记录关于 C++ 多线程的点滴。
- 1. 为什么使用了std::thread的程序,在Linux下需要链接pthread?
- 2. 概念梳理: 数据竞争,线程安全
- 3. 子线程访问主线程变量的问题
- 4. 理解join()函数
- 5. 使用join()的例子:序列图的读取和处理,多线程加速
- 6.
-pthread和-lpthread的区别 - 7. Android NDK 为啥不用链接 pthread? NDK 支持 pthread 吗?
- 8. std::thread创建后会立即执行
- 9. 常用多线程库概况
- 10. 死锁例子
- 11. 多线程的Linux调试
- 12. 区分 data race 和 race conditions
- 13. data race 的一个例子
- 14. data race 的另一个例子:OpenMP 场景下出现
- 15. 线程id不一定是唯一的(unique)
1. 为什么使用了std::thread的程序,在Linux下需要链接pthread?
std::thread 是编译器实现相关的,只不过是保持了API一致:
- Linux: GCC/Clang 的 std::thread 实现,是 pthread 的封装
- MacOSX:不基于 pthread
- 可使用 ldd(Linux), otool(macOSX) 辅助验证:
#include <thread>
#include <iostream>
int main()
{
std::thread t{[]()
{
std::cout << "Hello World\n";
}};
t.join();
return 0;
}
Linux
clang++ ThreadTest.cpp
ldd a.out

macOSX
clang++ -std=c++11 ThreadTest.cpp
# 必须有-std=c++11, 感觉AppleClang很傻
otool -L a.out
# 必须有 -L 参数不然报错,感觉很难用

2. 概念梳理: 数据竞争,线程安全
data race
A data race is a situation when two threads concurrently access a shared memory location and at least one of the accesses is a write.
数据竞争指的是这样的一种情况: 两个线程并发的访问一个共享内存位置, 并且至少有一个数据访问是写操作。
(reference:ThreadSanitizer的论文: http://www.cs.columbia.edu/~junfeng/11fa-e6121/papers/thread-sanitizer.pdf)
Thread safety
Thread safety is the avoidance of data races—situations in which data are set to either correct or incorrect values, depending upon the order in which multiple threads access and modify the data.
线程安全是指消除了数据竞争的状态;数据竞争是说,数据可能正确也可能不正确,取决于多个线程的访问顺序。
Thread safety, 有时候也叫做 MT-safe.
(reference: https://docs.oracle.com/cd/E19683-01/806-6867/6jfpgdco5/index.html)
有时候我们说一个类或者一个函数是线程不安全的,是指该类或该函数在多线程环境下得到的结果可能是不稳定的,或者可能会出错。
相反,如果说这个类或者这个函数是线程安全的,则指该类或该函数即使是在多线程环境下也能稳定工作,保证数据的正确性和稳定性。
(reference:《C/C++代码调试的艺术》by 张海洋)
3. 子线程访问主线程变量的问题
所谓主线程,就是创建并执行了新开线程t的线程,而t线程就是子线程。
基于CCIA2e P18给出的例子,进一步改造、强化bug的不正确性,说明如下
2-buggy.cpp, 放大bug效果
// 2-buggy.cpp
#include <thread>
void do_something(int& i)
{
printf("i=%d\n", i);
}
struct func
{
int& i;
func(int& i_): i(i_) {}
void operator()()
{
for(unsigned j=0; j<5;j++)
{
do_something(i);
}
std::this_thread::sleep_for(std::chrono::seconds(1));
}
};
int main()
{
int some_local_state = 0;
func my_func(some_local_state);
std::thread my_thread(my_func);
my_thread.detach();
return 0;
}
简单的编译执行,预期是输出5个0,但是Linux下执行后没有任何输出:
(base) zz@home% clang++ 2-buggy.cpp -pthread
(base) zz@home% ./a.out
(base) zz@home%

开启tsan的编译选项重新编译,运行后得到0值和垃圾值:
(base) zz@home% clang++ 2-buggy.cpp -pthread -fsanitize=thread -fno-omit-frame-pointer
(base) zz@home% ./a.out
i=0
i=-570496032
i=-570496032
i=-570496032
i=-570496032
(base) zz@home%

垃圾值分析:由于主线程已经结束, 但是子线程没结束,却又读取变量i(注意是int&,是引用类型),也就是读取主线程里的i,即:访问主线程的内存,这是非法访问了,主线程内存已经被系统收回了:
- 正常情况下的编译:子线程访问不到i,于是没输出
- 开启tsan情况下的输出:访问到了垃圾值
2.cpp, 正确写法
第一种解决方法是,主线程中等待子线程,也就是
// my_thread.detach(); // 分离,原有写法
my_thread.join() // 当前改为等待
第二种解决方法:令线程函数完全自我包含(self-contained),int& i改int i,也就是在构造函数的时候获得一份i的拷贝。
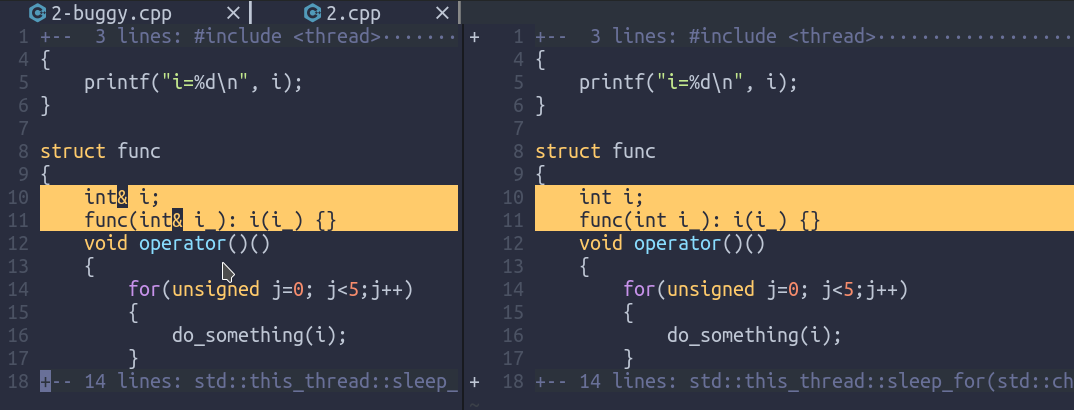
#include <thread>
void do_something(int& i)
{
printf("i=%d\n", i);
}
struct func
{
int i;
func(int i_): i(i_) {}
void operator()()
{
for(unsigned j=0; j<5;j++)
{
do_something(i);
}
std::this_thread::sleep_for(std::chrono::seconds(1)); // 故意等待长时间,让主线程先结束
}
};
int main()
{
int some_local_state = 0;
func my_func(some_local_state);
std::thread my_thread(my_func);
my_thread.detach();
fprintf(stderr, "main() is dying\n");
return 0;
}
4. 理解join()函数
第一次看一些示例代码时,std::thread对象的join()函数,让人很迷糊,不知道它到底有什么意义,例如如下代码:
MyFunctor f;
std::thread my_thread(f);
f.join();
看起来是要在新开的线程里执行 f 的 operator(), 然后主线程陷入阻塞状态,直到 f 运行结束才解封; 感觉多此一举啊,为什么不在主线程里直接调用 f() ?
是的,上面这个例子非常的useless,not practical,实际往往是在线程创建后和线程join之间,主线程仍然要执行一些操作(假设为prepare函数),那么主线程里的prepare()和子线程里的f()是并行的,并且当prepare()执行完之后,要check一下f的状态,确保f()执行完了,才能继续做后面的big_thing()函数:
MyFunctor f;
std::thread my_thread(f);
prepare(); // 主线程做一些准备函数
f.join(); // 检查子线程是否做完了,若没做完要等着,隐含着依赖关系:主线程的big_thing()的执行,依赖于子线程的完成
big_thing(); // 正式的干大事儿
感觉还是不够直白,那就用“做饭”这件事儿来举例了:
MyFunction f("买酱油");
std::thread my_thread(f); //意思是新开一个线程,去买酱油
wash_dishes(); // 洗碗(要么洁癖,要么昨天的碗没洗,T_T)
cut_vegetables(); // 洗菜
my_thread.join(); // 检查酱油是否买回来了,如果没买回来,不能炒菜。
chao_cai(); // 炒菜
结论:
- 创建线程后,立即
join(), 这对于主线程毫无意义,不如直接在主线程执行子线程要做的事情 - 创建线程后,和线程的
join()之前,主线程应该有自己的事情在做,这样使得主线程和子线程同时执行,节约了时间 - 在
join()之后,主线程应该有事情要做,并且是依赖于子线程的运行结束的;如果不存在这种依赖,就应该用detatch()
5. 使用join()的例子:序列图的读取和处理,多线程加速
例如有100张图,每张图都需要被处理(cnn,resize,etc);在每张图被处理之前,需要读取。也就是说,依赖关系只有一种,先度图再处理;前后两张图被处理或读取的顺序,是不做要求的。
如果是串行执行,那么总的耗时就是100*(readImage() + processImage()). 这样就没有用到多线程加速,很慢啊。
如果每次开一个线程来读图,然后处理上一张图,并且join一下这次地图的子线程;然后进入下一次循环; 这样的话,每次读取第i+1张图、处理第i张图的这两个过程,可以并行,并且确保了第i张图先被读然后才能被处理。代码如下
#include <thread>
#include "autotimer.hpp"
const int g_loop_count = 5;
void do_something(int& i)
{
printf("i=%d\n", i);
}
struct func
{
int i;
func(int i_): i(i_) {}
void operator()()
{
for(unsigned j=0; j<5;j++)
{
do_something(i);
}
std::this_thread::sleep_for(std::chrono::seconds(1)); // 故意等待长时间,让主线程先结束
}
};
void readImage(int i)
{
fprintf(stderr, "readImage() %d\n", i);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
void processImage(int i)
{
fprintf(stderr, "processImage() %d\n", i);
std::this_thread::sleep_for(std::chrono::milliseconds(200));
}
int main()
{
{
AutoTimer timer("sequential");
for (int i = 0; i < g_loop_count; i++)
{
readImage(i);
processImage(i);
}
}
{
AutoTimer timer("concurrent");
readImage(0);
for (int i = 1; i < g_loop_count; i++)
{
std::thread t1{readImage, i};
processImage(i-1);
t1.join();
}
processImage(g_loop_count-1);
}
return 0;
}
执行,可以看到多线程版本快了不少:
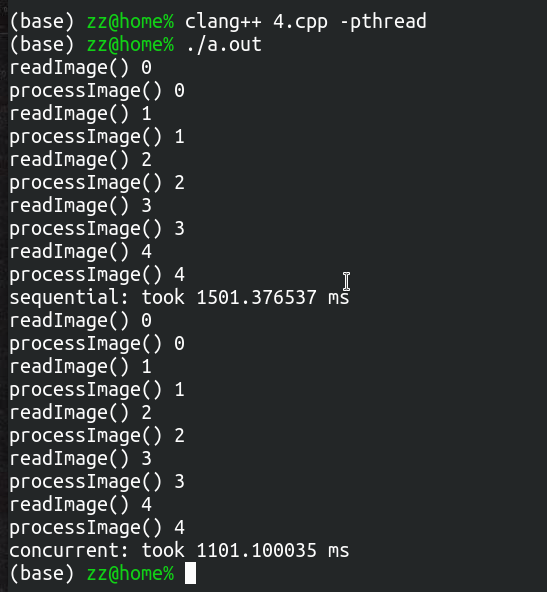
注意:上述多线程版本仅用来说明可以加速、顺序(依赖关系)可以保持(即正确的结果),但没有涉及参数传递,后续用更完整的例子进行说明。
6. -pthread 和 -lpthread 的区别
先说结论: 应该用-pthread,不应该用-lpthread; -pthread同时开启编译和链接选项,-lpthread只负责链接库。以下是探索记录:
在 StackOverFlow 已经有相关提问: Difference between -pthread and -lpthread while compiling
这里稍作翻译整理,以及进一步实践说明:
-lpthread 是曾经(大约2005年)的一种解决方案,当时有一些私有的Pthreads API的实现和POSIX不兼容,而POSIX作为一个标准仅仅规定说,如果一个(多线程库)想要保持POSIX的兼容行为,就需要链接时指定-lpthread。(个人理解为,POSIX标准在推广的时候,让原有的库有两种模式,一种是原有行为,另一种是兼容POSIX行为,后者对应-lpthread). 意味着有多种实现。
而对于现代操作系统来说,已经不存在多种实现了(也就是说大家都遵循POSIX规范,只有一种实现,因此-lpthread作为提供兼容行为的链接选项,没有使用的意义了)。
而对于现代操作系统的编译器们,-lpthread仍然能用,意思是“链接pthread库”; 而-pthread则表示“打开相关的宏定义,然后链接pthread库”(通过 man gcc 找到的)

-pthread
Define additional macros required for using the POSIX threads library. You should use this option consistently for both compilation and linking. This option is supported
on GNU/Linux targets, most other Unix derivatives, and also on x86 Cygwin and MinGW targets.
但这段英文解释仍然让人疑惑:到底展开了哪些宏定义?这些宏定义又有什么作用?
(base) zz@home% gcc -dM -E - < /dev/null > log.txt 2>&1 #导出编译器默认的宏定义到log.txt
(base) zz@home% gcc -DHOHO -dM -E - < /dev/null > log2.txt 2>&1 #手动指定-DHOHO后再导出宏定义到log2.txt,看到新增#define HOHO 1
(base) zz@home% gcc -pthread -dM -E - < /dev/null > log3.txt 2>&1 #查看-pthread选项被指定后,编译器内置的宏定义,放log3.txt
(base) zz@home% gcc -lpthread -dM -E - < /dev/null > log4.txt 2>&1 # 查看-lpthread对应的内置宏定义,放log4.txt


也就是说, 是否指定-lpthread都不产生新的编译器内置宏定义,而-pthread则增加定义了 _REENTRANT 宏。
_REENTRANT宏的作用
https://stackoverflow.com/questions/2601753/what-is-the-reentrant-flag/52933202
第一种说法: 保证了线程安全
Defining _REENTRANT causes the compiler to use thread safe (i.e. re-entrant) versions of several functions in the C library.
第二种说法:老代码里的宏,新版libc用 _POSIX_C_SOURCE 替代
Macro: _REENTRANT
Macro: _THREAD_SAFEThese macros are obsolete. They have the same effect as defining _POSIX_C_SOURCE with the value 199506L.
Some very old C libraries required one of these macros to be defined for basic functionality (e.g. getchar) to be thread-safe.
We recommend you use _GNU_SOURCE in new programs. If you don’t specify the ‘-ansi’ option to GCC, or other conformance options such as -std=c99, and don’t define any of these macros explicitly, the effect is the same as defining _DEFAULT_SOURCE to 1.
When you define a feature test macro to request a larger class of features, it is harmless to define in addition a feature test macro for a subset of those features. For example, if you define _POSIX_C_SOURCE, then defining _POSIX_SOURCE as well has no effect. Likewise, if you define _GNU_SOURCE, then defining either _POSIX_SOURCE or _POSIX_C_SOURCE as well has no effect.
考虑到有些老代码依赖于 _REENTRANT 宏,-pthread和-lphtread可能导致不一样的行为,因此保险起见应当使用 -pthread 而不是 -lpthread。
7. Android NDK 为啥不用链接 pthread? NDK 支持 pthread 吗?
先说结论:Android NDK 平台的工程,不用自行链接 pthread 库,它的 bionic 库(相当于libc)实现了 pthread 库的接口(大部分,非全部)。以下为探索:
https://stackoverflow.com/questions/30801752/android-ndk-and-pthread
第一个回答,说 bionic 里实现了 pthread 的功能:
POSIX threads (pthreads)
The android libc, bionic, provides built-in support for pthreads, so no
additional linking (-lpthreads) is necessary. It does not implement full
POSIX threads functionality and leaves out support for read/write locks,
pthread_cancel(), process-shared mutexes and condition variables as well as
other more advanced features. Read the bionic OVERVIEW.txt for more
information.TLS, thread-local storage, is limited to 59 pthread_key_t slots available
to applications, lower than the posix minimum of 128.
第二个回答,说 android ndk 的 pthread 实现不是完整的,
for the specific case of pthread_getaffinity_np, no, we don't support that. you can combine pthread_gettid_np from <pthread.h> and sched_getaffinity from <sched.h> though.
bionic 官方的状态: https://android.googlesource.com/platform/bionic/+/master/docs/status.md
8. std::thread创建后会立即执行
仍然考虑对join()的理解:在主线程中连续创建两个线程t1,t2,然后立即分别join(),问是否会t1和t2同时执行,还是串行执行?
答案是同时(并发)执行。join()是对主线程的阻塞,但是子线程创建了就立即执行了(至少下面这个例子是这样的;若创建后无法立即执行,还请给出例子)
#include <stdio.h>
#include <thread>
const int g_loop_count = 10;
void hello1()
{
for (int i = 0; i <g_loop_count; i++) {
fprintf(stderr, "hello 1\n");
}
}
void hello2()
{
for (int i = 0; i < g_loop_count; i++) {
fprintf(stderr, "hello 2\n");
}
}
int main()
{
std::thread t1(hello1);
std::thread t2(hello2);
t1.join();
t2.join();
return 0;
}
程序输出:
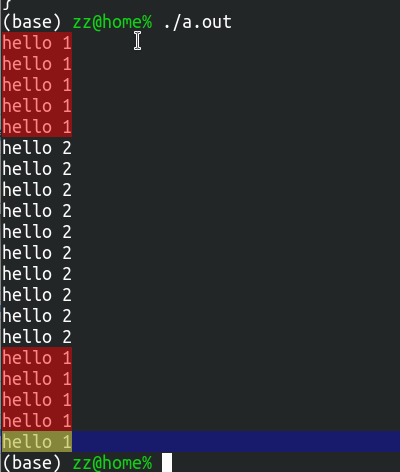
可以看到hello1()和hello2()中的输出是交错出现的,而不是严格的先后顺序关系,说明确实是并发执行的。
9. 常用多线程库概况
- pthread
平台支持: Linux (需编译链接-pthread), Android(bionic库内置,无需链接-pthread), macOSX(libSystem.B内置,无需链接),windows(没试过,但确实有库) - openmp
- tbb
- std::thread, since C++11
pthread 手册查询:
ubuntu:
# 安装依赖,否则可能不显示文档,例如docker镜像
sudo apt-get install manpages-posix manpages-posix-dev
man pthreads # 主文档。注意:有s
man pthreadbarrier_init # 单个函数文档。注意:没有s
# 如果还是不显示文档,那就再装点包
apt-get install manpages-de manpages-de-dev manpages-dev glibc-doc manpages-posix-dev manpages-posix
macOSX:
man pthread # 注意,不带s
或在线版)
明显感受到 macOSX 的用心, Linux 的pthreads文档没那么有条理:
10. 死锁例子
// C/C++ 代码调试的艺术,代码清单4-9
#include <mutex>
#include <thread>
#include <chrono>
#include <iostream>
using std::mutex;
using std::lock_guard;
using std::thread;
mutex _mutex1;
mutex _mutex2;
int data1;
int data2;
int do_work_1()
{
std::cout << "线程函数do_work_1开始" << std::endl;
lock_guard<mutex> locker1(_mutex1);
data1++;
std::this_thread::sleep_for(std::chrono::seconds(1));
lock_guard<mutex> locker2(_mutex2);
data2++;
std::cout << "线程函数do_work_1结束" << std::endl;
return 0;
}
int do_work_2()
{
std::cout << "线程函数do_work_2开始" << std::endl;
lock_guard<mutex> locker2(_mutex2);
data2++;
std::this_thread::sleep_for(std::chrono::seconds(1));
lock_guard<mutex> locker1(_mutex1);
data1++;
std::cout << "线程函数do_work_2结束" << std::endl;
return 0;
}
int main()
{
thread t1(do_work_1);
thread t2(do_work_2);
t1.join();
t2.join();
std::cout <<"线程运行结束" << std::endl;
return 0;
}
在 Linux 执行,只输出了一行,然后“卡住”,也就是陷入了死锁状态
11. 多线程的Linux调试
借助 gdb/lldb 的命令进行调试(原生命令行,or clangd+codelldb VSCode调试插件)
gdb 多线程相关命令:
#查看线程
info threads
#切换线程
thread 线程id
#只运行当前线程
set scheduler-locking on
#运行全部的线程
set scheduler-locking off
#指定某线程执行某gdb命令:
thread apply 线程id cmd
#全部的线程执行某gdb命令:
thread apply all cmd
#发送Ctrl+C(即中断信号):
signal SIGINT
https://www.bilibili.com/video/BV1ei4y1V758?p=5
lldb 相关命令:
#发送Ctrl+C(即中断信号):
pro signal SIGINT
12. 区分 data race 和 race conditions
data race 和 race conditions 相关, 但不能混为一谈:发生 data race 时, 可能有 race condition,也可能没有 race condition。
13. data race 的一个例子
https://github.com/llvm/llvm-project/issues/53241
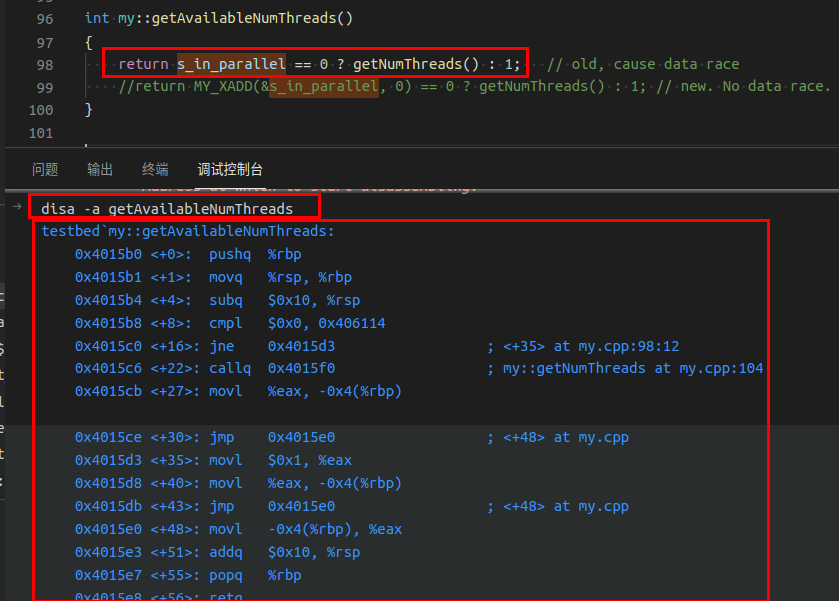
简单说就是: 两个线程t1, t2并发执行, t1会读和写变量 s_in_parallel, 因此使用了 MY_XADD 来确保原子性; 但线程 t2 呢? 虽然只是读取 s_in_parallel,但由于读取不是原子性的,仍然可能得到错误结果。
拿出证据就是:查看反汇编, MY_XADD 对应的汇编中有 lock 指令, 读 s_in_parallel 则没有:

(另外吐槽下,编译器生成的汇编,并不严格按代码写的顺序,因此不能简单的顺序查看汇编。。)
14. data race 的另一个例子:OpenMP 场景下出现
// clang++ main.cpp -fopenmp
// clang++ main.cpp -fopenmp -fsanitize=thread
#include <stdio.h>
int main()
{
while (true) {
int sum = 0;
int data = 1;
#pragma omp parallel for
for (int i = 0; i < 100; i++)
{
sum += data; // 读取 data
data++; // 写入 data
}
if(sum!=5050) {
printf("Error! sum = %d\n", sum);
break;
}
}
return 0;
}
15. 线程id不一定是唯一的(unique)
线程id可能存在复用的情况,即:第一个线程结束后,它的id可能会被以后的某个线程复用。(对于 std::thread 获取的 id 来说)。
目前的策略是: 第一个线程里强行sleep, 使得当前线程和下一个线程存在时间差, 这样一来,两个线程的id有很大概率不一样。