我这里,
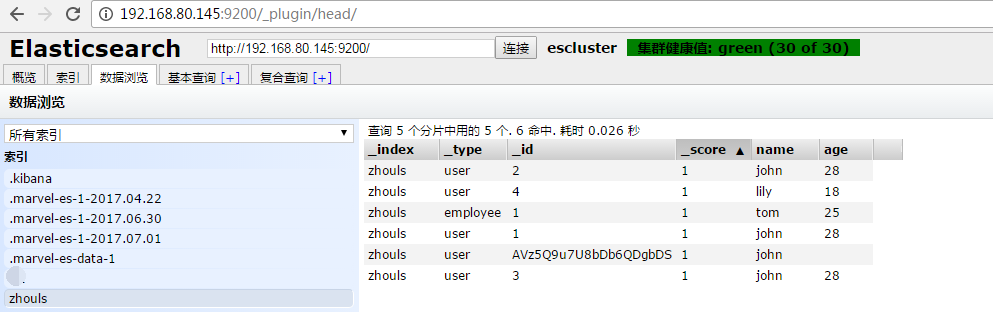
再,创建一个zhouls2的索引库。

[hadoop@master elasticsearch-2.4.0]$ curl -XPUT 'http://master:9200/zhouls2/' {"acknowledged":true}[hadoop@master elasticsearch-2.4.0]$ [hadoop@master elasticsearch-2.4.0]$
得到
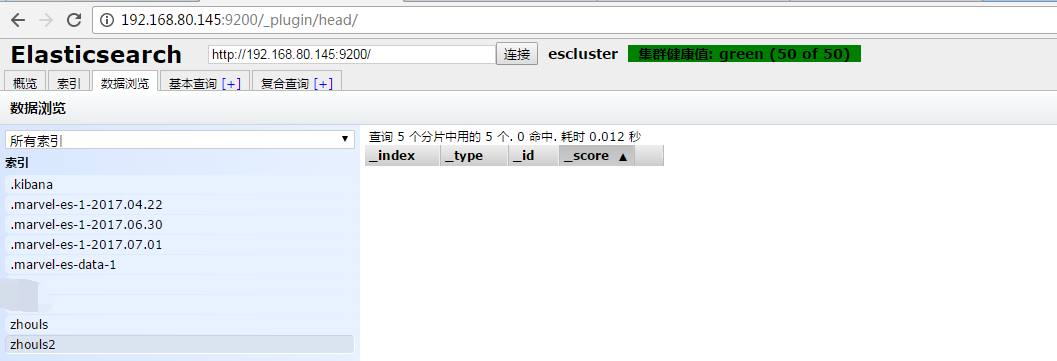
在新创建的索引库zhouls2里,添加一条数据进去。
[hadoop@master elasticsearch-2.4.0]$ curl -XPOST http://master:9200/zhouls2/user/1 -d '{"name" : "lucy" , "age" : 18}' {"_index":"zhouls2","_type":"user","_id":"1","_version":1,"_shards":{"total":2,"successful":2,"failed":0},"created":true}[hadoop@master elasticsearch-2.4.0]$ [hadoop@master elasticsearch-2.4.0]$ [hadoop@master elasticsearch-2.4.0]$
得到
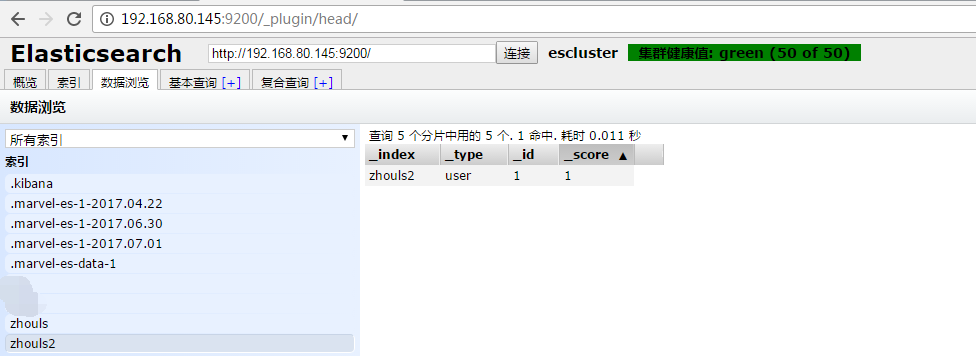
如下,是我用mget命令,为大家演示,通过xmget命令来获取多个文档
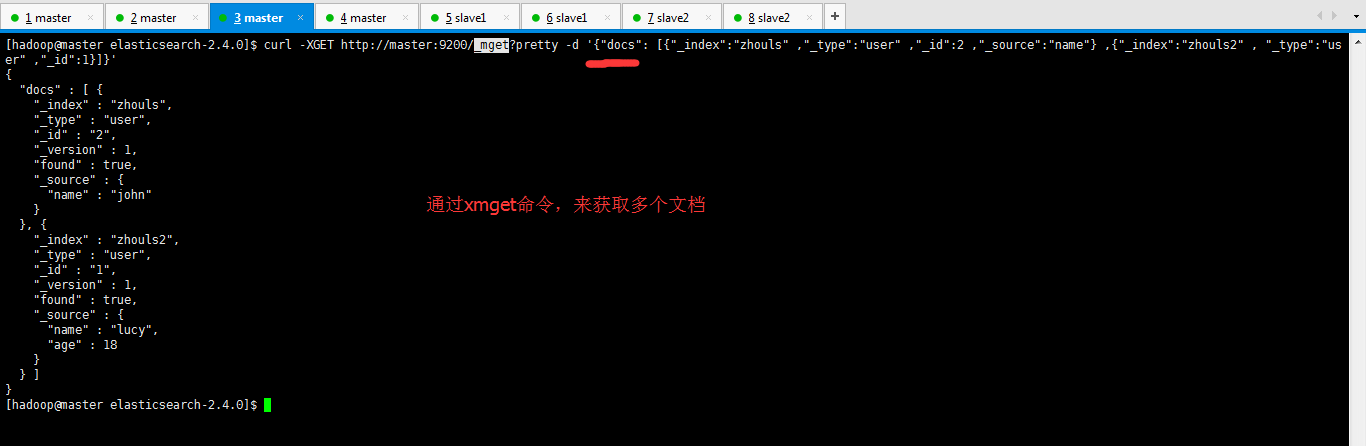
[hadoop@master elasticsearch-2.4.0]$ curl -XGET http://master:9200/_mget?pretty -d '{"docs": [{"_index":"zhouls" ,"_type":"user" ,"_id":2 ,"_source":"name"} ,{"_index":"zhouls2" , "_type":"user" ,"_id":1}]}' { "docs" : [ { "_index" : "zhouls", "_type" : "user", "_id" : "2", "_version" : 1, "found" : true, "_source" : { "name" : "john" } }, { "_index" : "zhouls2", "_type" : "user", "_id" : "1", "_version" : 1, "found" : true, "_source" : { "name" : "lucy", "age" : 18 } } ] } [hadoop@master elasticsearch-2.4.0]$
如果我们需要的文档在同一个_index或者同一个_type中,我们就可以在URL中指定一个默认的/_index或者_index/_type。
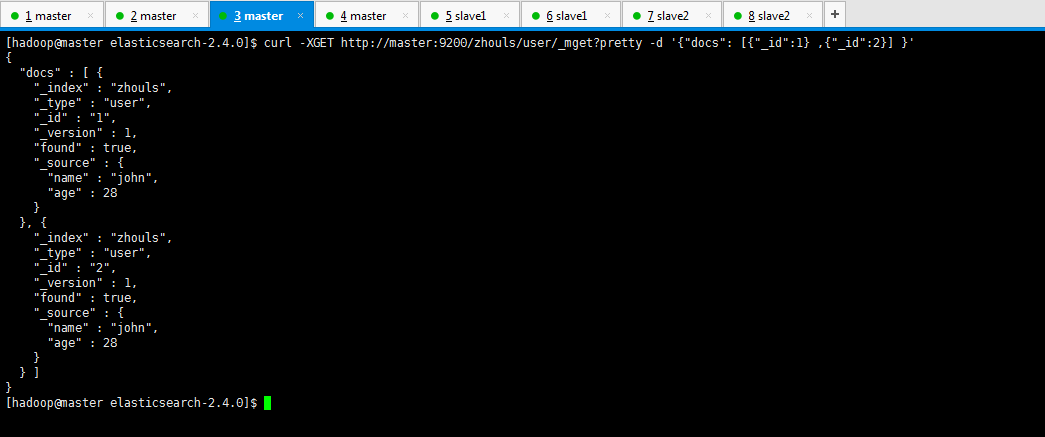
[hadoop@master elasticsearch-2.4.0]$ curl -XGET http://master:9200/zhouls/user/_mget?pretty -d '{"docs": [{"_id":1} ,{"_id":2}] }' { "docs" : [ { "_index" : "zhouls", "_type" : "user", "_id" : "1", "_version" : 1, "found" : true, "_source" : { "name" : "john", "age" : 28 } }, { "_index" : "zhouls", "_type" : "user", "_id" : "2", "_version" : 1, "found" : true, "_source" : { "name" : "john", "age" : 28 } } ] } [hadoop@master elasticsearch-2.4.0]$
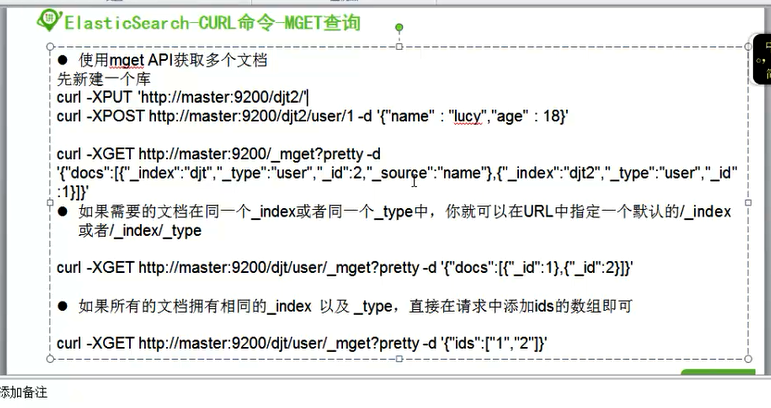
如果我们的文档拥有相同的_index以及_type,直接在请求中添加ids的数组即可
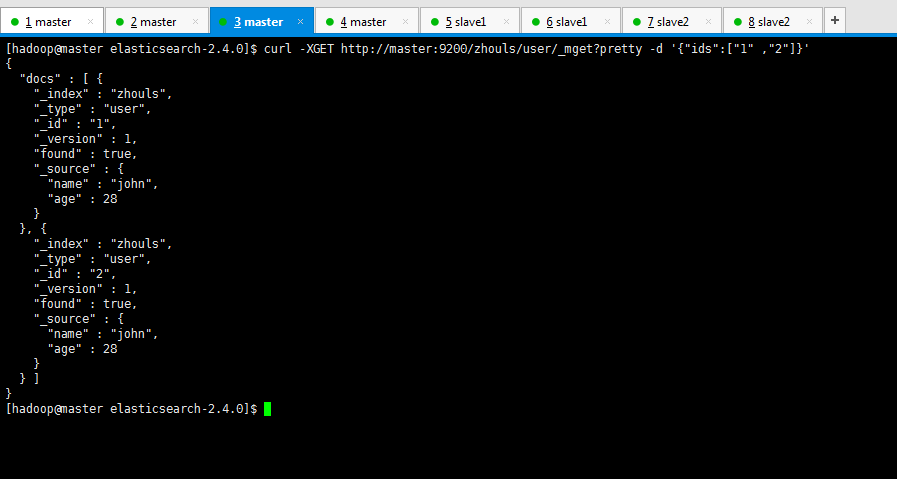
[hadoop@master elasticsearch-2.4.0]$ curl -XGET http://master:9200/zhouls/user/_mget?pretty -d '{"ids":["1" ,"2"]}' { "docs" : [ { "_index" : "zhouls", "_type" : "user", "_id" : "1", "_version" : 1, "found" : true, "_source" : { "name" : "john", "age" : 28 } }, { "_index" : "zhouls", "_type" : "user", "_id" : "2", "_version" : 1, "found" : true, "_source" : { "name" : "john", "age" : 28 } } ] } [hadoop@master elasticsearch-2.4.0]$
更多,请见