| 什么是编排 |
Kubernetes中,我们总是在说一个概念:编排.
在[Kubernetes]谈谈Kubernetes的本质这篇文章中,关于"编排"的概念介绍了一下:过去很多集群管理项目所擅长的都是把一个容器,按照某种规则,放置在某个最佳节点上运行起来,这种功能我们称为"调度".但Kubernetes项目所擅长的,是按照用户的意愿和整个系统的规则,完全自动化处理好容器之间的各种关系,这种功能,叫做编排.
这篇文章就尝试来讲一下,编排.
| 编排是如何实现的 |
不知道你对kube-controller-manager这个组件还有没有印象.这个组件实际上就是一系列控制器的集合.而Deployment,正是一系列控制器集合中的一种.
咱们来举个例子,来解释一下Deployment的作用.现在定义一个nginx的YAML文件,内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
我们可以看到,这个Deployment定义的编排动作非常简单,要做的就是:确保携带了app=nginx标签的Pod的个数,永远等于spec.replicas指定的个数,即2个.
这意味着,如果在这个集群中,携带app=nginx标签的个数大于2的时候,就会有旧的Pod被删除;反之,则会有新的Pod被创建.
在这里,我们需要提到一个概念:控制循环.我先上一段伪代码,来描述一下控制循环概念:
for {
实际状态 = 获取集群中对象 X 的实际状态(Actual State)
期望状态 = 获取集群中对象 X 的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
应该能够看出,实际状态往往来自Kubernetes集群本身.而期望状态,一般来自于用户提交的YAML文件.基于上面的伪代码,来讲讲,Deployment是如何实现控制循环的.
- 1,Deployment控制器从Etcd中获取到所有携带了"app:nginx"标签的Pod,然后统计它们的数量,这就是实际状态;
- 2,Deployment对象的Replicas字段的值就是期望状态;
- 3,Deployment控制器将两个状态作比较,然后根据比较结果,确定是创建Pod,还是删除已有的Pod
| 控制器的完整实现 |
上面只是一个概述.这一部分详细讲讲控制器的完整实现:Deployment.
Deployment看似简单,但实际上,它实现了Kubernetes项目中一个非常重要的功能:Pod的"水平扩展/收缩".
比较难以理解?没关系,咱们来举个例子.假设更新了Deployment的Pod模板(比如,修改了容器的镜像),那么Deployment就需要遵循一种叫做"滚动更新"的方式,来升级现有的容器,而这个能力的实现,依赖的是Kubernetes中一个非常重要的API对象:ReplicaSet.它的组成也很简单:副本数目的定义和一个Pod模板.
我们可以发现,所谓的ReplicaSet对象,其实是Deployment的一个子集.而实际上,Deployment控制器实际操纵的,正是这样的ReplicaSet对象,而不是Pod对象.
在这个基础上,咱们一起来分析一下下面的这个Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
从上面我们可以看到,这就是一个nginx-deployment,它定义的Pod副本个数是3(spec.replicas=3).具体实现是这样的:
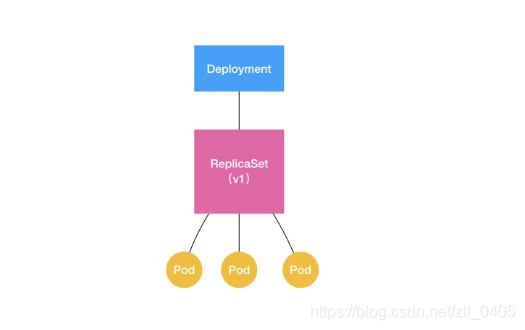
这样我们就能很清楚的看到了,Deployment,ReplicaSet,Pod之间,是一种"层层控制"的关系.ReplicaSet负责通过"控制器模式",保证系统中Pod的个数永远等于指定的个数.这也是在Deployment中,为什么只允许容器的restartPolicy=Always的原因:只有在容器能保证自己始终是Running状态的前提下,ReplicaSet调整Pod的个数才有意义.
在此基础上,Deployment同样通过"控制器模式",来操作ReplicaSet的个数和属性,进而实现"水平扩展/收缩"和"滚动更新"这两个编排动作."水平扩展/收缩"非常容易实现,Deployment Controller只需要修改它所控制的ReplicaSet的Pod副本个数就可以了.而在"滚动更新"这个动作中,它有一个状态转换的过程:
- DESIRED:用户期望的Pod副本数(spec.replicas的值);
- CURRENT:当前处于Running状态的Pod的个数;
- UP-TO-DATE:当前处于最新版本的Pod的个数,就是说,Pod的Spec部分与Deployment中Pod模板里定义的完全一致;
- AVAILABLE:当前已经可用的Pod的个数,即:既是Running状态,又是最新版本,并且已经处于Ready(健康检查正确)状态的Pod的个数
| 滚动更新的详细过程 |
在这一部分,我详细讲述一下"滚动更新"这个过程.这样,会对"滚动更新"的好处,有一个比较好的理解.
来个小前提:假设我需要"滚动更新"3个Pod.
当我修改了Deployment里的Pod定义之后,Deployment Controller会使用这个修改后的Pod模板,创建一个新的ReplicaSet,此时这个ReplicaSet的初始Pod副本数是:0;
然后,Deployment Controller开始将这个新的ReplicaSet所控制的Pod副本数从0个变成1个,即:"水平扩展"出一个副本;
紧接着,Deployment Controller又将旧的ReplicaSet所控制的旧Pod副本数减少一个,即:“水平收缩"成两个副本.
如此交替进行,新ReplicaSet管理的Pod副本数,从0个变成1个,再变成2个,最后变成3个.与此同时,旧的ReplicaSet管理的Pod副本数则从3个变成2个,再变成1个,最后变成0个.
像这样,将一个集群中正在运行的多个Pod版本,交替地逐一升级过程,就是"滚动更新”
在你详细了解"滚动更新"的过程之后,你就会对它所带来的好处,有一个好的了解.
比如,在升级刚开始的时候,集群里只有1个新版本的Pod,如果这个时候,新版本Pod有问题启动不起来,那么"滚动更新"就会停止,允许开发和运维人员介入解决问题,而这个应用本身还有两个旧版本的Pod在线,所以服务不会受到太大的影响.
想和大家分享的内容,讲的差不多了
以上内容来自我学习<深入剖析Kubernetes>专栏文章之后的一些见解,有偏颇之处,还望指出.
感谢您的阅读~