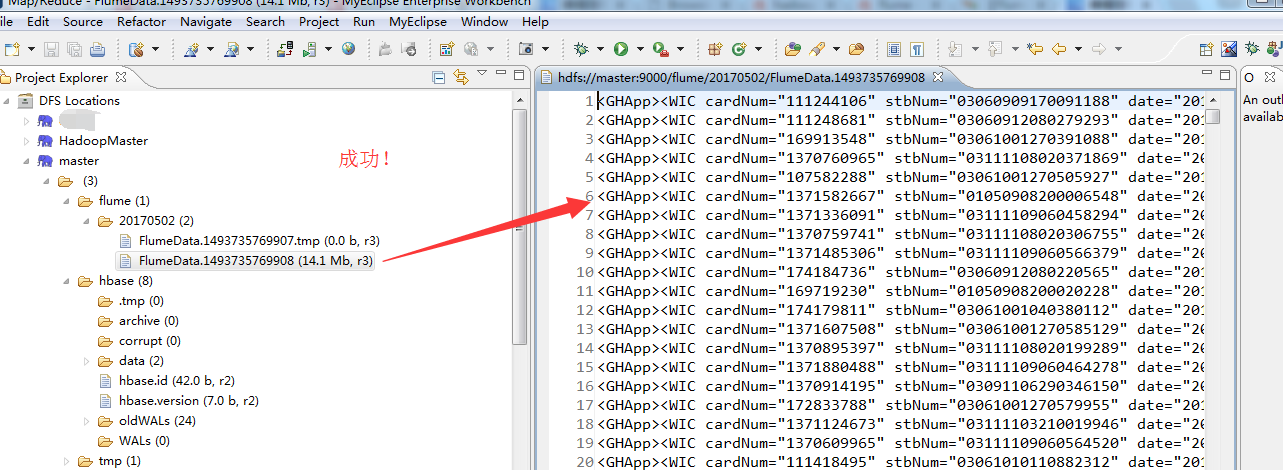
问题描述


解决办法
先把这个hdfs目录下的数据删除。并修改配置文件flume-conf.properties,重新采集。
# Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, # software distributed under the License is distributed on an # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY # KIND, either express or implied. See the License for the # specific language governing permissions and limitations # under the License. # The configuration file needs to define the sources, # the channels and the sinks. # Sources, channels and sinks are defined per agent, # in this case called 'agent' agent1.sources = spool-source1 agent1.sinks = hdfs-sink1 agent1.channels = ch1 #Define and configure an Spool directory source agent1.sources.spool-source1.channels=ch1 agent1.sources.spool-source1.type=spooldir agent1.sources.spool-source1.spoolDir=/home/hadoop/data/flume/sqooldir/73/2012-09-22/ agent1.sources.spool-source1.ignorePattern=event(_d{4}-d{2}-d{2}\_d{2}\_d{2})?.log(.COMPLETED)? agent1.sources.spool-source1.deserializer.maxLineLength=10240 #Configure channel agent1.channels.ch1.type = file agent1.channels.ch1.checkpointDir = /home/hadoop/data/flume/checkpointDir agent1.channels.ch1.dataDirs = /home/hadoop/data/flume/dataDirs #Define and configure a hdfs sink agent1.sinks.hdfs-sink1.channel = ch1 agent1.sinks.hdfs-sink1.type = hdfs agent1.sinks.hdfs-sink1.hdfs.path = hdfs://master:9000/flume/%Y%m%d agent1.sinks.hdfs-sink1.hdfs.useLocalTimeStamp = true agent1.sinks.hdfs-sink1.hdfs.rollInterval = 60 agent1.sinks.hdfs-sink1.hdfs.rollSize = 0 agent1.sinks.hdfs-sink1.hdfs.rollCount = 0 agent1.sinks.hdfs-sink1.hdfs.minBlockReplicas=1 agent1.sinks.hdfs-sink1.hdfs.idleTimeout=0 #agent1.sinks.hdfs-sink1.hdfs.codeC = snappy agent1.sinks.hdfs-sink1.hdfs.fileType=DataStream #agent1.sinks.hdfs-sink1.hdfs.writeFormat=Text # For each one of the sources, the type is defined #agent.sources.seqGenSrc.type = seq # The channel can be defined as follows. #agent.sources.seqGenSrc.channels = memoryChannel # Each sink's type must be defined #agent.sinks.loggerSink.type = logger #Specify the channel the sink should use #agent.sinks.loggerSink.channel = memoryChannel # Each channel's type is defined. #agent.channels.memoryChannel.type = memory # Other config values specific to each type of channel(sink or source) # can be defined as well # In this case, it specifies the capacity of the memory channel #agent.channels.memoryChannel.capacity = 100
教大家一招:大家在这些如flume的配置文件,最好还是去看官网,学会扩展,别只局限于别人的博客的文档,当然可以作为参考。关键还是来源于官方!
[hadoop@master sqooldir]$ $HADOOP_HOME/bin/hadoop fs -rm -r /flume/20170502 17/05/02 21:53:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 17/05/02 21:53:17 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /flume/20170502 [hadoop@master sqooldir]$





重新开启flume

[hadoop@master flume]$ pwd /home/hadoop/app/flume [hadoop@master flume]$ bin/flume-ng agent -n agent1 -f conf/flume-conf.properties



如果你的问题,还有副本数的问题,自行去解决。将$HADOOP_HOME/etc/hadoop/下的hdfs-site.xml的属性(master、slave1和slave2都要修改)
<property>
<name>dfs.replication</name>
<value>3</value>
<description>Set to 1 for pseudo-distributed mode,Set to 2 for distributed mode,Set to 3 for distributed mode.</description>
</property>
记得重启hadoop集群。