问题:
Natural language sentence matching (NLSM),自然语言句子匹配,是指比较两个句子并判断句子间关系,是许多任务的一项基本技术。针对NLSM任务,目前有两种流行的深度学习框架。一种是Siamese network: 对两个输入句子通过同样的神经网络结构得到两个句子向量,然后对这两个句子向量做匹配。这种共享参数的方式可以有效减少学习的参数,让训练更方便。但是这种方式只是针对两个句子向量做匹配,没有捕捉到两个句子之间的交互信息。于是有了第二种框架matching-aggregation:先对两个句子之间的单元做匹配,匹配结果通过一个神经网络(CNN或LSTM)聚集为一个向量后做匹配。这种方式可以捕捉到两个句子之间的交互特征,但是之前的方式只是基于词级别的匹配忽略了其他层级的信息,匹配只是基于一个方向忽略了相反的方向。
为了解决matching-aggregation框架的不足,这篇文章提出了一种双向的多角度匹配模型(bilateral multi-perspective matching)。该模型在同义识别、自然语言推理、答案选择任务上都取得了比较好的结果。
主要方法:
NLSM中每个样例可以表示为这样一个三元组:(P, Q, y),其中P表示长度为M的句子序列,Q表示长度为N的句子序列,y表示P和Q之间关系的标签。模型的目标就是学习概率分布Pr(y|P,Q),整体结构如下:
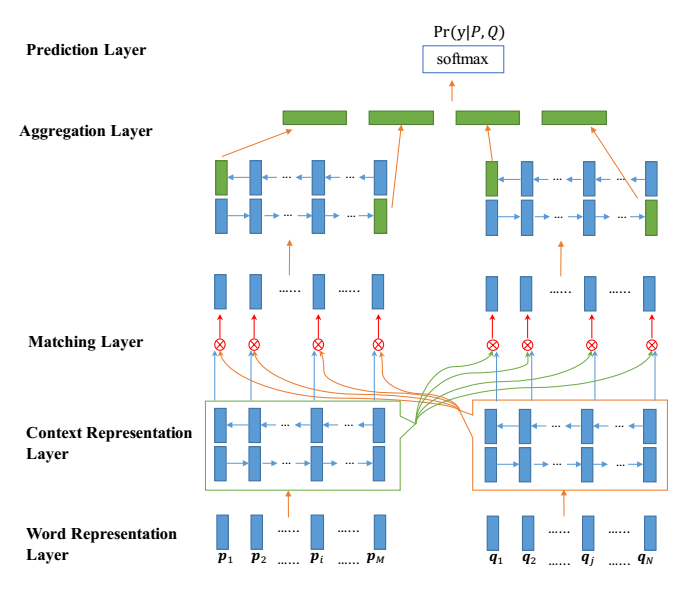
Word Representation Layer:将句子中的每个单词表示为d维向量,这里d维向量分为两部分:一部分是固定的词向量,另一部分是字符向量构成的词向量。这里将一个单词里面的每个字符向量输入LSTM得到最后的词向量。
Context Representation Layer:将上下文信息融合到P和Q每个time-step的表示中,这里利用Bi-Lstm表示P和Q每个time-step的上下文向量。
Matching Layer:
双向:比较句子P的每个上下文向量(time-step)和句子Q的所有上下文向量(time-step),比较句子Q的每个上下文向量(time-step)和句子P的所有上下文向量(time-step)。为了比较一个句子的某个上下文向量(time-step)和另外一个句子的所有上下文向量(time-step),这里设计了一种 multi-perspective匹配方法。这层的输出是两个序列,序列中每一个向量是一个句子的某个time-step对另一个句子所有的time-step的匹配向量。
Aggregation Layer.:聚合两个匹配向量序列为一个固定长度的匹配向量。对两个匹配序列分别应用BiLSTM,然后连接BiLSTM最后一个time-step的向量(4个)得到最后的匹配向量。
Prediction Layer:预测概率Pr(y|P;Q),利用两层前馈神经网络然后接softmax分类。
Multi-perspective Matching
首先,定义比较两个向量的multi-perspective余弦函数:
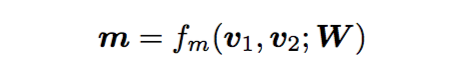
这里和
是d维向量,W是
的可训练的参数,
表示的是perspcetive的个数,所以m是一个
维的向量,每一维度表示的是两个加权向量的余弦相似度:
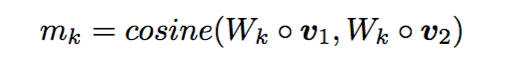
接着,为了比较一个句子的某个time-step与另一个句子的所有time-step,制定了四种匹配策略。为了避免重复,仅从一个方向进行描述,以从P到Q为例:
这里的Multi-perspective Matching可以分为以下四种方案:
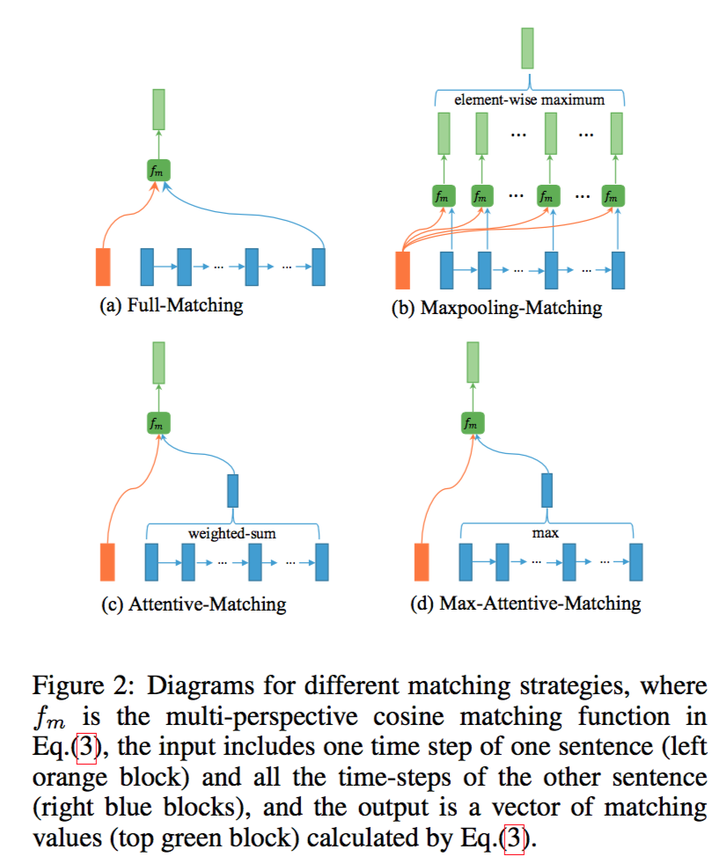
(1) Full-Matching
取一个句子的某个time-step和另一个句子的最后一个time-step做比较
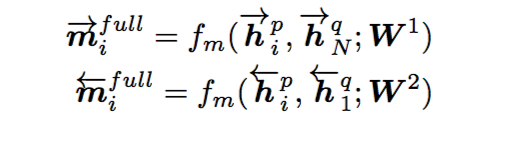
(2) Max-pooling-Matching
取一个句子的某个time-step和另一个句子的所有time-step比较后取最大
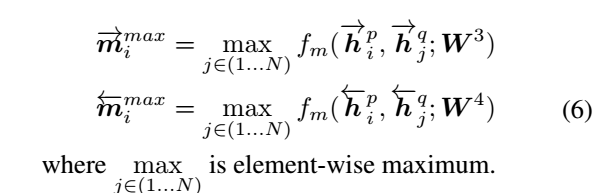
(3) Attentive-Matching
首先计算一个句子的某个time-step和另一个句子的所有time-step的余弦相似度
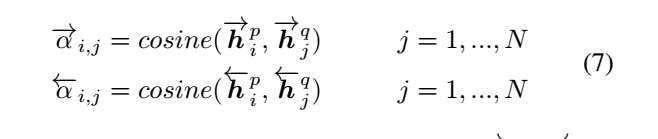
利用上面的余弦相似度对另一个句子的所有time-step加权取平均
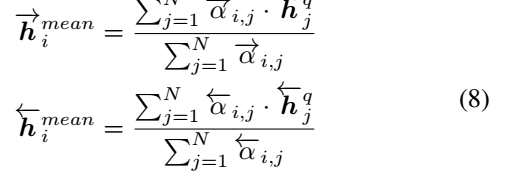
后比一个句子的某个time-step与另一个句子的加权time-step
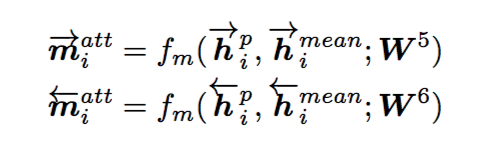
(4) Max-Attentive-Matching
方法与(3)类似,只是加权平均变成了取最大
实验结果:
1 paraphrase identification 同义识别
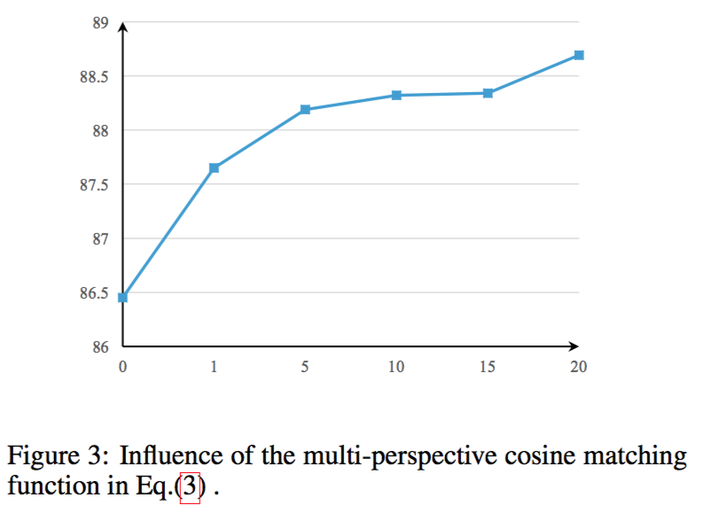
首先判断perspective数目对模型的影响:
判断双向的有效性和模型融合策略的有效性:
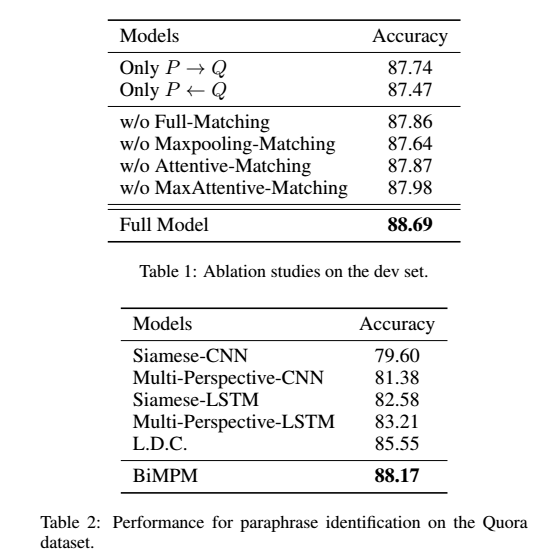
和当前state-of-art的结果比较,证明本模型的有效性。
2 Natural Language Inference 自然语言推理
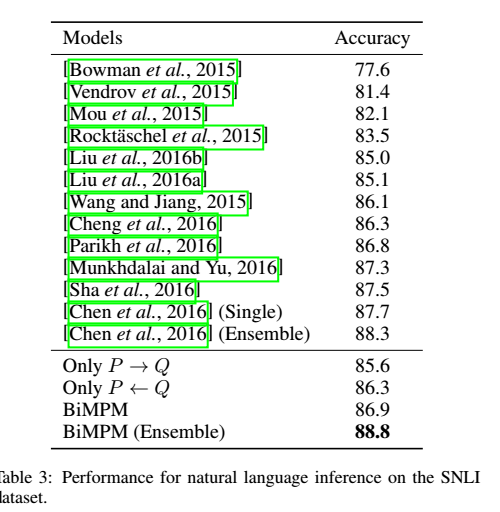
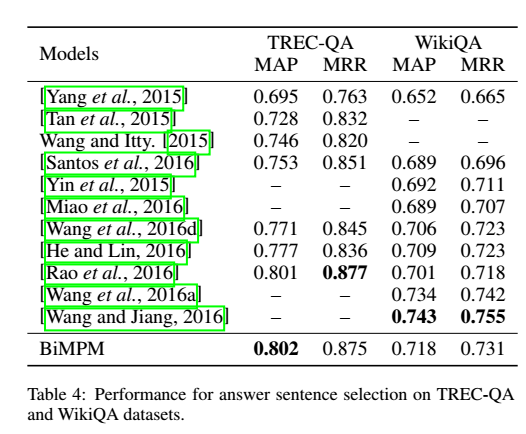
3 Answer Sentence Selection 答案选择
简评:
这篇文章主要是研究句子匹配的问题:
用biLSTM对两个给定句子分别编码,从两个方向P->Q,Q->P对其匹配。在匹配过程中,从多视野的角度,一个句子的每一步都与另一个句子的所有time-steps对应匹配。最后用一个BiLSTM被用来集合所有匹配结果到一个固定长度的向量,连上一个全连接层得到匹配的结果。本文模型在三个任务上的实验结果证明了模型的有效性。此外,本文用到词级别和字符级别的词向量。传统的Siamese网络结构忽视了低层级的交互特征,重点放在向量表示上。现阶段的一些模型更加注重句子之间交互信息,从不同层次不同粒度来匹配句子的模型越来越多。本文就是基于matching-aggregation框架,从多个视角不同方向去提取句子的特征,得到了更好的结果。
参考:https://zhuanlan.zhihu.com/p/26548034