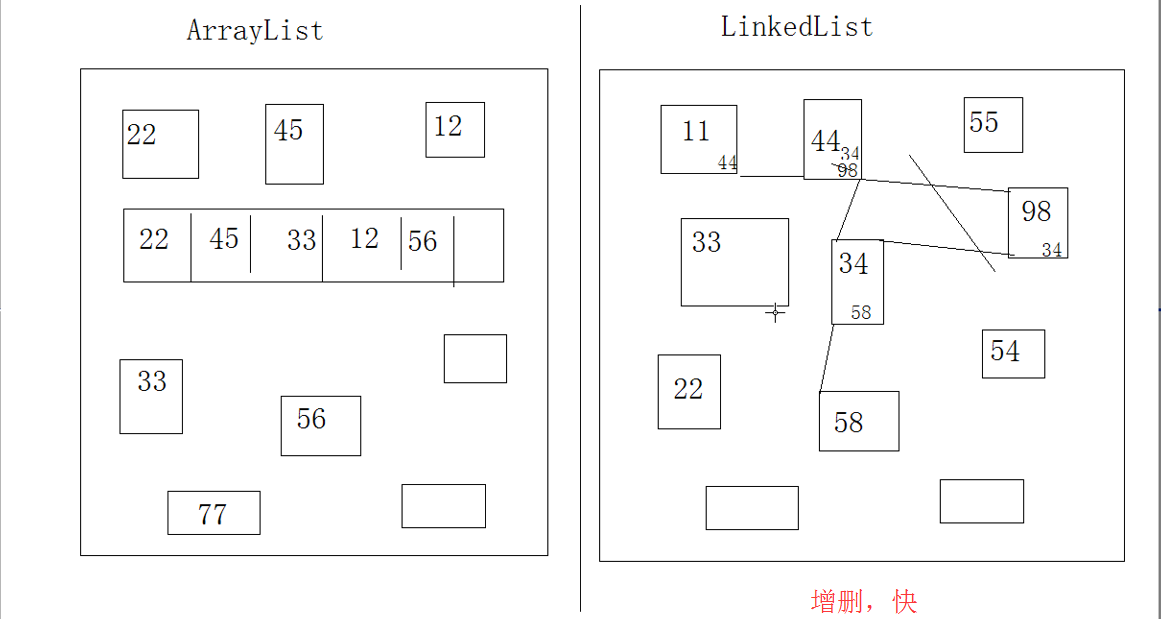
LinkedList的查询速率比较慢:

List集合子类Vector这个类已经不常用了, 我就说里面的一个方法, Elements方法, 这个方法的返回值是枚举接口, 里面有两个方法, 判断和获取。此接口Enumeration的功能与 Iterator 接口的功能是重复的。Enumeration的名称和方法的名称过程, 书写很麻烦。 所以被Iterator所取代。
更多,见
牛客网Java刷题知识点之ArrayList 、LinkedList 、Vector 的底层实现和区别
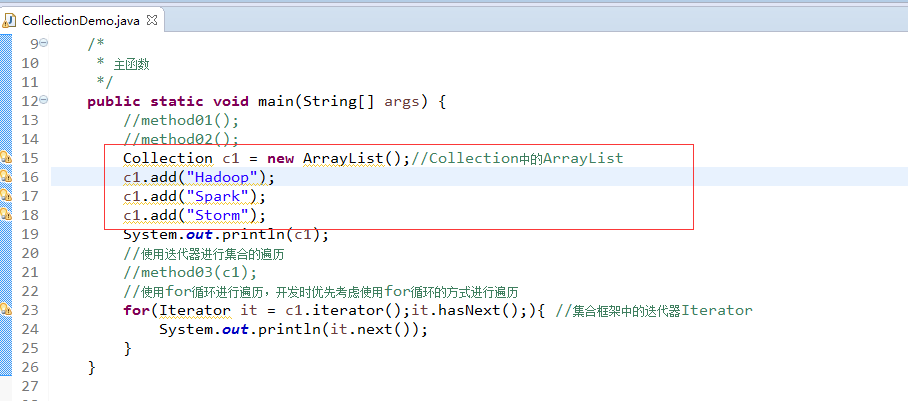
Collection c1 = new ArrayList();//Collection中的ArrayList c1.add("Hadoop"); c1.add("Spark"); c1.add("Storm");
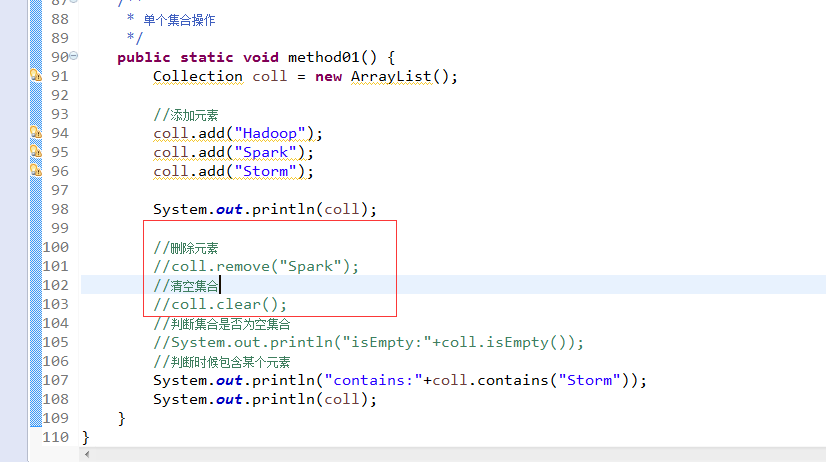
//删除元素 coll.remove("Spark"); //清空集合 coll.clear();
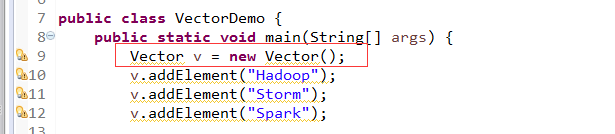
VectorDemo.java
package zhouls.bigdata.DataFeatureSelection; import java.util.Enumeration; import java.util.Iterator; import java.util.Vector; public class VectorDemo { public static void main(String[] args) { Vector v = new Vector(); v.addElement("abc1"); v.addElement("abc2"); v.addElement("abc3"); v.addElement("abc4"); Enumeration en = v.elements();//Enumeration是枚举类型 while(en.hasMoreElements()){ System.out.println("nextelment:"+en.nextElement()); /* nextelment:abc1 nextelment:abc2 nextelment:abc3 nextelment:abc4 */ } Iterator it = v.iterator(); while(it.hasNext()){ System.out.println("next:"+it.next()); /* next:abc1 next:abc2 next:abc3 next:abc4 */ } } }
LinkedListDemo.java
package zhouls.bigdata.DataFeatureSelection; import java.util.Iterator; import java.util.LinkedList; public class LinkedListDemo{ /** * @param args */ public static void main(String[] args){ LinkedList link = new LinkedList(); link.addFirst("abc1"); link.addFirst("abc2"); link.addFirst("abc3"); link.addFirst("abc4"); System.out.println(link);//[abc4, abc3, abc2, abc1] System.out.println(link.getFirst());//获取第一个但不删除。abc4 System.out.println(link.getFirst());//abc4 System.out.println(link.removeFirst());//获取元素但是会删除。是abc4 System.out.println(link.removeFirst());//abc3 while(!link.isEmpty()){ System.out.println(link.removeLast());//abc1 } System.out.println(link);//abc2 Iterator it = link.iterator(); while(it.hasNext()){ System.out.println(it.next());//[] } } }
Person.java
package cn.itcast.p.bean; public class Person /*extends Object*/ implements Comparable { private String name; private int age; public Person() { super(); } public Person(String name, int age) { super(); this.name = name; this.age = age; } @Override public int hashCode() { // System.out.println(this+".......hashCode"); return name.hashCode()+age*27; // return 100; } @Override public boolean equals(Object obj) { if(this == obj) return true; if(!(obj instanceof Person)) throw new ClassCastException("类型错误"); // System.out.println(this+"....equals....."+obj); Person p = (Person)obj; return this.name.equals(p.name) && this.age == p.age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String toString(){ return name+":"+age; } @Override public int compareTo(Object o) { Person p = (Person)o; int temp = this.age-p.age; return temp==0?this.name.compareTo(p.name):temp; // int temp = this.name.compareTo(p.name); // return temp==0?this.age-p.age:temp; /* if(this.age>p.age) return 1; if(this.age<p.age) return -1; else{ return this.name.compareTo(p.name); } */ } }
ArrayListTest.java
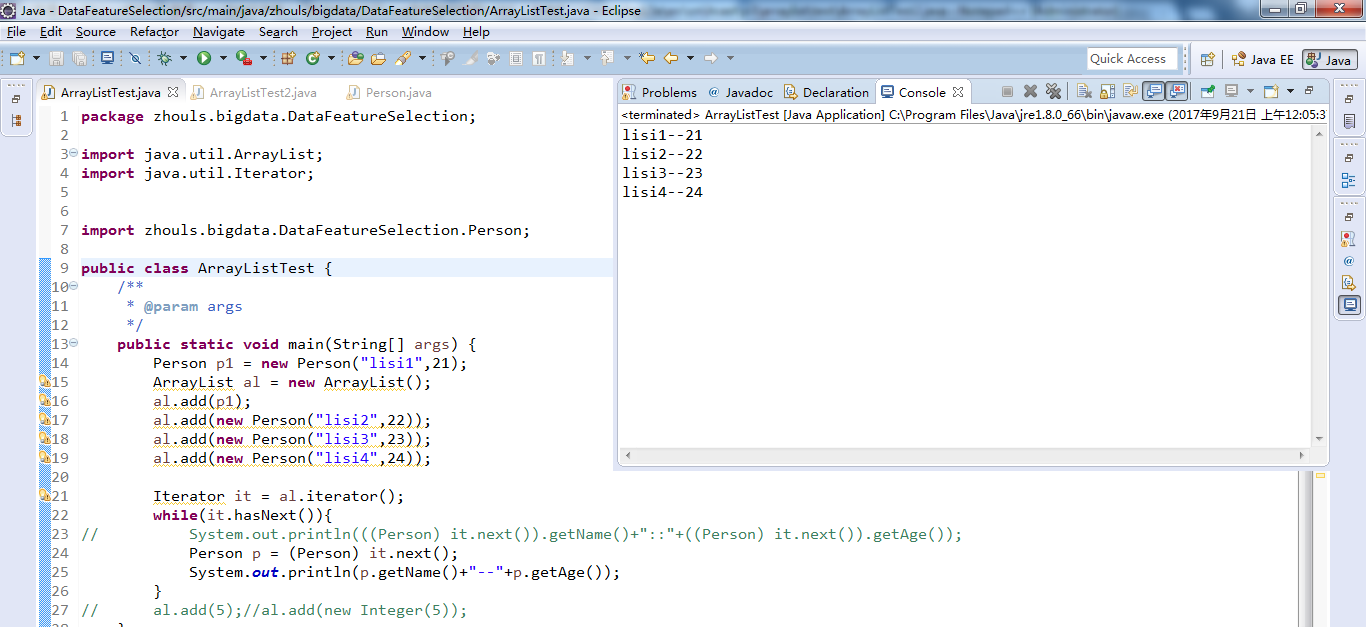
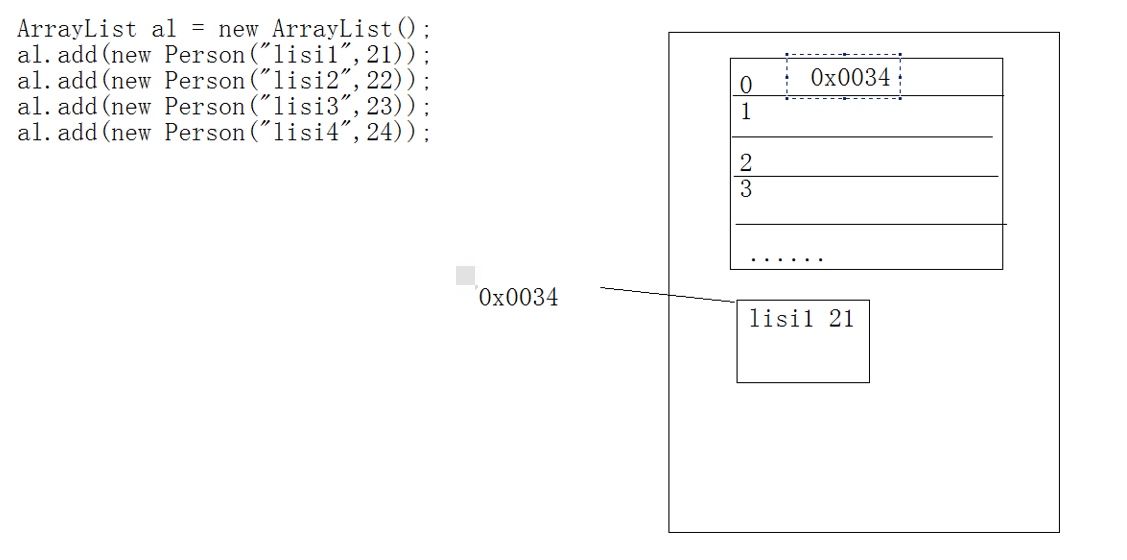
package zhouls.bigdata.DataFeatureSelection; import java.util.ArrayList; import java.util.Iterator; import zhouls.bigdata.DataFeatureSelection.Person; public class ArrayListTest { /** * @param args */ public static void main(String[] args) { Person p1 = new Person("lisi1",21); ArrayList al = new ArrayList(); al.add(p1); al.add(new Person("lisi2",22)); al.add(new Person("lisi3",23)); al.add(new Person("lisi4",24)); Iterator it = al.iterator(); while(it.hasNext()){ // System.out.println(((Person) it.next()).getName()+"::"+((Person) it.next()).getAge()); Person p = (Person) it.next(); System.out.println(p.getName()+"--"+p.getAge()); } // al.add(5);//al.add(new Integer(5));//因为集合里存储的是对象,同时集合里不能存储基本数据类型。这是自动装箱。 } }
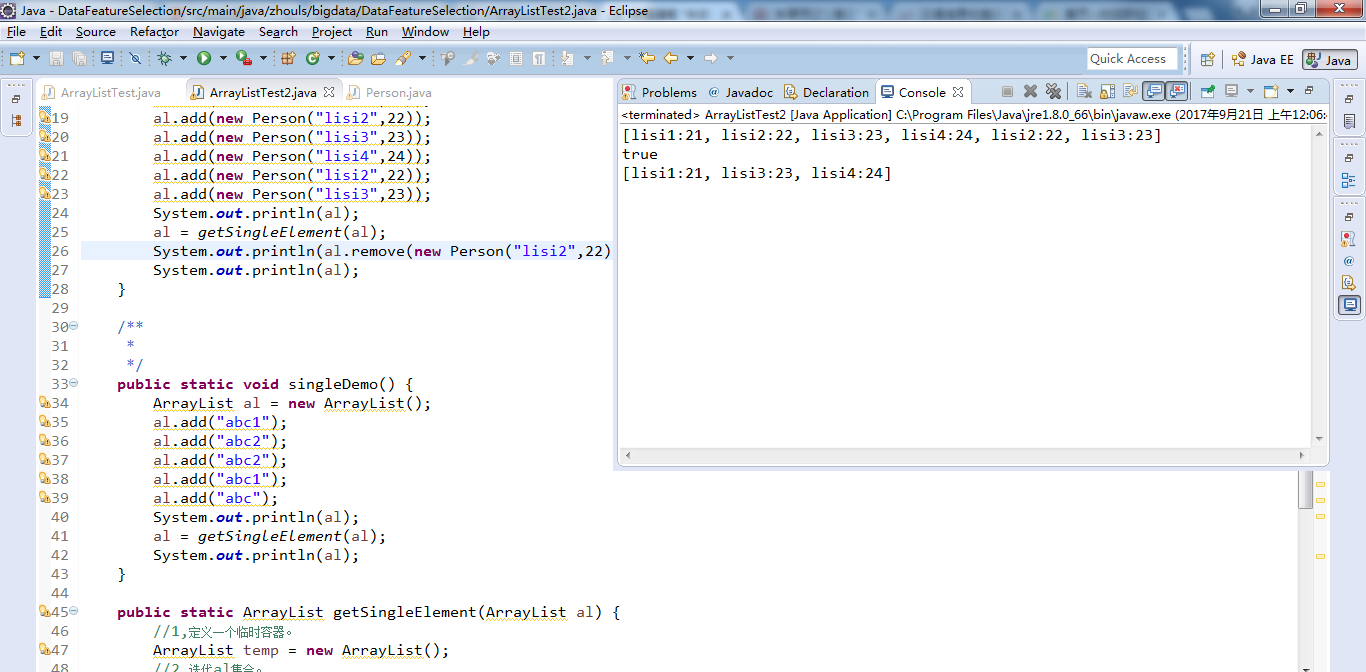
ArrayListTest2.java
package zhouls.bigdata.DataFeatureSelection; import java.util.ArrayList; import java.util.Iterator; import zhouls.bigdata.DataFeatureSelection.Person; /* * 定义功能去除ArrayList中的重复元素。 */ public class ArrayListTest2 { /** * @param args */ public static void main(String[] args) { // demo(); // singleDemo(); ArrayList al = new ArrayList(); al.add(new Person("lisi1",21)); al.add(new Person("lisi2",22)); al.add(new Person("lisi3",23)); al.add(new Person("lisi4",24)); al.add(new Person("lisi2",22)); al.add(new Person("lisi3",23)); System.out.println(al); al = getSingleElement(al); System.out.println(al.remove(new Person("lisi2",22))); System.out.println(al); } /** * */ public static void singleDemo() { ArrayList al = new ArrayList(); al.add("abc1"); al.add("abc2"); al.add("abc2"); al.add("abc1"); al.add("abc"); System.out.println(al); al = getSingleElement(al); System.out.println(al); } public static ArrayList getSingleElement(ArrayList al) { //1,定义一个临时容器。 ArrayList temp = new ArrayList(); //2,迭代al集合。 Iterator it = al.iterator(); while(it.hasNext()){ Object obj = it.next(); //3,判断被迭代到的元素是否在临时容器存在。 if(!temp.contains(obj)){ temp.add(obj); } } return temp; } /** * */ public static void demo() { // al.add(5);//al.add(new Integer(5)); } }
Set集合概述
Set集合中的元素是无序, 不可以重复的, Set接口的方法和Collection中的方法一致
注意: Set集合取出元素的方法只有迭代器。
常用的实现类有是HashSet和TreeSet
应用场景: 假设要存储的元素必须是唯一的, 这个时候就可以使用Set集合
Set:元素不可以重复,是无序。
Set接口中的方法和Collection一致。
|--HashSet: 内部数据结构是哈希表 ,是无序不能排序,是不同步的。
如何保证该集合的元素唯一性呢?
是通过对象的hashCode和equals方法来完成对象唯一性的。
如果对象的hashCode值不同,那么不用判断equals方法,就直接存储到哈希表中。
如果对象的hashCode值相同,那么要再次判断对象的equals方法是否为true。
如果为true,视为相同元素,不存。如果为false,那么视为不同元素,就进行存储。
记住:如果元素要存储到HashSet集合中,必须覆盖hashCode方法和equals方法。
一般情况下,如果定义的类会产生很多对象,比如人,学生,书,通常都需要覆盖equals,hashCode方法。
建立对象判断是否相同的依据。
hash是一种算法,很多存储起来,就是hash表。
|--TreeSet:可以对Set集合中的元素进行排序。是不同步的。
判断元素唯一性的方式:就是根据比较方法的返回结果是否是0,是0,就是相同元素,不存。
TreeSet对元素进行排序的方式一:
让元素自身具备比较功能,元就需要实现Comparable接口。覆盖compareTo方法。
如果不要按照对象中具备的自然顺序进行排序。如果对象中不具备自然顺序。怎么办?
可以使用TreeSet集合第二种排序方式二:
让集合自身具备比较功能,定义一个类实现Comparator接口,覆盖compare方法。
将该类对象作为参数传递给TreeSet集合的构造函数。


比如,ab的hash值是5.
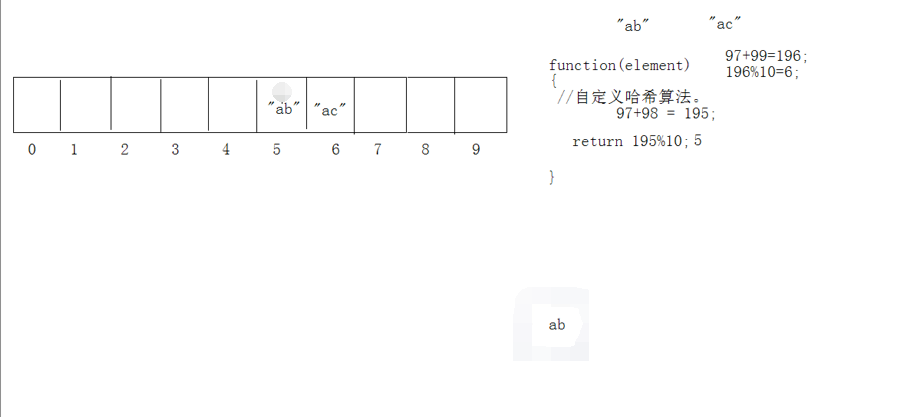
Set接口中常用的类HashSet、TreeSet
HashSet: 底层数据结构是哈希表。 哈希表这种结构, 其实就是对哈希值的存储。 线程不安全, 存取速度快。 它是如何保证元素唯一性的呢?
TreeSet: 可以对Set集合中的元素进行排序。 底层数据结构是二叉树结构,
这种结构, 可以提高排序性能。 线程不安全的。 它的排序是如何进行的呢?
HashSetDemo.java

package zhouls.bigdata.DataFeatureSelection; import java.util.HashSet; import java.util.Iterator; public class HashSetDemo { /** * @param args */ public static void main(String[] args) { HashSet hs = new HashSet(); hs.add("hehe"); // hs.add("heihei"); hs.add("hahah"); hs.add("xixii"); hs.add("hehe"); Iterator it = hs.iterator(); while(it.hasNext()){ System.out.println(it.next()); } } }
同时,也看出来,set的确是保证唯一性,保证里面的元素不能重复。 hehe没进去。
HashSet集合数据结构是哈希表,所以存储元素的时候,使用的元素的hashCode方法来确定位置,如果位置相同,再通过元素的equals来确定是否相同。
Set集合元素唯一性原因
HashSet: 通过equals方法和hashCode 方法来保证元素的唯一性。
TreeSet: 通过compareTo或者compare 方法中的来保证元素的唯一性。 元素是以二叉树的形式存放的。
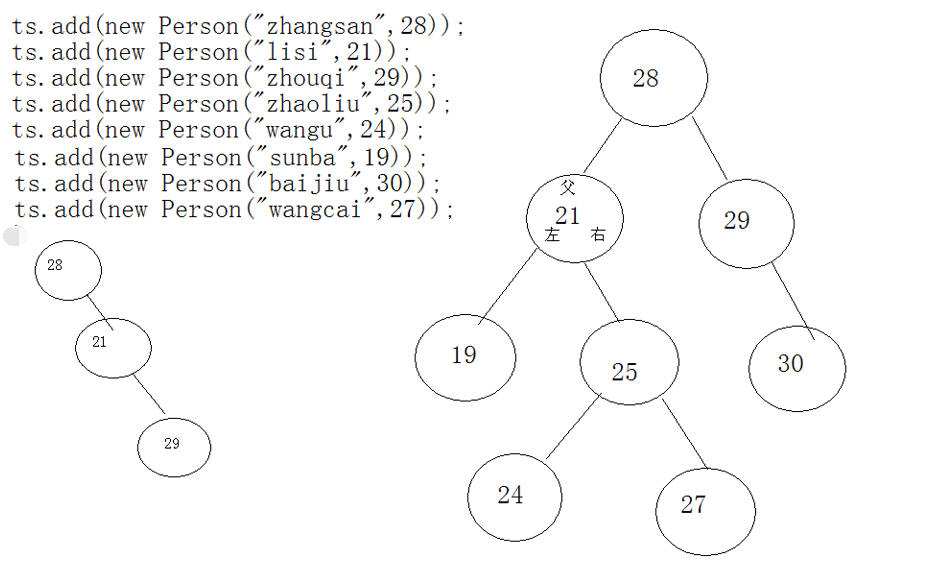
ArrayList和HashSet判断重复总结
ArrayList: 判断包含, 以及删除, 都是依据元素的equals方法
HashSet, 判断包含, 以及删除, 都是依据元素的hashCode方法, 当hashCode相同时, 再判断一次equals方法
Treeset添加排序功能
在向里面添加自定义对象的时候, 需要指定这个对象的排序方式。 让这个对象具有可比较性, 否则会报错。 ClassCastException。
第一种: 自定义类, 要想要被treeset排序, 就需要实现Comparable接口, 实现里面的compareTo方法
第二种: 将一个实现了comparetor接口的子类对象作为参数传递给treeset集合中的构造函数, 这时该集合就具备了比较功能。
Person.java
package zhouls.bigdata.DataFeatureSelection; public class Person /*extends Object*/ implements Comparable { private String name; private int age; public Person() { super(); } public Person(String name, int age) { super(); this.name = name; this.age = age; } public int hashCode() { // System.out.println(this+".......hashCode"); return name.hashCode()+age*27; // return 100; } public boolean equals(Object obj) { if(this == obj) return true; if(!(obj instanceof Person)) throw new ClassCastException("类型错误"); // System.out.println(this+"....equals....."+obj); Person p = (Person)obj; return this.name.equals(p.name) && this.age == p.age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String toString(){ return name+":"+age; } public int compareTo(Object o) { Person p = (Person)o; int temp = this.age-p.age; return temp==0?this.name.compareTo(p.name):temp; // int temp = this.name.compareTo(p.name); // return temp==0?this.age-p.age:temp; /* if(this.age>p.age) return 1; if(this.age<p.age) return -1; else{ return this.name.compareTo(p.name); } */ } }
ComparatorByLength.java
package zhouls.bigdata.DataFeatureSelection; import java.util.Comparator; public class ComparatorByLength implements Comparator { public int compare(Object o1, Object o2) { String s1 = (String)o1; String s2 = (String)o2; int temp = s1.length()-s2.length(); return temp==0 ? s1.compareTo(s2) : temp; } }
ComparatorByName.java
package zhouls.bigdata.DataFeatureSelection; import java.util.Comparator; /** * 创建了一个根据Person类的name进行排序的比较器。 */ public class ComparatorByName implements Comparator { public int compare(Object o1, Object o2) { Person p1 = (Person)o1; Person p2 = (Person)o2; int temp = p1.getName().compareTo(p2.getName()); return temp==0 ? p1.getAge()-p2.getAge() : temp; // return 1;//有序。 } }
TreeSetDemo.java
package zhouls.bigdata.DataFeatureSelection; import java.util.Iterator; import java.util.TreeSet; public class TreeSetDemo { /** * @param args */ public static void main(String[] args) { TreeSet ts = new TreeSet(new ComparatorByName()); /* * 以Person对象年龄进行从小到大的排序。 * */ ts.add(new Person("zhangsan",28)); ts.add(new Person("lisi",21)); ts.add(new Person("zhouqi",29)); ts.add(new Person("zhaoliu",25)); ts.add(new Person("wangu",24)); Iterator it = ts.iterator(); while(it.hasNext()){ Person p = (Person)it.next(); System.out.println(p.getName()+":"+p.getAge()); } } /** * */ public static void demo1() { TreeSet ts = new TreeSet(); ts.add("abc"); ts.add("zaa"); ts.add("aa"); ts.add("nba"); ts.add("cba"); Iterator it = ts.iterator(); while(it.hasNext()){ System.out.println(it.next()); } } }
总结
TreeSet排序方式有两种。
1, 让元素自身具备比较性。
其实是让元素实现Comparable接口, 覆盖compareTo方法。这称为元素的自然排序。
2, 当元素自身不具备比较性, 或者元素具备的比较性不是所需要的,可以让集合自身具备比较性。
定义一个比较器: 其实就是定义一个类, 实现Comparator接口。 覆盖compare方法。
将Comparator接口的子类对象作为参数传递给TreeSet的构造函数。
LinkedHashSet
元素存入和取出的顺序一致。 是一个有序的集合, 不需要我们自己实现排序功能
集合框架中的Collection集合总结
ArrayList: 基于数组,不同步,查询较快
LinkedList:基于链表,不同步,查询较慢,增删较快
HashSet: 哈希表
TreeSet: 二叉树
看到array就要想到数组, 就要想到角标, 想到查询很快。
看到link就要想到链表, 就要想到增删很快, 最高再想到addFirst
看到hash就要想到哈希表, 就要想到元素的hashcode方法和equals方法
看到tree, 就要想到二叉树, 就要想到排序, 就要想到两个接口, comparable和comparator
什么时候用List, 什么时候用Set
保证元素唯一, 就用Set集合。不需要就使用List集合。
实在搞不清楚, 就用ArrayList
三、集合框架中的Map
Map与Collection在集合框架中属并列存在。Map是一次添加一对元素(存储的是夫妻,哈哈)。Collection是一次添加一个元素(存储的是光棍,哈哈)。
Map存储的是键值对。
Map存储元素使用put方法, Collection使用add方法。
Map集合没有直接取出元素的方法, 而是先转成Set集合, 再通过迭代获取元素。
Map集合中键要保证唯一性。
以下,就是Map集合没有直接取出元素的方法, 而是先转成Set集合, 再通过迭代获取元素。
MapDemo.java
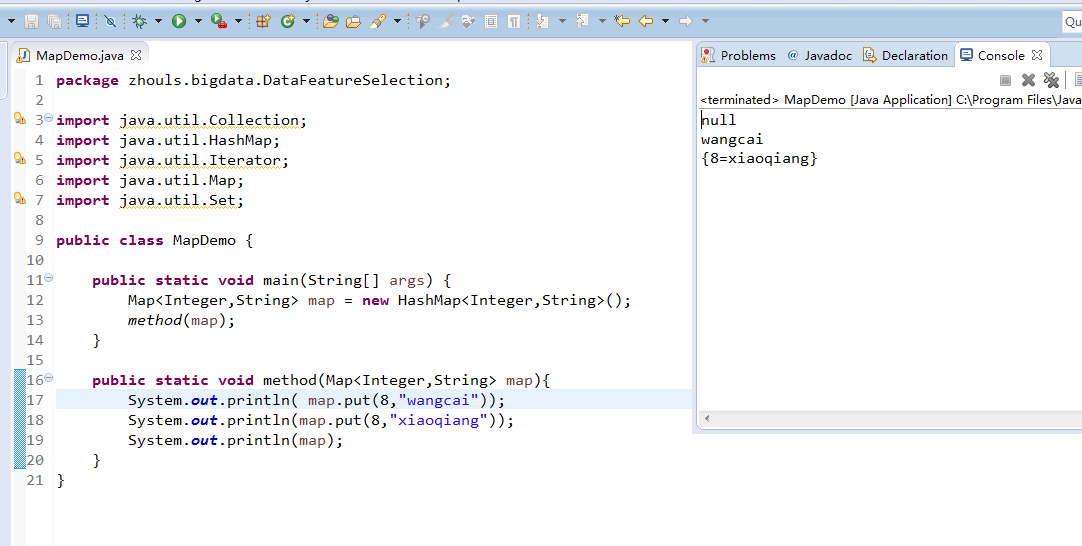
package zhouls.bigdata.DataFeatureSelection; import java.util.Collection; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class MapDemo { public static void main(String[] args) { Map<Integer,String> map = new HashMap<Integer,String>(); method(map); } public static void method(Map<Integer,String> map){ System.out.println(map.put(8,"wangcai"));//null 把8看作丈夫,wangcai看作妻子。这里返回的是前妻,对于丈夫8来说,是新婚,所以返回null System.out.println(map.put(8,"xiaoqiang"));//wangcai 把8看作丈夫,xiaoqiang看作妻子。这里返回的是前妻,对于丈夫8来说,是wangcai System.out.println(map);//{8=xiaoqiang} } }
即,存相同键,则值会覆盖。
继续修改,MapDemo.java

package zhouls.bigdata.DataFeatureSelection; import java.util.Collection; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class MapDemo { public static void main(String[] args) { Map<Integer,String> map = new HashMap<Integer,String>(); method(map); } public static void method(Map<Integer,String> map){ System.out.println(map.put(8,"wangcai"));//null 把8看作丈夫,wangcai看作妻子。这里返回的是前妻,对于丈夫8来说,是新婚,所以返回null System.out.println(map.put(8,"xiaoqiang"));//wangcai 把8看作丈夫,xiaoqiang看作妻子。这里返回的是前妻 ,对于丈夫8来说,是wangcai map.put(2, "zhangshan"); map.put(7, "zhaoliu"); System.out.println(map);//{2=zhangshan, 7=zhaoliu, 8=xiaoqiang} } }
再修修,MapDemo.java
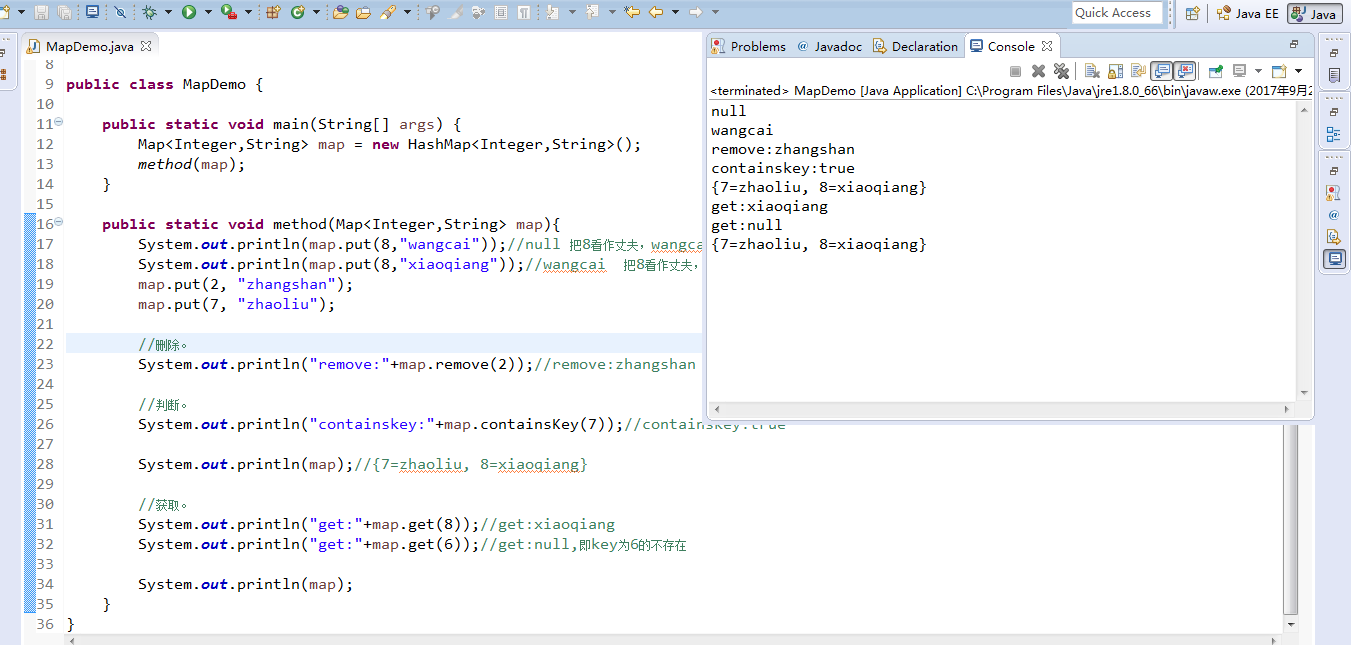
package zhouls.bigdata.DataFeatureSelection; import java.util.Collection; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class MapDemo { public static void main(String[] args) { Map<Integer,String> map = new HashMap<Integer,String>(); method(map); } public static void method(Map<Integer,String> map){ System.out.println(map.put(8,"wangcai"));//null 把8看作丈夫,wangcai看作妻子。这里返回的是前妻,对于丈夫8来说,是新婚,所以返回null System.out.println(map.put(8,"xiaoqiang"));//wangcai 把8看作丈夫,xiaoqiang看作妻子。这里返回的是前妻 ,对于丈夫8来说,是wangcai map.put(2, "zhangshan"); map.put(7, "zhaoliu"); //删除。 System.out.println("remove:"+map.remove(2));//remove:zhangshan //判断。 System.out.println("containskey:"+map.containsKey(7));//containskey:true System.out.println(map);//{7=zhaoliu, 8=xiaoqiang} //获取。 System.out.println("get:"+map.get(8));//get:xiaoqiang System.out.println("get:"+map.get(6));//get:null,即key为6的不存在 System.out.println(map); } }
再修改,MapDemo.java

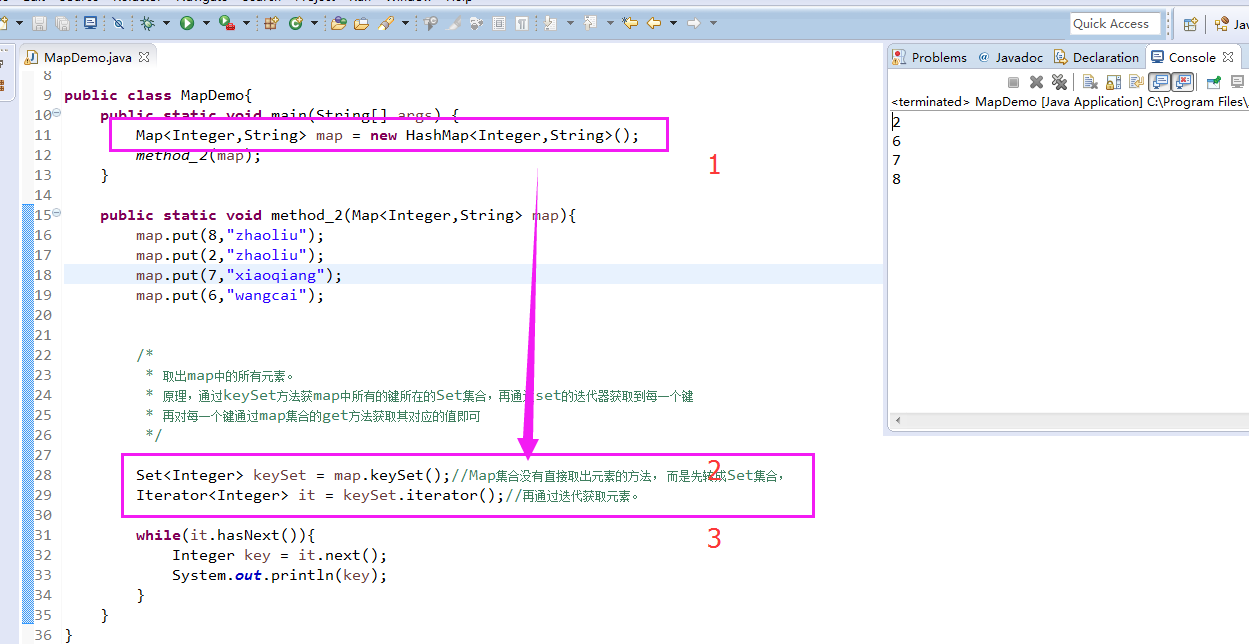
package zhouls.bigdata.DataFeatureSelection; import java.util.Collection; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class MapDemo{ public static void main(String[] args) { Map<Integer,String> map = new HashMap<Integer,String>(); method_2(map); } public static void method_2(Map<Integer,String> map){ map.put(8,"zhaoliu"); map.put(2,"zhaoliu"); map.put(7,"xiaoqiang"); map.put(6,"wangcai"); /* * 取出map中的所有元素。 * 原理,通过keySet方法获map中所有的键所在的Set集合,再通过set的迭代器获取到每一个键 * 再对每一个键通过map集合的get方法获取其对应的值即可 */ Set<Integer> keySet = map.keySet();//Map集合没有直接取出元素的方法, 而是先转成Set集合, Iterator<Integer> it = keySet.iterator();//再通过迭代获取元素。 while(it.hasNext()){ Integer key = it.next(); System.out.println(key); } } }
再修改,MapDemo.java(非常重要,必须要理解)(里面有keySet)
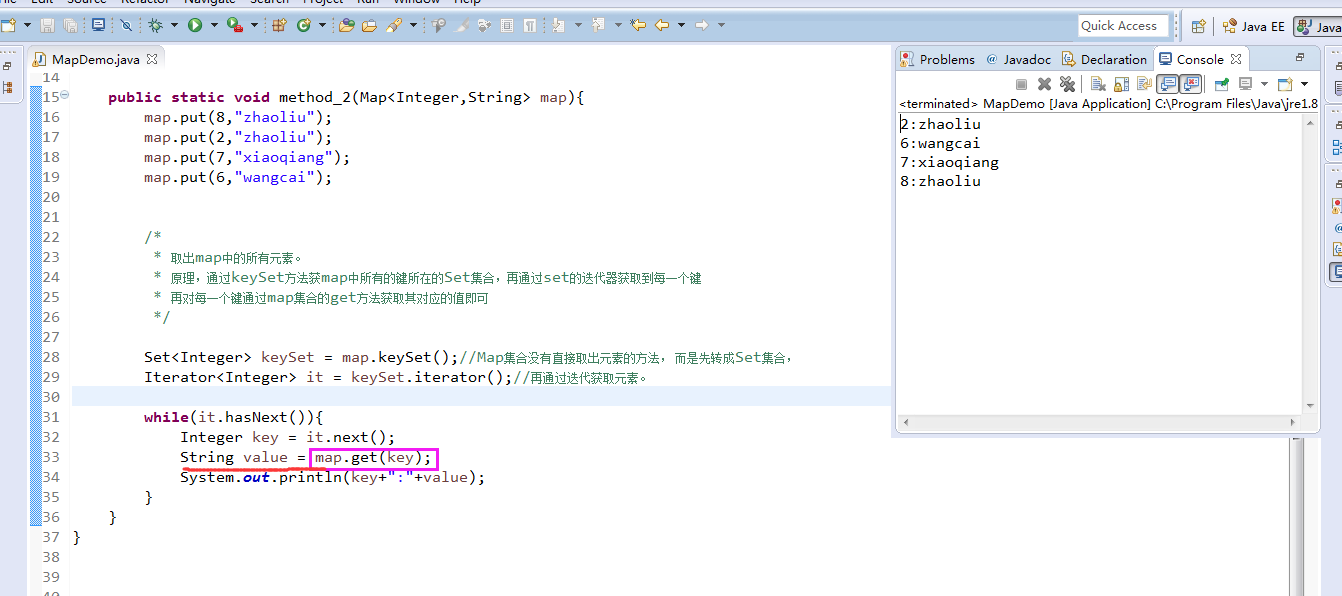
package zhouls.bigdata.DataFeatureSelection; import java.util.Collection; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class MapDemo{ public static void main(String[] args) { Map<Integer,String> map = new HashMap<Integer,String>(); method_2(map); } public static void method_2(Map<Integer,String> map){ map.put(8,"zhaoliu"); map.put(2,"zhaoliu"); map.put(7,"xiaoqiang"); map.put(6,"wangcai"); /* * 取出map中的所有元素。 * 原理,通过keySet方法获map中所有的键所在的Set集合,再通过set的迭代器获取到每一个键 * 再对每一个键通过map集合的get方法获取其对应的值即可 */ Set<Integer> keySet = map.keySet();//Map集合没有直接取出元素的方法, 而是先转成Set集合, Iterator<Integer> it = keySet.iterator();//再通过迭代获取元素。 while(it.hasNext()){ Integer key = it.next(); String value = map.get(key); System.out.println(key+":"+value); } } }
keySet是所有键的集合
MapDemo.java(里面有entrySet)
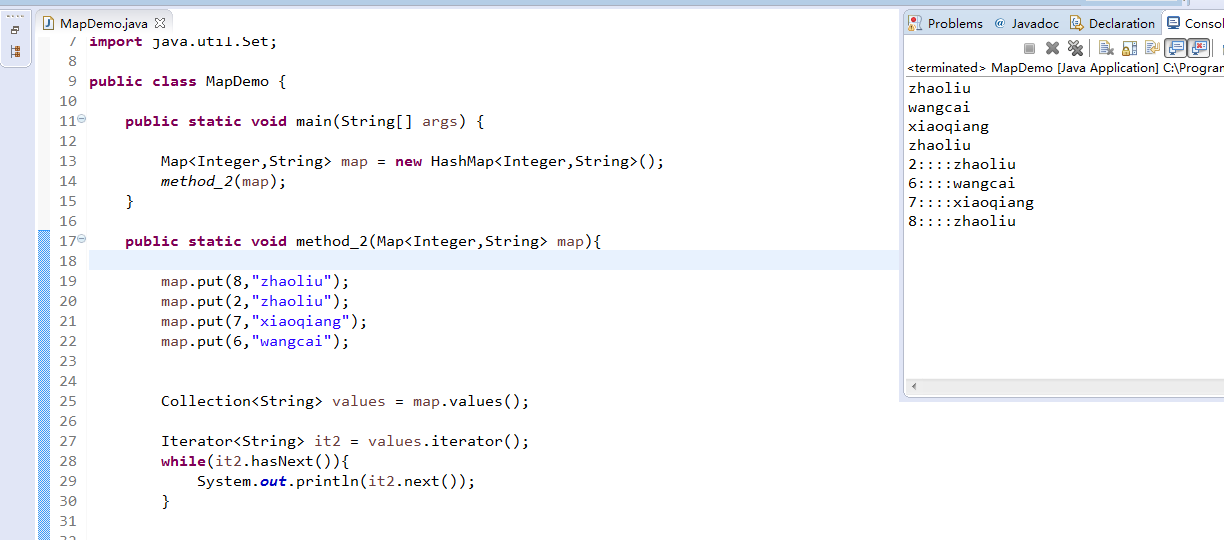
package zhouls.bigdata.DataFeatureSelection; import java.util.Collection; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class MapDemo { public static void main(String[] args) { Map<Integer,String> map = new HashMap<Integer,String>(); method_2(map); } public static void method_2(Map<Integer,String> map){ map.put(8,"zhaoliu"); map.put(2,"zhaoliu"); map.put(7,"xiaoqiang"); map.put(6,"wangcai"); Collection<String> values = map.values(); Iterator<String> it2 = values.iterator(); while(it2.hasNext()){ System.out.println(it2.next()); } /* * 通过Map转成set就可以迭代。 * 找到了另一个方法。entrySet。 * 该方法将键和值的映射关系作为对象存储到了Set集合中,而这个映射关系的类型就是Map.Entry类型(结婚证) */ Set<Map.Entry<Integer, String>> entrySet = map.entrySet(); Iterator<Map.Entry<Integer, String>> it = entrySet.iterator(); while(it.hasNext()){ Map.Entry<Integer, String> me = it.next(); Integer key = me.getKey(); String value = me.getValue(); System.out.println(key+"::::"+value); } //取出map中的所有元素。 //原理,通过keySet方法获取map中所有的键所在的Set集合,在通过Set的迭代器获取到每一个键, //在对每一个键通过map集合的get方法获取其对应的值即可。 /* Set<Integer> keySet = map.keySet(); Iterator<Integer> it = keySet.iterator(); while(it.hasNext()){ Integer key = it.next(); String value = map.get(key); System.out.println(key+":"+value); } */ } public static void method(Map<Integer,String> map){//学号和姓名 // 添加元素。 System.out.println(map.put(8, "wangcai"));//null System.out.println(map.put(8, "xiaoqiang"));//wangcai 存相同键,值会覆盖。 map.put(2,"zhangsan"); map.put(7,"zhaoliu"); //删除。 // System.out.println("remove:"+map.remove(2)); //判断。 // System.out.println("containskey:"+map.containsKey(7)); //获取。 System.out.println("get:"+map.get(6)); System.out.println(map); Outer.Inner.show(); } } interface MyMap{ public static interface MyEntry{//内部接口 void get(); } } class MyDemo implements MyMap.MyEntry{ public void get(){} } class Outer{ static class Inner{ static void show(){} } }
Map集合常用类Hashtable、HashMap、TreeMap
Hashtable: 线程安全, 速度慢, 不允许存放null键, null值, 已被HashMap替代。
HashMap: 线程不安全, 速度快, 允许存放null键, null值。
TreeMap: 对键进行排序, 排序原理与TreeSet相同。
Hashtable :内部结构是哈希表,是同步的。不允许null作为键,null作为值。
Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
HashMap : 内部结构是哈希表,不是同步的。允许null作为键,null作为值。
TreeMap : 内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
HashMap根据键的HashCode值存放数据。
HashMap与Hashtable都采用了hash法进行索引。
HashMap是Hashtable的轻量级实现,HashMap允许空(null)键值(key)(但需要注意,最多只运行一条记录的键为null,不允许多条记录的值为null),而Hashtable不允许。
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。Hashtable继承自Dictionary类 ,而HashMap是Map接口的一个实现
Hashtable的方法是线程安全的,而HashMap不支持线程的同步,所以它不是线程安全的。
Hashtable使用Enumeration,HashMap使用Iterator。
Hashtable和HashMap采用的hash/rehash算法都几乎一样。
HashMap里面存入的键值对在取出时没有固定的顺序,是随机的。
TreeMap实现了SortMap接口,键是排序的。

HashMapDemo.java
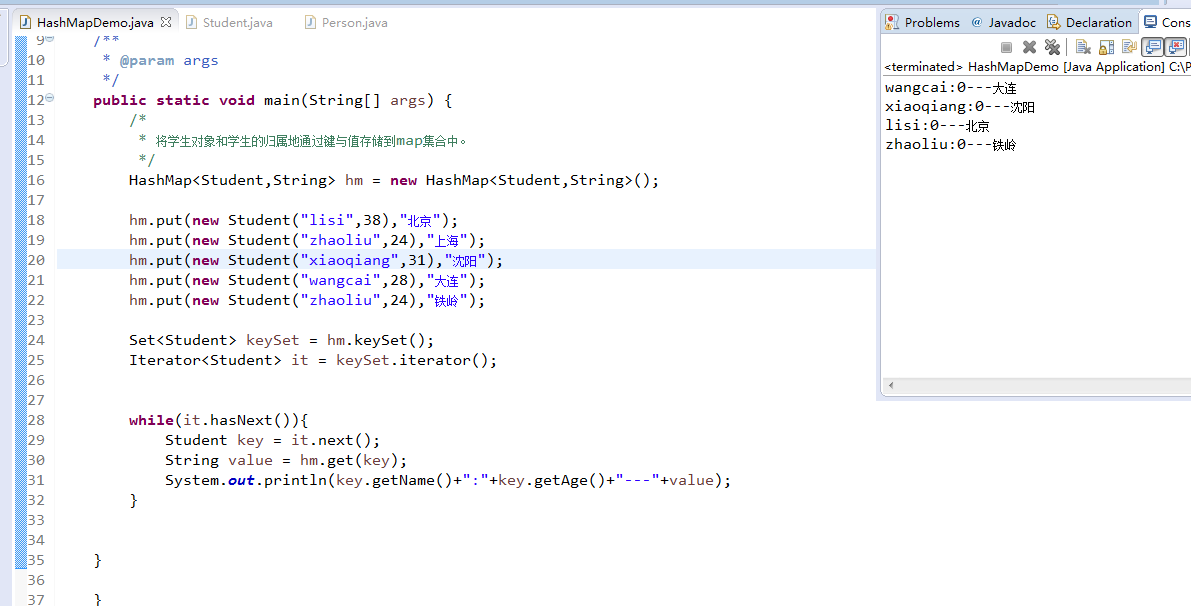
package zhouls.bigdata.DataFeatureSelection; import java.util.HashMap; import java.util.Iterator; import java.util.Set; public class HashMapDemo { /** * @param args */ public static void main(String[] args) { /* * 将学生对象和学生的归属地通过键与值存储到map集合中。 */ HashMap<Student,String> hm = new HashMap<Student,String>(); hm.put(new Student("lisi",38),"北京"); hm.put(new Student("zhaoliu",24),"上海"); hm.put(new Student("xiaoqiang",31),"沈阳"); hm.put(new Student("wangcai",28),"大连"); hm.put(new Student("zhaoliu",24),"铁岭"); Set<Student> keySet = hm.keySet(); Iterator<Student> it = keySet.iterator(); while(it.hasNext()){ Student key = it.next(); String value = hm.get(key); System.out.println(key.getName()+":"+key.getAge()+"---"+value); } } }
Student.java
package zhouls.bigdata.DataFeatureSelection; public class Student extends Person { public Student() { super(); } public Student(String name, int age) { super(name, age); } @Override public String toString() { return "Student:"+getName()+":"+getAge(); } public int getAge() { // TODO Auto-generated method stub return 0; } }
Person.java
package zhouls.bigdata.DataFeatureSelection; public class Person implements Comparable<Person> { private String name; private int age; public Person() { super(); } public Person(String name, int age) { super(); this.name = name; this.age = age; } public int compareTo(Person p){ // Person p = (Person)obj; int temp = this.age - p.age; return temp==0?this.name.compareTo(p.name):temp; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + age; result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Person other = (Person) obj; if (age != other.age) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; return true; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Person:"+getName()+":"+getAge(); } }
HashMapDemo.java,再次修改。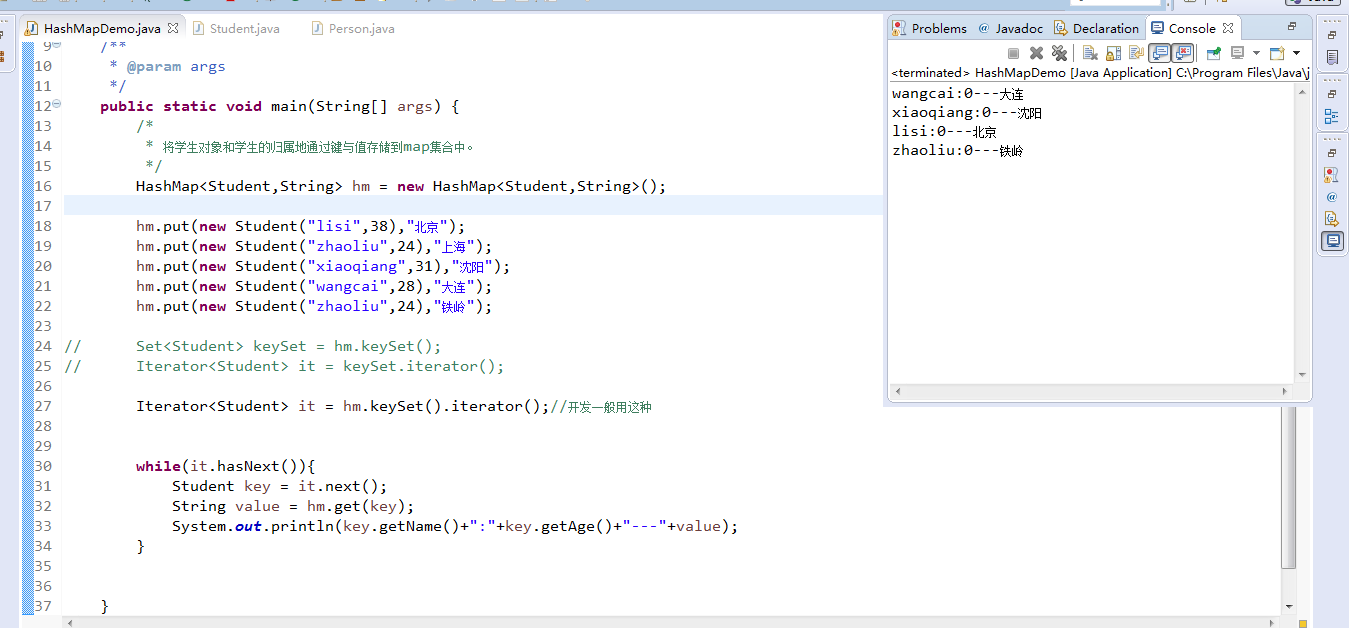
继续。。。。
Map的两种取值方式keySet、entrySet
keySet
先获取所有键的集合, 再根据键获取对应的值。(即先找到丈夫,去找妻子)
entrySet
先获取map中的键值关系封装成一个个的entry对象, 存储到一个Set集合中,再迭代这个Set集合, 根据entry获取对应的key和value。
向集合中存储自定义对象 (entry类似于是结婚证)
keySet的演示图解:

entrySet的演示图解:
LinkedHashMap
这个是HashMap的子类
可以实现存入顺序和取出顺序一致 。
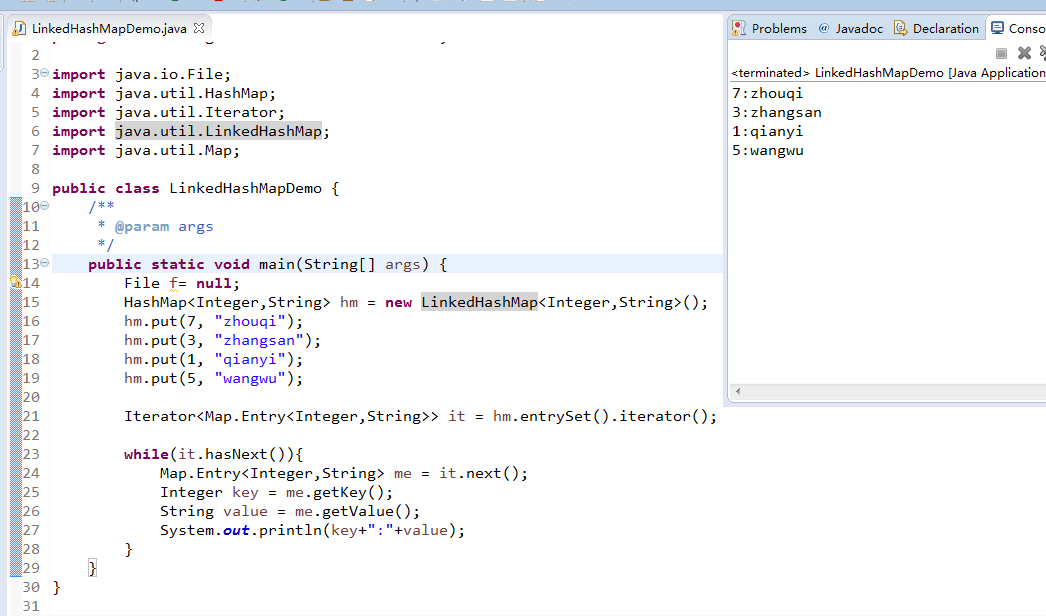
LinkedHashMapDemo.java
package zhouls.bigdata.DataFeatureSelection; import java.io.File; import java.util.HashMap; import java.util.Iterator; import java.util.LinkedHashMap; import java.util.Map; public class LinkedHashMapDemo { /** * @param args */ public static void main(String[] args) { File f= null; HashMap<Integer,String> hm = new LinkedHashMap<Integer,String>(); hm.put(7, "zhouqi"); hm.put(3, "zhangsan"); hm.put(1, "qianyi"); hm.put(5, "wangwu"); Iterator<Map.Entry<Integer,String>> it = hm.entrySet().iterator(); while(it.hasNext()){ Map.Entry<Integer,String> me = it.next(); Integer key = me.getKey(); String value = me.getValue(); System.out.println(key+":"+value); } } }
map-values方法
可以获取map中的所有value的一个集合。
集合的一些技巧:
需要唯一吗?
需要:Set
需要制定顺序:
需要: TreeSet
不需要:HashSet
但是想要一个和存储一致的顺序(有序):LinkedHashSet
不需要:List
需要频繁增删吗?
需要:LinkedList
不需要:ArrayList
如何记录每一个容器的结构和所属体系呢?
看名字!
List
|--ArrayList
|--LinkedList
Set
|--HashSet
|--TreeSet
后缀名就是该集合所属的体系。
前缀名就是该集合的数据结构。
看到array:就要想到数组,就要想到查询快,有角标.
看到link:就要想到链表,就要想到增删快,就要想要 add get remove+frist last的方法
看到hash:就要想到哈希表,就要想到唯一性,就要想到元素需要覆盖hashcode方法和equals方法。
看到tree:就要想到二叉树,就要想要排序,就要想到两个接口Comparable,Comparator 。
而且通常这些常用的集合容器都是不同步的。
1:Set集合(理解) (1)Set集合的特点 无序,唯一 (2)HashSet集合(掌握) A:底层数据结构是哈希表(是一个元素为链表的数组) B:哈希表底层依赖两个方法:hashCode()和equals() 执行顺序: 首先比较哈希值是否相同 相同:继续执行equals()方法 返回true:元素重复了,不添加 返回false:直接把元素添加到集合 不同:就直接把元素添加到集合 C:如何保证元素唯一性的呢? 由hashCode()和equals()保证的 D:开发的时候,代码非常的简单,自动生成即可。 E:HashSet存储字符串并遍历 F:HashSet存储自定义对象并遍历(对象的成员变量值相同即为同一个元素) (3)TreeSet集合 A:底层数据结构是红黑树(是一个自平衡的二叉树) B:保证元素的排序方式 a:自然排序(这种排序方式可以理解成元素本身具备比较性) 让元素所属的类实现Comparable接口 b:比较器排序(这种排序可以理解成集合类具备比较性) 让集合构造方法接收Comparator的实现类对象,实现方式可以用匿名类来实现。 C:把我们讲过的代码看一遍即可 (4)案例: A:获取无重复的随机数 B:键盘录入学生按照总分从高到底输出 2:Collection集合总结(掌握) Collection |--List 有序,可重复 |--ArrayList 底层数据结构是数组,查询快,增删慢。 线程不安全,效率高 |--Vector 底层数据结构是数组,查询快,增删慢。 线程安全,效率低 |--LinkedList 底层数据结构是链表,查询慢,增删快。 线程不安全,效率高 |--Set 无序,唯一 |--HashSet 底层数据结构是哈希表。 如何保证元素唯一性的呢? 依赖两个方法:hashCode()和equals() 开发中自动生成这两个方法即可 |--LinkedHashSet 底层数据结构是链表和哈希表 由链表保证元素有序 由哈希表保证元素唯一 |--TreeSet 底层数据结构是红黑树。 如何保证元素排序的呢? 自然排序 比较器排序 如何保证元素唯一性的呢? 根据比较的返回值是否是0来决定 3:针对Collection集合我们到底使用谁呢?(掌握) 唯一吗? 是:Set 排序吗? 是:TreeSet 否:HashSet 如果你知道是Set,但是不知道是哪个Set,就用HashSet。 否:List 要安全吗? 是:Vector 否:ArrayList或者LinkedList 查询多:ArrayList 增删多:LinkedList 如果你知道是List,但是不知道是哪个List,就用ArrayList。 如果你知道是Collection集合,但是不知道使用谁,就用ArrayList。 如果你知道用集合,就用ArrayList。 4:在集合中常见的数据结构(掌握) ArrayXxx:底层数据结构是数组,查询快,增删慢 LinkedXxx:底层数据结构是链表,查询慢,增删快 HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals() TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序