这篇博客,给大家,体会不一样的版本编程。
是将map、combiner、shuffle、reduce等分开放一个.java里。则需要实现Tool。
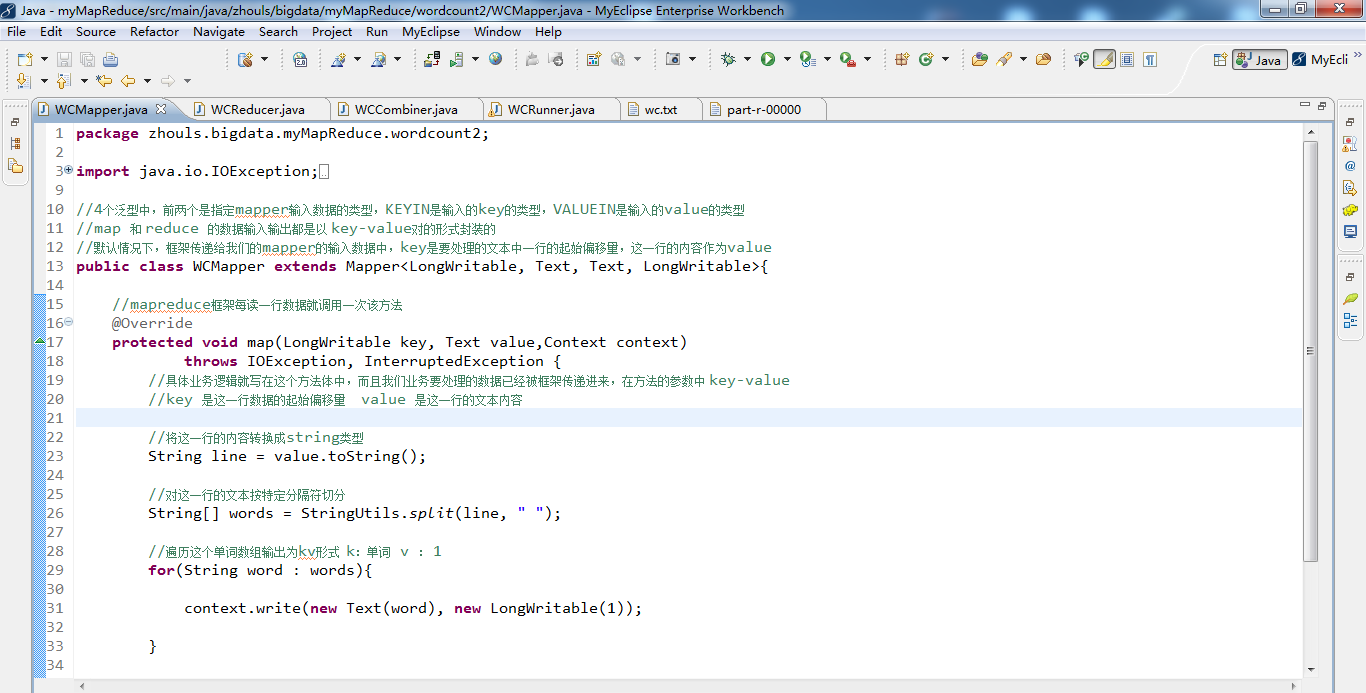
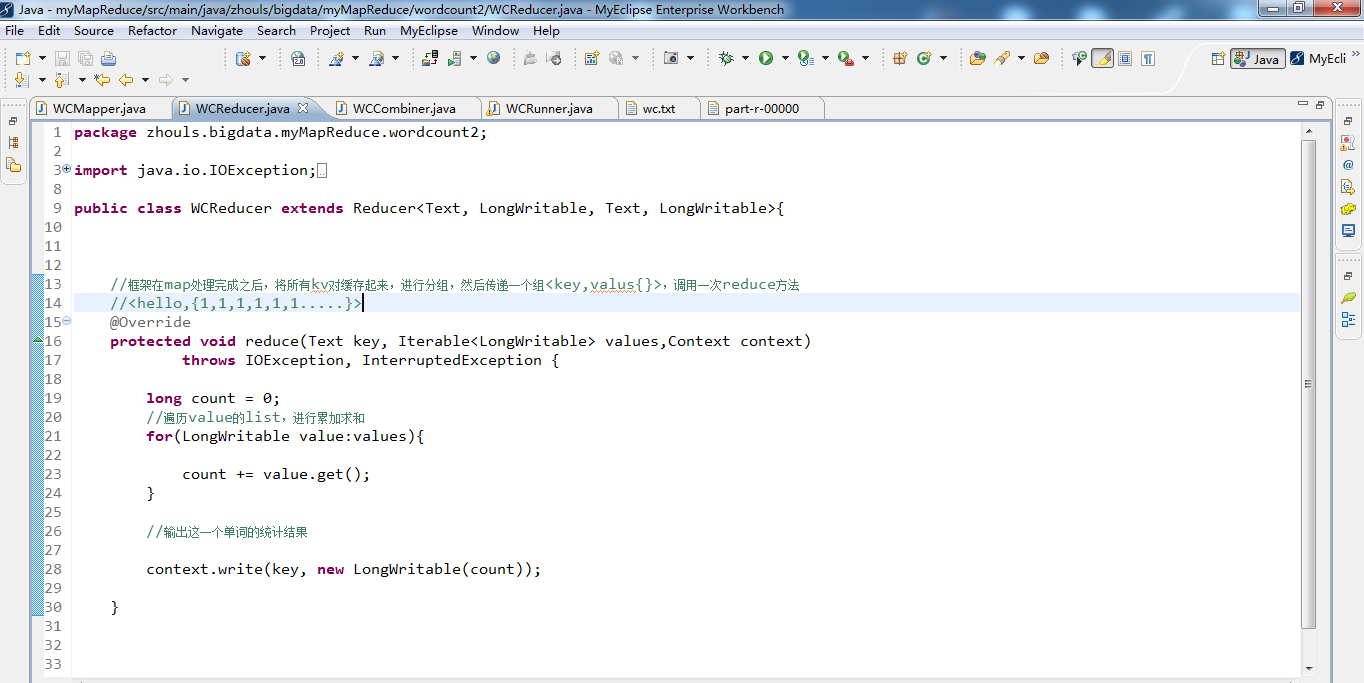
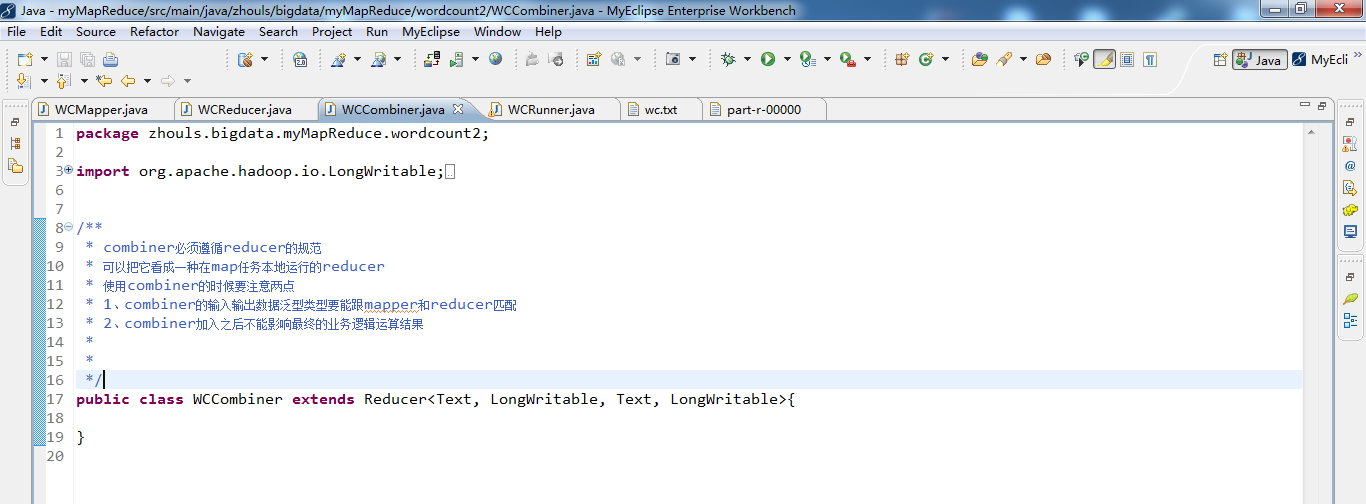
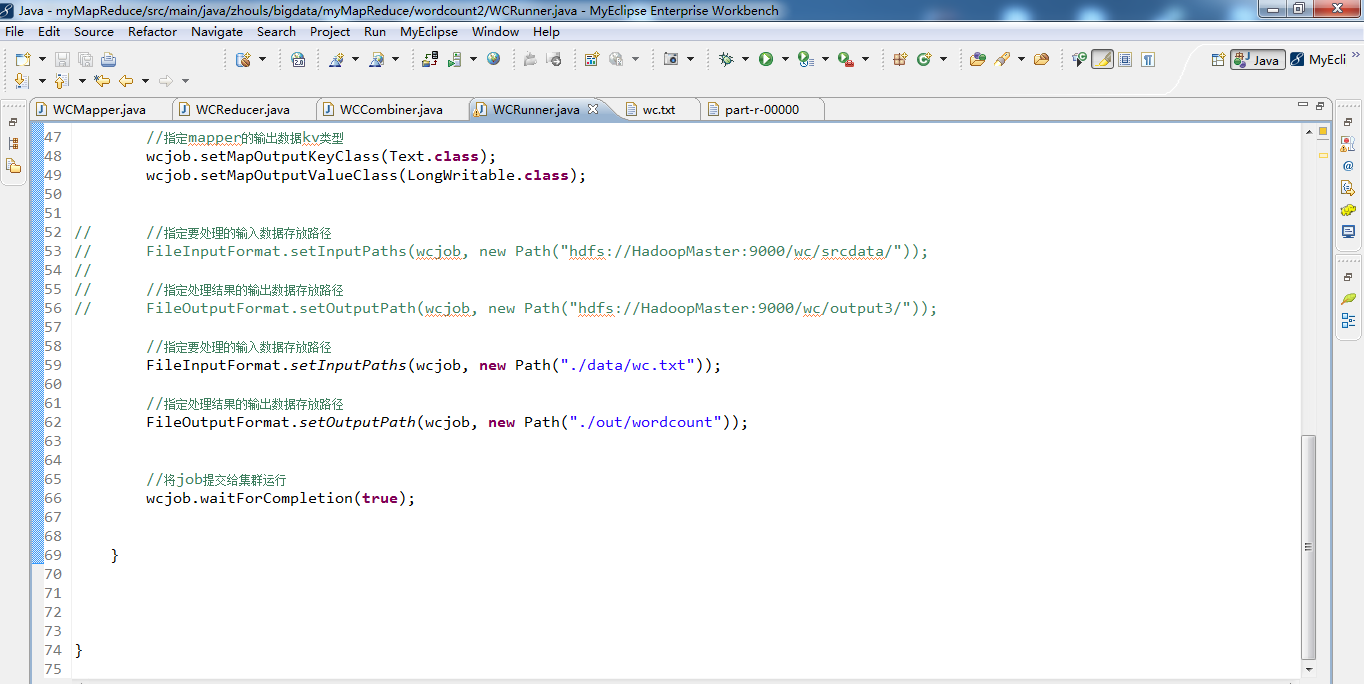
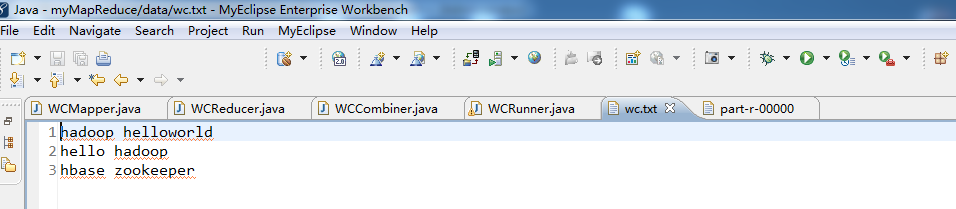
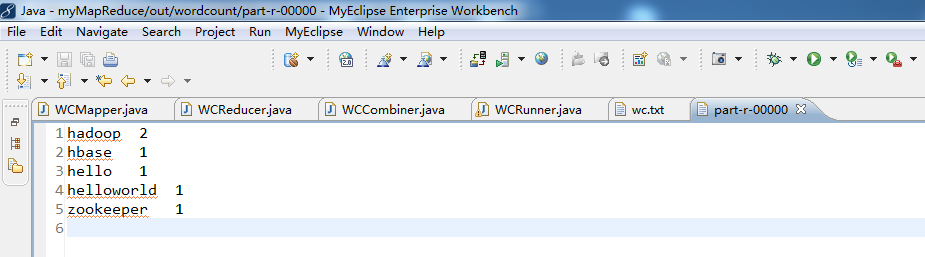
代码
1 package zhouls.bigdata.myMapReduce.wordcount2; 2 3 import java.io.IOException; 4 5 import org.apache.commons.lang.StringUtils; 6 import org.apache.hadoop.io.LongWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Mapper; 9 10 //4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的类型 11 //map 和 reduce 的数据输入输出都是以 key-value对的形式封装的 12 //默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value 13 public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ 14 15 //mapreduce框架每读一行数据就调用一次该方法 16 @Override 17 protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException{ 18 //具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中 key-value 19 //key 是这一行数据的起始偏移量 value 是这一行的文本内容 20 21 //将这一行的内容转换成string类型 22 String line = value.toString(); 23 24 //对这一行的文本按特定分隔符切分 25 //hadoop helloworld 26 String[] words = StringUtils.split(line, " "); 27 28 //遍历这个单词数组输出为kv形式 k:单词 v : 1 29 for(String word : words){//word是k2 30 context.write(new Text(word), new LongWritable(1));//写入word是k2,1是v2 31 // context.write(word,1);等价 32 33 } 34 35 36 } 37 38 39 40 }
1 package zhouls.bigdata.myMapReduce.wordcount2; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Reducer; 8 9 public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ 10 11 12 13 //框架在map处理完成之后,将所有kv对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法 14 //<hello,{1,1,1,1,1,1.....}> 15 @Override 16 protected void reduce(Text key, Iterable<LongWritable> values,Context context)throws IOException, InterruptedException { 17 long count = 0; 18 //遍历value的list,进行累加求和 19 for(LongWritable value:values){//value是v2 20 count += value.get(); 21 } 22 23 //输出这一个单词的统计结果 24 25 context.write(key,new LongWritable(count));//key是k3,count是v3 26 // context.write(key,count); 27 } 28 29 30 31 }
1 package zhouls.bigdata.myMapReduce.wordcount2; 2 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Reducer; 6 7 8 /** 9 * combiner必须遵循reducer的规范 10 * 可以把它看成一种在map任务本地运行的reducer 11 * 使用combiner的时候要注意两点 12 * 1、combiner的输入输出数据泛型类型要能跟mapper和reducer匹配 13 * 2、combiner加入之后不能影响最终的业务逻辑运算结果 14 * 15 * 16 */ 17 public class WCCombiner extends Reducer<Text, LongWritable, Text, LongWritable>{ 18 19 }
1 package zhouls.bigdata.myMapReduce.wordcount2; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 12 13 /** 14 * 用来描述一个特定的作业 15 * 比如,该作业使用哪个类作为逻辑处理中的map,哪个作为reduce 16 * 还可以指定该作业要处理的数据所在的路径 17 * 还可以指定改作业输出的结果放到哪个路径 18 * .... 19 * @author duanhaitao@itcast.cn 20 * 21 */ 22 public class WCRunner { 23 24 public static void main(String[] args) throws Exception { 25 26 Configuration conf = new Configuration(); 27 28 Job wcjob = Job.getInstance(conf); 29 30 //设置整个job所用的那些类在哪个jar包 31 wcjob.setJarByClass(WCRunner.class); 32 33 34 //本job使用的mapper和reducer的类 35 wcjob.setMapperClass(WCMapper.class); 36 wcjob.setReducerClass(WCReducer.class); 37 38 39 //指定本job使用combiner组件,组件所用的类为 40 wcjob.setCombinerClass(WCReducer.class); 41 42 43 //指定reduce的输出数据kv类型 44 wcjob.setOutputKeyClass(Text.class); 45 wcjob.setOutputValueClass(LongWritable.class); 46 47 //指定mapper的输出数据kv类型 48 wcjob.setMapOutputKeyClass(Text.class); 49 wcjob.setMapOutputValueClass(LongWritable.class); 50 51 52 // //指定要处理的输入数据存放路径 53 // FileInputFormat.setInputPaths(wcjob, new Path("hdfs://HadoopMaster:9000/wordcount/wc.txt/")); 54 // 55 // //指定处理结果的输出数据存放路径 56 // FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://HadoopMaster:9000/out/wordcount/wc/")); 57 58 //指定要处理的输入数据存放路径 59 FileInputFormat.setInputPaths(wcjob, new Path("./data/wordcount/wc.txt")); 60 61 //指定处理结果的输出数据存放路径 62 FileOutputFormat.setOutputPath(wcjob, new Path("./out/wordcount/wc/")); 63 64 65 //将job提交给集群运行 66 wcjob.waitForCompletion(true); 67 68 69 } 70 71 72 73 74 }