# Introducing NEON Development Article
介绍NEON的开发文章
链接: https://pan.baidu.com/s/1iHmmvnlLziSPPNMgaYGEoA 密码: 5asd
出版时间:2009年。
目录:
第一章 介绍 NEON
1.1 什么是SIMD
1.2 什么是NEON
1.3 NEON架构概况
1.4 面向NEON的开发
Chapter 1 第一章
Introducing NEON 介绍NEON
这里引入NEON技术,它首先在ARM Cortex-A8处理器里实现。除了介绍NEON架构,还给出单指令多数据(SIMD)的概念,从比较高的层次介绍了怎么利用它。包括这些小节:
1. SIMD是什么?
2. NEON是什么?
3. NEON架构概况
4. 面向NEON的开发
1.1 SIMD是什么?
典型的用处:多媒体编解码,图形加速,超大规模数据处理。音频处理常见的16比特数据,图形和视频处理常见的8比特数据。
当在32位微处理器上做这些操作时,有些计算单元没有被用到,但是仍然耗电。为了充分利用资源,SIMD技术用单个指令执行同时执行多个同样的操作(需要同样类型、同样尺寸的数据)。这样,硬件本来要做32位加法的,改为同时做4个8位加法,并且时间开销和做一个8位加法是一样的。
1.1.1 ARM SIMD指令
ARMv6架构引入了少量SIMD指令,是把多个16位或8位的数据打包为32位,然后放在32位通用寄存器上处理。这样看来可以有2倍或4倍加速。举个例子,UADD8 R0, R1, R2,这条指令是说把R1和R2这两个寄存器里的值相加,其中R0和R1都看做4个通道(lane)的向量,具体相加是逐通道(lane)相加,不同通道互不干扰:
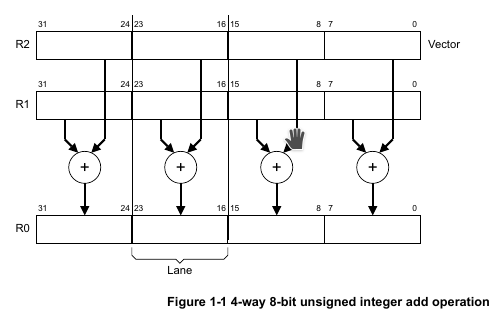
1.2 NEON是什么?
ARMv7架构引入了Advanced SIMD extension(高级SIMD扩展),作为ARMv7-A和ARMv7-R的扩展。它怎么扩展了SIMD的概念呢?定义了在64位D向量寄存器和128位Q向量寄存器上的操作。
在ARM处理器上实现的ASIMD扩展又叫做NEON,在所有的ARM Cortex-A系列上都支持。
NEON指令被作为ARM或Thumb指令流来执行,相比于使用外部加速器,这样做能简化开发、调试和集成。NEON指令能做的事情包括这些方面:
- 内存访问
- NEON向量寄存器和通用寄存器之间的数据相互拷贝
- 数据类型转换
- 数据处理
举例:VADD.I16 Q0, Q1, Q2 指令意思是,每个lane有16bit,每个对应lane位做加法,一共有8个这样的lane同时执行;第一个8个lane放在Q0向量寄存器里,第二个8个lane放在Q1向量寄存器里,结果存放在Q0向量寄存器里:
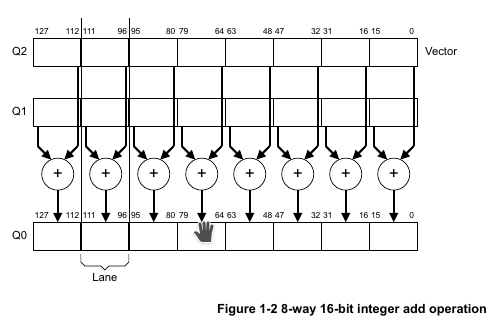
1.3 NEON架构概况
ARM架构定义ASIMD扩展作为第10、11代的架构的协处理器的一部分,而这些协处理器也用于向量浮点扩展(Vector Floating Point extension,VFP)。实际上不必同时实现VFP和NEON,通常来说支持VFP的系统只需要稍微修改(甚至不用修改)就支持NEON。
在为特定处理器优化NEON代码时,您可能必须考虑该处理器如何集成NEON技术的实现定义方面。啥意思呢?假设有A、B两个ARM处理器,你给A处理器写的NEON优化代码,在B处理器上跑,得到的时间开销很可能跟A上的不一样,即使A、B两个处理器的每个指令的指令周期数是完全一样的。 (个人理解为,A、B两个处理器频率有差别,因而相同的指令周期对应的实际耗时仍不一样)
关于ASIMD扩展的更多细节需要翻看 ARM Architecture Reference Manual ARMv7-A and ARMv7-R edition,里面列出了指令和编码。具体请到 http://infocenter.arm.com 查找。
1.3.1 支持的数据类型
NEON指令支持8位、16位、32位、64位的有符号和无符号整数。
NEON也支持32位的单精浮点类型,和8位、16位的多项式(?polynomial,不太懂)
有一个NEON指令,VCVT,用来做NEON数据类型转换,包括这些类型到32位单精度浮点的转换:
- 32位整数
- 定点的
- 半精度的浮点数(如果处理器实现了半精度扩展的话,也就是fp16)
1.3.2 NEON寄存器
NEON寄存器组(register bank),由32个64位的寄存器组成。如果ASIMD和VFPv3都被处理器所支持,那么VFPv3的浮点寄存器和ASIMD的向量寄存器是重合的。(ASIMD就是NEON的意思)。 这种情况下,VFPv3被实现为VFPv3-D32,意思是支持32个双精度浮点寄存器。啥好处呢?恢复VFP上下文的机制,和恢复NEON上下文的机制,共享使用,实现一个就可以了。
NEON向量寄存器可以整块使用,也可以切开来用,不过不是随便切,是单次或多次折半那种。所有的NEON向量寄存器组,因而有多种叫法:
- 16个128位的Q寄存器,Q0-Q15
- 32个64位的D寄存器,D0-D31
其中NEON的D0-D31向量寄存器,和VFPv3的D0-D31浮点寄存器是完全等同的。Q0-Q15的向量寄存器,每一个Q寄存器对应到一对(挨着的两个,而不是随意两个)D向量寄存器。具体写代码的时候,完全等同的寄存器,不用手动切换区分。下图展示了上面说的等同映射关系和整体情况:
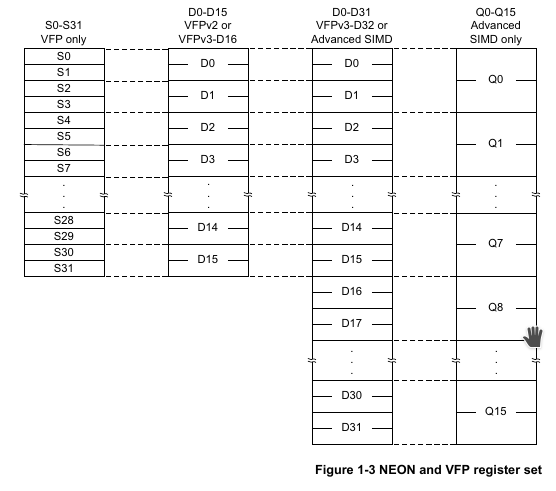
1.3.3 NEON指令
NEON指令从功能上来说很少,为啥呢?因为只提供了数据读取、数据存储、数据处理的功能,并且是集成到ARM和Thumb指令集里头的。标准的ARM和Thumb指令管理了所有的程序流控制。(这说的很绕,其实就是说,NEON相当于是ARM汇编的扩展,可以在内联汇编或单个汇编文件里写NEON,也可以用intrinsic这种类似API调用的方式来写NEON)。
很多NEON指令都是可以处理多种数据类型的(功能相同,向量长度相同,由于数据类型长度不一样,因而lane数量也不一样),具体表现为在指令后面紧跟着处理的每个lane的比特数,例如:
VADD.I16 q0, q1, q2
意思是是把q0, q1, q2都看做有8个lane的、每个lane是16bit的向量寄存器,然后q1和q2的对应lane相加,结果放到q0的对应lane上。
还有一些NEON指令,它们的输入、输出的向量寄存器大小不一样。比如:
VMULL.S16 Q0, D2, D3
意思是每个lane宽度是16bit的情况下,对应lane相乘,得到32位(而不是16位)的结果;D2和D3都是4个16bit的lane,而Q0则是4个32bit的lane。
为了提升性能和代码密度,NEON指令里的数据加载、数据写入(内存和向量寄存器之间,普通寄存器和向量寄存器之间)支持一次多写多个数据。还包括在多写多个数据时,交叉存放的指令。(初学者看到交叉存放肯定懵逼,稍微画个图):
假设内存里的uchar数组data保存了RGBRGBRGB...顺序的数据,被vld3_u8指令读取,会存放在3个分别是R、G、B通道数据的向量寄存器;如果是三次调用vld1_u8,偏移量分别是0、8、16,则目标向量寄存器里读进去的,仍然是RGB交错的数据;vld3_u8是“交错读取”的指令,对应的写入指令vst3_u8是它的逆过程(从3个向量寄存器v1.val[0], v1.val[1], v2.val[2]交错的取数据写入到连续的内存空间)。

1.4 面向NEON开发
为了使用NEON这样的新特性,你得用新一点的编译工具,比如GNU的工具,或RealView的编译工具(当前时间2021-04-05 14:28:05,Android NDK已经切换到Clang了,2333,编译器发展日新月异)。
1.4.1 汇编器
在汇编里写NEON是很直接的一种方式。正是因为NEON指令集和汇编在设计上的连贯性,使得在汇编里写起NEON往往比预期的要容易。
GNU和RVCT汇编器使用同样的指令形式,但指令形式之外的语法就不一样了。区别包括:
- 汇编指令(assembler directives)
- 标签形式(format of labels)
- 注释写法(comment indicators)
例1-1显示的是用GNU汇编器(Gas)执行NEON指令写成的函数,例1-2则给出了RVCT格式的写法。
例1-1 Simple NEON Assembler example for Gas
-----------------------------------------------------------------------------------------------------------------------
.text
.arm
.global double_elements
double_elements:
vadd.i32 q0, q0, q0
bx lr
.end
-----------------------------------------------------------------------------------------------------------------------
用Gas汇编器汇编例1-1的代码时,需要传入 -mfpu=neon 命令行参数,意思是开启NEON指令。例如:
arm-neon-linux-gnueabi-as -mfpu=neon asm.s
例1-2 Simpe NEON assembler example for RVCT
-----------------------------------------------------------------------------------------------------------------------
AREA RO, CODE, READONLY
ARM
EXPORT double_elements
double_elements
VADD.I32 Q0, Q0, Q0
BX LR
END
-----------------------------------------------------------------------------------------------------------------------
用RVCT汇编1-2的代码时,需要指定目标处理器为支持NEON指令集的处理器,例如:
armasm --cpu=Cortex-A8 asm.s
1.4.2 Intrinsic(不太好翻译,通常也不翻译)
Intrinsic函数和数据类型,统称为intrinsics(加了s的复数形式),提供了和内联函数类似的功能,并且提供了额外的特征比如类型检查、自动寄存器分配。每个Intrinsic函数看起来是C/C++调用,但在编译阶段会被底层指令所替代。这意味着什么?意味着你可以用(相对)high-level的语言来表达low-level的体系结构行为(说的这么绕,不就是用看似函数的写法表达底层NEON汇编指令吗?)
用Intrinsic函数,和用NEON汇编,有啥区别?除了能用high-level的类似函数调用的方式来访问指令,还有一点区别是,编译器可以优化Intrinsic而汇编则不被优化。(也就是通常写的asm volatile或者单独放在.s为后缀的汇编文件中)。使用Intrinsic意味着开发者不需要考虑寄存器分配和连锁问题(interlock issues,没懂),因为编译器会处理这些事情。
GCC和RVCT支持相同的NEON intrinsic语法,使得C/C++代码在两种工具链之间有很好的兼容性。要使用NEON intrinsics,需要包含头文件 arm_neon.h 。例1-3用C和Intrinsic实现了和前面汇编例子同样的功能:
例1-3 Example NEON Intrinsics
-----------------------------------------------------------------------------------------------------------------------
#include <arm_neon.h>
uint32x4_t double_elements(uint32x4_t input)
{
return (vaddq_u32(input, input));
}
-----------------------------------------------------------------------------------------------------------------------
注意,GCC和RVCT两个工具链都能正确识别例1-3的代码,区别仅仅在于给汇编器传入的参数不一样,其中:
GCC编译NEON Intrinsics:
必须制定-mfpu=neon命令行参数:
arm-none-linux-gnueabi-gcc -mfpu=neon intrinsic.c
此外你可能还需要考虑你的toolchain的其他参数,有可能需要手动增加传参-mfloat-abi=softfp,表示的是NEON变量必须被送给通用寄存器(general purpose registers)。(没动。。)
完整的被支持的Intrinsics可以在gnu在线手册里找到:
http://gcc.gnu.org/onlinedocs/gcc/ARM-NEON-Intrinsics.html
NEON Intrinsics with RVCT
RVCT要编译NEON intrinsic的话,需要在命令行参数里传入支持NEON指令的CPU,例如:
armcc –cpu=Cortex-A9 intrinsic.c
完整的受支持的Intrinsic函数和向量数据类型,请看RealView Compilation Tools Compiler Reference Guide,在线网址为:
1.4.3 自动向量化
编译器也可以对C/C++代码执行自动向量化。也就是说,不写NEON汇编,也不写NEON Intrinsics,(满足条件下)也能达到NEON一样的高性能。这样一来,代码的可移植性就更强了,包括不同的工具、不同的平台,都友好。
例1-4 NEON向量化
------------------------------------------------------------------------------------------------------------------------
void add_ints(int * __restrict pa, int * __restrict pb, unsigned int n, int x)
{
unsigned int I;
for(i=0; i<(n&~3); i++) {
pa[i] = pb[i] + x;
}
}
------------------------------------------------------------------------------------------------------------------------
例1-4给出的例子意在说明,编译器可以安全的、最佳地向量化的一个小函数。为啥呢?首先pa和pb都是用__restrict修饰,意思是说pa和pb不会有相互重叠的内存部分。同时,循环次数表示的是磨掉了后两位二进制,使得循环次数一定是4的倍数。这些因素使得编译器可以安全地向量化NEON的读写操作。
编译例1-4的代码:
和先前类似,GCC和RVCT都能识别上述代码,但是要开启编译时自动向量化展开的特性,传入的编译参数是不一样的。对于GCC来说是:
arm-none-linux-gnueabi-gcc -mfpu=neon -ftree-vectorize -c vectorized.c
同时,你可能还需要传入-mfloat-abi=softfp,表示说NEON变量必须被放在通用寄存器上。
此外,你还可以传入 -ftree-vectorizer-verbose=1 表示让编译器输出“它已经做了向量化的代码”,以及输出“它无法做向量化的代码,以及为什么不能向量化”。有些版本的GCC还支持大于1的值;利用这个参数,可以观察和尝试优化更多的代码。
对于RVCT来说,编译器开启自动向量化的参数里,必须指定支持NEON指令的CPU,以及传入-O2或更高的优化选项,以及传入-Otime和--vectorize参数,例如:
armcc --cpu=Cortex-A9 -O3 -Otime --vectorize -c vectorized.c
注意!当指定--vectorize,必须还同时指定了-Otime和-O2或-O3的优化,才能开启自动向量化。
此外,传入--fpmode=fast会给输入排序,可能导致浮点精度差异。这个参数默认是没开启的。
再有就是传入--remarks命令行参数给RVCT编译器,会提供更多详情,对于NEON向量化来说包括:
- 哪些代码被向量化了
- 哪些代码没有被向量化,以及为什么没有被向量化
1.4.4 使用NEON优化的库
在你的系统里,使用NEON技术的最简单方式,是直接用NEON优化过的库。一个具体的例子是,使用OpenMAX库(open media acceleration),可以从 http://www.arm.com 下载。(没听说过T_T)
例1-5计算两个16位整数的点积,是通过调用OpenMAX的函数omxSP_DotProd_S16( )做到的。这个函数使用NEON向量化操作实现的。
例1-5 OpenMAX example
----------------------------------------------------------------------------------------------------------------------
#include <omxSP.h>
OMX_S16 sources1[] = {42, 23, 983, 7456, 124, 11111, 4554, 10002};
OMX_S16 source2[] = {242, 423, 9832, 746, 1124, 1411, 2254, 1298};
OMX_S32 source_dotproduct(void)
{
OMX_INT len = sizeof(source1)/sizeof(OMX_S16);
return omxSP_DotProd_S16(source1, source2, len);
}
----------------------------------------------------------------------------------------------------------------------