1、var let const 区别实例
<script type="text/javascript"> var aa = 1; function fn(n) { console.log(aa); var aa = 2; } fn();//undefinde var 定义变量会变量提升,提升到函数局部的顶部,但是变量的赋值不会提升,所以是函数内部变量有声明而未定义, console.log(aa);//1 </script> <script type="text/javascript"> let aa = 1; function fn(n) { console.log(aa); let aa = 2; } fn(); console.log(aa);//程序报错 aa is not defined let 声明变量不会变量提升,let不能重复赋值 let会形成暂时性死区 不会向函数外去找已定义的变量 所以会报错 </script> <script type="text/javascript"> const aa = 1; function fn(n) { console.log(aa); const aa = 2; } fn(); console.log(aa);//程序报错 aa is not defined const继承了let的特性,且const声明变量不可更改 </script>
2、
var arr2 = [1,2,3,4]; function aa(arr){
//形参预解析 var arr = arr2;
console.log(arr); //[1,2,3,4,5] arr.push(5)
} aa(arr2); console.log(arr2);//[1,2,3,4,5]
3、
getName(); //5 函数提升优先级比变量提升要高,且不会被变量声明覆盖,但是会被变量赋值覆盖。 var getName = function () { console.log(4); }; function getName() { console.log(5); } getName(); //4 被变量赋值覆盖
4、this指向
var fullname = 'John Doe'; var obj = { fullname: 'Colin Ihrig', prop: { fullname: 'Aurelio De Rosa', getFullname: function () { return this.fullname; } } }; console.log(obj.prop.getFullname()); //Aurelio De Rosa // 函数的最终调用者 obj.prop var test = obj.prop.getFullname; console.log(test()); //John Doe // 函数的最终调用者 test() this-> window obj.func = obj.prop.getFullname; console.log(obj.func()); //Colin Ihrig // 函数最终调用者是obj var arr = [obj.prop.getFullname, 1, 2]; arr.fullname = "JiangHao"; //JiangHao console.log(arr[0]()); // 函数最终调用者数组
5、面向对象
function Foo() { getName = function () { console.log(1); }; return this; } Foo.getName = function () { console.log(2); }; Foo.prototype.getName = function () { console.log(3); }; var getName = function () { console.log(4); }; function getName() { console.log(5); } Foo.getName(); //2 getName(); //4 Foo().getName();//1 getName(); //4 new Foo.getName();//2 new Foo().getName(); //3 new new Foo().getName();//3
做这道题时,首先要明白一点:就是一开始的函数申明,function Foo(),在没有调用之前,始终是不会运行的.
1.Foo.getName()输出2!
此处函数Foo()没有调用,不执行函数,后面的输出均于此函数什么时候调用有密切关系.
此处的Foo是一个实例化对象,跟1行处的Foo除了同名再无其他关系.所以直接找到第5行处.这里第5行表示给Foo对象添加一个输出为2的方法.
2.getName()输出4.
此处直接调用getName(),1行处的函数未执行,从上往下寻找,首先找到
第7行处,定义的getName对象.
3.Foo().getName()输出1
此处先运行Foo(),这里就调用第1行的函数了,运行后return一个this,这里调用Foo()的是window,所以this就指window。后面相当于window.getName()就直接找到函数内部getName()方法了.
4.getName()输出1
因为在3中已经执行过Foo()函数了,函数内部内容有效.getName()无直接写明调用对象,此处调用的对象就是window,函数体内部,getName也并未重新定义,而是一个全局的getName(即window的方法),此处直接找到第二行处.
5.new Foo.getName()输出2
以先执行5行处 Foo.getName()得到function(){console.log(2);}然后在 new function(){console.log(2);}
6.new Foo().getName()输出3
此处,先函数调用Foo(),接着运行new Foo(),再用new得到的这个实例化对象运行属性getName(),而getName()是通过6行处的原型链来定义的,所以找到第6行.
7.new new Foo().getName()输出3
此处有2个new,先执行右边的new Foo()得到一个实例化对象,这时,就无法运行左边的new了(总不至于new 后边跟一个实例对象吧),只能先运行后边的 .getName()得到一个函数,最后执行最左边的new.
六、
for (var i = 0; i < 5; i++) { console.log(i); } //0,1,2,3,4 不解释 for (var i = 0; i < 5; i++) { setTimeout(function () { console.log(i); }, 1000 * i); } //setTimeout 会延迟执行,那么执行到 console.log 的时候,其实 i 已经变成 5 了 ,开始输出一个 5,然后每隔一秒再输出一个 5,一共 5 个 5。 for (var i = 0; i < 5; i++) { (function (i) { setTimeout(function () { console.log(i); }, i * 1000); })(i); } //运用闭包 i 以参数的形式传到函数内部,这时候i 就是函数的内部变量, 就不会更改了,所以是 0,1,2,3,4 for (var i = 0; i < 5; i++) { (function () { setTimeout(function () { console.log(i); }, i * 1000); })(i); } //这个函数中没有形参,实参i传不进去,所以函数内部没有变量i,然后会向函数外去找变量i,当延时器触发函数的时候,这时i已经是5了,所以会是 5个5 for (var i = 0; i < 5; i++) { setTimeout((function (i) { console.log(i); })(i), i * 1000); } //因为传入的是一个自执行函数,当执行到这个代码的时候已经执行了,所以 0,1,2,3,4 //JS预解释: 在进入执行上下文阶段的时候函数并不会执行,简单来说就是当你声明这个函数的时候,只要不调用就不会执行,上下文里面只会保存着这个函数的引用,可以看做这个函数保存在内存中,只有到调用的时候函数才会执行,延时器的作用就是稍后调用这个函数,当是自执行函数的时候,就回直接执行了了。 setTimeout(function () { console.log(1) }, 0); new Promise(function executor(resolve) { console.log(2); for (var i = 0; i < 10000; i++) { i == 9999 && resolve(); } console.log(3); }).then(function () { console.log(4); }); console.log(5); //首先先碰到一个 setTimeout,于是会先设置一个定时,在定时结束后将传递这个函数放到任务队列里面,因此开始肯定不会输出 1 。 // 然后是一个 Promise,里面的函数是直接执行的,因此应该直接输出 2 3 。 // 然后,Promise 的 then 应当会放到当前 tick 的最后,但是还是在当前 tick 中。 // 因此,应当先输出 5,然后再输出 4 。 // 最后在到下一个 tick,就是 1 。 // “2 3 5 4 1”
6、vue刷新页面以后丢失store的数据问题?
刷新页面时vue实例重新加载,store就会被重置,可以把定义刷新前把store存入本地localStorage、sessionStorage、cookie中,localStorage是永久储存,重新打开页面时会读取上一次打开的页面数据,sessionStorage是储存到关闭为止,cookie不适合存大量数据。根据我的需求,最合适的是sessionStorage。
beforeunload在页面刷新时触发,可以监听这个方法,让页面在刷新前存store到sessionStorage中。
当然,在页面刷新时还要读取sessionStorage中的数据到store中,读取和储存都写在app.vue中。
7、隐式转换
var str = false + 1; document.write(str); //1 var demo = false == 1; document.write(demo); //false if(typeof(a)&&-true+(+undefined)+""){ console.log(1); } //能打印出1 // typeof(a) typeof打印未声明的变量不会报错,结果为字符串 "undefined" //-true 为 -1 //+undefined 隐式转换 undefined 转换为数字 转不成结果为 NaN //-1+NaN+"" 结果为字符串 "NaN" //所以if("undefined" && "NaN") 为true ,结果能打印 if(11 + "11" * 2 == 33){ console.log(1); } //"11" * 2 为 22 22+11 = 33 if结果为true 所以能打印 !!" " + !!"" - !!false||document.write(333); //双叹号 !! 是将表达式强制转化为bool值的运算,运算结果为true或false,表达式是什么值,结果就是对应的bool值,不再取非。 // !!" " true // !!"" false // !!false false // 1+0-0 = 1 为真 不走后面 所以不会打印
8、js中的 async 和 defer 有什么区别
1)没有这个两个属性时,浏览器遇到script时,文档解析停止,其他线程现在下载并执行js脚本,执行完后接续解析文档
2)添加async 时,文档解析不会停止,其他线程下载js脚本,脚本下载完成后开始执行脚本,执行脚本时文档停止解析,直到脚本解析完成,再继续解析 (异步下载,并立即执行)
3)添加defer时,文档的解析不会停止,其他线程下载脚本,待文档解析完成之后,脚本才会执行。 (一步下载,待文档解析完成后,执行)
9、新增数据类型
1)set集合 :是Object里面的一种, set与数组不同在于set中不可以有重复数据,常用语去重操作
2)Map类型:可以允许任何类型作为对象的键,弥补了object只能使用字符串作为键的问题
3)symbol : Symbol意思是符号,有一个特性—每次创建一个Symbol值都是不一样的。
symbol是程序创建并且可以用作属性键的值,并且它能避免命名冲突的风险。
创建的方式也有点奇怪,只能通过调用全局函数Symbol()来完成。
let firstSymbol = Symbol();
10、display:inline-block的间隙问题和解决办法
1) block水平的元素inline-block后,IE6/7没有换行符间隙问题,其他浏览器均有,
2)inline水平的元素 inline-block后,所有主流浏览器都换行符 空格间隙问题。
3)解决方法:
①移除标签间的空格。(代码不优雅)
②在父元素上加上font-size:0;以及 letter-spacing 为负值
11、块级元素,行内元素,空元素
空元素就是单个标签的 <br/> meta <hr/> input img (这样的就叫空元素)
12、ajax的缺点
1)ajax不支持浏览器返回按钮
2)安全问题,ajax暴露了与服务器交互的细节
3)对搜索引擎的支持比较弱
4)破坏了程序的异常机制
5)不容易调试
13、git fetch 和git pull 的差别
1)git fetch 相当于是从远程获取最新到本地,不会自动merge
2)git pull:相当于是从远程获取最新版本并merge到本地
在实际使用中,git fetch更安全一些 注:用git pull更新代码的话就比较简单暴力了但是根据commit ID来看的话,他们实际的实现原理是不一样的,所以不要用git pull,用git fetch和git merge更加安全。
14、@supports CSS3新引入的规则之一,主要用于检测当前浏览器是否支持某个CSS属性并加载具体样式.(浏览器支持不完善)
@supports (display: grid) {
.container {
color: red;
}
}
当浏览器支持display:grid这个CSS属性时才应用其中的样式
15、@media 媒体查询
@media screen and (max- 300px) { body { background-color:lightblue; } }
16、-webkit-backface-visibility 属性定义当元素不面向屏幕时是否可见。
| visible | 背面是可见的。 |
| hidden | 背面是不可见的。 |
//隐藏被旋转的 div 元素的背面:
div { backface-visibility:hidden; -webkit-backface-visibility:hidden; /* Chrome 和 Safari */ -moz-backface-visibility:hidden; /* Firefox */ -ms-backface-visibility:hidden; /* Internet Explorer */ }
17、overflow-scrolling
-webkit-overflow-scrolling 属性控制元素在移动设备上是否使用滚动回弹效果. auto: 使用普通滚动, 当手指从触摸屏上移开,滚动会立即停止。 touch: 使用具有回弹效果的滚动, 当手指从触摸屏上移开,内容会继续保持一段时间的滚动效果。继续滚动的速度和持续的时间和滚动手势的强烈程度成正比。同时也会创建一个新的堆栈上下文。
18、touch-action 用于设置触摸屏用户如何操纵元素的区域(例如,浏览器内置的缩放功能)。
—touch-action:none; (这句代码的意思是:禁止触发默认的手势操作)
touch-acion: auto | none | [ [ [ pan-x || pan-y || pinch-zoom ? ] | manipulation ] || double-tap-zoom ? ]
属性值
auto:
默认值。浏览器允许一些手势(touch)操作在设置了此属性的元素上,例如:对视口(viewport)平移、缩放等操作。
none:
禁止触发默认的手势操作。
pan-x:
可以在父级元素(the nearest ancestor)内进行水平移动的手势操作。
pan-y:
可以在父级元素内进行垂直移动的手势操作。
manipulation:
允许手势水平/垂直平移或持续的缩放。任何auto属性支持的额外操作都不支持。
注:touch-action只支持具有CSS width和height属性的元素。这个限制的目的是帮助浏览器优化低延时的手势操作。对于默认不支持此属性的元素,如这种内联元素,可以给它设置display:block这样的CSS属性来支持width和height。未来W3C规范会将此API扩展到支持所有元素。
18、pointer-events CSS 属性指定在什么情况下 (如果有) 某个特定的图形元素可以成为鼠标事件的 target。
pointer-events: none;
1 阻止用户的点击动作产生任何效果
2 阻止缺省鼠标指针的显示
3 阻止CSS里的hover和active状态的变化触发事件
4 阻止JavaScript点击动作触发的事件
19、NaN :非数字
alert(NaN==NaN) //false 基于这个原因 :定义了isNaN()函数。 判断其参数 是否“不是数值”
NaN不是数字,但是它的数据类型是数字
NaN在布尔运算时被当作false
console.log(isNaN('abc')); //true
Number.isNaN(NaN); // true Number.isNaN(Number.NaN); // true Number.isNaN(0 / 0) // true
Number.isNaN("NaN"); // false,字符串 "NaN" 不会被隐式转换成数字 NaN。 Number.isNaN(undefined); // false Number.isNaN({}); // false Number.isNaN("blabla"); // false
Number.isNaN = Number.isNaN || function(value) { return typeof value === "number" && isNaN(value); }
20、 get和post请求的区别
1) url可见性:
get,参数url可见;
post,url参数不可见
2)数据传输上:
get,通过拼接url进行传递参数;
post,通过body体传输参数
3)缓存性:
get请求是可以缓存的
post请求不可以缓存
4)后退页面的反应
get请求页面后退时,不产生影响
post请求页面后退时,会重新提交请求
5)传输数据的大小
get一般传输数据大小不超过2k-4k(根据浏览器不同,限制不一样,但相差不大)
post请求传输数据的大小根据php.ini 配置文件设定,也可以无限大。
6)安全性
这个也是最不好分析的,原则上post肯定要比get安全,毕竟传输参数时url不可见,但也挡不住部分人闲的没事在那抓包玩。安全性个人觉得是没多大区别的,防君子不防小人就是这个道理。对传递的参数进行加密,其实都一样。
21、什么是js事件流?
事件的概念:
HTML中与javascript交互是通过事件驱动来实现的,例如鼠标点击事件、页面的滚动事件onscroll等等,可以向文档或者文档中的元素添加事件侦听器来预订事件。
"DOM2事件流"规定的事件流包括三个阶段:
1,事件捕获阶段。
2,处于目标阶段。
3,事件冒泡阶段。
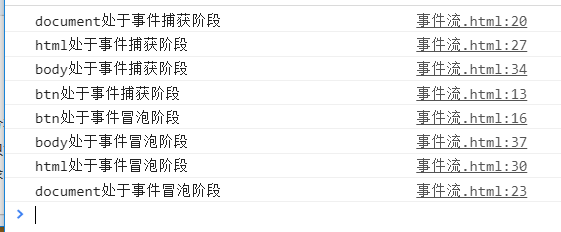
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>事件流</title> <script> window.onload = function(){ var oBtn = document.getElementById('btn'); oBtn.addEventListener('click',function(){ console.log('btn处于事件捕获阶段'); }, true); oBtn.addEventListener('click',function(){ console.log('btn处于事件冒泡阶段'); }, false); document.addEventListener('click',function(){ console.log('document处于事件捕获阶段'); }, true); document.addEventListener('click',function(){ console.log('document处于事件冒泡阶段'); }, false); document.documentElement.addEventListener('click',function(){ console.log('html处于事件捕获阶段'); }, true); document.documentElement.addEventListener('click',function(){ console.log('html处于事件冒泡阶段'); }, false); document.body.addEventListener('click',function(){ console.log('body处于事件捕获阶段'); }, true); document.body.addEventListener('click',function(){ console.log('body处于事件冒泡阶段'); }, false); }; </script> </head> <body> <a href="javascript:;" id="btn">按钮</a> </body> </html>
1,addEventListener
addEventListener是DOM2级事件新增的指定事件处理程序的操作,这个方法接收3个参数:要处理的事件名,作为事件处理程序的函数和一个布尔值,最后这个布尔值如果是true,表示在捕获阶段调用事件处理程序;如果是false,表示在冒泡阶段调用事件处理程序。
2,document,documentElement和document.body三者之间的关系:
document代表的是整个html页面,
document.documentElement代表是的<html>标签。
document.body代表的是<body>标签。
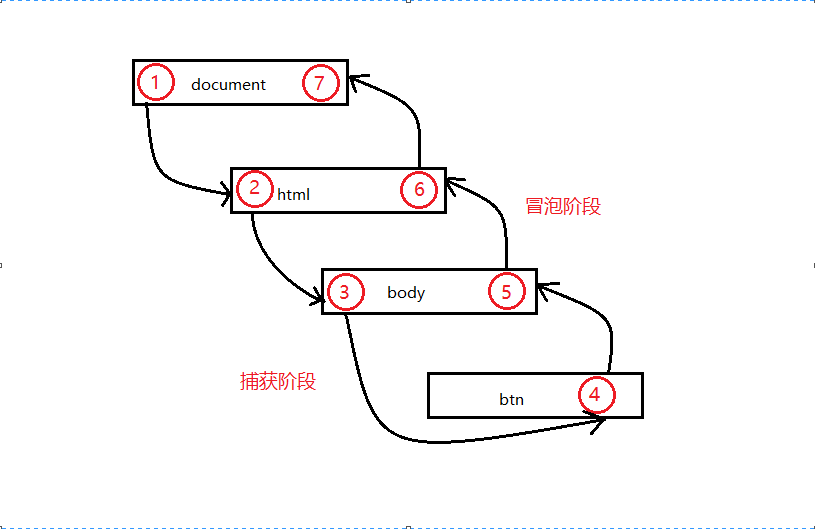
首先在事件捕获过程中,document对象首先接收到click事件,然后事件沿着DOM树依次向下,一直传播到事件的实际目标。就是id为btn的标签。
接着在事件冒泡的过程中,时间开始是由具体的元素(a标签)接收,然后逐级向上传播到较为不具体的节点。
22、浏览器内核的理解?
一般内核包含:渲染引擎:获取html,css,图片 js引擎:解析执行javascript
(1)Trident(IE内核)
国内很多的双核浏览器的其中一核便是 Trident,美其名曰 "兼容模式"。
代表: IE、傲游、世界之窗浏览器、Avant、腾讯TT、猎豹安全浏览器、360极速浏览器、百度浏览器等。
Window10 发布后,IE 将其内置浏览器命名为 Edge,Edge 最显著的特点就是新内核 EdgeHTML。
(2)Gecko(firefox)
Gecko(Firefox 内核): Mozilla FireFox(火狐浏览器) 采用该内核,Gecko 的特点是代码完全公开,因此,其可开发程度很高,全世界的程序员都可以为其编写代码,增加功能。 可惜这几年已经没落了, 比如 打开速度慢、升级频繁、猪一样的队友flash、神一样的对手chrome。
(3) webkit(Safari)
Safari 是苹果公司开发的浏览器,所用浏览器内核的名称是大名鼎鼎的 WebKit。
现在很多人错误地把 webkit 叫做 chrome内核(即使 chrome内核已经是 blink 了),苹果感觉像被别人抢了媳妇,都哭晕再厕所里面了。
代表浏览器:傲游浏览器3、 Apple Safari (Win/Mac/iPhone/iPad)、Symbian手机浏览器、Android 默认浏览器,
(4) Chromium/Blink(chrome)
在 Chromium 项目中研发 Blink 渲染引擎(即浏览器核心),内置于 Chrome 浏览器之中。Blink 其实是 WebKit 的分支。
大部分国产浏览器最新版都采用Blink内核。二次开发
(5) Presto(Opera)
Presto(已经废弃) 是挪威产浏览器 opera 的 "前任" 内核,为何说是 "前任",因为最新的 opera 浏览器早已将之抛弃从而投入到了谷歌怀抱了。
移动端的浏览器内核主要说的是系统内置浏览器的内核。
Android手机而言,使用率最高的就是Webkit内核,大部分国产浏览器宣称的自己的内核,基本上也是属于webkit二次开发。
iOS以及WP7平台上,由于系统原因,系统大部分自带浏览器内核,一般是Safari或者IE内核Trident的
23、css优先级
1)优先级就近原则,同权重的样式谁离标签内容近谁就优先级高;
2)载入样式以最后载入的定位为准;
3)!important优先级最高;
4)权重计算:
(1)内联,如style=”“——1000,
(2)id,如#content——100,
(3)类、伪类和属性选择器,如.content——10,
(4)标签选择器和伪元素选择器,如div p——1
(5)通配符、子选择器和相邻选择器,如*,>,+——0
24、什么是Cookie 隔离?
请求资源的时候不要让它带cookie怎么做
如果静态文件都放在主域名下,那静态文件请求的时候都带有的cookie的数据提交给server的,非常浪费流量,所以不如隔离开。
因为cookie有域的限制,因此不能跨域提交请求,故使用非主要域名的时候,请求头中就不会带有cookie数据,这样可以降低请求头的大小,降低请求时间,从而达到降低整体请求延时的目的。
同时这种方式不会将cookie传入Web Server,也减少了Web Server对cookie的处理分析环节,提高了webserver的http请求的解析速度。