OpenCV GaussianBlur 结果不一致
TL;DR
OpenCV高版本的GaussianBlur,某些条件下会对整张图做定点化计算替代浮点计算,导致跨版本的结果不一致:
void GaussianBlurFixedPoint(const Mat& src, /*const*/ Mat& dst,
const uint16_t/*ufixedpoint16*/* fkx, int fkx_size,
const uint16_t/*ufixedpoint16*/* fky, int fky_size,
int borderType)
{
CV_INSTRUMENT_REGION();
CV_Assert(src.depth() == CV_8U && ((borderType & BORDER_ISOLATED) || !src.isSubmatrix()));
fixedSmoothInvoker<uint8_t, ufixedpoint16> invoker(
src.ptr<uint8_t>(), src.step1(),
dst.ptr<uint8_t>(), dst.step1(), dst.cols, dst.rows, dst.channels(),
(const ufixedpoint16*)fkx, fkx_size, (const ufixedpoint16*)fky, fky_size,
borderType & ~BORDER_ISOLATED);
{
// TODO AVX guard (external call)
parallel_for_(Range(0, dst.rows), invoker, std::max(1, std::min(getNumThreads(), getNumberOfCPUs())));
}
}
问题描述
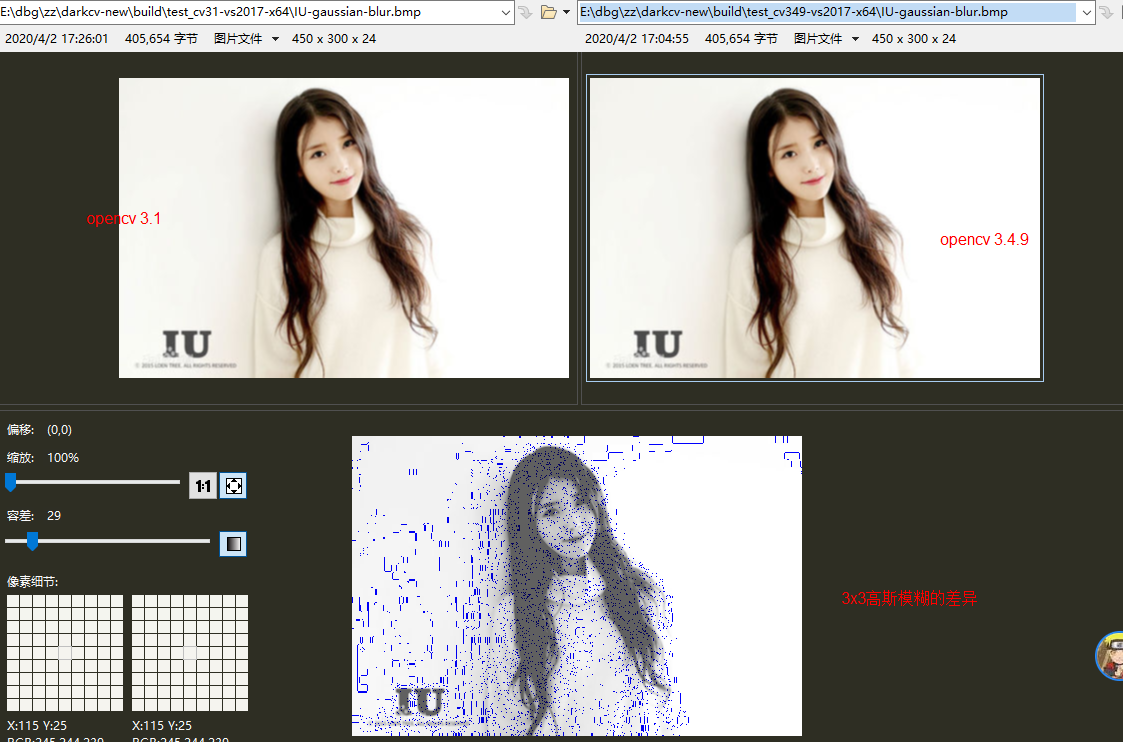
在移植OpenCV的GaussianBlur相关函数,测试阶段发现和OpenCV结果不一致,但是肉眼看不出差异。于是对比了多个版本的OpenCV,发现它们之间结果也不一致。
样例代码
namespace cv
{
static void test_GaussianBlur()
{
std::string im_pth = "../../imgs/IU.bmp";
Mat src = imread(im_pth);
Mat dst;
Size size(3, 3);
GaussianBlur(src, dst, size, 0, 0);
imwrite("IU-gaussian-blur.bmp", dst);
}
}
测试结果
第一种结果:
OpenCV 2.4.13
OpenCV 3.1.0
第二种结果:
OpenCV 3.4.5
OpenCV 3.4.9
以及我的移植版本
说明:所用OpenCV都是PC CPU版本,关闭IPP优化。
调试排查
以OpenCV3.4.9为例,会把满足一定条件的图像,执行定点化版本的高斯模糊,而不是浮点数版本的计算。这是相当于OpenCV3.1.0 / 2.4.13版本增加的内容。
看完整源码:
void GaussianBlur(InputArray _src, OutputArray _dst, Size ksize,
double sigma1, double sigma2,
int borderType)
{
CV_INSTRUMENT_REGION();
int type = _src.type();
Size size = _src.size();
_dst.create( size, type );
if( (borderType & ~BORDER_ISOLATED) != BORDER_CONSTANT &&
((borderType & BORDER_ISOLATED) != 0 || !_src.getMat().isSubmatrix()) )
{
if( size.height == 1 )
ksize.height = 1;
if( size.width == 1 )
ksize.width = 1;
}
if( ksize.width == 1 && ksize.height == 1 )
{
_src.copyTo(_dst);
return;
}
bool useOpenCL = (ocl::isOpenCLActivated() && _dst.isUMat() && _src.dims() <= 2 &&
((ksize.width == 3 && ksize.height == 3) ||
(ksize.width == 5 && ksize.height == 5)) &&
_src.rows() > ksize.height && _src.cols() > ksize.width);
CV_UNUSED(useOpenCL);
int sdepth = CV_MAT_DEPTH(type), cn = CV_MAT_CN(type);
Mat kx, ky;
createGaussianKernels(kx, ky, type, ksize, sigma1, sigma2);
CV_OCL_RUN(useOpenCL, ocl_GaussianBlur_8UC1(_src, _dst, ksize, CV_MAT_DEPTH(type), kx, ky, borderType));
CV_OCL_RUN(_dst.isUMat() && _src.dims() <= 2 && (size_t)_src.rows() > kx.total() && (size_t)_src.cols() > kx.total(),
ocl_sepFilter2D(_src, _dst, sdepth, kx, ky, Point(-1, -1), 0, borderType))
Mat src = _src.getMat();
Mat dst = _dst.getMat();
Point ofs;
Size wsz(src.cols, src.rows);
if(!(borderType & BORDER_ISOLATED))
src.locateROI( wsz, ofs );
CALL_HAL(gaussianBlur, cv_hal_gaussianBlur, src.ptr(), src.step, dst.ptr(), dst.step, src.cols, src.rows, sdepth, cn,
ofs.x, ofs.y, wsz.width - src.cols - ofs.x, wsz.height - src.rows - ofs.y, ksize.width, ksize.height,
sigma1, sigma2, borderType&~BORDER_ISOLATED);
CV_OVX_RUN(true,
openvx_gaussianBlur(src, dst, ksize, sigma1, sigma2, borderType))
//CV_IPP_RUN_FAST(ipp_GaussianBlur(src, dst, ksize, sigma1, sigma2, borderType));
if(sdepth == CV_8U && ((borderType & BORDER_ISOLATED) || !_src.getMat().isSubmatrix()))
{
std::vector<ufixedpoint16> fkx, fky;
createGaussianKernels(fkx, fky, type, ksize, sigma1, sigma2);
static bool param_check_gaussian_blur_bitexact_kernels = utils::getConfigurationParameterBool("OPENCV_GAUSSIANBLUR_CHECK_BITEXACT_KERNELS", false);
if (param_check_gaussian_blur_bitexact_kernels && !validateGaussianBlurKernel(fkx))
{
CV_LOG_INFO(NULL, "GaussianBlur: bit-exact fx kernel can't be applied: ksize=" << ksize << " sigma=" << Size2d(sigma1, sigma2));
}
else if (param_check_gaussian_blur_bitexact_kernels && !validateGaussianBlurKernel(fky))
{
CV_LOG_INFO(NULL, "GaussianBlur: bit-exact fy kernel can't be applied: ksize=" << ksize << " sigma=" << Size2d(sigma1, sigma2));
}
else
{
if (src.data == dst.data)
src = src.clone();
//-------------!! 注意这里,dispatch到fixedpoint这一版本的实现上
CV_CPU_DISPATCH(GaussianBlurFixedPoint, (src, dst, (const uint16_t*)&fkx[0], (int)fkx.size(), (const uint16_t*)&fky[0], (int)fky.size(), borderType),
CV_CPU_DISPATCH_MODES_ALL);
return;
}
}
//-------!!先前几行的dispatch分支算好后直接return,不会fall back到sepFilter2D
sepFilter2D(src, dst, sdepth, kx, ky, Point(-1, -1), 0, borderType);
}
而OpenCV 3.1.0的实现则是这样的:
void cv::GaussianBlur( InputArray _src, OutputArray _dst, Size ksize,
double sigma1, double sigma2,
int borderType )
{
int type = _src.type();
Size size = _src.size();
_dst.create( size, type );
if( borderType != BORDER_CONSTANT && (borderType & BORDER_ISOLATED) != 0 )
{
if( size.height == 1 )
ksize.height = 1;
if( size.width == 1 )
ksize.width = 1;
}
if( ksize.width == 1 && ksize.height == 1 )
{
_src.copyTo(_dst);
return;
}
#ifdef HAVE_TEGRA_OPTIMIZATION
Mat src = _src.getMat();
Mat dst = _dst.getMat();
if(sigma1 == 0 && sigma2 == 0 && tegra::useTegra() && tegra::gaussian(src, dst, ksize, borderType))
return;
#endif
CV_IPP_RUN(true, ipp_GaussianBlur( _src, _dst, ksize, sigma1, sigma2, borderType));
Mat kx, ky;
createGaussianKernels(kx, ky, type, ksize, sigma1, sigma2);
sepFilter2D(_src, _dst, CV_MAT_DEPTH(type), kx, ky, Point(-1,-1), 0, borderType );
}
显然它是始终调用sepFilter2D的实现的。
调用sepFilter2D()就能产生一致的结果了吗?
实际上,sepFilter2D()里面也做了SSE和定点化的优化。也可以认为有幺蛾子:如果限定都用同一版本的opencv(例如3.1),但一个是开启SSE(默认开启的),另一个是手动关掉SSE(例如我自行移植的,源码拿过来,只不过取消定义CV_SSE2宏),那么同一张图的高斯模糊结果还是可能不一致。
Let's going deeper into the source code:
调用堆栈中的关键断点:
GaussianBlur() //---(1)
-> sepFilter2D() //---(2)
-> f->apply() //---(3)
-> proceed() //---(4)
-> (*columnFilter)(...) //---(5)
-> i = (this->vecOp)(src, dst, width) //---(6)
-> SymmColumnVec_32s8u类的operator()函数 //---(7)
for (; i < width; i++) {
-> ST s0 = (S0[i] + S2[i])*f1 + S1[i] * f0 + _delta; //---(8)
-> D[i] = castOp(s0); //---(9)
}
其中(7)处根据是否开启SSE返回一个索引值i,如果开了SSE支持则执行相应计算,处理了图像一行内绝大多数元素(图像宽度width做向下16取整的长度,都给处理了),并且SSE调用确保了浮点精度;而如果没开启SSE则返回了0,也就是“留给后人做完整计算”:
struct SymmColumnVec_32s8u{
...
int operator()(const uchar** _src, uchar* dst, int width) const
{
#if defined(CV_SSE2) && defined(USE_SSE2)
int ksize2 = (kernel.rows + kernel.cols - 1) / 2;
const float* ky = kernel.ptr<float>() + ksize2;
int i = 0, k;
bool symmetrical = (symmetryType & KERNEL_SYMMETRICAL) != 0;
const int** src = (const int**)_src;
const __m128i *S, *S2;
__m128 d4 = _mm_set1_ps(delta);
if (symmetrical)
{
for (; i <= width - 16; i += 16)
{
__m128 f = _mm_load_ss(ky);
f = _mm_shuffle_ps(f, f, 0);
__m128 s0, s1, s2, s3;
__m128i x0, x1;
S = (const __m128i*)(src[0] + i);
s0 = _mm_cvtepi32_ps(_mm_load_si128(S));
s1 = _mm_cvtepi32_ps(_mm_load_si128(S + 1));
s0 = _mm_add_ps(_mm_mul_ps(s0, f), d4);
s1 = _mm_add_ps(_mm_mul_ps(s1, f), d4);
s2 = _mm_cvtepi32_ps(_mm_load_si128(S + 2));
s3 = _mm_cvtepi32_ps(_mm_load_si128(S + 3));
s2 = _mm_add_ps(_mm_mul_ps(s2, f), d4);
s3 = _mm_add_ps(_mm_mul_ps(s3, f), d4);
for (k = 1; k <= ksize2; k++)
{
S = (const __m128i*)(src[k] + i);
S2 = (const __m128i*)(src[-k] + i);
f = _mm_load_ss(ky + k);
f = _mm_shuffle_ps(f, f, 0);
x0 = _mm_add_epi32(_mm_load_si128(S), _mm_load_si128(S2));
x1 = _mm_add_epi32(_mm_load_si128(S + 1), _mm_load_si128(S2 + 1));
s0 = _mm_add_ps(s0, _mm_mul_ps(_mm_cvtepi32_ps(x0), f));
s1 = _mm_add_ps(s1, _mm_mul_ps(_mm_cvtepi32_ps(x1), f));
x0 = _mm_add_epi32(_mm_load_si128(S + 2), _mm_load_si128(S2 + 2));
x1 = _mm_add_epi32(_mm_load_si128(S + 3), _mm_load_si128(S2 + 3));
s2 = _mm_add_ps(s2, _mm_mul_ps(_mm_cvtepi32_ps(x0), f));
s3 = _mm_add_ps(s3, _mm_mul_ps(_mm_cvtepi32_ps(x1), f));
}
x0 = _mm_packs_epi32(_mm_cvtps_epi32(s0), _mm_cvtps_epi32(s1));
x1 = _mm_packs_epi32(_mm_cvtps_epi32(s2), _mm_cvtps_epi32(s3));
x0 = _mm_packus_epi16(x0, x1);
_mm_storeu_si128((__m128i*)(dst + i), x0);
}
for (; i <= width - 4; i += 4)
{
__m128 f = _mm_load_ss(ky);
f = _mm_shuffle_ps(f, f, 0);
__m128i x0;
__m128 s0 = _mm_cvtepi32_ps(_mm_load_si128((const __m128i*)(src[0] + i)));
s0 = _mm_add_ps(_mm_mul_ps(s0, f), d4);
for (k = 1; k <= ksize2; k++)
{
S = (const __m128i*)(src[k] + i);
S2 = (const __m128i*)(src[-k] + i);
f = _mm_load_ss(ky + k);
f = _mm_shuffle_ps(f, f, 0);
x0 = _mm_add_epi32(_mm_load_si128(S), _mm_load_si128(S2));
s0 = _mm_add_ps(s0, _mm_mul_ps(_mm_cvtepi32_ps(x0), f));
}
x0 = _mm_cvtps_epi32(s0);
x0 = _mm_packs_epi32(x0, x0);
x0 = _mm_packus_epi16(x0, x0);
*(int*)(dst + i) = _mm_cvtsi128_si32(x0);
}
}
else
{
for (; i <= width - 16; i += 16)
{
__m128 f, s0 = d4, s1 = d4, s2 = d4, s3 = d4;
__m128i x0, x1;
for (k = 1; k <= ksize2; k++)
{
S = (const __m128i*)(src[k] + i);
S2 = (const __m128i*)(src[-k] + i);
f = _mm_load_ss(ky + k);
f = _mm_shuffle_ps(f, f, 0);
x0 = _mm_sub_epi32(_mm_load_si128(S), _mm_load_si128(S2));
x1 = _mm_sub_epi32(_mm_load_si128(S + 1), _mm_load_si128(S2 + 1));
s0 = _mm_add_ps(s0, _mm_mul_ps(_mm_cvtepi32_ps(x0), f));
s1 = _mm_add_ps(s1, _mm_mul_ps(_mm_cvtepi32_ps(x1), f));
x0 = _mm_sub_epi32(_mm_load_si128(S + 2), _mm_load_si128(S2 + 2));
x1 = _mm_sub_epi32(_mm_load_si128(S + 3), _mm_load_si128(S2 + 3));
s2 = _mm_add_ps(s2, _mm_mul_ps(_mm_cvtepi32_ps(x0), f));
s3 = _mm_add_ps(s3, _mm_mul_ps(_mm_cvtepi32_ps(x1), f));
}
x0 = _mm_packs_epi32(_mm_cvtps_epi32(s0), _mm_cvtps_epi32(s1));
x1 = _mm_packs_epi32(_mm_cvtps_epi32(s2), _mm_cvtps_epi32(s3));
x0 = _mm_packus_epi16(x0, x1);
_mm_storeu_si128((__m128i*)(dst + i), x0);
}
for (; i <= width - 4; i += 4)
{
__m128 f, s0 = d4;
__m128i x0;
for (k = 1; k <= ksize2; k++)
{
S = (const __m128i*)(src[k] + i);
S2 = (const __m128i*)(src[-k] + i);
f = _mm_load_ss(ky + k);
f = _mm_shuffle_ps(f, f, 0);
x0 = _mm_sub_epi32(_mm_load_si128(S), _mm_load_si128(S2));
s0 = _mm_add_ps(s0, _mm_mul_ps(_mm_cvtepi32_ps(x0), f));
}
x0 = _mm_cvtps_epi32(s0);
x0 = _mm_packs_epi32(x0, x0);
x0 = _mm_packus_epi16(x0, x0);
*(int*)(dst + i) = _mm_cvtsi128_si32(x0);
}
}
return i;
#else
return 0;
#endif
}
};
回到(8)和(9)处,其实是做定点化计算,以及clip(saturate_cast). saturate cast时,源类型ST是int,目标类型DT是uchar。
ST s0 = (S0[i] + S2[i])*f1 + S1[i] * f0 + _delta; //---(8)
D[i] = castOp(s0); //---(9)
调试时看到,f1等于64,f0等于128;castOp则其实是FixedPtCastEx类实例,执行它的functor。其完整定义:
template<typename ST, typename DT> struct FixedPtCastEx
{
typedef ST type1;
typedef DT rtype;
FixedPtCastEx() : SHIFT(0), DELTA(0) {}
FixedPtCastEx(int bits) : SHIFT(bits), DELTA(bits ? 1 << (bits - 1) : 0) {}
DT operator()(ST val) const { return saturate_cast<DT>((val + DELTA) >> SHIFT); } //此处functor被调用,定点化计算的同时,被saturate_cast<>执行了clip操作
int SHIFT, DELTA;
};
当然了,(8)和(9)的定点化操作,是给:
- 开启SSE支持时,SSE没有处理完的行尾元素用的
- 没开启SSE支持时,给整行元素用的