前言
使用Kafka也有一段时间了, 主要还是作为生产者推送数据到其它业务方, 作为生产者编写代码并不多, 因为客户端内部做了太多的处理, 同时也不太容易达到性能瓶颈, 大多情况也只是改变一下发送消息的路由策略. 即便如此面对众多参数如果不理解一条消息从发送到Kafka集群中间经历什么, 那么设置这些参数的时候可能达不到最初的目的.
注: 以下内容是学习<<图解 Kafka 之实战指南>>记录的笔记, 强烈建议大家读下原文, 可以到掘金搜索
主要架构
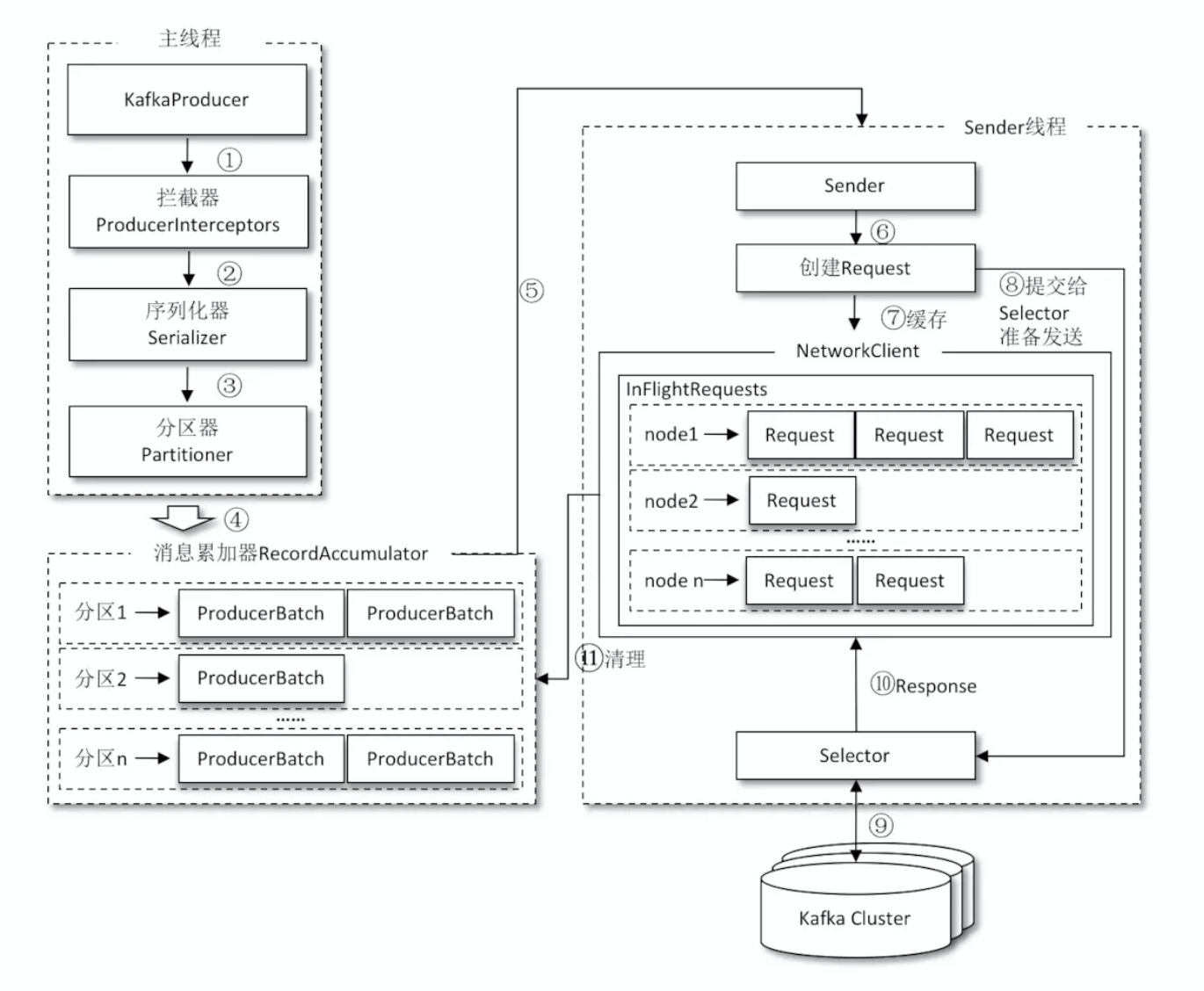
- 主线程
主线程负责创建消息, 依次通过生产者拦截器 -> 序列化器 -> 分区器到达消息累加器RecordAccumulator.- 生产者拦截器: 可以类比于中间件, 可以对特定消息做处理, 比如过滤和统计等
- 序列化器: 把消息对象转换为字节数组后发送Kafka集群
- 分区器: 这里可以设置消息到哪个分区的规则
- 指定该消息到达分区
- 轮询分区, 适合于对消息次序不敏感, 消息量较大的情况, 这样消费者可以更好地均衡消费
- 指定路由key, 相同的key的消息达到相同的分区, 保证消息在分区内的顺序
- 消息收集器RecordAccumulator
- 主要目的是缓存消息, 方便Sender线程批量发送, 较少网络传输消耗. 默认大小是32M, 可通过KafkaProducer参数buffer.memory 配置. 如果生产者速度过快超过发送的速度, 那么send方法会阻塞或异常, 超时时间由
max.block.ms控制 - 内部为每一个分区维护了一个
双端队列, 写入消息到尾部, Sender从头部读. 队列内容是ProducerBatch - ProducerBatch不是单个的消息, 而是一批消息, 包含很多ProducerRecord(单个消息)
- 当一条消息(ProducerRecord)进入RecordAccumulator, 首先需要找与分区对应的双端队列(没有就创建), 在从队列尾部获取一个ProducerBatch(如果没有则新建), 再看ProducerBatch还有没有空间写入, 如果没有空间, 需要看该消息是否 > batch.size, 如果不大于就按照batch.size的大小新建, 如果大于就按照实际大小新建
- 主要目的是缓存消息, 方便Sender线程批量发送, 较少网络传输消耗. 默认大小是32M, 可通过KafkaProducer参数buffer.memory 配置. 如果生产者速度过快超过发送的速度, 那么send方法会阻塞或异常, 超时时间由
- Sender线程
Sender线程负责从RecordAccumulator获取消息发送到Kafka集群.- 将
<分区, Deque<ProducerBatch>>转换为<Node, List<ProducerBatch>>. Node表示kafka节点 - 将
<Node, List<ProducerBatch>>转换为<Node, Request>形式, 然后把Request发往各个Node
- 将
- InFlightRequests
- Sender线程发往Kafka之前会将消息保存到InFlightRequests中, 主要存储格式是
Map<NodeId, Deque>, 主要缓存了已经发出去但是还没有收到响应的请求. 这个Deque的配置参数是max.in.flight.requests. per. connection(默认为5). 通过比较配置参数和实际Deque的大小来判断是否还能再向这个连接发送请求, 除非缓存的请求收到响应从队列移除 - 通过InFlightRequests可以得到负载最低的Node, 叫做leastLoadedNode, 因为未确认的请求越多说明负载越高
- Sender线程发往Kafka之前会将消息保存到InFlightRequests中, 主要存储格式是
以下公众号是我个人运营的, 初衷是可以适当备份自己的笔记, 之后想可能会帮到更多的人. 发文时间不固定, 尽可能每篇文章直奔主题, 不去占用大家宝贵的时间. 如觉得对你有用, 欢迎关注交流.
