Tachyon实战应用
-
配置及启动环境
-
修改spark-env.sh
-
启动HDFS
-
启动Tachyon
-
-
Tachyon上运行Spark
-
添加core-site.xml
-
启动Spark集群
-
读取文件并保存
-
-
Tachyon运行MapReduce
-
修改core-site.xml
-
启动YARN
-
运行MapReduce例子
-
1 配置及启动环境
1.1.1 修改spark-env.sh
修改$SPARK_HOME/conf目录下spark-env.sh文件:
$cd /app/hadoop/spark-1.1.0/conf $vi spark-env.sh
在该配置文件中添加如下内容:
export SPARK_CLASSPATH=/app/hadoop/tachyon-0.5.0/client/target/tachyon-client-0.5.0-jar-with-dependencies.jar:$SPARK_CLASSPATH

1.1.2 启动HDFS
$cd /app/hadoop/hadoop-2.2.0/sbin $./start-dfs.sh
1.1.3 启动Tachyon
在这里使用SudoMout参数,需要在启动过程中输入hadoop的密码,具体过程如下:
$cd /app/hadoop/tachyon-0.5.0/bin $./tachyon-start.sh all SudoMount
1.2 Tachyon上运行Spark
1.2.1 添加core-site.xml
在Tachyon的官方文档说Hadoop1.X集群需要添加该配置文件(参见http://tachyon-project.org/documentation/Running-Spark-on-Tachyon.html),实际在Hadoop2.2.0集群测试的过程中发现也需要添加如下配置文件,否则无法识别以tachyon://开头的文件系统,具体操作是在$SPARK_HOME/conf目录下创建core-site.xml文件
$cd /app/hadoop/spark-1.1.0/conf $touch core-site.xml
$vi core-site.xml
在该配置文件中添加如下内容:
<configuration>
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>
</configuration>

1.2.2 启动Spark集群
$cd /app/hadoop/spark-1.1.0/sbin $./start-all.sh
1.2.3 读取文件并保存
第一步 准备测试数据文件
使用Tachyon命令行准备测试数据文件
$cd /app/hadoop/tachyon-0.5.0/bin $./tachyon tfs copyFromLocal ../conf/tachyon-env.sh /tachyon-env.sh $./tachyon tfs ls /

第二步 启动Spark-Shell
$cd /app/hadoop/spark-1.1.0/bin $./spark-shell
第三步 对测试数据文件进行计数并另存
对前面放入到Tachyon文件系统的文件进行计数
scala>val s = sc.textFile("tachyon://hadoop1:19998/tachyon-env.sh") scala>s.count()


把前面的测试文件另存为tachyon-env-bak.sh文件
scala>s.saveAsTextFile("tachyon://hadoop1:19998/tachyon-env-bak.sh")

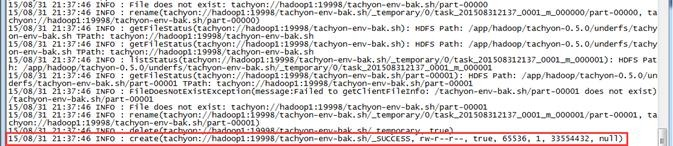
第四步 在Tachyon的UI界面查看
可以查看到该文件在Tachyon文件系统中保存成tahyon-env-bak.sh文件夹
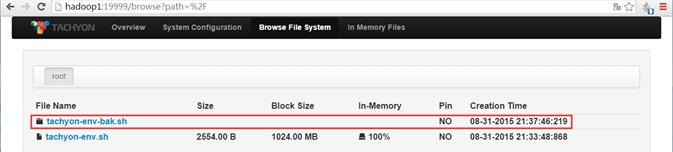
该文件夹中包含两个文件,分别为part-00000和part-00001:

其中tahyon-env-bak.sh/part-0001文件中内容如下:

另外通过内存存在文件的监控页面可以观测到,这几个操作文件在内存中:
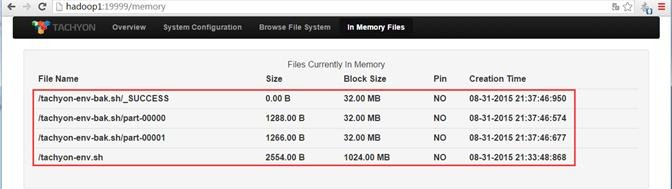
1.3 Tachyon运行MapReduce
1.3.1 修改core-site.xml
该配置文件为$Hadoop_HOME/conf目录下的core-site.xml文件
$cd /app/hadoop/hadoop-2.2.0/etc/hadoop $vi core-site.xml
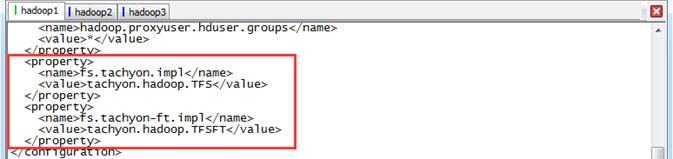
修改core-site.xml文件配置,添加如下配置项:
<property> <name>fs.tachyon.impl</name> <value>tachyon.hadoop.TFS</value> </property> <property> <name>fs.tachyon-ft.impl</name> <value>tachyon.hadoop.TFSFT</value> </property>
1.3.2 启动YARN
$cd /app/hadoop/hadoop-2.2.0/sbin $./start-yarn.sh
1.3.3 运行MapReduce例子
第一步 创建结果保存目录
$cd /app/hadoop/hadoop-2.2.0/bin $./hadoop fs -mkdir /class10
第二步 运行MapReduce例子
$cd /app/hadoop/hadoop-2.2.0/bin $./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount -libjars $TACHYON_HOME/client/target/tachyon-client-0.5.0-jar-with-dependencies.jar tachyon://hadoop1:19998/tachyon-env.sh hdfs://hadoop1:9000/class10/output
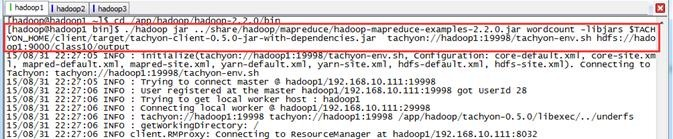

第三步 查看结果
查看HDFS,可以看到在/class10中创建了output目录
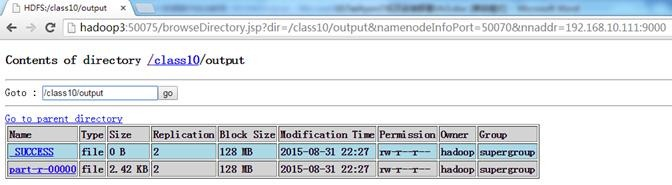
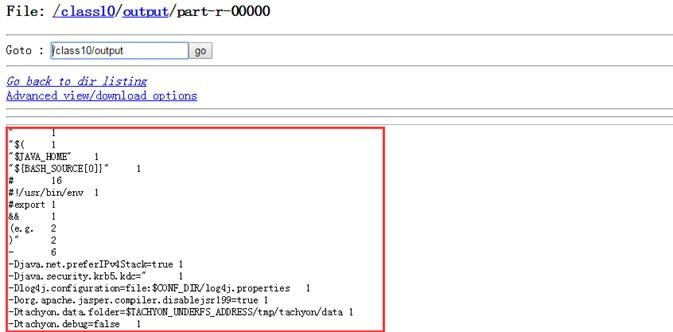
查看part-r-0000文件内容,为tachyon-env.sh单词计数