设置utf-8
当前版本为5.7.14在mysql文件夹下的myl.ini设置
[mysqld] //加上下面两条 character_set_server = utf8
设置完后重启mysql
数据库存放数据格式一般为JSON 之前学习的是xxxx|xxxx|xxxx需要直接切割数据。
注意:
- JSON中属性名称必须用双引号
- JSON中表述字符串必须使用双引号
- JSON中不能有单行或多行注释
- JSON没有undefined这个值
mysql常用命令
show databases;
create database +数据库名; 创建一个指定名称的数据库
use +数据库; 使用一个数据库,相当于进入指定的数据库
show tables; 显示当前数据库中有哪些表
create table +表名 (几列,每列存什么数据格式); 创建一个指定名称的数据表,并添加几列
例如 创建 表名为user 有id,name,age,gender四列,其中id,age,gender存整数、name存字符串
create table user(id int ,name char(5) , age int, gender int);
desc +表名 查看指定表结构
可视化工具
使用navicat
设置链接mysql 连接 连接名自定 ,主机名localhost ,端口默认mysql 3306 ,密码为进入mysql密码。(使用wampserver 默认密码为空)
drop table +表名 删除表 删除就无法复原
drop +数据库 删除数据库
语法:
1.创建数据表
CREATE TABLE IF NOT EXISTS `mytable` ( `id` INT UNSIGNED AUTO_INCREMENT, `title` VARCHAR(100) NOT NULL, `date` DATE, PRIMARY KEY(`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INT UNSIGNED AUTO_INCREMENT 整数 无符号(非负数) 自增
PRIMARY KEY(`id`) id为主键 您可以使用多列来定义主键,列间以逗号分隔。
ENGINE 设置存储引擎 CHARSET 设置编码
创建数据库
CREATE DATABASE 数据库名
2.插入数据
INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN );
修改数据表名
ALTER TABLE 原表名 RENAME TO 新表名
修改数据表字段类型或字段名
#mysql修改字段类型 ALTER TABLE 表名 MODIFY COLUMN 字段名 新数据类型 新类型长度 新默认值 新注释; -- COLUMN可以省略 alter table table1 modify column column1 decimal(10,1) DEFAULT NULL COMMENT '注释'; -- 正常,能修改字段类型、类型长度、默认值、注释 #mysql修改字段名: ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型; alter table table1 change column1 column1 varchar(100) DEFAULT 1.2 COMMENT '注释'; -- 正常,此时字段名称没有改变,能修改字段类型、类型长度、默认值、注释
3.更新数据
UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause]
UPDATE runoob_tbl SET runoob_title='学习 C++' WHERE runoob_id=3;
更新数据表中 runoob_id 为 3 的 runoob_title 字段值:
4.删除数据
DELETE FROM runoob_tbl WHERE runoob_id=3;
删除表
DROP TABLE mytable ;
删除数据库
DROP DATABASE 数据库名
5.同一个数据库中不同表的查询
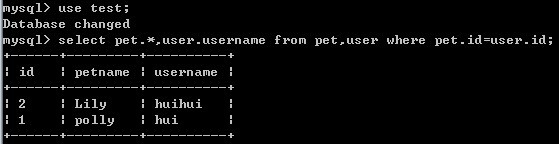
比如我要查询test数据库中 pet表 和 user表 中id相同的数据
先要使用 use test;把数据库切换到test。
select pet.*,user.username from pet,user where pet.id=user.id;
select语句后面可以加order by id,这样就可以按照id来排序了。
不同数据库中不同表的查询
比如我要查询 test数据库中 pet表 和huihui数据库中的 user表 中id相同的数据
因为是查询不同数据库中的内容~所以语句中要写清是哪个数据库中的表,所以这步不需要使用use来切换数据库,随便在哪个数据库里面都可以
select test.pet.*,huihui.user.name from test.pet,huihui.user where test.pet.id=huihui.user.id;
6.join连接数据
可以在 SELECT, UPDATE 和 DELETE 语句中使用 Mysql 的 JOIN 来联合多表查询。
JOIN 按照功能大致分为如下三类:
- left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
- right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
- inner join(等值连接) 只返回两个表中联结字段相等的行
以下一对一情况
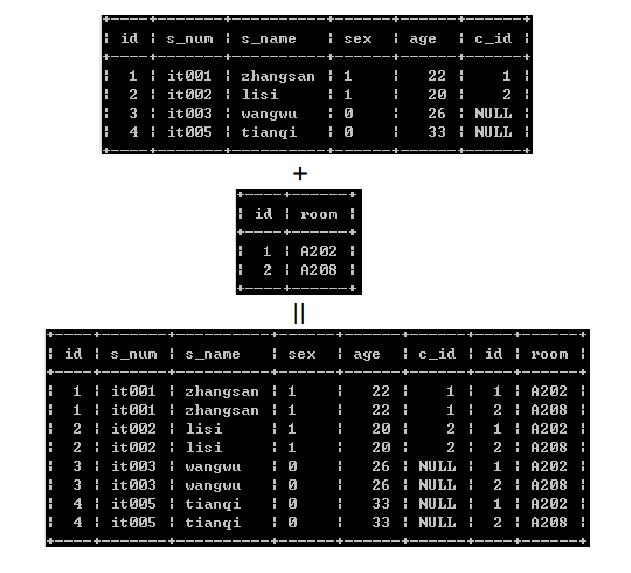
(1)交差连接(cross join)
用左表中的每一行数据去匹配右表中的每一行数据,且认为全部匹配成功。最终的结果集是迪卡尔积。
笛卡尔集是集合的一种,假设A和B都是集合,A和B的笛卡尔积用A X B来表示,是所有有序偶(a,b)的集合,其中a属于A,b属于B。 A X B={(a,b)|a属于A且b属于B} ,则AXB所形成的集合就叫笛卡尔集。
语法:
select * from 左表 cross join 右表; (无联接条件)
示例:
(2)内连接(inner join)
使用左表中的每一条记录去匹配右表的所有的记录,根据匹配的条件,如果成立,保留整条记录,如果不成立则丢弃。
用文氏图表示,则如下:
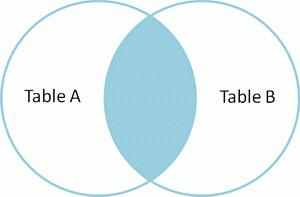
语法:
select * from 左表 【inner】 join 右表 【on 条件】(左表和右表 id 一 一对应)
示例:

(3)左连接(left join)
将左表作为主表,用主表中的每一条记录,去匹配从表(右表)中的所有记录,根据匹配的条件,如果成功则将主表的记录中的字段与从表的记录中的记录,拼接成一条完整的记录,放到结果集;如果不成功则将从表中的记录中的字段全部置为null,保留主表中的字段。
用文氏图表示,如下:
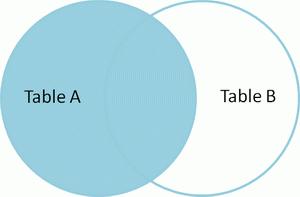
语法:
select * from 左表 left join 右表【on条件】(左表和右表 id 一 一对应)
示例:

(4)右连接(right join)
将右表作为主表,用主表中的每一条记录,匹配从表中的所有记录,根据匹配的条件,如果成功则将主表的记录中的字段与从表的记录中的记录,拼接成一条完整的记录,放到结果集。如果不成功则将从表中的记录中的字段全部置为null,保留主表中的字段。
用文氏图表示,如下:
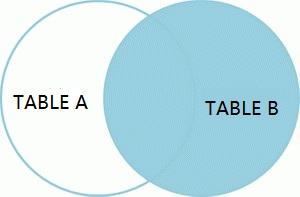
语法:
select * from 左表 right join 右表【on条件】(左表和右表 id 一 一对应)
示例:
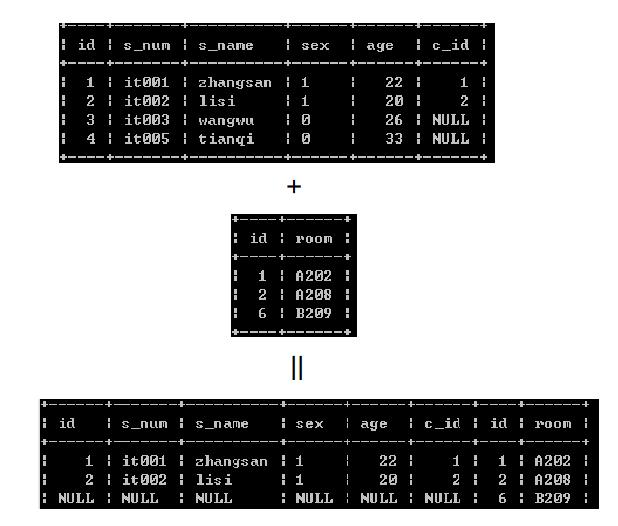
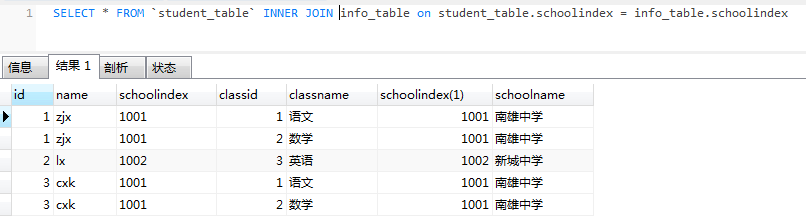
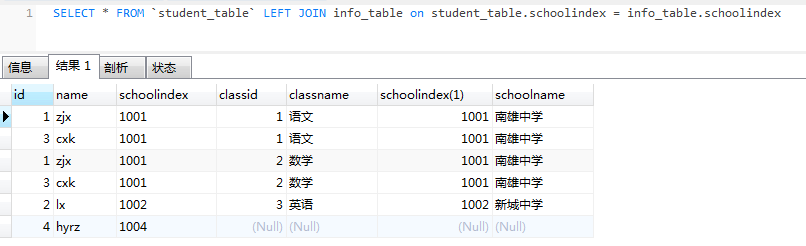
一对多和多对多情况
student_table
student_table多个相同的schoolindex 对应 info_table多个相同的schoolindex
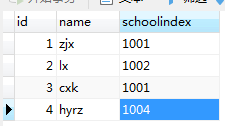
info_table
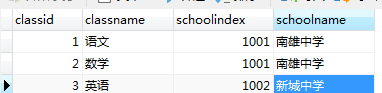
连接schoolindex
inner join结果
left join结果
right join结果

6.union 组合查询或复合查询 (需要有相似结构的数据)
用到Union操作符,将多个SELECT语句组合起来,这种查询被称为并(Union)或者复合查询。
组合查询适用于下面两种情境中:
-
从多个表中查询出相似结构的数据,并且返回一个结果集
-
从单个表中多次
SELECT查询,将结果合并成一个结果集返回。
创建一个用户表
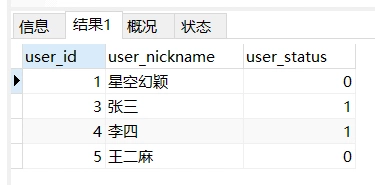
首先分两次查询用户表,然后再组合查询
select user_id,user_nickname,user_status from yy_user where user_status = 1 // 第一次查询

select user_id,user_nickname,user_status from yy_user where user_id > 3 // 第二次查询
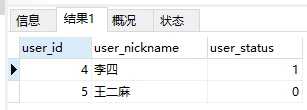
第一条SQL查询了user_status=1的用户,第二条查询了user_id > 3的用户
下面我们组合这两条SQL语句: (union会去除重复数据)
select user_id,user_nickname,user_status from yy_user where user_status = 1 UNION select user_id,user_nickname,user_status from yy_user where user_id > 3

这条语句由前面的两条语句组成,通过Union组合了两条SELECT,并且把结果集合并后输出。这条组合查询也可以使用同等where语句来替代:
select user_id,user_nickname,user_status from yy_user where user_status = 1 or user_id > 3;Union使用规则
Union有他的强大之处,详细介绍之前,首先明确一下Union的使用注意规则。
-
Union必须由两条或者两条以上的SELECT语句组成,语句之间使用Union链接。 -
Union中的每个查询必须包含相同的列、表达式或者聚合函数,他们出现的顺序可以不一致(这里指查询字段相同,表不一定一样) -
列的数据类型必须兼容,兼容的含义是必须是数据库可以隐含的转换他们的类型
UNION 语句:用于将不同表中相同列中查询的数据展示出来;(不包括重复数据)
UNION ALL 语句:用于将不同表中相同列中查询的数据展示出来;(包括重复数据)
区分多表
我们组合查询了user表和posts表。虽然结果混合在一起没有任何问题,但是当显示到页面的时候,我们需要给用户和文章不同的链接或者其他的区分。所以我们必须确定该条记录来自于哪张表,我们可以添加一个别名来作为表名。
select posts_id,posts_name,posts_status,'users' as table_name from yy_posts UNION select user_id,user_nickname,user_status,'posts' as table_name from yy_user
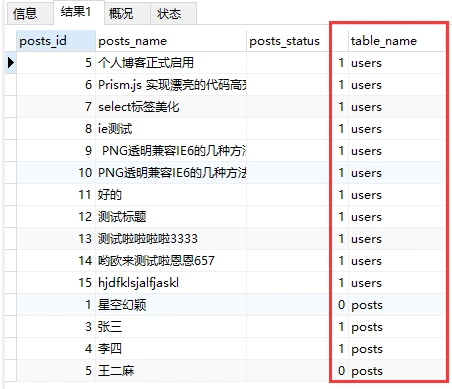
注意SQL语句中的'users' as table_name。对应的是图片里的table_name,就是我们刚刚添加用于区别表的字段。
7.导出表和数据
mysqldump -u用戶名 -p密码 -d 数据库名 表名 > 脚本名;
导出整个数据库结构和数据
mysqldump -h localhost -uroot -p123456 database > dump.sql
导出单个数据表结构和数据
mysqldump -h localhost -uroot -p123456 database table > dump.sql
导出整个数据库结构(不包含数据)
mysqldump -h localhost -uroot -p123456 -d database > dump.sql
导出单个数据表结构(不包含数据)
mysqldump -h localhost -uroot -p123456 -d database table > dump.sql
8.null值
我们已经看到SQL SELECT命令和WHERE子句一起使用,来从MySQL表中提取数据,但是,当我们试图给出一个条件,比较字段或列值设置为NULL,它确不能正常工作。
为了处理这种情况,MySQL提供了三大运算符
-
IS NULL: 如果列的值为NULL,运算结果返回 true
-
IS NOT NULL: 如果列的值不为NULL,运算结果返回 true
-
<=>: 运算符比较值,(不同于=运算符)即使两个空值它返回 true
涉及NULL的条件是特殊的。不能使用= NULL或!= NULL来匹配查找列的NULL值。这样的比较总是失败,因为它是不可能告诉它们是否是true。 甚至 NULL = NULL 也是失败的。
要查找列的值是或不是NULL,使用IS NULL或IS NOT NULL。
9.正则表达式
10.mysql全文搜索
MySQL 数据类型
MySQL中定义数据字段的类型对你数据库的优化是非常重要的。
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
数值类型
MySQL支持所有标准SQL数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
BIT数据类型保存位字段值,并且支持MyISAM、MEMORY、InnoDB和BDB表。
作为SQL标准的扩展,MySQL也支持整数类型TINYINT、MEDIUMINT和BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 字节 | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 字节 | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 字节 | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 字节 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 字节 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | 大小 (字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 |
1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |

字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
mysql管理权限
1.安装
2.安装一个MYSQL服务(需要管理员权限cmd)
注意只有操作服务的安装、启动和删除需要管理员权限,其他时候最好不要使用管理员权限。
(1)定位到安装目录下的bin文件夹
cd c:换盘符
cd C:wampinmysqlmysql5.7.9in
cd 到mysql 安装目录 (本电脑使用的是Wampserver 集成php和mysql )
(2)初始化数据库所需文件以及获取一个临时的访问密码
mysql --initialize --user=mysql --console
初始化会在bin文件夹下生成data目录(旧版本会自动有data目录,新版需要上面命令初始化)
注意:若data已经初始化,再次输入上述命令会提示文件已经存在,不用初始化了
(3)安装mysql服务
mysql install +服务名
例如:mysql install mysqltest
再在服务面板上查看 自己设定的服务名 把默认设置的自动 改为手动,php也是同样配置。
(4)登录MYSQL服务器,重置密码
mysql -u root -p
显示Enter password:输入临时密码
(5)设置数据库访问密码
mysql>set password for root@localhost=password('a19960504');
注意:本机使用的wampserver 默认密码为空,所以直接回车可进入。
注意命令行前面显示mysql>为已经进入到mysql 每条命令后面要记得加上;号
show databases; 可看到数据库,里面包含一些默认数据库不要删除。
exit;或者quit; 退出数据库
删除服务 管理员打开cmd ,在cmd任意目录下可进行删除操作 sc delete +服务名
net start +服务名 开启服务(需要管理员权限)
注意连接MySQL 需要在安装mysql目录文件夹下 mysql -u root -p
替换wamp默认mysql密码为空(现在我的电脑mysql root用户密码还是为空)
更改密码
旧版:
use mysql;
update user set password=PASSWORD('hooray') where user='root';
flush privileges;
新版:
新安装的MySQL5.7,登录时提示密码错误,安装的时候并没有更改密码,后来通过免密码登录的方式更改密码,输入update mysql.user set password=password('root') where user='root'时提示ERROR 1054 (42S22): Unknown column 'password' in 'field list',原来是mysql数据库下已经没有password这个字段了,password字段改成了authentication_string
use mysql;
update mysql.user set authentication_string=password('19960504') where user='root' ;
flush privileges;
//flush privileges; 强制刷新权限 不输入这个的话,修改密码的操作不会生效的。
一.创建用户
CREATE USER 'zjx'@'localhost' IDENTIFIED BY '19960504';
- username:你将创建的用户名
- host:指定该用户在哪个主机上可以登陆,如果是本地用户可用localhost,如果想让该用户可以从任意远程主机登陆,可以使用通配符
% - password:该用户的登陆密码,密码可以为空,如果为空则该用户可以不需要密码登陆服务器
例如:
CREATE USER 'pig'@'192.168.1.101_' IDENDIFIED BY '123456';
CREATE USER 'pig'@'%' IDENTIFIED BY '123456';
现在我电脑新建了用户 用户名:zjx 密码:19960504
新建用户zjx数据库里默认只有information_schema一个数据库,想要看root用户下数据库需要授权。
二.授权
GRANT privileges ON databasename.tablename TO 'username'@'host'
GRANT SELECT ON mysqltest4.course TO 'zjx'@'localhost'
在root用户目录下,输入上述命令,为zjx用户授权可以 select权限 查看 mysqltest4数据库里的course表内容,而mysqltest4里面的其他表内容则无法看到。
- privileges:用户的操作权限,如
SELECT,INSERT,UPDATE等,如果要授予所的权限则使用ALL - databasename:数据库名
- tablename:表名,如果要授予该用户对所有数据库和表的相应操作权限则可用
*表示,如*.*
GRANT SELECT, INSERT ON test.user TO 'pig'@'%'; GRANT ALL ON *.* TO 'pig'@'%'; GRANT ALL ON maindataplus.* TO 'pig'@'%';
注意:
用以上命令授权的用户不能给其它用户授权,如果想让该用户可以授权,用以下命令:
GRANT privileges ON databasename.tablename TO 'username'@'host' WITH GRANT OPTION;
三.设置与更改用户密码
命令:
SET PASSWORD FOR 'username'@'host' = PASSWORD('newpassword');
如果是当前登陆用户用:
SET PASSWORD = PASSWORD("newpassword");
例子:
SET PASSWORD FOR 'pig'@'%' = PASSWORD("123456");
四. 撤销用户权限
命令:
REVOKE privilege ON databasename.tablename FROM 'username'@'host';
说明:
privilege, databasename, tablename:同授权部分
例子:
REVOKE SELECT ON *.* FROM 'pig'@'%';
注意:
假如你在给用户'pig'@'%'授权的时候是这样的(或类似的):GRANT SELECT ON test.user TO 'pig'@'%',则在使用REVOKE SELECT ON *.* FROM 'pig'@'%';命令并不能撤销该用户对test数据库中user表的SELECT 操作。相反,如果授权使用的是GRANT SELECT ON *.* TO 'pig'@'%';则REVOKE SELECT ON test.user FROM 'pig'@'%';命令也不能撤销该用户对test数据库中user表的Select权限。
具体信息可以用命令SHOW GRANTS FOR 'pig'@'%'; 查看。
五.删除用户
命令:
DROP USER 'username'@'host';
mysql 子查询和派生表(派生表是在from中使用子查询)
1.子查询
MySQL子查询是嵌套在另一个查询(如SELECT,INSERT,UPDATE或DELETE)中的查询。 另外,MySQL子查询可以嵌套在另一个子查询中。
MySQL子查询称为内部查询,而包含子查询的查询称为外部查询。 子查询可以在使用表达式的任何地方使用,并且必须在括号中关闭。
情况一 mysql 子查询在select语句中

但是注意,只能使用聚合函数 avg、count 、sum 、group_concat、max、min等
情况二 mysql 子查询在where语句中
SELECT customerNumber, checkNumber, amount FROM payments WHERE amount > (SELECT AVG(amount) FROM payments);
SELECT customerName FROM customers WHERE customerNumber NOT IN (SELECT DISTINCT customerNumber FROM orders);
情况三 mysql 子查询在from语句中(派生表)
SELECT MAX(items), MIN(items), FLOOR(AVG(items)) FROM (SELECT orderNumber, COUNT(orderNumber) AS items FROM orderdetails GROUP BY orderNumber) AS lineitems;
from 语句中必须要有别名
2.派生表
派生表是从SELECT语句返回的虚拟表。派生表类似于临时表,但是在SELECT语句中使用派生表比临时表简单得多,因为它不需要创建临时表的步骤。
术语:*派生表*和子查询通常可互换使用。当SELECT语句的FROM子句中使用独立子查询时,我们将其称为派生表。
以下说明了使用派生表的查询:

请注意,独立子查询是一个子查询,可独立于包含该语句的执行语句。
与子查询不同,派生表必须具有别名,以便稍后在查询中引用其名称。 如果派生表没有别名,MySQL将发出以下错误:
Every derived table must have its own alias.
以下说明了使用派生表的SQL语句:
SELECT column_list FROM (SELECT column_list FROM table_1) derived_table_name; WHERE derived_table_name.c1 > 0;
mysql cte使用(需要mysql 8.0+)
mysql视图
视图: view, 是一种不存在的虚拟表: 类似表但是不是表
- 类似表: 视图有表结构
- 不是表: 没有数据, 视图的数据来源都是基表
视图根据基表的数量分为两种
单表视图: 基表只有一个

多表视图: 基表至少两个以上
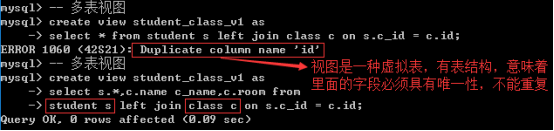
create view + sql语句 创建视图
执行了视图的创建语句之后: 到底发生了什么?
1、会在对应的数据库的表空间中产生一个视图(表)
2、会在数据库对应存储文件夹下产生一个结构文件
1.查看视图
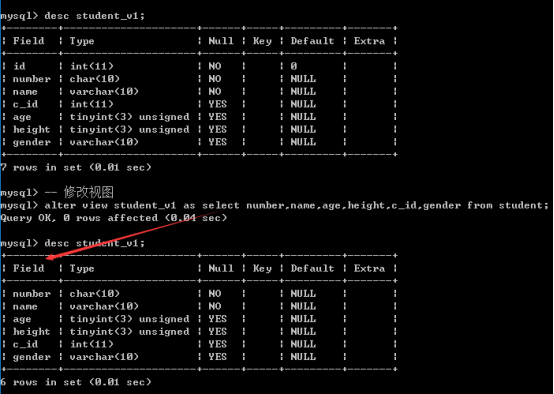
视图是虚拟表: 有类似的表结构: 凡是表的查看结构所能用的都可以用在视图上面
像表一样查看: show tables;
查看视图结构: desc 视图名字;(和平常sql查看表视图操作一致, desc + 表名)

查看创建语句
(查看数据库的创建语句 show create database 数据库名 )
(查看表的创建语句 show create table 表名)
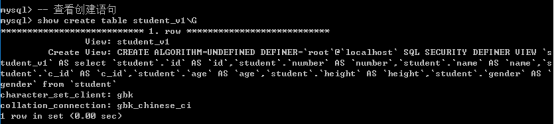
还可以使用view关键字
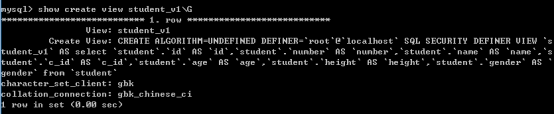
2.修改视图
视图的修改与创建类似: 视图结构是从其他表获取过来: 修改的是视图的获取方式.
alter view 视图名 as 新的select语句;
3.删除视图
drop view 视图名字;
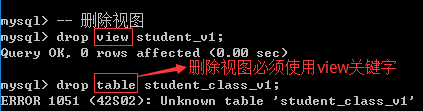
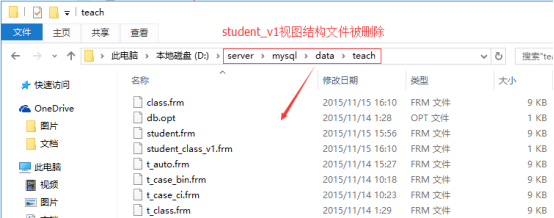
删除视图发生了什么?
1、数据库没有视图结构
2、数据库文件夹下也不存在对应的视图结构文件
4.使用视图
视图的使用: 与表一样的使用(主要用于查询数据)
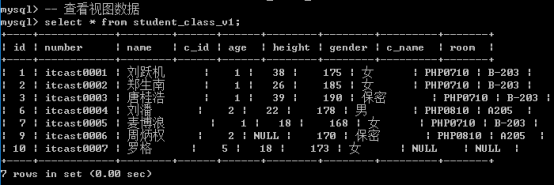
视图自身没有数据: 所有的数据来源都是基于原视图内部的查询语句.
5.视图数据操作
通过视图进行数据的写操作(增删改)
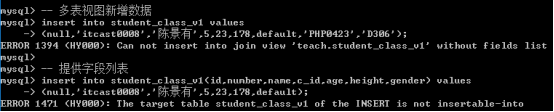
多表视图(基表来源两个以上)不能插入数据, 也不能删除数据: 但是可以修改数据
插入数据
删除数据

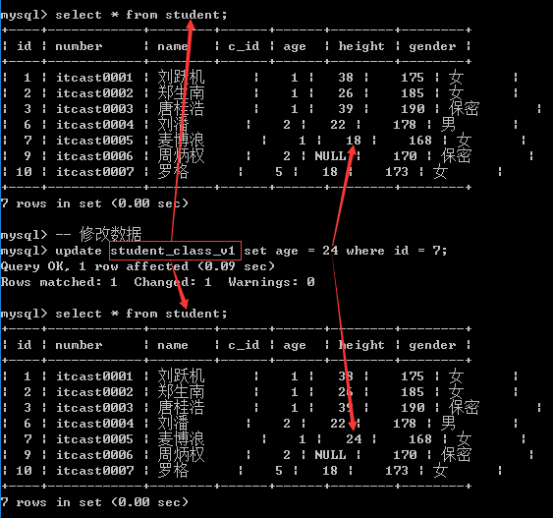
修改数据: 本身就是对基表进行操作
单表视图操作: 可以进行增删改, 但是要实现新增: 前提是视图必须包含基表的所有不能为空的字段
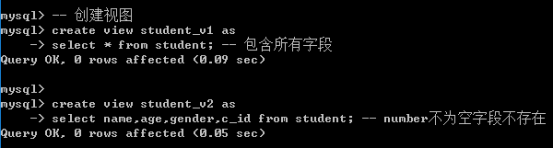
插入数据: 视图包含所有基表不为空的字段

插入数据: 视图不包含全部的基表不为空的字段
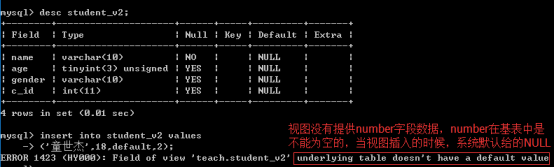
几乎不可能通过视图对表进行数据新增操作
视图更新限制: with check option
当视图原本可以查看到的数据,在经过视图修改的时候,如果修改之后,视图不能查出来: 更新失败

视图修改: 效果验证

6.视图算法
理论上: 每一个视图都有算法
视图算法有三种:
- undefined: 未定义的,默认的: 但是该算法不是真正算法: 真正的执行算法只有temptable和merge: undefined是指交给系统自动选择(系统优先选择merge: 效率高)
- temptable: 临时表,表示视图对应的select语句单独执行(先)
- merge: 合并算法: 表示视图的对应的select语句不是单独执行, 而是与外部的select语句先进行合并, 后进行执行.
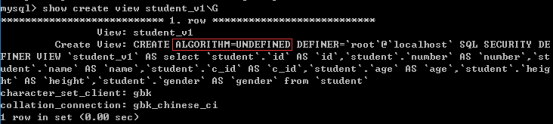
视图: create view v1 as select语句;
查询视图: select * from v1; -- select * from (select 语句) 别名;
需求: 求出每个班年龄最大的一个学生.
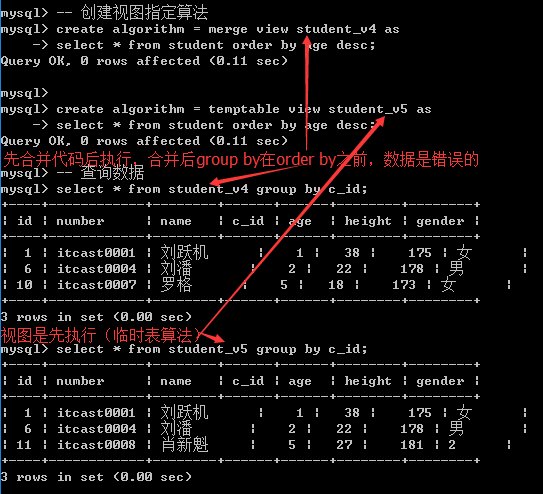
大部分的时候都会使用视图的默认算法: 但是如果涉及到视图与外部的select语句中有些五子句的关系顺序的时候: 一般使用temptable
7.视图意义
1、视图可以将复杂的SQL查询语句进行了封装: 简化了SQL语句: 从而提升了带宽的使用效率和网络间的传输效率
2、视图的存在: 主要是为了对外提供数据支持(外部系统)
- 隐藏基表字段(隐私)
- 保证了数据库的数据安全(保护数据库内部的数据结构)
- 可以灵活的控制对外的数据: 保证针对每个接口都有一个单独的数据支持: 增强了用户友好性.
3、视图利于权限控制: 有助于数据库对权限进行管理.
mysql合并表和拆分表
mysql常用函数
1.数学函数
| 函数 | 作用 |
|---|---|
| ABS(x) | 返回x的绝对值 |
| BIN(x) | 返回x的二进制(OCT返回八进制,HEX返回十六进制) |
| EXP(x) | 返回值e(自然对数的底)的x次方 |
| GREATEST(x1,x2,...,xn) | 返回集合中最大的值 |
| LEAST(x1,x2,...,xn) | 返回集合中最小的值 |
| LN(x) | 返回x的自然对数 |
| LOG(x,y) | 返回x的以y为底的对数 |
| MOD(x,y) | 返回x/y的模(余数) |
| PI() | 返回pi的值(圆周率) |
| RAND() | 返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。 |
| FLOOR(x) | 返回小于x的最大整数值,(去掉小数取整) |
| CEILING(x) | 返回大于x的最小整数值,(进一取整) |
| ROUND(x,y) | 返回参数x的四舍五入的有y位小数的值,(四舍五入) |
| TRUNCATE(x,y) | 返回数字x截短为y位小数的结果 |
| SIGN(x) | 返回代表数字x的符号的值(正数返回1,负数返回-1,0返回0) |
| SQRT(x) | 返回一个数的平方根 |
2.聚合函数(常用于GROUP BY从句的SELECT查询中)
下面五个函数会忽略值为NULL的行
| 函数 | 作用 |
|---|---|
| AVG(col) | 返回指定列的平均值 |
| COUNT(col) | 返回指定列中非NULL值/行的个数(当函数参数为星号*时不会忽略) |
| MIN(col) | 返回指定列的最小值 |
| MAX(col) | 返回指定列的最大值 |
| SUM(col) | 返回指定列的所有值之和 |
| GROUP_CONCAT(col) | 返回由属于一组的列值连接组合而成的结果 |
3.字符串函数
| 函数 | 作用 |
|---|---|
| ASCII(char) | 返回字符的ASCII码值 |
| BIT_LENGTH(str) | 返回字符串的比特长度 |
| CONCAT(s1,s2...,sn) | 将s1,s2...,sn连接成字符串 |
| CONCAT_WS(sep,s1,s2...,sn) | 将s1,s2...,sn连接成字符串,并用sep字符间隔 |
| INSERT(str,x,y,instr) | 将字符串str从第x位置开始,y个字符长的子串替换为字符串instr,返回结果 |
| FIND_IN_SET(str,list) | 分析逗号分隔的list列表,如果发现str,返回str在list中的位置 |
| LCASE(str)或LOWER(str) | 返回将字符串str中所有字符改变为小写后的结果 |
| UCASE(str)或UPPER(str) | 返回将字符串str中所有字符转变为大写后的结果 |
| LEFT(str,x) | 返回字符串str中最左边的x个字符 |
| RIGHT(str,x) | 返回字符串str中最右边的x个字符 |
| LENGTH(str) | 返回字符串str中的字符数 |
| POSITION(substr,str) | 返回子串substr在字符串str中第一次出现的位置 |
| QUOTE(str) | 用反斜杠转义str中的单引号 |
| REPEAT(str,srchstr,rplcstr) | 返回字符串str重复x次的结果 |
| REVERSE(str) | 返回颠倒字符串str的结果 |
| LTRIM(str) | 去掉字符串str开头的空格 |
| RTRIM(str) | 去掉字符串str尾部的空格 |
| TRIM(str) | 去除字符串首部和尾部的所有空格 |
4.日期和时间函数
| 函数 | 作用 |
|---|---|
| DATE_ADD(date,INTERVAL int keyword) | 返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE_ADD(CURRENT_DATE,INTERVAL 6 MONTH); |
| DATE_SUB(date,INTERVAL int keyword) | 返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE_SUB(CURRENT_DATE,INTERVAL 6 MONTH); |
| DATE_FORMAT(date,fmt) | 依照指定的fmt格式格式化日期date值 |
| FROM_UNIXTIME(ts,fmt) | 根据指定的fmt格式,格式化UNIX时间戳ts |
| MONTHNAME(date) | 返回date的月份名(英语月份,如October) |
| DAYNAME(date) | 返回date的星期名(英语星期几,如Saturday) |
| NOW() | 返回当前的日期和时间 如:2016-10-08 18:57:39 |
| CURDATE()或CURRENT_DATE() | 返回当前的日期 |
| CURTIME()或CURRENT_TIME() | 返回当前的时间 |
| QUARTER(date) | 返回date在一年中的季度(1~4) |
| WEEK(date) | 返回日期date为一年中第几周(0~53) |
| DAYOFYEAR(date) | 返回date是一年的第几天(1~366) |
| DAYOFMONTH(date) | 返回date是一个月的第几天(1~31) |
| DAYOFWEEK(date) | 返回date所代表的一星期中的第几天(1~7) |
| YEAR(date) | 返回日期date的年份(1000~9999) |
| MONTH(date) | 返回date的月份值(1~12) |
| DAY(date) | 返回date的天数部分 |
| HOUR(time) | 返回time的小时值(0~23) |
| MINUTE(time) | 返回time的分钟值(0~59) |
| SECOND(time) | 返回time的秒值(0-59) |
| DATE(datetime) | 返回datetime的日期值 |
| TIME(datetime) | 返回datetime的时间值 |
5.加密函数
| 函数 | 作用 |
|---|---|
| AES_ENCRYPT(str,key) | 返回用密钥key对字符串str利用高级加密标准算法加密后的结果,调用AES_ENCRYPT的结果是一个二进制字符串,以BLOB类型存储 |
| AES_DECRYPT(str,key) | 返回用密钥key对字符串str利用高级加密标准算法解密后的结果 |
| DECODE(str,key) | 使用key作为密钥解密加密字符串str |
| ENCRYPT(str,salt) | 使用UNIXcrypt()函数,用关键词salt(一个可以惟一确定口令的字符串,就像钥匙一样)加密字符串str |
| ENCODE(str,key) | 使用key作为密钥加密字符串str,调用ENCODE()的结果是一个二进制字符串,它以BLOB类型存储 |
| MD5() | 计算字符串str的MD5校验和 |
| PASSWORD(str) | 返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法。 |
| SHA() | 计算字符串str的安全散列算法(SHA)校验和 |
6.格式化函数
| 函数 | 作用 |
|---|---|
| DATE_FORMAT(date,fmt) | 依照字符串fmt格式化日期date值 |
| FORMAT(x,y) | 把x格式化为以逗号隔开的数字序列,y是结果的小数位数 |
| INET_ATON(ip) | 返回IP地址的数字表示 |
| INET_NTOA(num) | 返回数字所代表的IP地址 |
| TIME_FORMAT(time,fmt) | 依照字符串fmt格式化时间time值 |
其中最简单的是FORMAT()函数,它可以把大的数值格式化为以逗号间隔的易读的序列。
7.数据类型转换函数
CAST()函数,将一个值转换为指定的数据类型(类型有:BINARY,CHAR,DATE,TIME,DATETIME,SIGNED,UNSIGNED)
SELECT CAST(NOW() AS SIGNED INTEGER),CURDATE()+0;

8.系统信息函数
| 函数 | 作用 |
|---|---|
| DATABASE() | 返回当前数据库名 |
| BENCHMARK(count,expr) | 将表达式expr重复运行count次 |
| CONNECTION_ID() | 返回当前客户的连接ID |
| FOUND_ROWS() | 返回最后一个SELECT查询进行检索的总行数 |
| USER()或SYSTEM_USER() | 返回当前登陆用户名 |
| VERSION() | 返回MySQL服务器的版本 |
补充:
1.聚合函数中的group_concat函数
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符']) 结果形成字符串
基本查询
+------+------+
| id| name |
+------+------+
|1 | 10|
|1 | 20|
|1 | 20|
|2 | 20|
|3 | 200 |
|3 | 500 |
+------+------+
6 rows in set (0.00 sec)
以id分组,把name字段的值打印在一行,逗号分隔(默认)
+------+--------------------+
| id| group_concat(name) |
+------+--------------------+
|1 | 10,20,20|
|2 | 20 |
|3 | 200,500|
+------+--------------------+
3 rows in set (0.00 sec)
2.以id分组,把去冗余的name字段的值打印在一行,以';'分割
Sql代码 select id,group_concat(name separator ';') from aa group by id;
+------+----------------------------------+
| id| group_concat(name separator ';') |
+------+----------------------------------+
|1 | 10;20;20 |
|2 | 20|
|3 | 200;500 |
+------+----------------------------------+
3 rows in set (0.00 sec)
3.以id分组,把不同name字段的值打印在一行,逗号分隔
+------+-----------------------------+
| id| group_concat(distinct name) |
+------+-----------------------------+
|1 | 10,20|
|2 | 20 |
|3 | 200,500 |
+------+-----------------------------+
3 rows in set (0.00 sec)
4.以id分组,把name字段的值打印在一行,逗号分隔,以name排倒序
+------+---------------------------------------+
| id| group_concat(name order by name desc) |
+------+---------------------------------------+
|1 | 20,20,10 |
|2 | 20|
|3 | 500,200|
+------+---------------------------------------+
3 rows in set (0.00 sec)
2.字符串函数的find_in_set函数
FIND_IN_SET(str,strlist)函数接受两个参数:
- 第一个参数str 是要查找的字符串。
- 第二个参数strlist 是要搜索的逗号分隔的字符串列表。 参数以”,”分隔 如 (1,2,6,8)
FIND_IN_SET(str,strlist)函数接受两个参数根据参数的值返回一个整数或一个NULL值:
- 如果str 或strlist 为
NULL,则函数返回NULL值。 - 如果str 不在strlist 中,或者
haystack是空字符串,则返回零。 - 如果str 在strlist 中,则返回一个正整数。
这个函数在第一个参数包含一个逗号(‘,’)时将无法正常运行。
--------------------------------------------------------
例子:
mysql> SELECT FIND_IN_SET('b', 'a,b,c,d');
-> 2 因为b 在strlist集合中放在2的位置 从1开始
select FIND_IN_SET('1', '1'); 返回 就是1 这时候的strlist集合有点特殊 只有一个字符串 其实就是要求前一个字符串 一定要在后一个字符串集合中才返回大于0的数
select FIND_IN_SET('2', '1,2'); 返回2
select FIND_IN_SET('6', '1'); 返回0 字符串‘6‘不在字符串‘1’里 返回0

CREATE TABLE `tb_test` ( `id` int(8) NOT NULL auto_increment, `name` varchar(255) NOT NULL, `list` varchar(255) NOT NULL, PRIMARY KEY (`id`) );
INSERT INTO `tb_test` VALUES (1, 'name', 'daodao,xiaohu,xiaoqin'); INSERT INTO `tb_test` VALUES (2, 'name2', 'xiaohu,daodao,xiaoqin'); INSERT INTO `tb_test` VALUES (3, 'name3', 'xiaoqin,daodao,xiaohu');
原来以为mysql可以进行这样的查询:
SELECT id,name,list from tb_test WHERE 'daodao' IN(list); -- (一)

实际上这样是不行的,这样只有当list字段的值等于'daodao'时(和IN前面的字符串完全匹配),查询才有效,否则都得不到结果,即使'daodao'真的在list中。
需要用find_in_set():
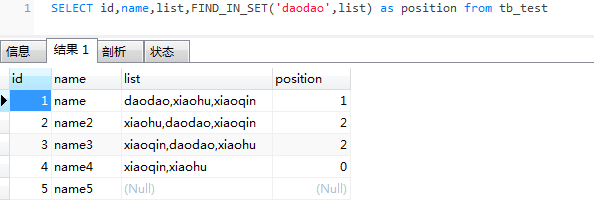
SELECT id,name,list from tb_test WHERE FIND_IN_SET('daodao',list); -- (一)的改进版

测试添加两条数据

3.字符串函数concat 和 concat_ws
CONCAT()函数在连接之前将所有参数转换为字符串类型。如果任何参数为NULL,则CONCAT()函数返回NULL值。
CONCAT_WS(separator,str1,str2,...) 第一个参数是分隔的参数的其余部分。分隔符是要连接的串之间加入。分隔符可以是一个字符串,如可以是参数的其余部分。如果分隔符是NULL,则结果为NULL。

使用concat连接 lastName 和 firstName

使用concat_ws连接 lastName 和 firstName 用 , 分割

concat_ws和concat不同的是当某个参数为null时,concat会返回null,而concat则不会
mysql 复制表
mysql备份信息
mysql防止sql注入