问题详情是
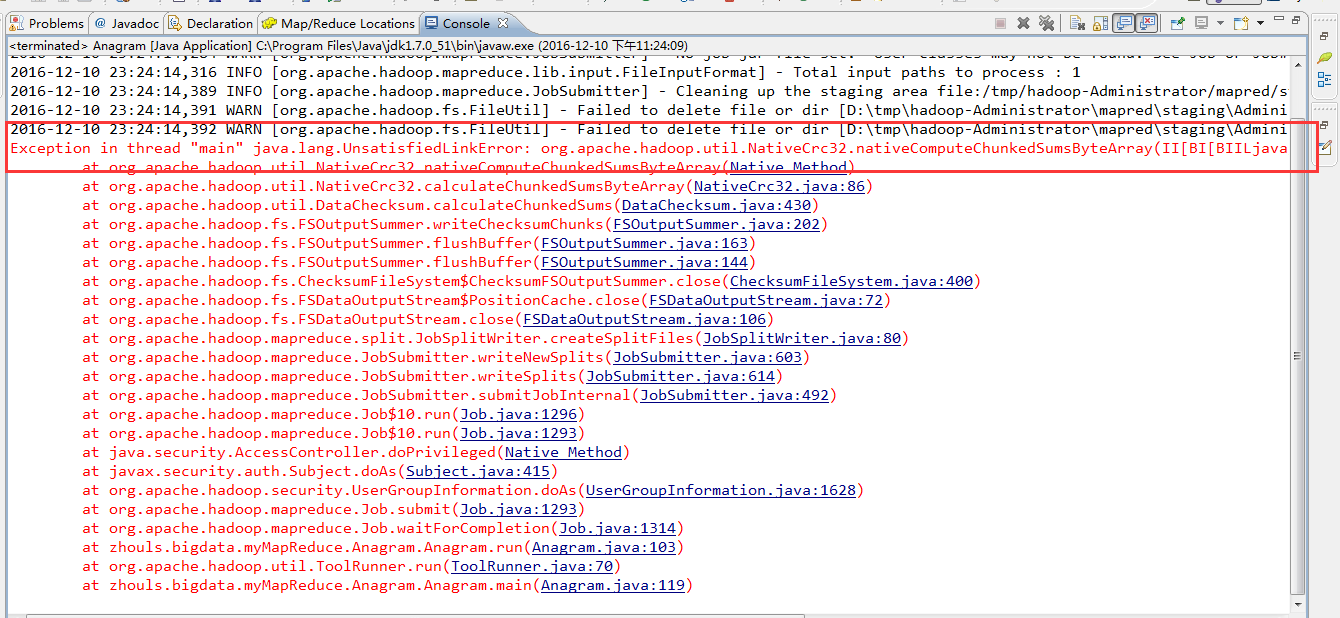
2016-12-10 23:24:13,317 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
2016-12-10 23:24:14,281 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2016-12-10 23:24:14,284 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2016-12-10 23:24:14,316 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 1
2016-12-10 23:24:14,389 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Cleaning up the staging area file:/tmp/hadoop-Administrator/mapred/staging/Administrator2004170506/.staging/job_local2004170506_0001
2016-12-10 23:24:14,391 WARN [org.apache.hadoop.fs.FileUtil] - Failed to delete file or dir [D: mphadoop-AdministratormapredstagingAdministrator2004170506.stagingjob_local2004170506_0001.job.split.crc]: it still exists.
2016-12-10 23:24:14,392 WARN [org.apache.hadoop.fs.FileUtil] - Failed to delete file or dir [D: mphadoop-AdministratormapredstagingAdministrator2004170506.stagingjob_local2004170506_0001job.split]: it still exists.
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
at org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(Native Method)
at org.apache.hadoop.util.NativeCrc32.calculateChunkedSumsByteArray(NativeCrc32.java:86)
at org.apache.hadoop.util.DataChecksum.calculateChunkedSums(DataChecksum.java:430)
at org.apache.hadoop.fs.FSOutputSummer.writeChecksumChunks(FSOutputSummer.java:202)
at org.apache.hadoop.fs.FSOutputSummer.flushBuffer(FSOutputSummer.java:163)
at org.apache.hadoop.fs.FSOutputSummer.flushBuffer(FSOutputSummer.java:144)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSOutputSummer.close(ChecksumFileSystem.java:400)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
at org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:106)
at org.apache.hadoop.mapreduce.split.JobSplitWriter.createSplitFiles(JobSplitWriter.java:80)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:603)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:614)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:492)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1314)
at zhouls.bigdata.myMapReduce.Anagram.Anagram.run(Anagram.java:103)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at zhouls.bigdata.myMapReduce.Anagram.Anagram.main(Anagram.java:119)

这是hadoop-2.6.0版本的

知识点:
2.4之前的和自后的需要的不一样,需要选择正确的版本(包括操作系统的版本)

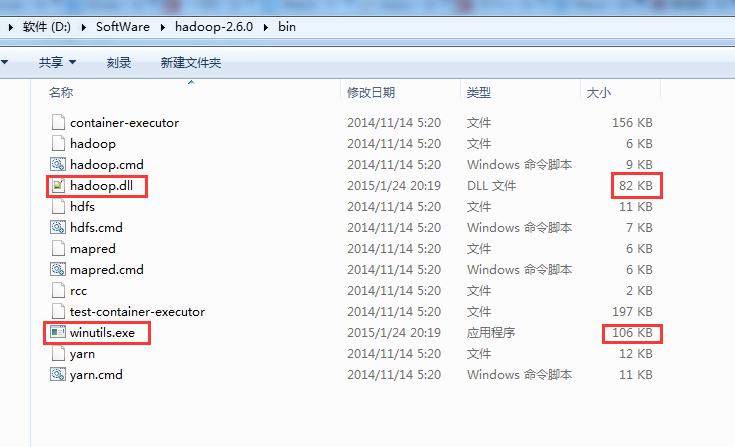
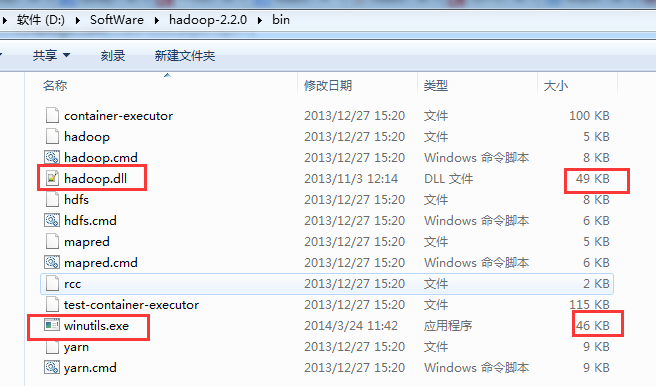
下载地址