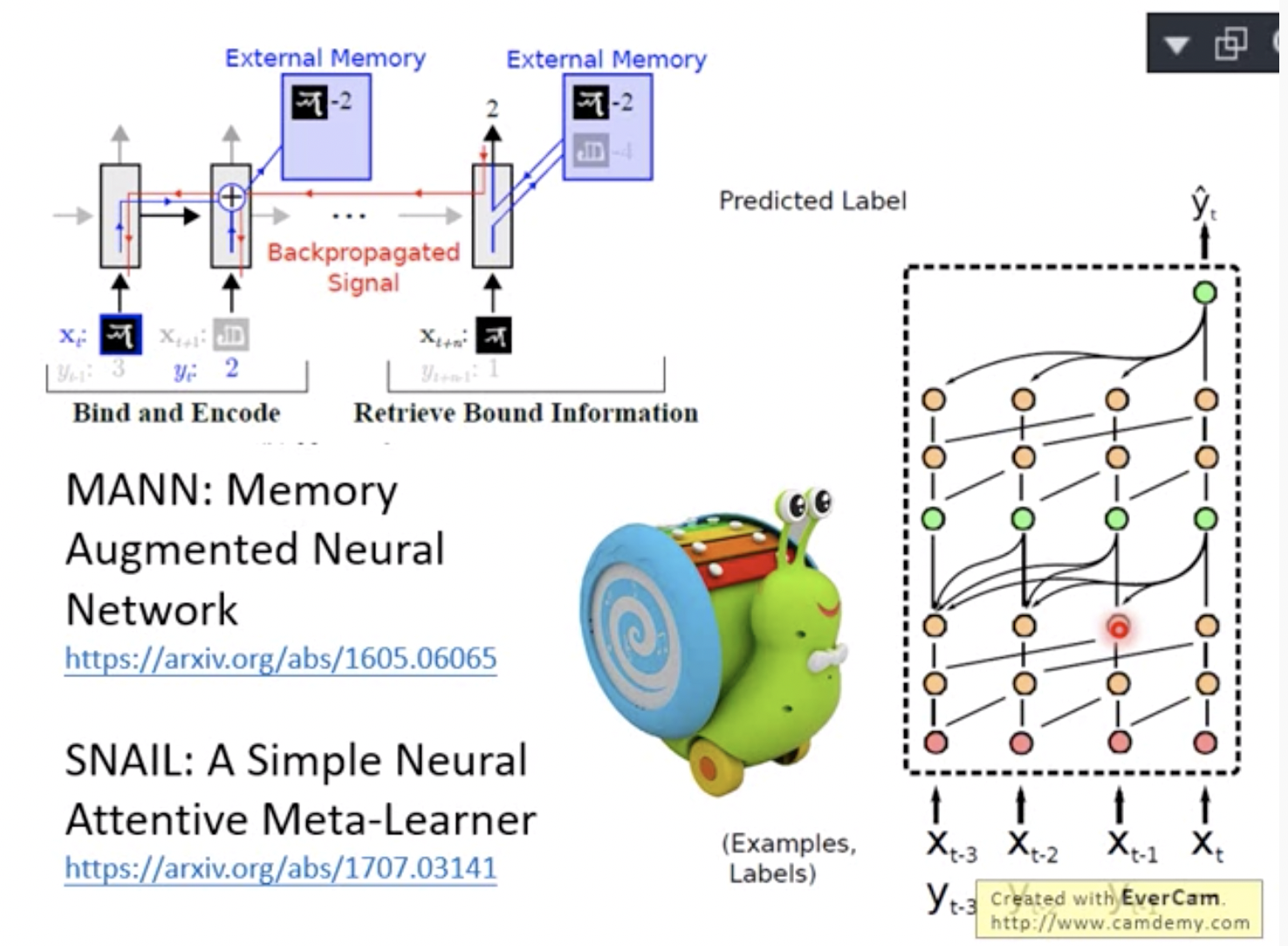
如果在 Few-shot Learning 的任务中去训练普通的基于 cross-entropy 的神经网络分类器,那么几乎肯定是会过拟合,因为神经网络分类器中有数以万计的参数需要优化。
相反,很多非参数化的方法(最近邻、K-近邻、Kmeans)是不需要优化参数的,因此可以在 meta-learning 的框架下构造一种可以端到端训练的 few-shot 分类器。该方法是对样本间距离分布进行建模,使得同类样本靠近,异类样本远离。下面介绍相关的方法。
一、孪生网络(Siamese Network)
如图 4 所示,孪生网络(Siamese Network)[4] 通过有监督的方式训练孪生网络来学习,然后重用网络所提取的特征进行 one/few-shot 学习。
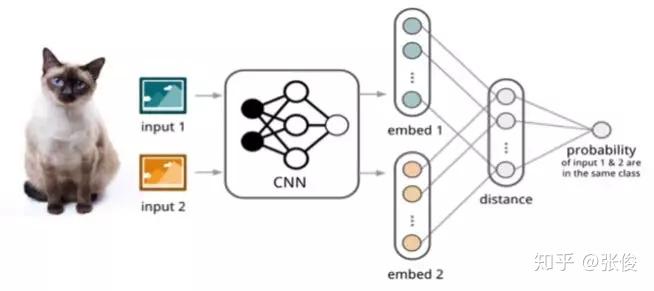 ▲ 图4:Siamese Network
▲ 图4:Siamese Network
具体的网络是一个双路的神经网络,训练时,通过组合的方式构造不同的成对样本,输入网络进行训练,在最上层通过样本对的距离判断他们是否属于同一个类,并产生对应的概率分布。在预测阶段,孪生网络处理测试样本和支撑集之间每一个样本对,最终预测结果为支撑集上概率最高的类别。
二、匹配网络(Match Network)
相比孪生网络,匹配网络(Match Network)[2] 为支撑集和 Batch 集构建不同的编码器,最终分类器的输出是支撑集样本和 query 之间预测值的加权求和。
如图 5 所示,该文章也是在不改变网络模型的前提下能对未知类别生成标签,其主要创新体现在建模过程和训练过程上。对于建模过程的创新,文章提出了基于 memory 和 attention 的 matching nets,使得可以快速学习。
对于训练过程的创新,文章基于传统机器学习的一个原则,即训练和测试是要在同样条件下进行的,提出在训练的时候不断地让网络只看每一类的少量样本,这将和测试的过程是一致的。
具体地,它显式的定义一个基于支撑集 的分类器,对于一个新的数据
,其分类概率由
与支撑集 S 之间的距离度量得出:
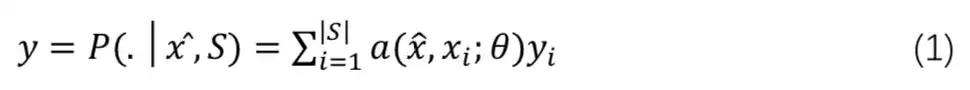
其中 a 是基于距离度量的 attention score:
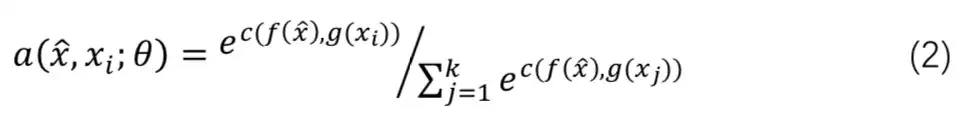
进一步,支撑集样本 embedding 模型 g 能继续优化,并且支撑集样本应该可以用来修改测试样本的 embedding 模型 f。
这个可以通过如下两个方面来解决,即:1)基于双向 LSTM 学习训练集的 embedding,使得每个支撑样本的 embedding 是其它训练样本的函数;2)基于 attention-LSTM 来对测试样本 embedding,使得每个 Query 样本的 embedding 是支撑集 embedding 的函数。文章称其为 FCE (fully-conditional embedding)。

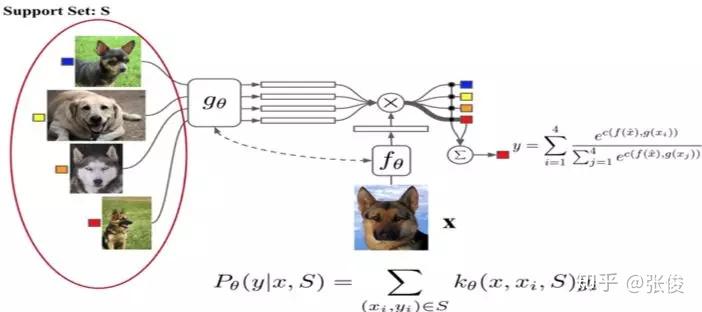 ▲ 图5:Match Network
▲ 图5:Match Network
三、原型网络(Prototype Network)
原型网络(Prototype Network)[5] 基于这样的想法:每个类别都存在一个原型表达,该类的原型是 support set 在 embedding 空间中的均值。然后,分类问题变成在 embedding 空间中的最近邻。
如图 6 所示,c1、c2、c3 分别是三个类别的均值中心(称 Prototype),将测试样本 x 进行 embedding 后,与这 3 个中心进行距离计算,从而获得 x 的类别。
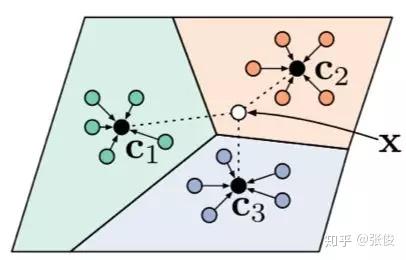 ▲ 图6:Prototype Network
▲ 图6:Prototype Network

文章采用在 Bregman 散度下的指数族分布的混合密度估计,文章在训练时采用相对测试时更多的类别数,即训练时每个 episodes 采用 20 个类(20 way),而测试对在 5 个类(5 way)中进行,其效果相对训练时也采用 5 way 的提升了 2.5 个百分点。
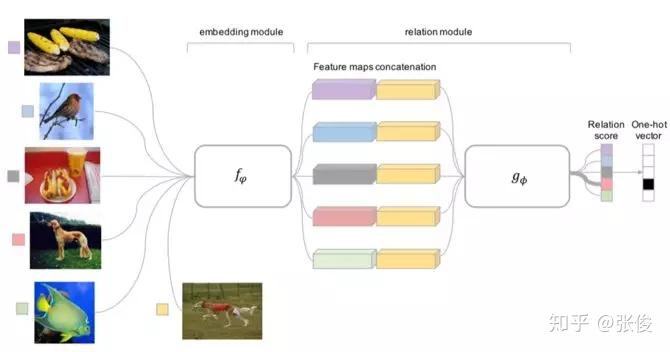
四、Relation Network
前面介绍的几个网络结构在最终的距离度量上都使用了固定的度量方式,如 cosine,欧式距离等,这种模型结构下所有的学习过程都发生在样本的 embedding 阶段。
而 Relation Network [6] 认为度量方式也是网络中非常重要的一环,需要对其进行建模,所以该网络不满足单一且固定的距离度量方式,而是训练一个网络来学习(例如 CNN)距离的度量方式,在 loss 方面也有所改变,考虑到 relation network 更多的关注 relation score,更像一种回归,而非 0/1 分类,所以使用了 MSE 取代了 cross-entropy。
五、