不多说,直接上干货!
对于初学者来说,建议你先玩玩这个免费的社区版,但是,一段时间,还是去玩专业版吧,这个很简单哈,学聪明点,去搞到途径激活!可以看我的博客。
包括:
IntelliJ IDEA(Community)的下载
IntelliJ IDEA(Community)的安装
IntelliJ IDEA(Community)中的scala插件安装
用SBT方式来创建工程 或 选择Scala方式来创建工程
本地模式或集群模式

我们知道,对于开发而言,IDE是有很多个选择的版本。如我们大部分人经常用的是如下。
Eclipse *版本
Eclipse *下载

而我们知道,对于spark的scala开发啊,有为其专门设计的eclipse,Scala IDE for Eclipse

Scala IDE for Eclipse的下载、安装和WordCount的初步使用(本地模式和集群模式)
这里,我们知道,spark的开发可以通过IntelliJ IDEA或者Scala IDE for Eclipse,包括来构建spark开发环境和源码阅读环境。由于IntelliJ IDEA对scala的支持更好,所以目前spark开发团队使用IntelliJ IDEA作为开发环境。强烈推荐!
1、IntelliJ IDEA(Community)的下载
下载链接: http://www.jetbrains.com/idea/download/
一般,我们使用选择免费的社区版就好了,不过Apache的贡献者可以免费获得商业发行版的使用权。



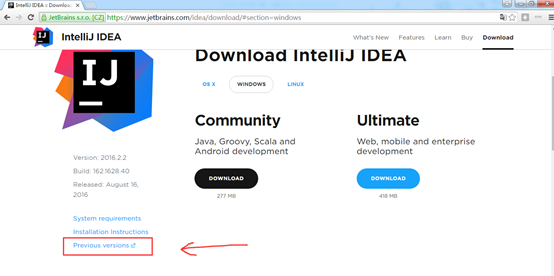
我们找历史版本,Windows7下安装IntelliJ IDEA Community Edition 2016.1.3(64)。

2、IntelliJ IDEA(Community)的安装
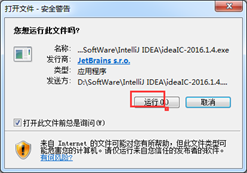

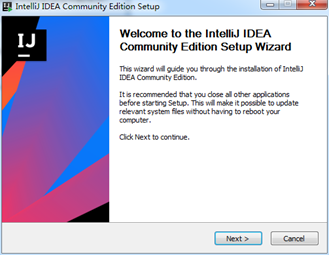
答案就是在:http://www.oschina.net/question/227259_2160359?fromerr=GzBpdLWq
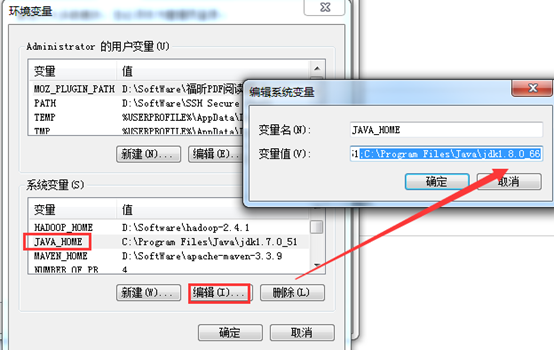
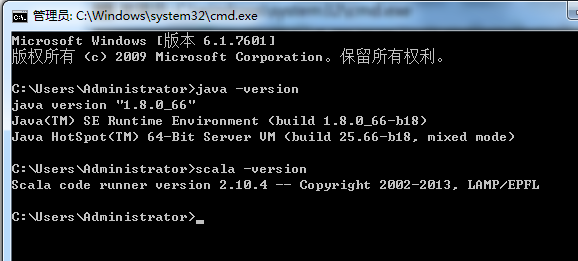
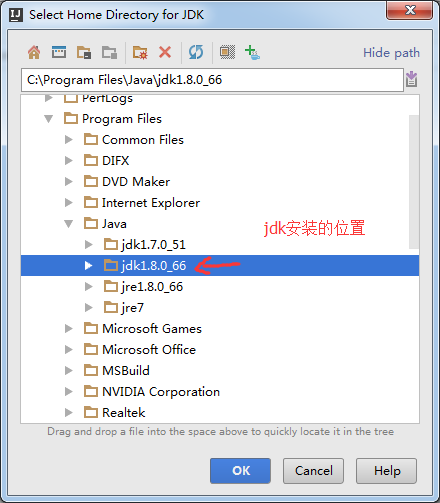
Idea 201*.*之后的64位需要JDK1.8了。很多都是需要jdk1.8。
而我的,

所以,就一直出现,不出来64位选择的问题。
而,Hadoop那边,一般以jdk1.7为主。为稳定。
为此,添加jdk1.8。

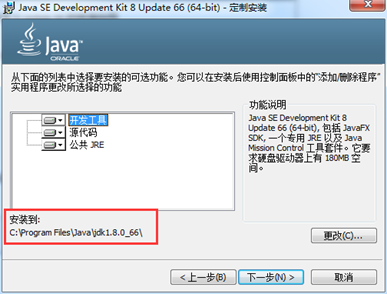


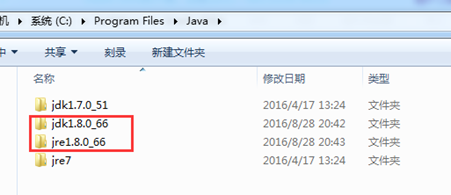
C:Program FilesJavajdk1.8.0_66
至于,CLASSPTH、PATH就不需了。
同时,存在,jdk1.7和jdk1.8。
则java -verison,得到,
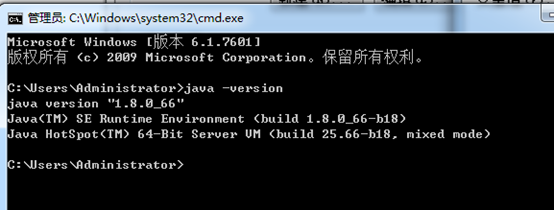
这里啊,要注意下,是以jdk1.8了,因为,高级版本会覆盖掉低级版本,当然,我留下它,是因为为我的hadoop-2.6.0版本着想,最近啊,2016年9月3日,hadoop-3.*出来了,以后的趋势肯定是要以jdk1.8了、
现在,来安装
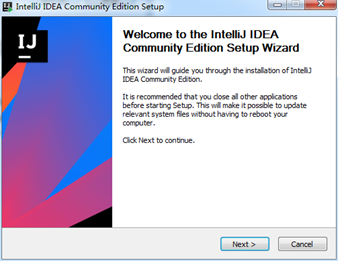
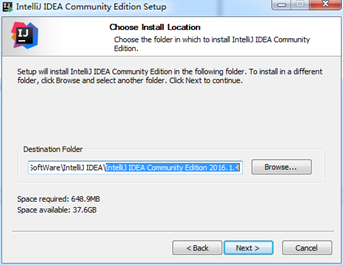
保存位置,不喜欢安装到系统盘的话,就选择到其它的位置
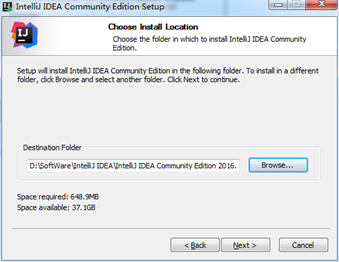
D:SoftWareIntelliJ IDEAIntelliJ IDEA Community Edition 2016.1.4
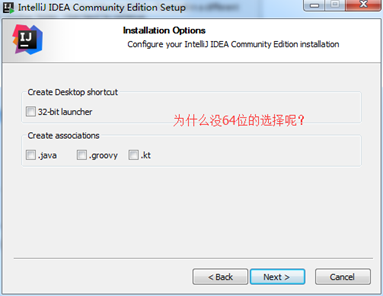
创建桌面快捷方式,我只选一个64位的够了;
注意:如果你的JDK是32位的,Tomcat是32位的,估计要使用32位的才行;
创建扩展名关联:都选上吧 ;


安装到这里就完成了,但接下来还有一些步骤需要配置

如果你之前安装过早期版本的,想把之前的配置应用到新版本就选则上面的,没有?
那就跟我选择一样的吧!
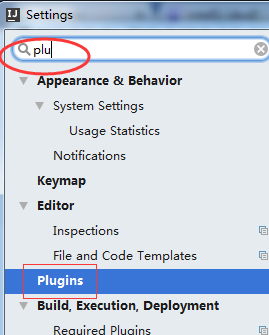
3、IntelliJ IDEA(Community)的使用
在这之前,先在本地里安装好java和scala
这个必须要同意,不然的话我们安装它干嘛!

主题皮肤设置,看你喜欢哪一种吧!
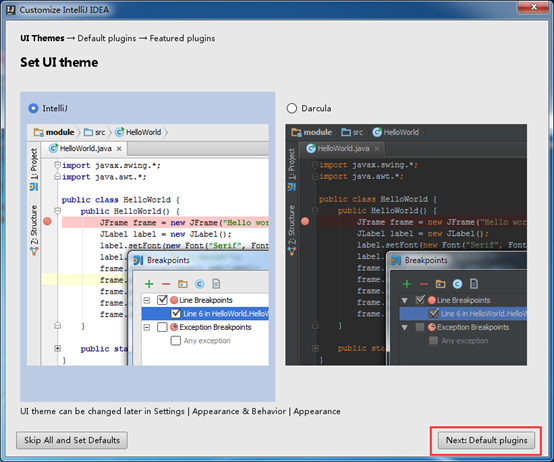

可以根据你的需要调整定制需要的特性:
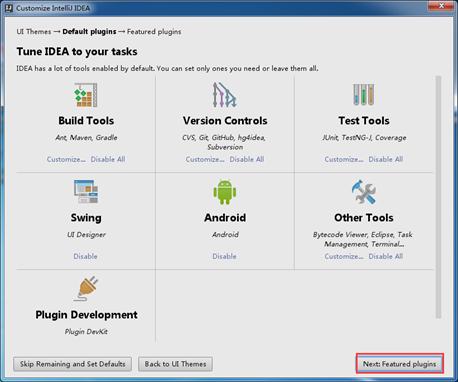
这里可以安装Scala和IdeaVim支持,但我试了几次,根本安装不上;(其实啊,这里可以安装的上,当然,有时候会安装不上)

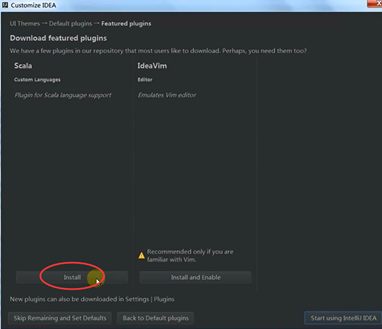
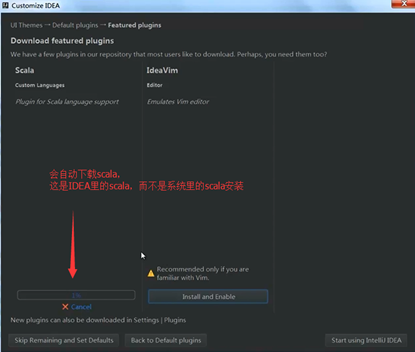
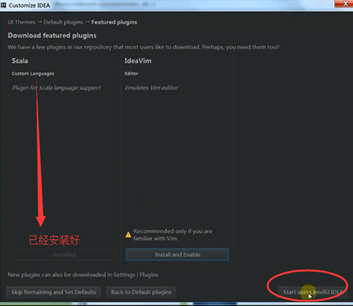
为IDEA安装scala,这个过程是是IDEA自动化的插件管理,所以点击后会自动下载。
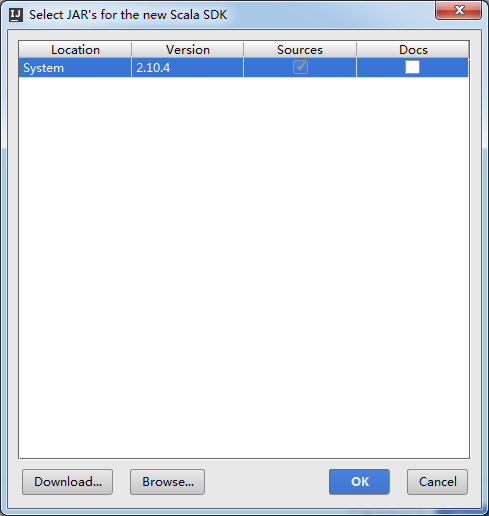
说明的是:我们是安装了scala2.10.4,为什么还要在IDEA里还要安装scala呢?
而不是IDEAl里本身开发支持的插件的版本。
则,现在已经安装好了。这一步,叫做,在IntelliJ IDEA里安装scala插件,当然,可以在安装IntelliJ IDEA就将scala插件安装好,或者,也可以在这一步没安装成功,之后,再来补安装scala插件。
具体,如何补安装scala插件,如下。
启动界面,挺酷的

先选择Create New Project 创建一个空项目看看吧

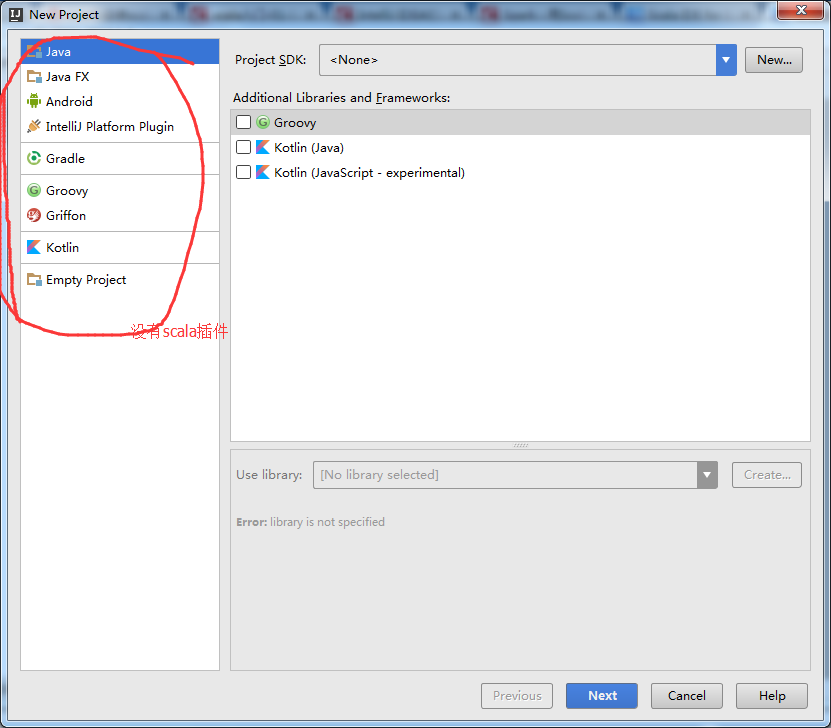
补安装scala插件
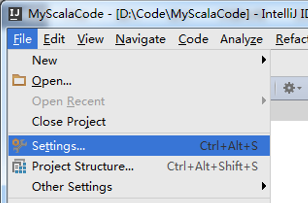
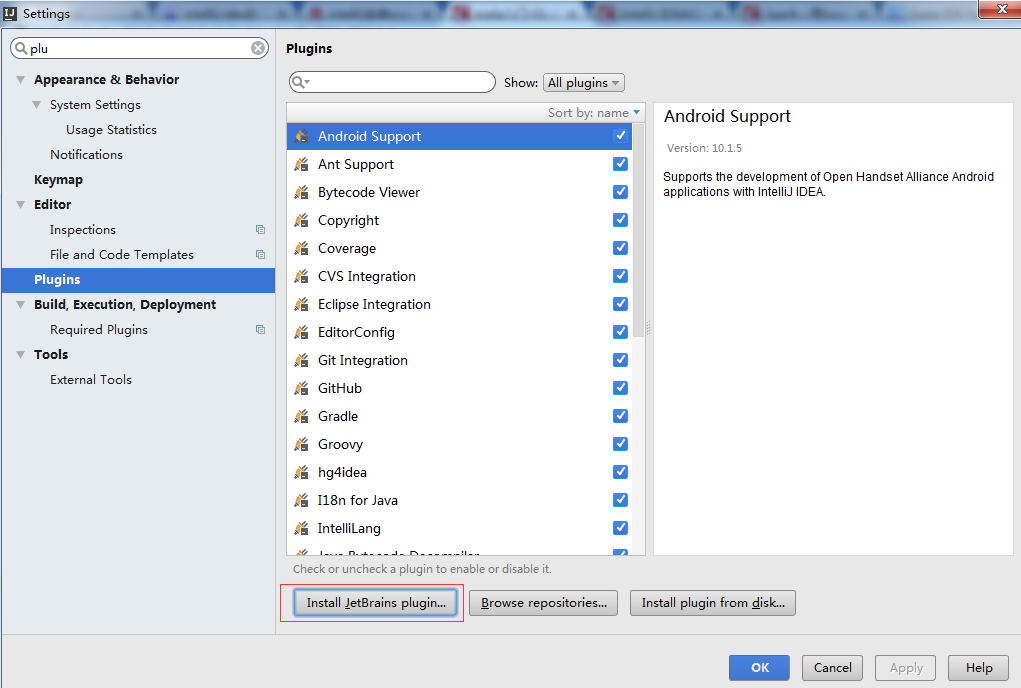
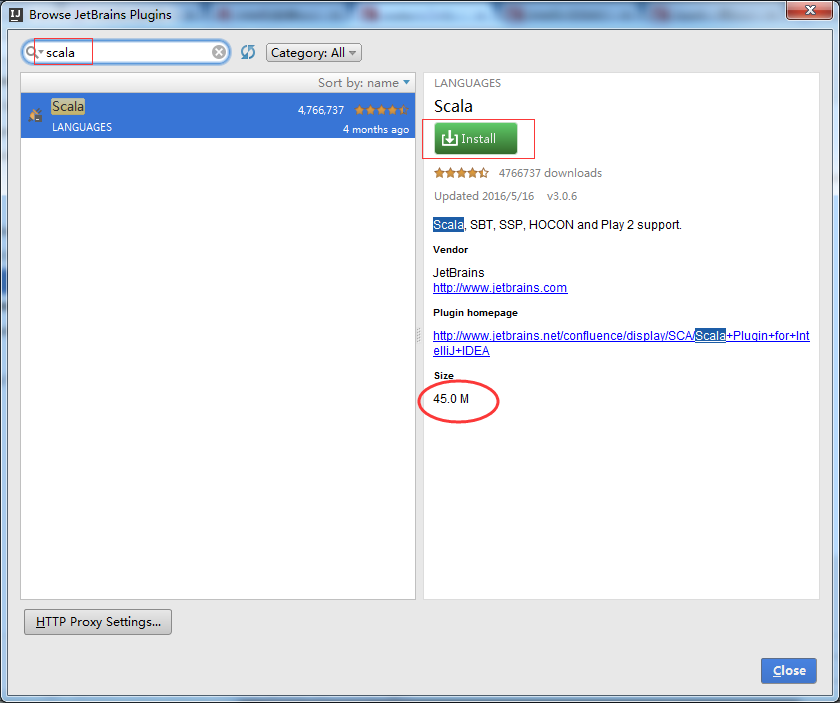
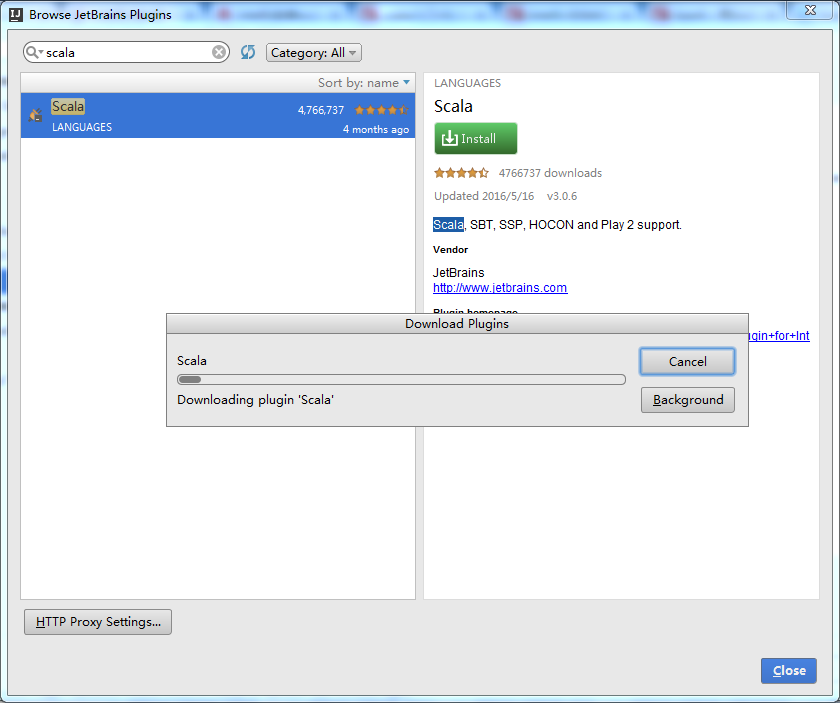
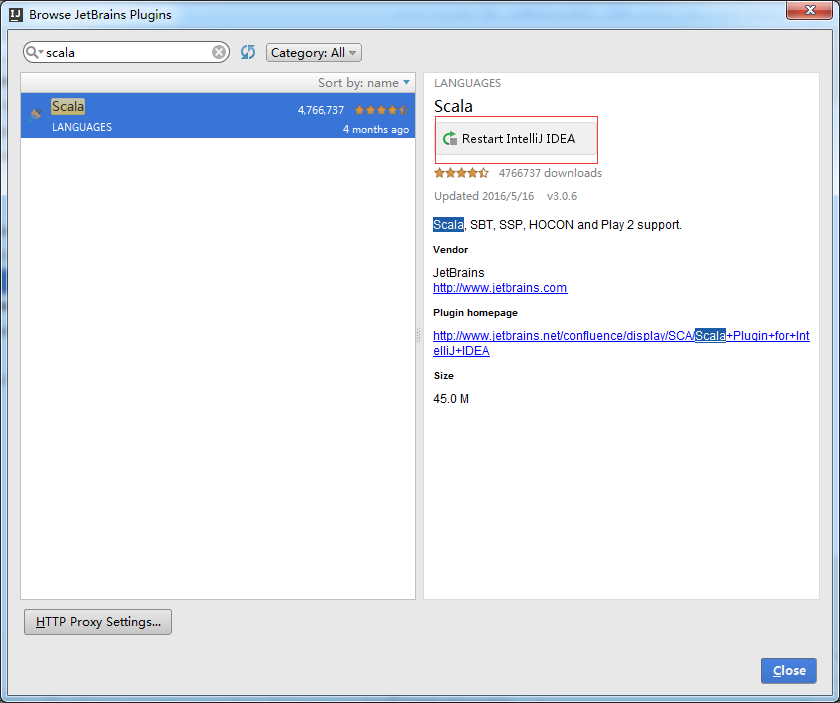
自动下载scala插件了,然后自动安装后重启就会生效了!
创建工程
File -> New -> Project
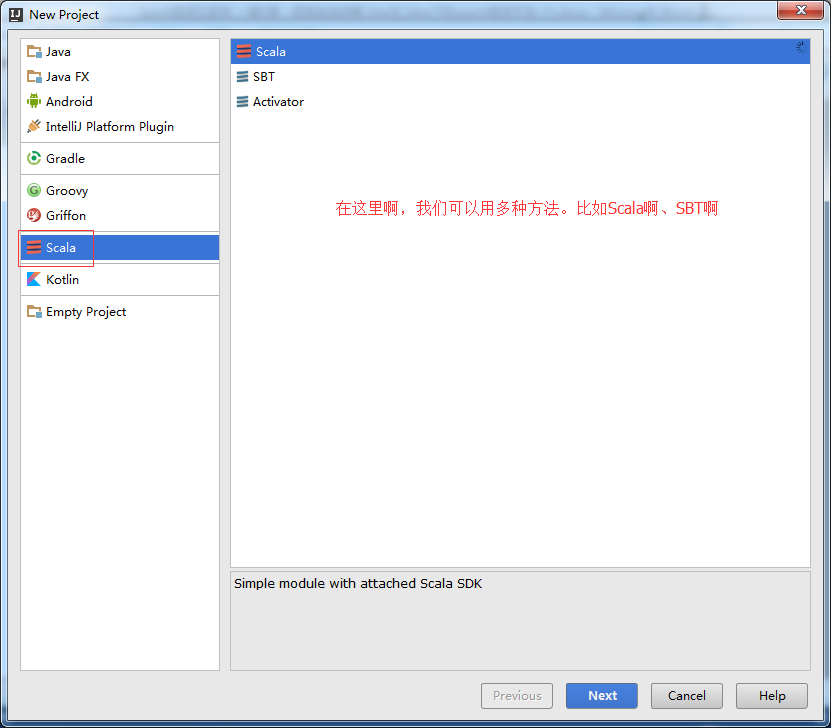
若是SBT方式,
参考了博客
http://blog.csdn.net/stark_summer/article/details/42460527
想说的是,SBT是为scala专门而设计的,但是,一般很多人还是用的是maven。
我这里,选择Scala方式,来创建,
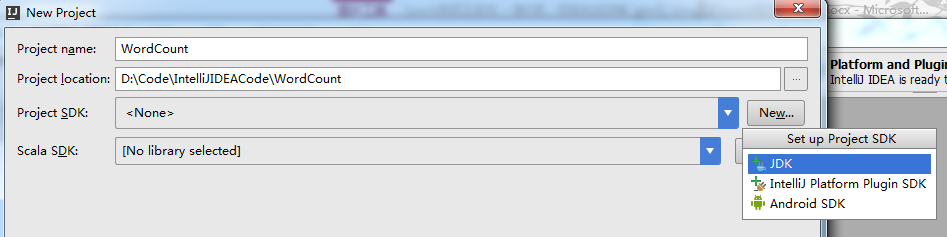
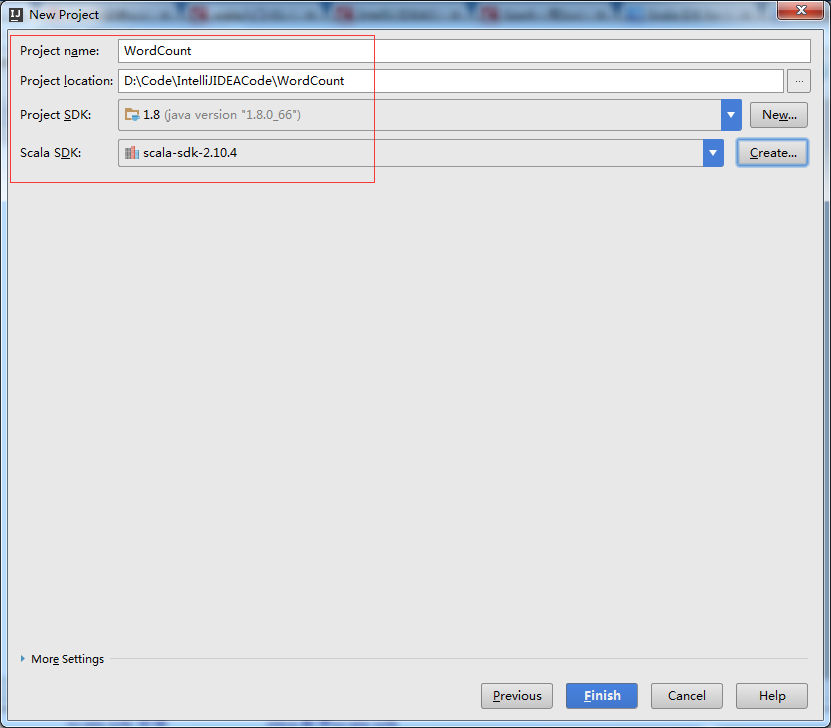

创建,需要一段时间
即,在以上过程中,模仿JDK1.8.x和scala2.10.4
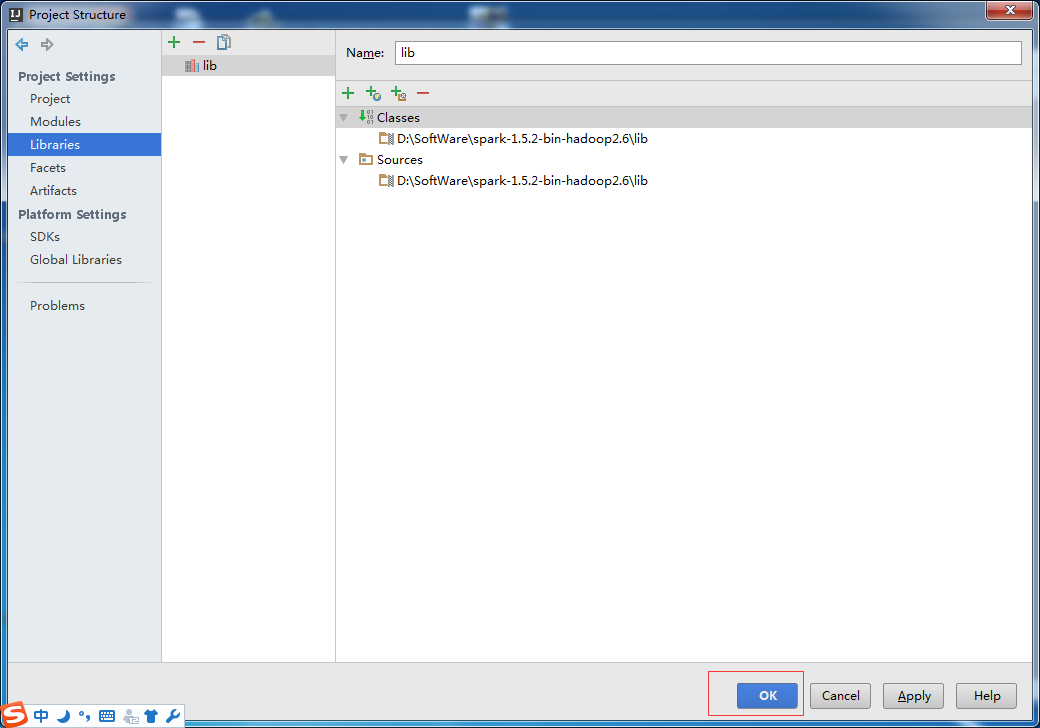
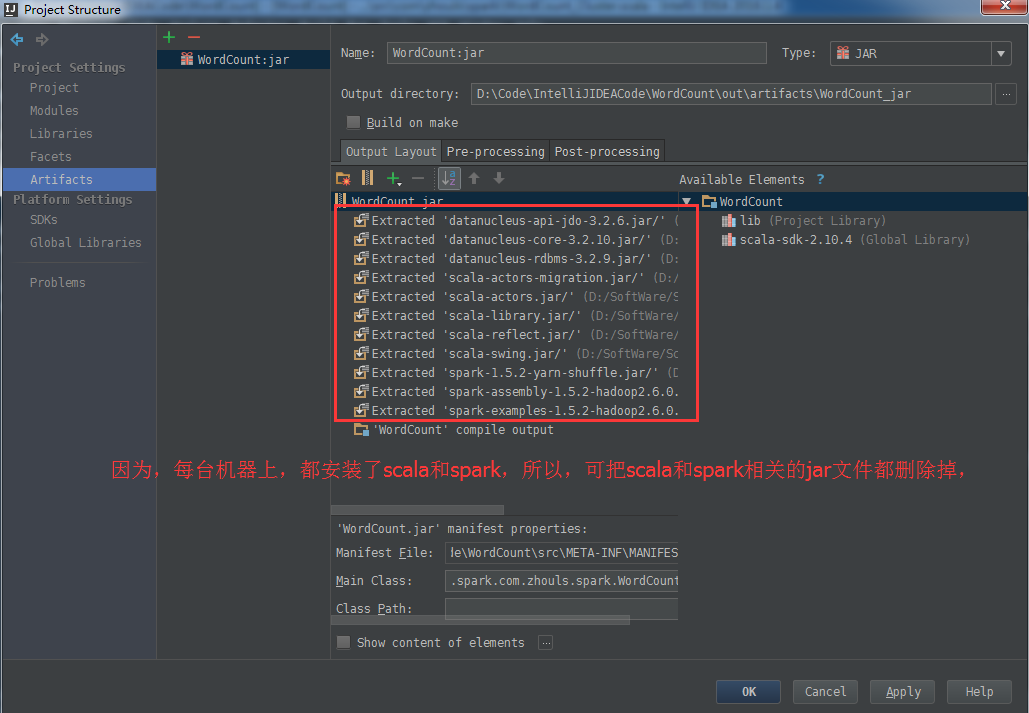
通过File –> Project Steuccture 来设置工程的Libraries核心是添加Spark的jar

选择,java,我们这里导入spark的jar包,为什么要选择java的选项呢?这里是从jvm的角度考虑的
添加Spark的jar依赖spark-1.5.2-bin-hadoop2.6.tgz里的lib目录下的spark-assembly-1.5.2-hadoop2.6.0.jar
注意,我们是在windows里开发,下载和解压的是linux版本(如spark-1.6.0-bin-hadoop2.6.tgz)

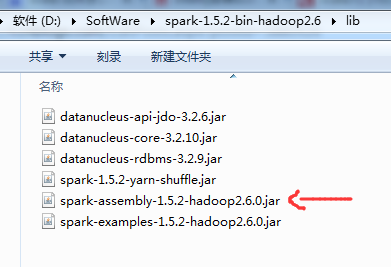
该包可以通过sbt/sbt assembly命令生成,这个命令相当于将spark的所有依赖包和spark源码打包为一个整体。


其实,这是一步拷贝的过程

需要一段时间

成功!
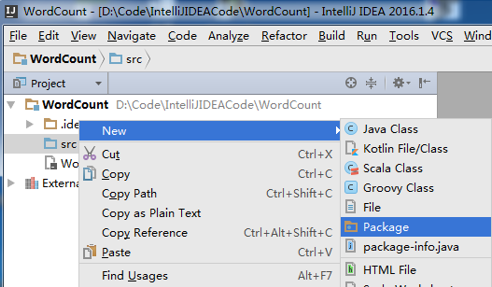
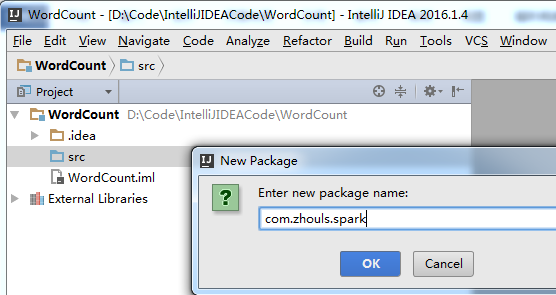
src -> New -> Package
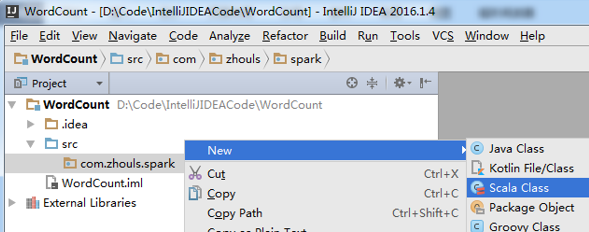
New -> Scala Class


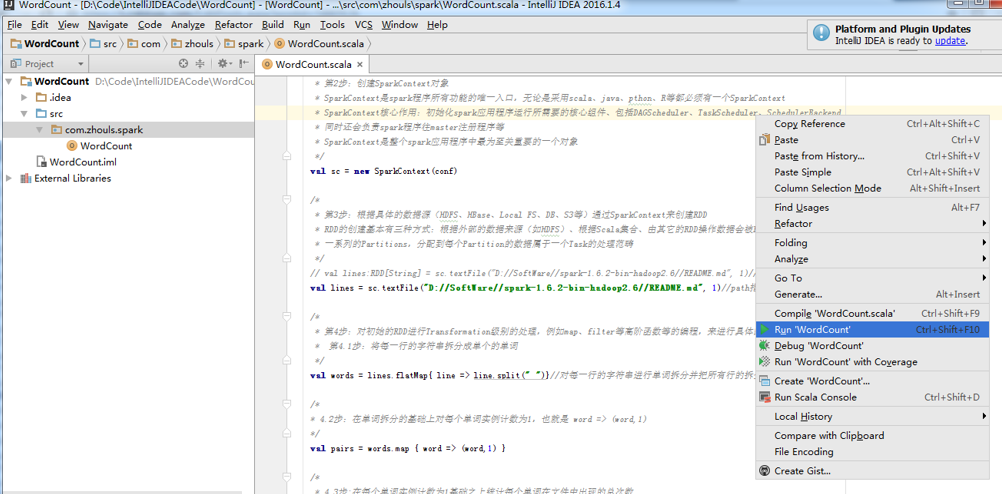
本地模式和集群模式的代码,这里我不多赘述。
(1)本地运行
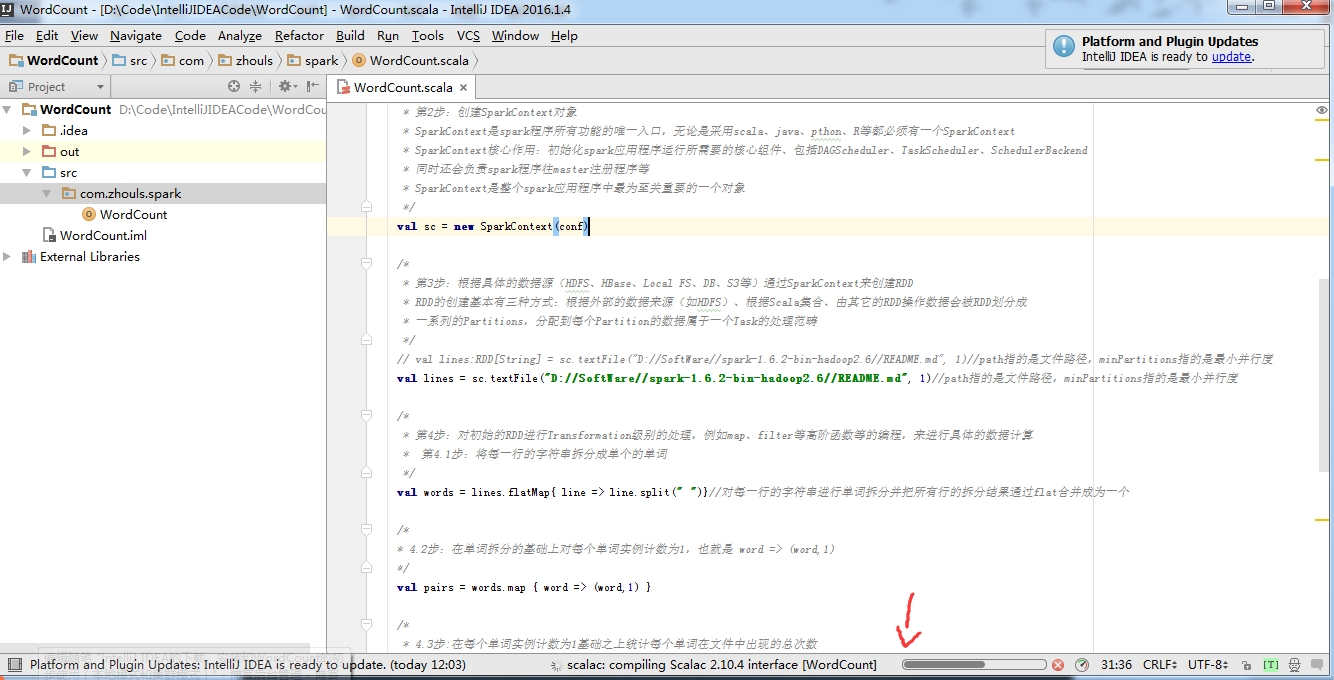
编写完Scala程序后,可以直接在IntelliJ IDEA中以本地(local)模式运行。
在IntelliJ IDEA中,点击Run 按钮,
或者
有的时候,会是如下情况:
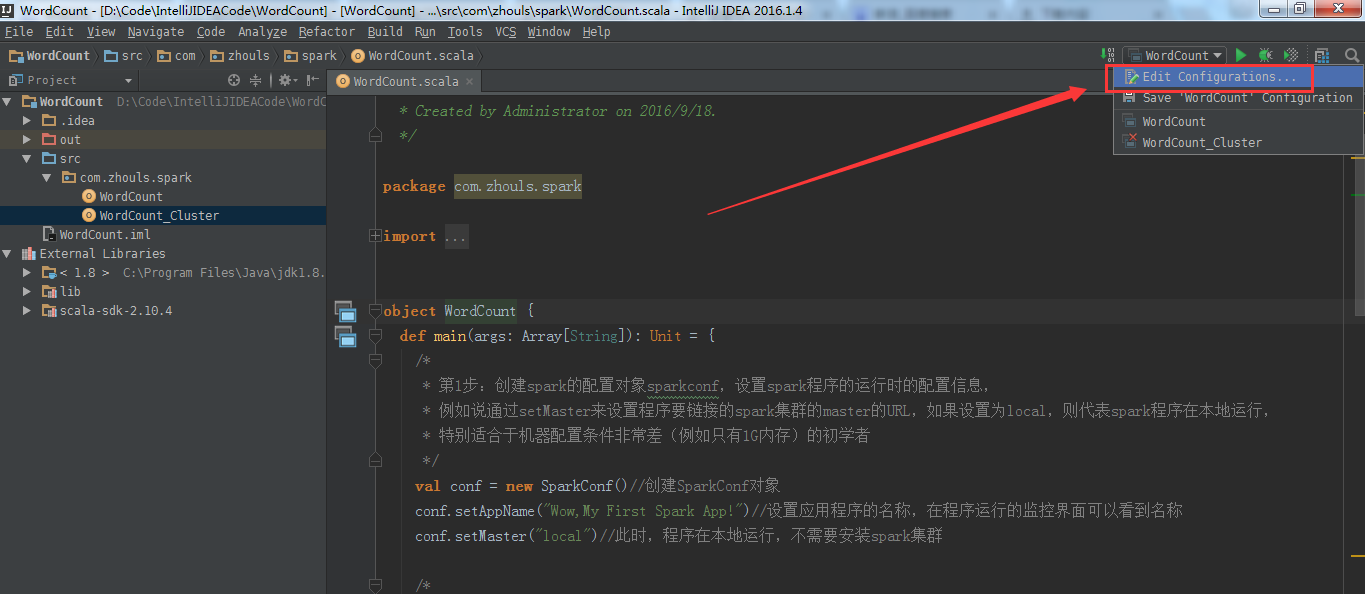
在IntelliJ IDEA中点击Run/Debug Configuration按钮,在其下拉列表选择Edit Configurations选项。
在Run输入选择界面中,在输入框Program arguments中输入main函数的输入参数local,即为本地单机执行spark应用。
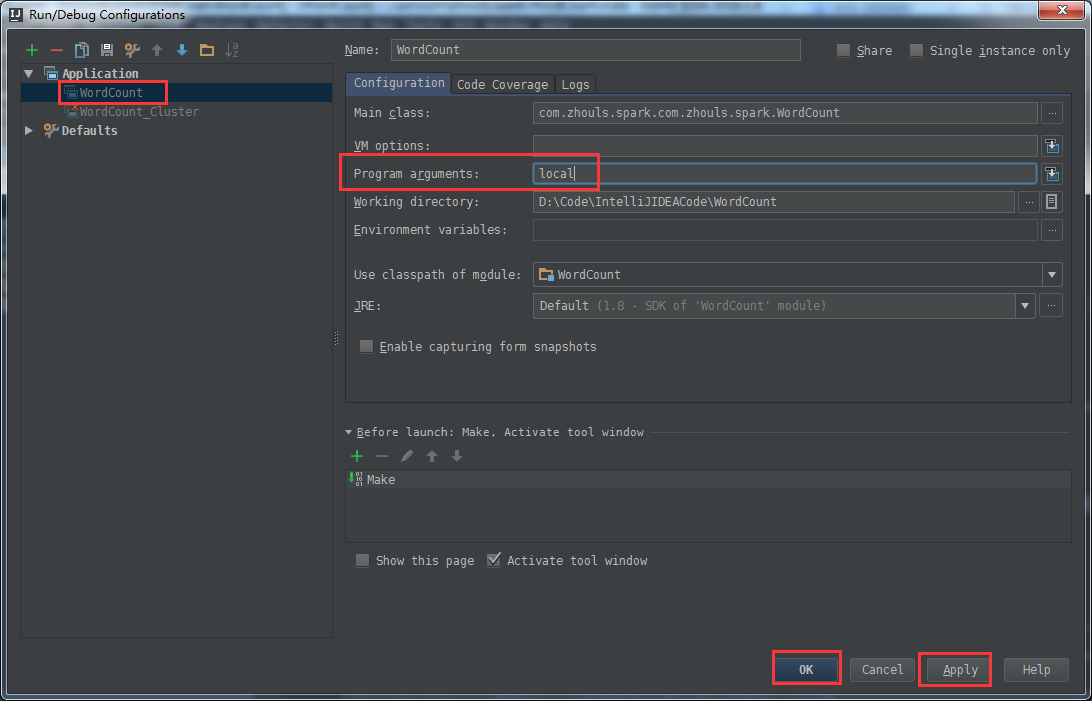
然后点击选择需要运行的类,点击Run运行spark应用程序。
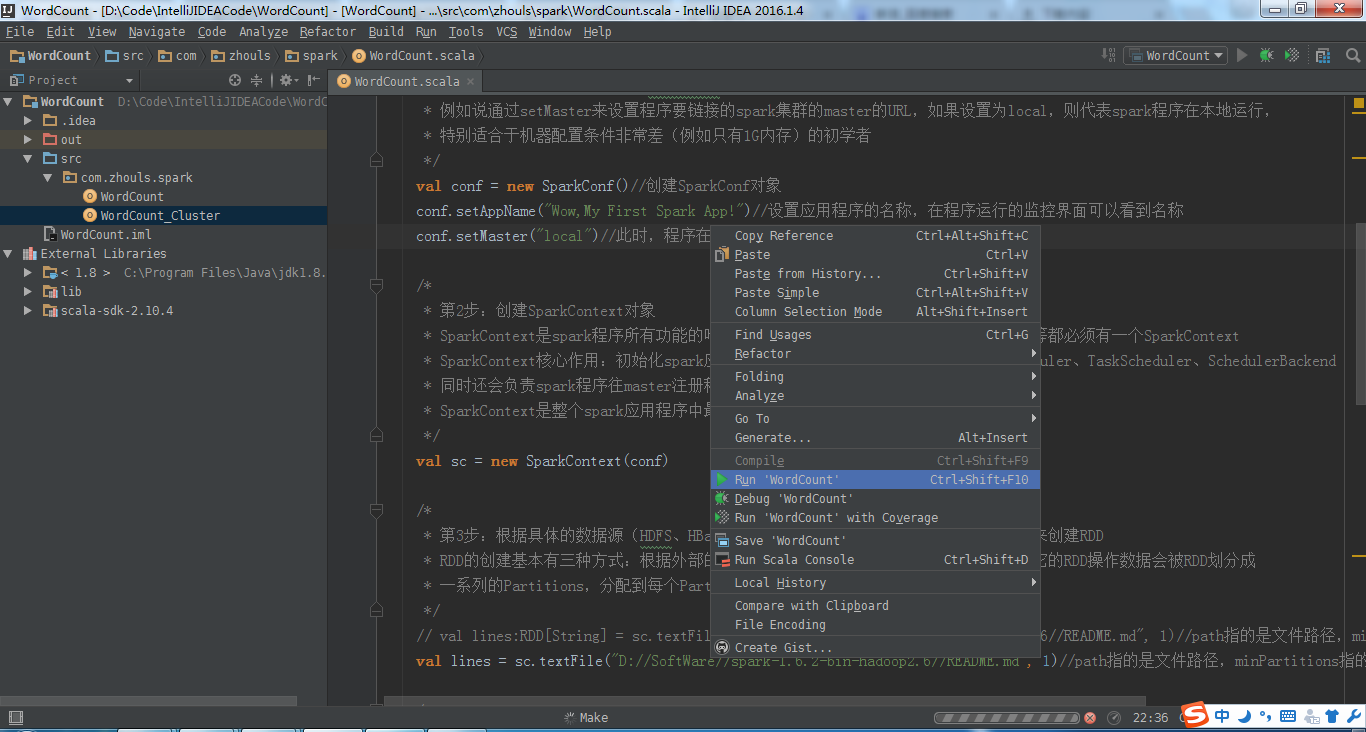
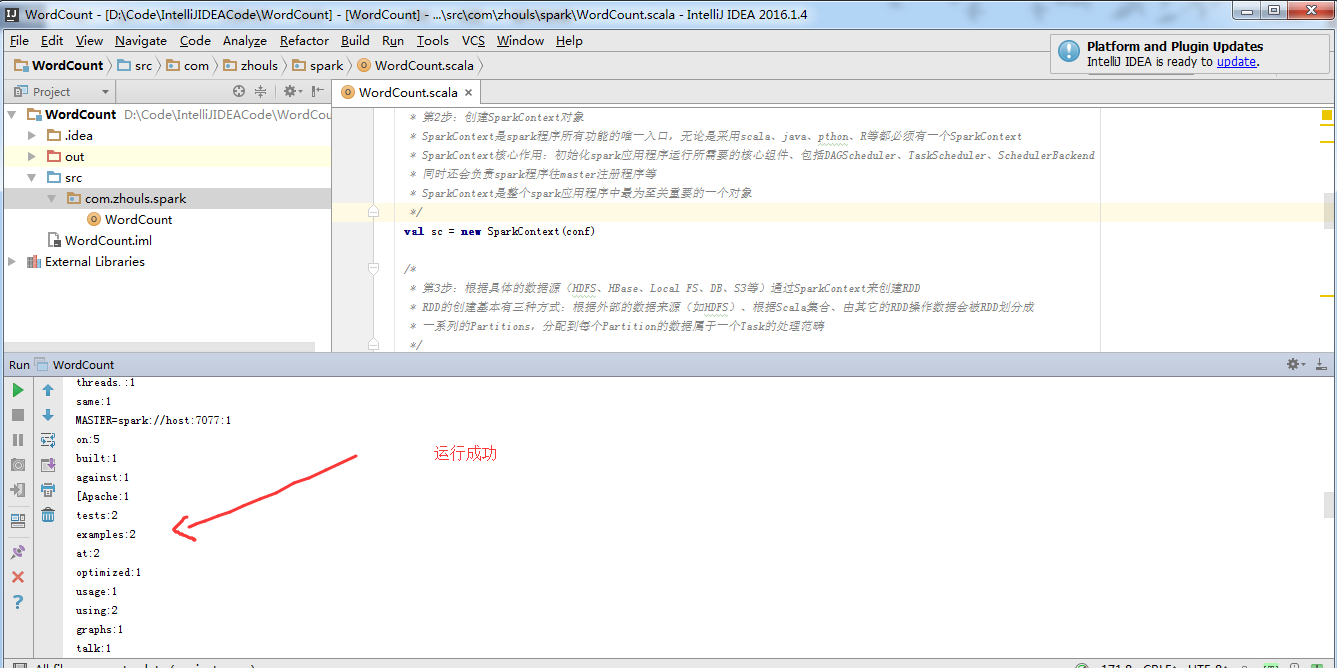
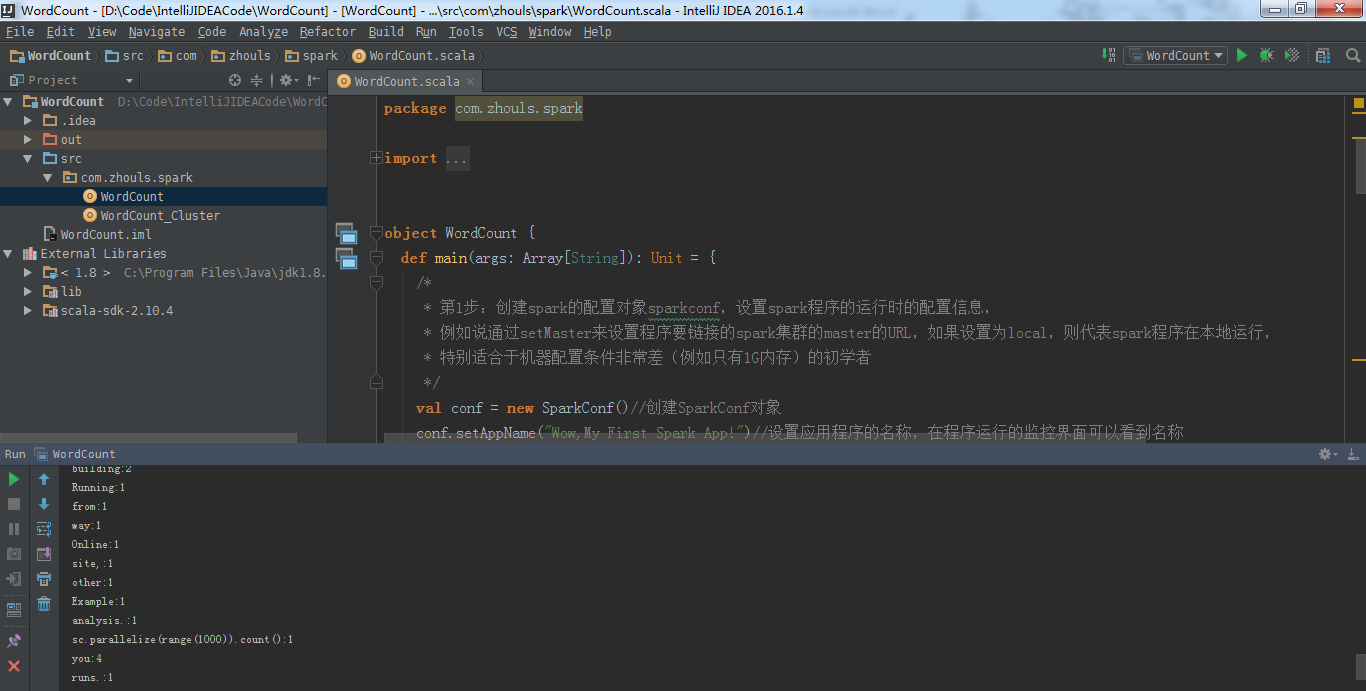 由此,可见,本地模式成功!
由此,可见,本地模式成功!
集群模式
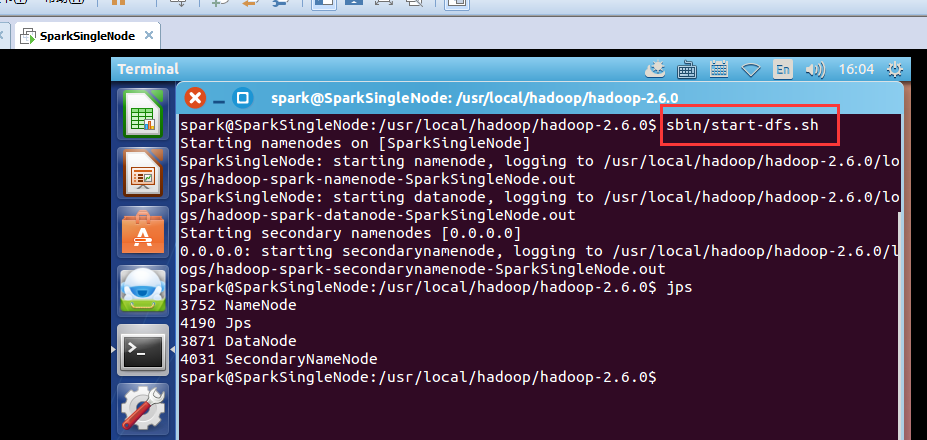
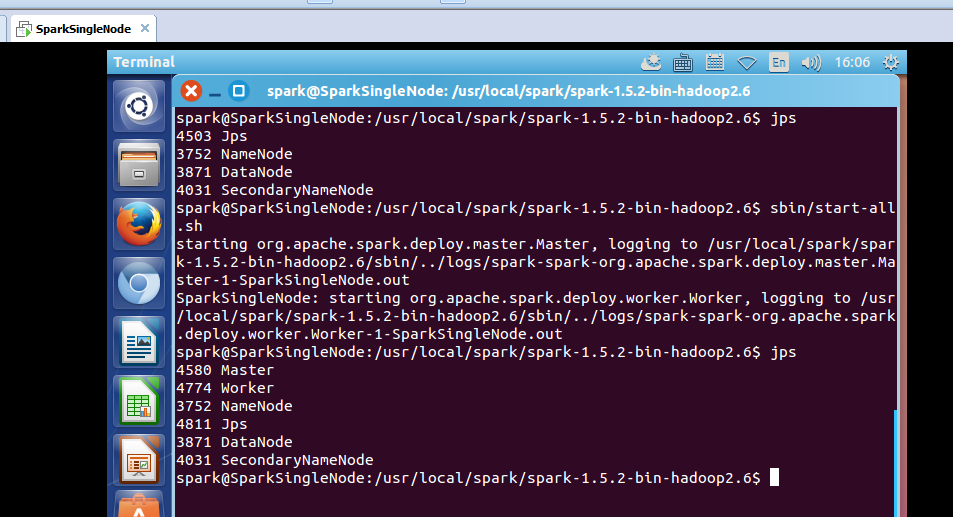
先开启hadoop集群
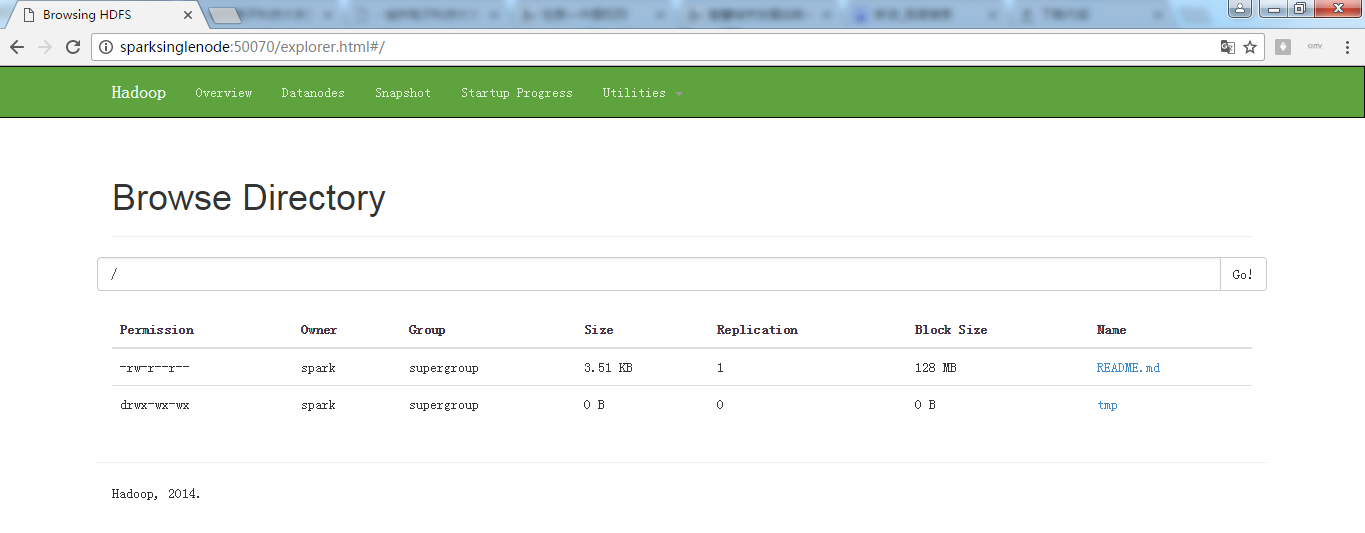
50070界面
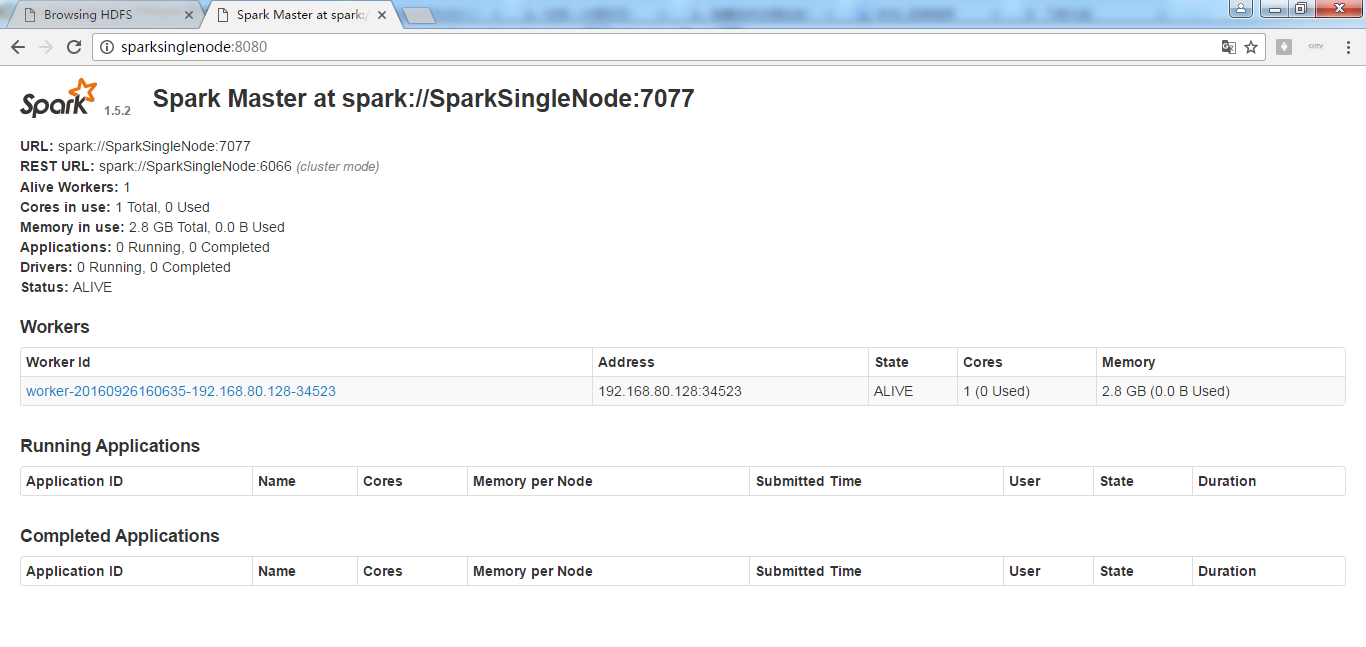
7070界面
接下来,继续打包,使用 Project Structure的Artifacts,
Artifacts -> + -> JAR + From modules with dependencies...
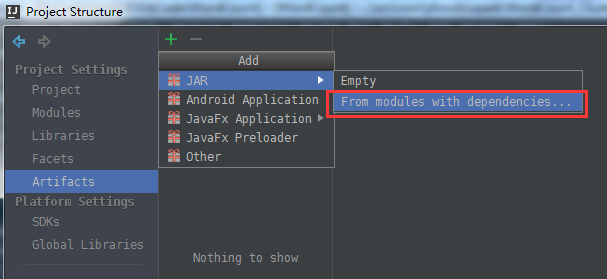
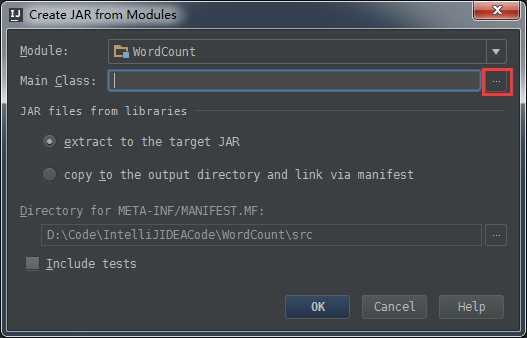
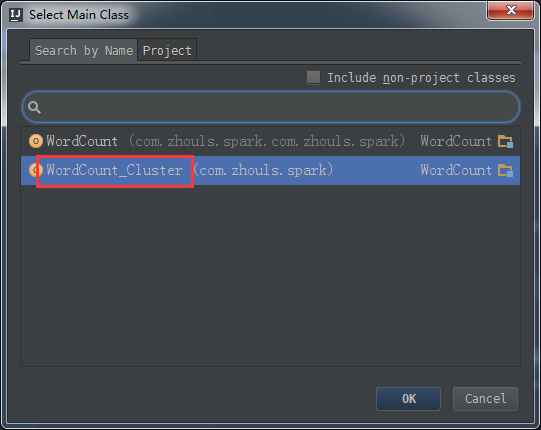
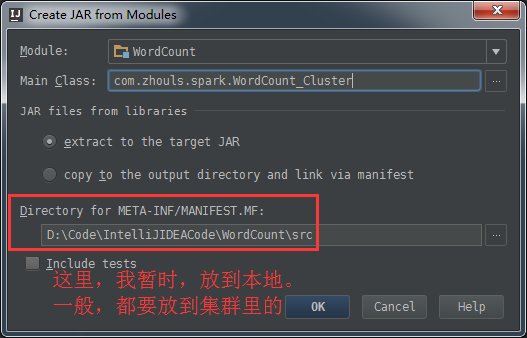
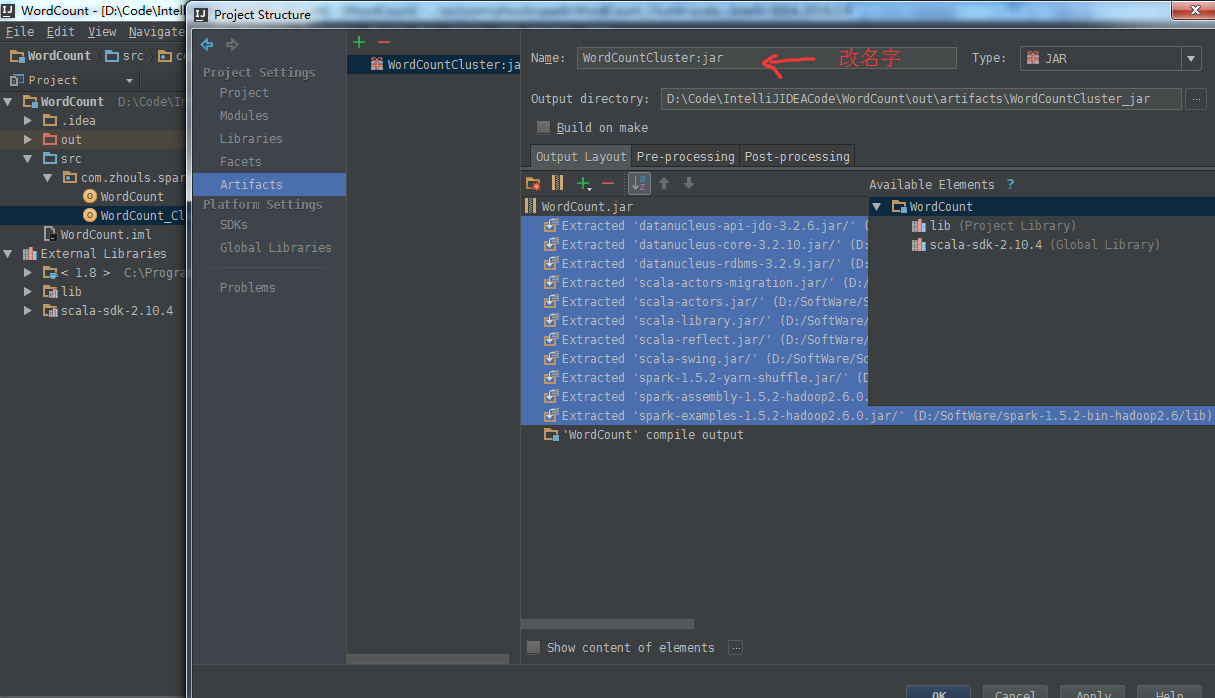

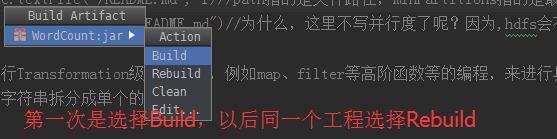
接下来,建立Build。


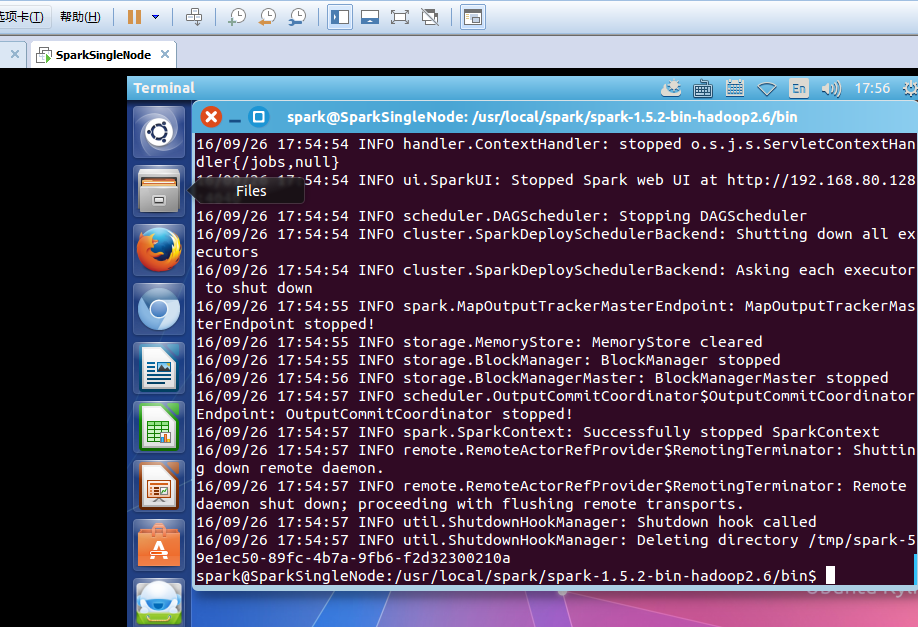
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin$ ./spark-submit --master spark://SparkSingleNode:7077 /home/spark/WordCount.jar

开始之前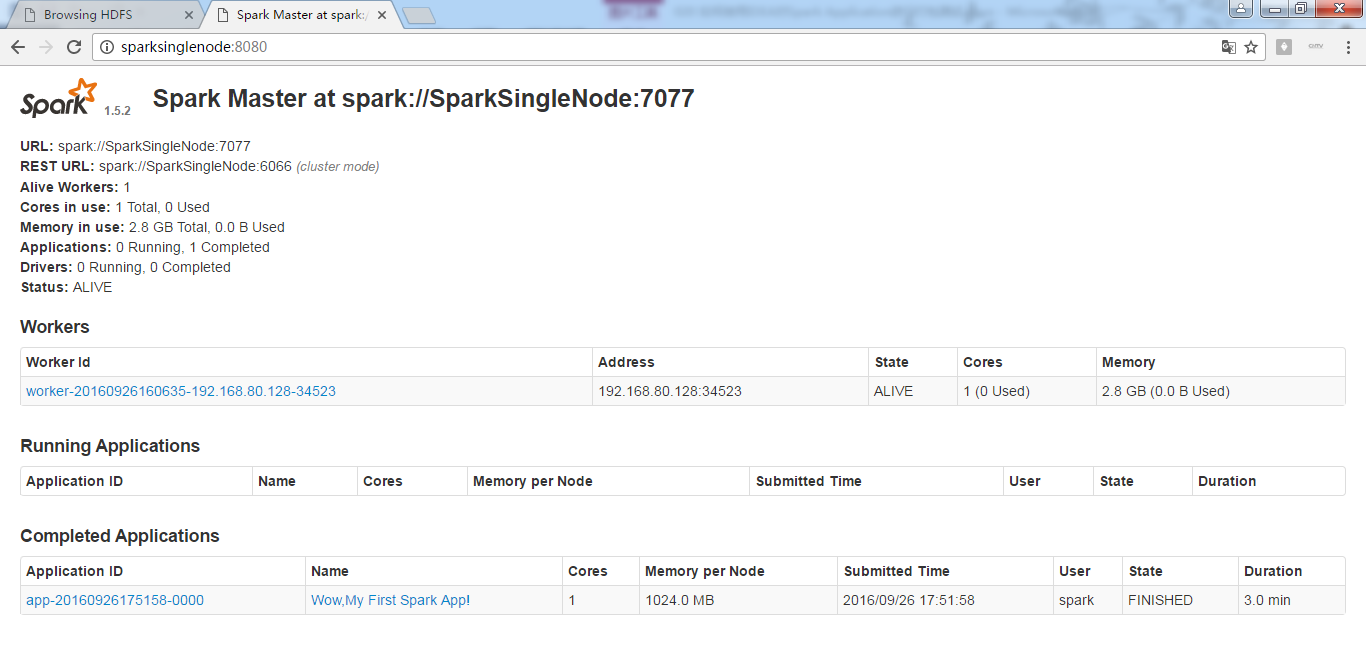
正在进行
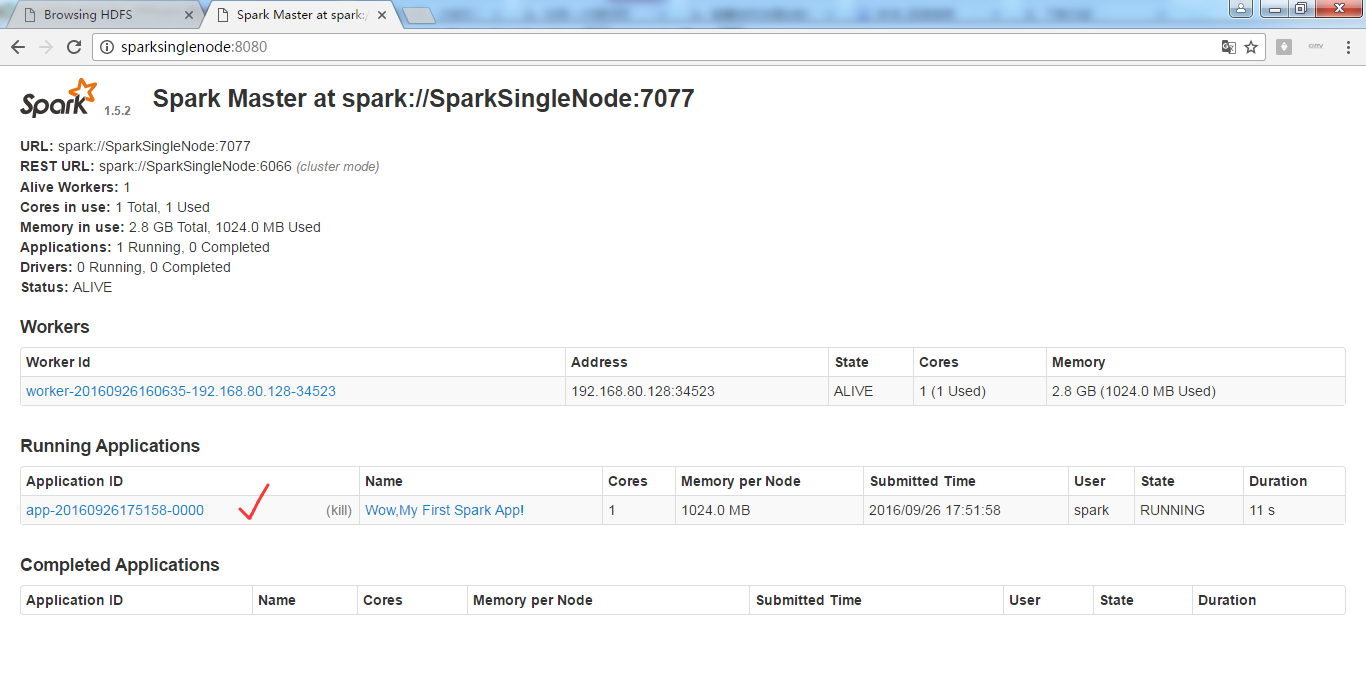
完成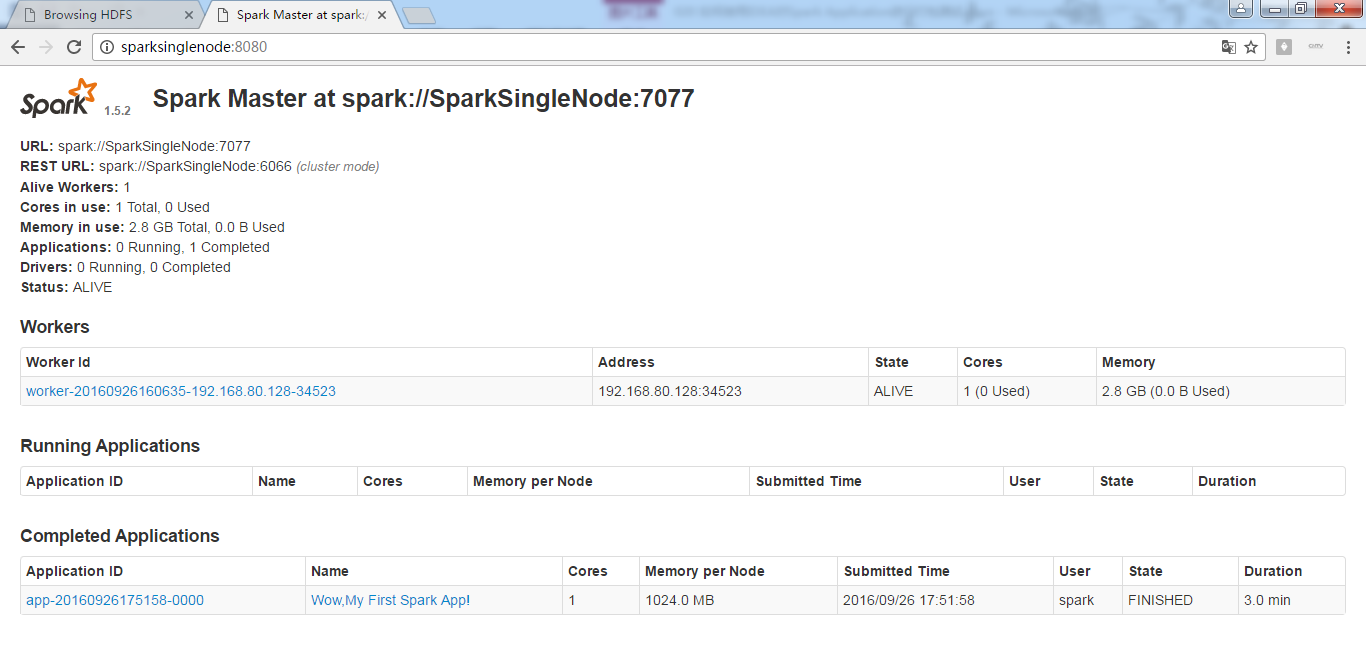

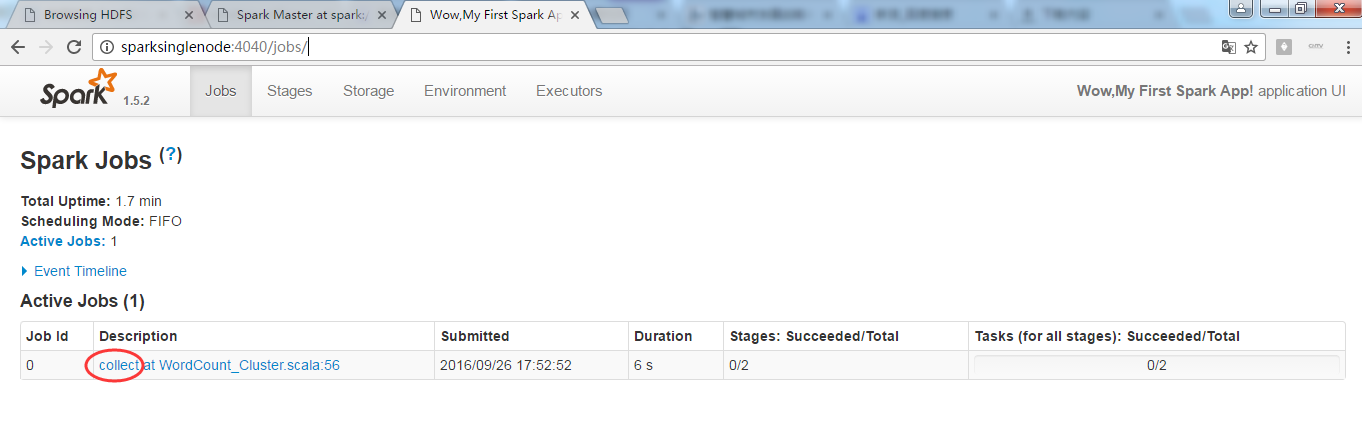
4040界面
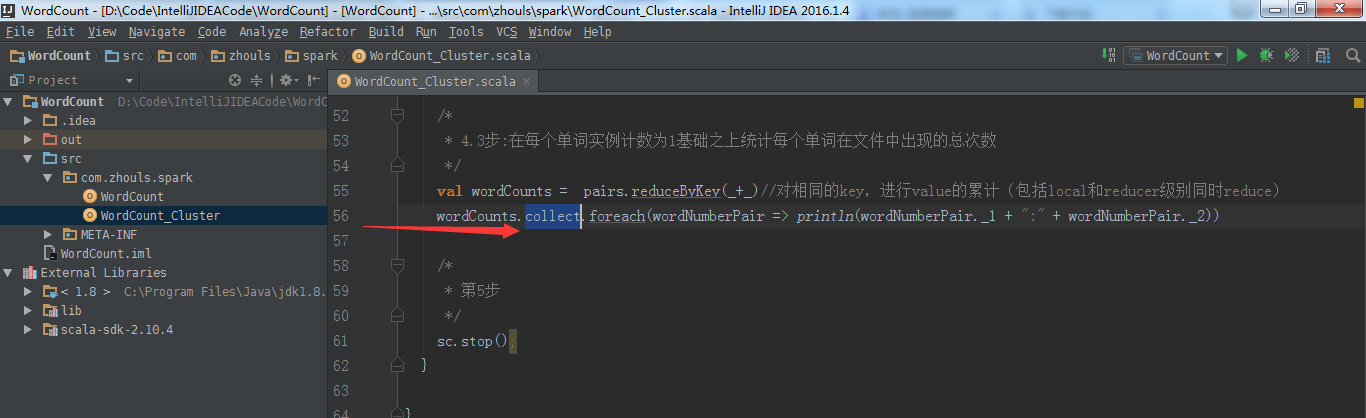
其实啊,在集群里,模板就是如下
val file = spark.textFile("hdfs://...”)
val counts = file.flatMap("line => line.spilt(" "))
.map(word => (word,1))
.reduceByKey(_+_)
counts.saveAsTextFile("hdfs://...”)
IntelliJ IDEA的黑白色背景切换
File -> Setting -> Editor -> Colors & Fonts

即,默认是白色的,那么,点击yes,则默认变成黑色了。
变成

想说的是,当然,这背景版本给出的是黑色和白色这两种选择,其实,自己可以将图片上传作为背景。
总结
WordCount.scala(本地模式)
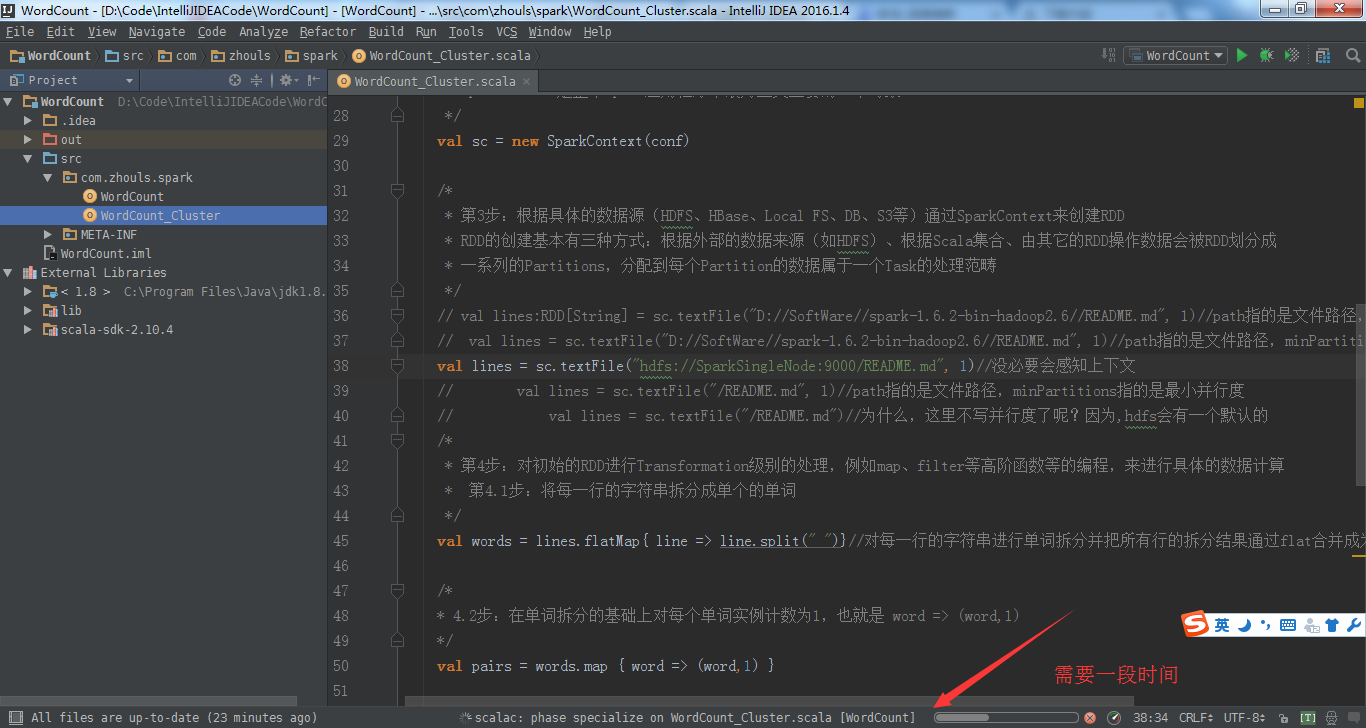
1 package com.zhouls.spark 2 3 /** 4 * Created by Administrator on 2016/9/18. 5 */ 6 7 package com.zhouls.spark 8 9 import org.apache.spark.SparkConf 10 import org.apache.spark.SparkContext 11 12 13 object WordCount { 14 def main(args: Array[String]): Unit = { 15 /* 16 * 第1步:创建spark的配置对象sparkconf,设置spark程序的运行时的配置信息, 17 * 例如说通过setMaster来设置程序要链接的spark集群的master的URL,如果设置为local,则代表spark程序在本地运行, 18 * 特别适合于机器配置条件非常差(例如只有1G内存)的初学者 19 */ 20 val conf = new SparkConf()//创建SparkConf对象 21 conf.setAppName("Wow,My First Spark App!")//设置应用程序的名称,在程序运行的监控界面可以看到名称 22 conf.setMaster("local")//此时,程序在本地运行,不需要安装spark集群 23 24 /* 25 * 第2步:创建SparkContext对象 26 * SparkContext是spark程序所有功能的唯一入口,无论是采用scala、java、pthon、R等都必须有一个SparkContext 27 * SparkContext核心作用:初始化spark应用程序运行所需要的核心组件、包括DAGScheduler、TaskScheduler、SchedulerBackend 28 * 同时还会负责spark程序往master注册程序等 29 * SparkContext是整个spark应用程序中最为至关重要的一个对象 30 */ 31 val sc = new SparkContext(conf) 32 33 /* 34 * 第3步:根据具体的数据源(HDFS、HBase、Local FS、DB、S3等)通过SparkContext来创建RDD 35 * RDD的创建基本有三种方式:根据外部的数据来源(如HDFS)、根据Scala集合、由其它的RDD操作数据会被RDD划分成 36 * 一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴 37 */ 38 // val lines:RDD[String] = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度 39 val lines = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度 40 41 /* 42 * 第4步:对初始的RDD进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算 43 * 第4.1步:将每一行的字符串拆分成单个的单词 44 */ 45 val words = lines.flatMap{ line => line.split(" ")}//对每一行的字符串进行单词拆分并把所有行的拆分结果通过flat合并成为一个 46 47 /* 48 * 4.2步:在单词拆分的基础上对每个单词实例计数为1,也就是 word => (word,1) 49 */ 50 val pairs = words.map { word => (word,1) } 51 52 /* 53 * 4.3步:在每个单词实例计数为1基础之上统计每个单词在文件中出现的总次数 54 */ 55 val wordCounts = pairs.reduceByKey(_+_)//对相同的key,进行value的累计(包括local和reducer级别同时reduce) 56 wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + ":" + wordNumberPair._2)) 57 58 /* 59 * 第5步 60 */ 61 sc.stop(); 62 } 63 64 }
WordCount_Cluster.scala(集群模式)
1 package com.zhouls.spark 2 3 /** 4 * Created by Administrator on 2016/9/18. 5 */ 6 7 import org.apache.spark.SparkConf 8 import org.apache.spark.SparkContext 9 10 11 object WordCount_Cluster { 12 def main(args: Array[String]): Unit = { 13 /* 14 * 第1步:创建spark的配置对象sparkconf,设置spark程序的运行时的配置信息, 15 * 例如说通过setMaster来设置程序要链接的spark集群的master的URL,如果设置为local,则代表spark程序在本地运行, 16 * 特别适合于机器配置条件非常差(例如只有1G内存)的初学者 17 */ 18 val conf = new SparkConf()//创建SparkConf对象 19 conf.setAppName("Wow,My First Spark App!")//设置应用程序的名称,在程序运行的监控界面可以看到名称 20 conf.setMaster("spark://SparkSingleNode:7077")//此时,程序在本地运行,不需要安装spark集群 21 22 /* 23 * 第2步:创建SparkContext对象 24 * SparkContext是spark程序所有功能的唯一入口,无是采用scala、java、pthon、R等都必须有一个SparkContext 25 * SparkContext核心作用:初始化spark应用程序运行所需要的核心组件、包括DAGScheduler、TaskScheduler、SchedulerBackend 26 * 同时还会负责spark程序往master注册程序等 27 * SparkContext是整个spark应用程序中最为至关重要的一个对象 28 */ 29 val sc = new SparkContext(conf) 30 31 /* 32 * 第3步:根据具体的数据源(HDFS、HBase、Local FS、DB、S3等)通过SparkContext来创建RDD 33 * RDD的创建基本有三种方式:根据外部的数据来源(如HDFS)、根据Scala集合、由其它的RDD操作数据会被RDD划分成 34 * 一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴 35 */ 36 // val lines:RDD[String] = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度 37 // val lines = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度 38 val lines = sc.textFile("hdfs://SparkSingleNode:9000/README.md", 1)//没必要会感知上下文 39 // val lines = sc.textFile("/README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度 40 // val lines = sc.textFile("/README.md")//为什么,这里不写并行度了呢?因为,hdfs会有一个默认的 41 /* 42 * 第4步:对初始的RDD进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算 43 * 第4.1步:将每一行的字符串拆分成单个的单词 44 */ 45 val words = lines.flatMap{ line => line.split(" ")}//对每一行的字符串进行单词拆分并把所有行的拆分结果通过flat合并成为一个 46 47 /* 48 * 4.2步:在单词拆分的基础上对每个单词实例计数为1,也就是 word => (word,1) 49 */ 50 val pairs = words.map { word => (word,1) } 51 52 /* 53 * 4.3步:在每个单词实例计数为1基础之上统计每个单词在文件中出现的总次数 54 */ 55 val wordCounts = pairs.reduceByKey(_+_)//对相同的key,进行value的累计(包括local和reducer级别同时reduce) 56 wordCounts.collect.foreach(wordNumberPair => println(wordNumberPair._1 + ":" + wordNumberPair._2)) 57 58 /* 59 * 第5步 60 */ 61 sc.stop(); 62 } 63 64 }
扩展
IntelliJ IDEA(Ultimate版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()


